FRED-T5. Новая SOTA модель для русского языка от SberDevices

Уже много времени прошло с момента публикации наших последних языковых моделей ruT5, ruRoBERTa, ruGPT-3. За это время много что изменилось в NLP. Наши модели легли в основу множества русскоязычных NLP-сервисов. Многие коллеги на базе наших моделей выпустили свои доменно-адаптированные решения и поделились ими с сообществом. Надеемся, что наша новая модель поможет вам поднять метрики качества, и ее возможности вдохновят вас на создание новых интересных продуктов и сервисов.
Появление ChatGPT и, как следствие, возросший интерес к методам обучения с подкреплением обратной связью от человека (Reinforcement Learning with Human Feedback, RLHF), привели к росту потребности в эффективных архитектурах для reward-сетей. Именно от «интеллекта» и продуктопригодности reward-модели зависит то, насколько эффективно модель для инструктивной диалоговой генерации будет дообучаться, взаимодействуя с экспертами. Разрабатывая FRED-T5, мы имели в виду и эту задачу, поскольку от качества её решения будет во многом зависеть успех в конкуренции с продуктами OpenAI. Так что если ваша команда строит в гараже свой собственный ChatGPT, то, возможно, вам следует присмотреться и к FRED«у. Мы уже ранее рассказывали в общих чертах об этой модели, а сейчас, вместе с публичным релизом, настало время раскрытия некоторых технических подробностей.
Появление новых, более производительных GPU и TPU открывает возможности для использования в массовых продуктах и сервисах всё более емких моделей машинного обучения. Выбирая архитектуру своей модели, мы целились именно в ее пригодность к массовому realtime-инференсу, поскольку время выполнения и доступное оборудование — это основные факторы, лимитирующие возможность создания массовых решений на основе нейросетевых моделей. Если вы уже используете в своем решении модель ruT5, то подменив ее на FRED-T5 вы, вероятно, получите заметное улучшение значений ваших целевых метрик. Конечно, в скором будущем мы обучим еще более емкие варианты модели FRED-T5 и проверим их возможности — мы планируем и дальнейшее развитие линейки энкодер-декодерных моделей для обработки русского языка.
Да, забегая вперед, модель вы можете взять на HF: FRED-T5–1.7B и FRED-T5-large.
Архитектура модели.
FRED-T5 расшифровывается как Full-scale Russian Enhanced Denoisers based on T5 architecture. Из названия видно, что модель основана на энкодер-декодерной архитектуре T5, изначально предложенной исследователями из Google. Существует две версии FRED-T5 — Large (820 млн параметров) и 1.7B (1,7 млрд параметров). Разница между ними только в количестве голов блока внимания (attention heads), размерности скрытого и полносвязного слоев. Таким образом, у обеих версий модели 24 слоя. В отличие от ruT5 в FRED-T5 вместо функции активации relu использована другая функция активации — gated-gelu.
Модель | Число параметров | Число слоев | Размерность эмбеддингов (d_model) | Размерность полносвязного слоя (d_ff) | Число голов (num_heads) | Размер словаря (vocab_size) |
ruT5-large | 737 млн | 24 | 1024 | 4096 | 16 | 32128 |
FRED-T5 large | 820 млн | 24 | 1024 | 2816 | 16 | 50364 |
FRED-T5 1.7B | 1740 млн | 24 | 1536 | 4096 | 24 | 50364 |
Мы решили отказаться от sentencepiece-токенизатора, использованного в модели ruT5, в пользу BBPE (Byte-level BPE) и увеличили словарь до 50364 токенов. BBPE-токенизатор используется в наших моделях ruGPT-3 и ruRoBERTa. Словарь такой же как у моделей ruGPT-3 до размера Large. Также мы добавили 107 спецтокенов, которые использовали на этапе предобучения модели (100 штук используются для кодирования span«ов, так же, как это сделано в модели ruT5, а 7 дополнительных спецтокенов кодируют различные задачи денойзеров).
Задачи на которых обучалась модель.
Во многом для задачи претрейна мы вдохновились статьей UL2 от Google Brain. Коллеги из гугла предложили смесь денойзеров (mixture of denoisers) для предобучения модели.
Дословно denoiser переводится на русский язык как «удалитель шума». Шум в данном случае заключается в случайном удалении части токенов используемой для обучения последовательности с тем, чтобы модель научилась восстанавливать данные пропуски. Решая задачу денойзинга (то есть, «очистки от шума»), модель выучивает взаимосвязи между различными частями текста на естественном языке, что затем позволяет ей решать множество задач, связанных с пониманием текста.
Под отдельным денойзером следует понимать конкретный способ подготовки примера для обучения. Два денойзера построены на задаче «span corruption» (то есть «повреждения спана», под спаном понимают участок последовательности, состоящий из одного или нескольких следующих подряд токенов) с различными параметрами выбора спанов. В этой задаче берут исходную последовательность, удаляют случайные спаны и подменяют их на спецтокены (
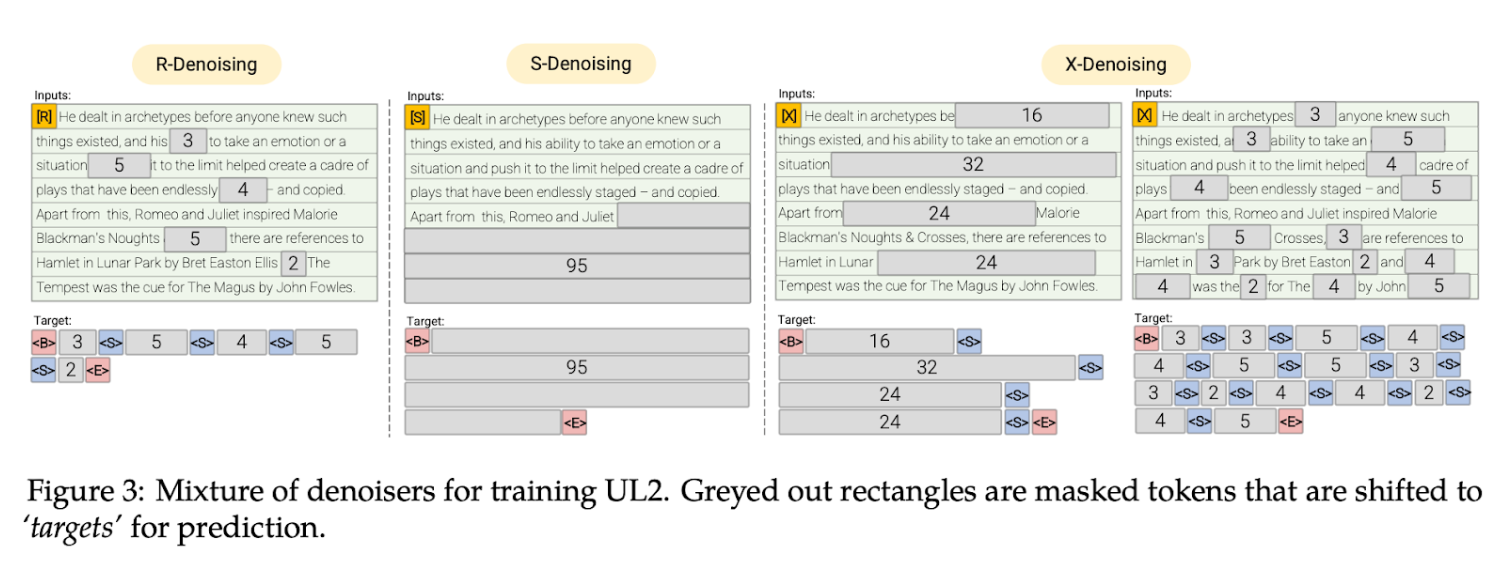
Денойзеры из статьи UL2.
Задача «span corruption» похожа на задачу MLM (masked language modelling — маскированного языкового моделирования), которую используют часто для претрейна энкодерных трансформерных моделей (BERT, RoBERTa и др.). Но эта задача сложнее для модели, ибо модель еще определяет какой длины спан ей нужно сгенерировать. Часто это длина может быть 64 токена и более.
Вот такие параметры семплирования для каждого из денойзеров предложили в UL2.

Параметры денойзеров из статьи UL2.
Для R и X денойзера использовали нормальное распределение для семплирования длин спанов. Параметр µ — это средняя длина спанов, r — это доля токенов, которая будет скрыта. Денойзер R c параметрами µ = 3, r = 0,15 соответствует задаче, на которой обучалась модель T5 и наш русскоязычный аналог — ruT5.
При обучении, каждый из денойзеров помечался спецтокеном, чтобы модель могла понять о каком денойзере сейчас идет речь.
В претрейне FRED-T5 мы использовали 7 денойзеров. В качестве отдельных денойзеров мы взяли все варианты семплирования как в UL2. С такими же параметрами, но с равномерным распределением, а не с нормальным. Например, для R-денойзера в UL2 есть два набора параметров семплирования (µ = 3, r = 0.15, n) и (µ = 8, r = 0.15, n) в нашем случае мы сделали два отдельных денойзера с параметрами (µ = 3, r = 0.15, n) и (µ = 8, r = 0.15, n). И в финальном варианте на каждый из денойзеров приходилось 1/7 часть семплов, в то время как у UL2 — ⅓. Для префиксов денойзеров мы использовали спецтокены: '

Денойзеры FRED-T5.
Обучение модели.
В качестве датасета мы взяли тот же сет, что использовали для обучения ruT5. Общий размер датасета около 300 Гб и состоит он из Википедии, новостей, книг, части очищенного CommonCrawl и т. д. Мы стремились зафиксировать датасет и сравнить модели с ruT5. Этот датасет был собран в 2020 году, и в нем, например, отсутствует информация про COVID-19 или поражение Трампа на президентских выборах в США. Позже мы собрали актуальные последние новости, свежий дамп Википедии и доучивали модель на них отдельно.
FRED-T5 1.7B мы обучали на кластере Кристофари Neo на 112 GPU Nvidia А100. Обучение модели Large мы запустили на первом «Кристофари» и продолжали в течение 35 дней, используя 160 GPU Nvidia V100, а затем доучивали 5 дней на 80 GPU Nvidia А100 на «Кристофари Neo».
Я опишу процесс обучения на примере модели 1.7B. На графике изображена динамика функции потерь на обучающей выборке (train loss) для этой модели на протяжении всего периода обучения.
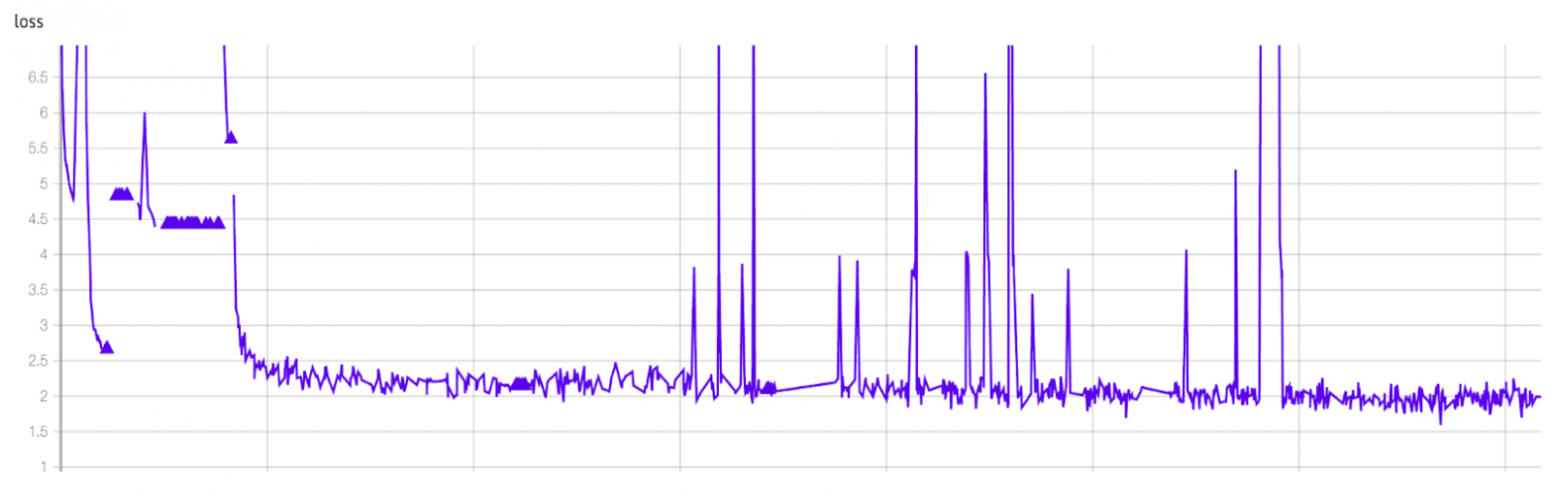
Полный график train loss FRED-T5.
В начале обучения мы столкнулись с большим количеством падения модели в том числе и из-за инфраструктурных причин. Если выбросить время на перезапуск и отладку кода, то совокупное обучение заняло около 45 дней на 112 GPU. В совокупности модель видела около 1,5 трлн токенов. Размер батча (batch size) в токенах составлял около 750 тысяч. Модель прошла чуть больше 2 млн шагов.
Ниже я разбил график train loss на несколько периодов обучения.

График train loss с периодами.
1. До вертикальной зеленой линии:
В первой части обучения, до вертикальной зеленой линии, в сиквенсах мы не добавляли префиксов денойзеров. Оптимизатор Adafactor с большим стартовым значением скорости обучения (learning rate, LR) — 0,01. Всего на этом этапе модель прошла около 700 тысяч шагов обучения.
2. От зеленой до красной линии:
Мы добавили префиксы задач в начало каждого сиквенса. Теперь модель понимала о каком денойзере идет речь в конкретном примере. Adafactor c постоянным LR = 0,001. Модель прошла еще около 700 тысяч шагов. Видно, что подсветка префиксами не оказала существенного влияния на снижение лосса. Да, лосс немного снижался, но ступенчатого снижения мы не видели. На втором этапе появились странные взлеты лосса и потом его возвращение. Пока мы не нашли объяснения этому феномену. Но дело точно не в аномальных семплах данных.
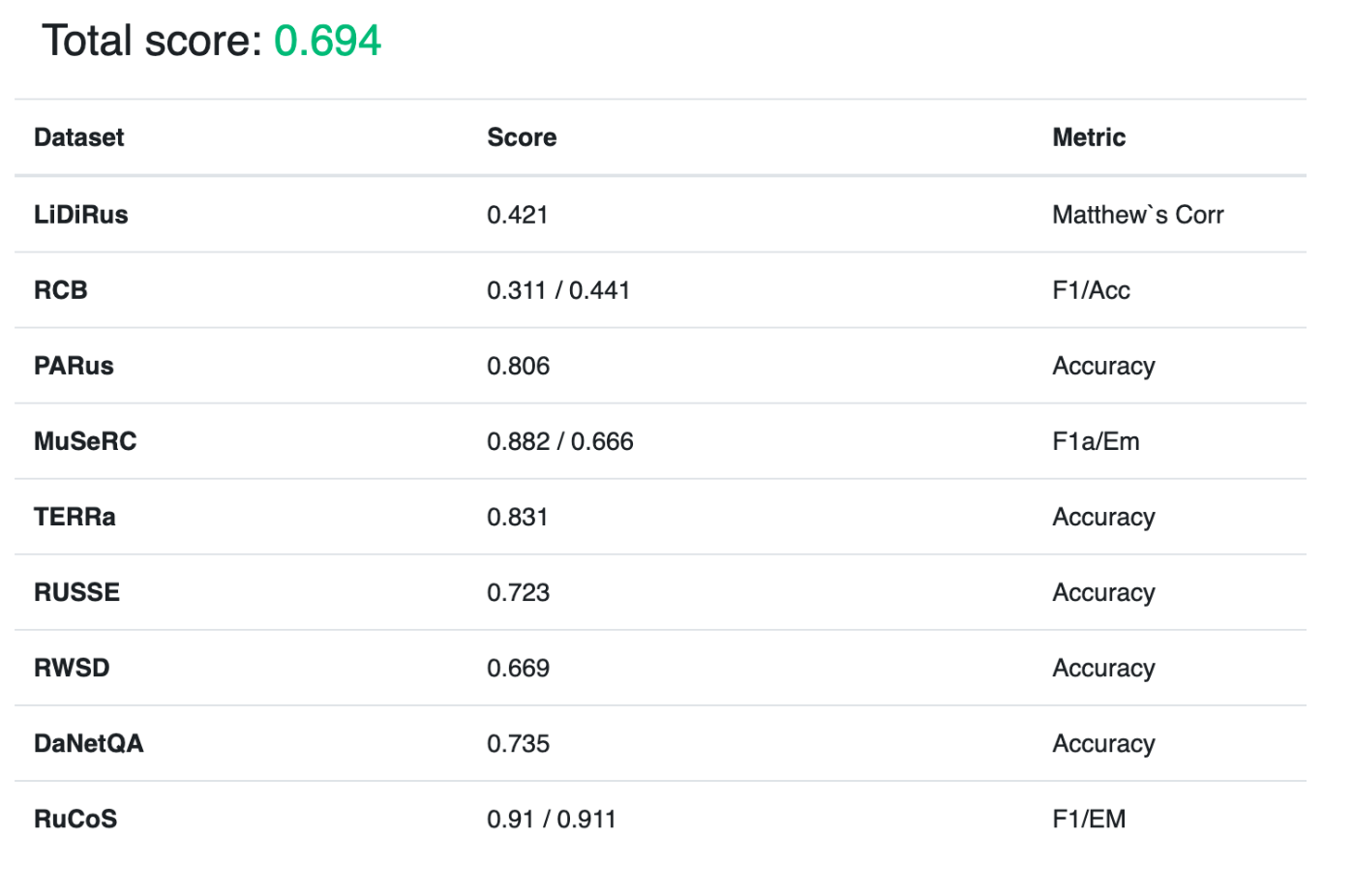
Как я уже писал выше, мы столкнулись с большим количеством падений обучения на начальной стадии. Для отладки кода мы фиксировали значения seed«ов (параметров инициализации генераторов псевдослучайных чисел). Для отладки всех воркеров в какой-то момент я настроил seed«ы воркеров таким образом, чтобы при работе они получали один и тот же набор данных. И как иногда это бывает — забыл отключить этот механизм при запуске предобучения. Так вот, до красной линии модель обучалась на 3,5 Гб данных, то есть на случайной выборке из нашего сета размеров чуть более 1% его объема. Позднейшее детальное изучение логов подтвердило эту гипотезу. Самое интересное, что полученная модель хорошо решала RussianSuperGLUE (с общей оценкой 0,759), в то время как финальный чекпойнт модели показал 0,762, то есть всего на 0,003 балла выше. Подробнее я расскажу об этом ниже.
3. Все, что справа от красной линии:
Мы поставили доучиваться модель на всем датасете. До голубой линии обучение шло с Adafactor и c постоянным LR = 0,001. После нее обучение шло с AdamW и LR = 0,00004 c линейным уменьшением LR. Интересно, то что лосс на этом этапе снизился совсем немного.
Для модели Large период обучения на маленькой части сета был меньше, что-то около 1/8 в самом начале обучения.
Замер на RussianSuperGLUE.
Для оценки модели мы использовали бенчмарк для русского языка RussianSuperGLUE.
Вот как сейчас выглядит лидерборд:

Лидерборд RussianSuperGLUE.
На решение Golden Transformer v2.0 не следует ориентироваться при сравнении моделей. Правильно смотреть на строки, где в качестве трейна использовался только сет с RSG и одна языковая модель. Авторы Golden Transformer в своем решении использовали большой оптимизированный ансамбль емких англоязычных моделей, которые были обучены на похожих задачах на английском языке, а также модель для перевода русского текста на английский язык. В общем, это не та история, когда мы из небольшого трейна пытаемся вытащить максимальное количество знаний и на их основе оцениваем возможности языковой модели. Кстати, мы у себя проводили эксперименты по переводу нашего сета на английский и дообучению (fine-tuning) некоторых английских моделей, получив в результате довольно высокие оценки на валидации. Но это тема для отдельного будущего рассказа.
Для дообучения мы использовали тот же код, что и для ruT5. Мы не делали никаких новых правок в сете, о которых писали коллеги из Яндекса. Набор для многозадачного дообучения мы использовали тот же, что и для ruT5. В общем, мы хотели зафиксировать все факторы чтобы выполнить корректное сравнение с ruT5. Если же предпринять дополнительную очистку сетов и потратить силы на оптимизацию гиперпараметров, то, вероятно, можно получить еще более высокую оценку.
Напомню, как мы выполняем оценку модели при помощи RussianSuperGLUE. Сначала модель учится на многозадачном сете в течение 10 эпох. Потом для каждой из задач мы выбираем лучший чекпойнт и дообучаем его на трейн-части сета этой задачи. На многозадачном сете мы использовали Adafactor c постоянным LR = 0,001, а на стадии дообучения в некоторых задачах себя лучше показал AdamW.
Вот такие результаты мы получили для версии модели с 1,7 млрд параметров. FRED-T5 1.7B finetune:
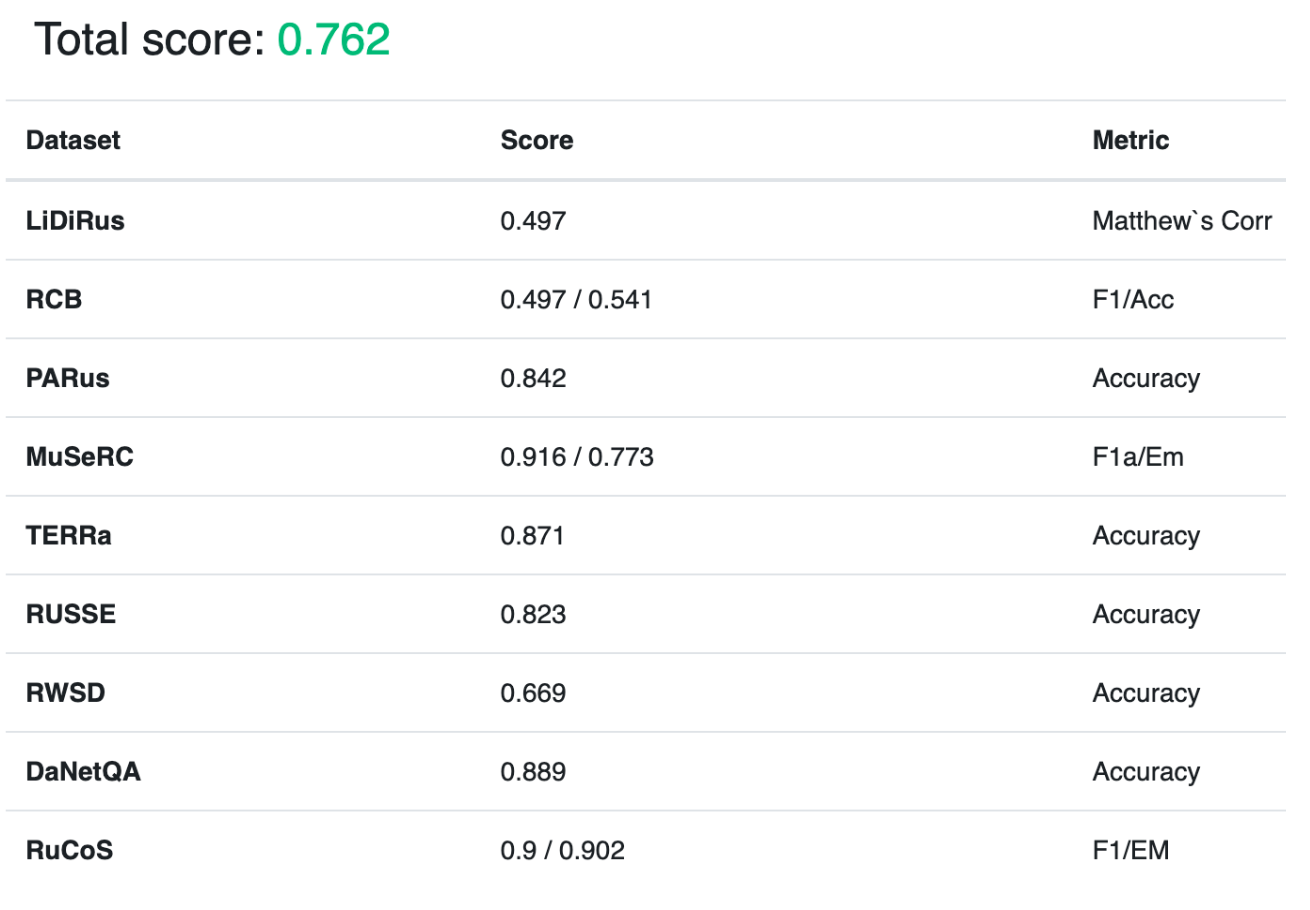
Результаты FRED-T5 1.7B на RSG.
А вот результаты Large-модели. FRED-T5 large finetune:

Результаты FRED-T5 large на RSG.
Надо отметить, что для модели 1.7B для большинства задач лучшим решением оказался лучший чекпойнт со стадии многозадачного обучения. При дообучении на RussianSuperGLUE мы пробовали использовать различные префиксы денойзеров:»
А вот результат 1.7B модели после 2 этапов претрейна, где она видела мало данных:

Результаты FRED-T5 1,7B на RSG после 2-х этапов обучения.
Мы также замерили энкодер от модели 1.7B на RussianSuperGLUE и получили довольно хороший результат FRED-T5 1.7B (only encoder 760M) finetune. Он оказался, к примеру, выше, чем у ruRoBERTa. Да, конечно, емкость этого энкодера более чем в 2 раза больше, чем у ruRoBERTa, но все же результат весьма интересный. Модель от Яндекса RuLeanALBERT, которая имеет 2.9B весов, получила оценку 0,698.
Результаты энкодера от FRED-T5 1,7B на RSG.
А что если дообучить FRED-T5 1.7B с добавлением задачи MLM для энкодера? Вероятно, метрики такого энкодера будут заметно улучшены, по сравнению с базовой версией. Это одно из направлений для наших будущих экспериментов.
Если смотреть на лидерборд, то FRED-T5 1.7B значительно превосходит на задачах RussianSuperGLUE модели, число параметров которых почти в 2 раза больше. А если посмотреть, какой прирост оценки получали модели при увеличении их размера, то одним лишь увеличением числа параметров модели не объяснить значительного прироста оценки модели 1.7B.
3.5Gb is all you need?!
Почти детективная история с зафиксированной частью датасета размером 3.5 Гб, на которых наша модель обучалась в течение весьма продолжительного интервала времени. Модель видела этот фрагмент датасета более 200 раз, что, однако, не привело к ее переобучению. На каждую последовательность токенов из сета у нас делается 7 семплов для каждого денойзера, и модели в таких условиях сложно запомнить весь датасет. Но оказывается, что такого небольшого набора данных вполне достаточно для того, чтобы хорошо решать задачи из набора RussianSuperGLUE. Что же получается, для обучения модели лучше использовать 10 Гб чистых данных вместо 1 Тб грязных?!
Как пользоваться моделями.
Модели доступны на HaggingFace: FRED-T5–1.7B и FRED-T5-large
Все довольно стандартно. Токенизатор — GPT2Tokenizer и модель T5ForConditionalGeneration из HF.
import torch
from transformers import GPT2Tokenizer, T5ForConditionalGeneration
tokenizer = GPT2Tokenizer.from_pretrained('ai-forever/FRED-T5-1.7B',eos_token='')
model = T5ForConditionalGeneration.from_pretrained('ai-forever/FRED-T5-1.7B')
device='cuda'
model.to(device)
#Prefix
lm_text='Принялся Кутузов рассказывать свою историю как он сюда попал. Началось'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True)
print(tokenizer.decode(outputs[0][1:]))
# print result: с того, что он был в армии, служил в артиллерии.
#Prefix
lm_text='Принялся Кутузов рассказывать свою историю . Началось с того, что он был в армии, служил в артиллерии.'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True)
print(tokenizer.decode(outputs[0][1:]))
#print result: ', как он воевал'
# Prefix
lm_text='Принялся Кутузов рассказывать свою историю . Началось с того, что он был в армии, служил в артиллерии.'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True)
print(tokenizer.decode(outputs[0][1:]))
#print result: ', как он стал генералом' 