«Фотошоп» для человеческой речи
3 ноября 2016 года на технологической конференции Adobe MAX компания Adobe представила очень интересную научно-техническую разработку, которая в будущем может превратиться в популярное программное приложение. Если описать изобретение вкратце, то это программа для семантического редактирования человеческой речи. При этом применяется не просто стандартный метод синтеза из собранных фонем (компиляционный синтез), но и вспомогательные методы, которые повышают реалистичность. Это интеллектуальный выбор трифонов и использование специафических характеристик голоса образца.
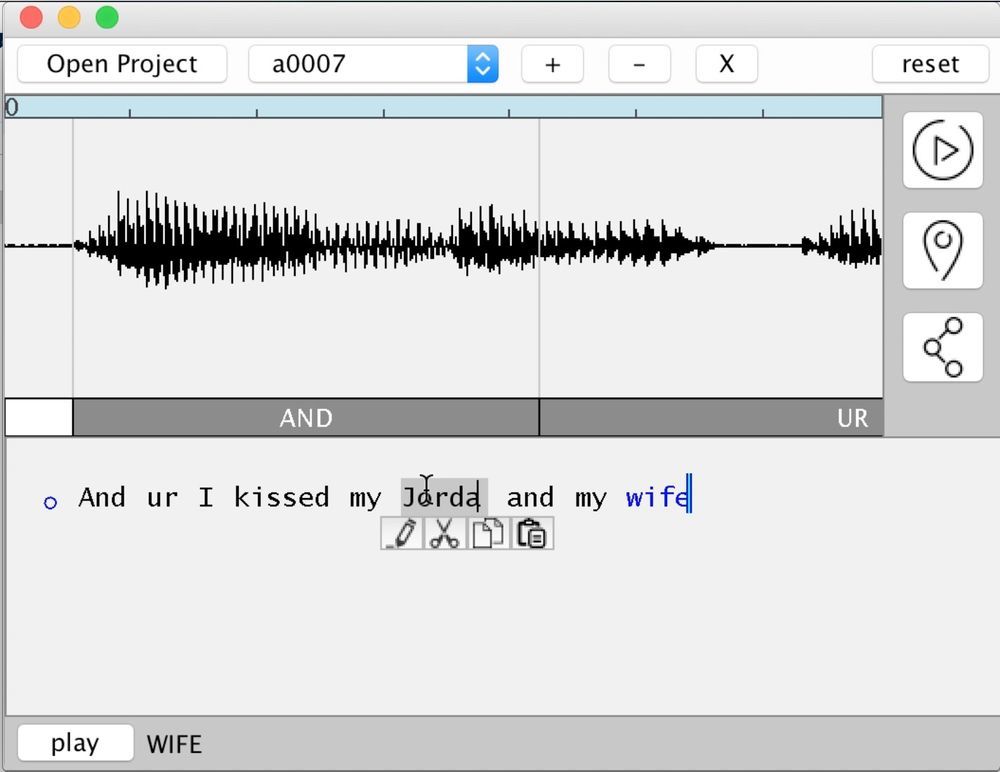
В результате пользователь пишет произвольный текст —, а программа озвучивает его тем голосом, на который её натренировали. Можно быстро добавить в речь любые слова или вырезать ненужные.
На практике программа, представленная в рамках проекта VoCo, работает следующим образом. Сначала собирается база фонем для голоса конкретного человека на определённом языке. Для реалистичных результатов программе нужно минимум 20 минут речи человека. Чем больше — тем лучше. На базе собранных фонем (трифонов) программа затем может собирать словно из кирпичиков практически любые новые слова.
Фрагмент презентации VoCo на конференции MAX
В каком-то смысле работает VoCo напоминает работу контекстной кисти в «Фотошопе». Она тоже берёт фрагменты из разных мест картинки — и собирает из этих фрагментов новое изображение. Кусочек леса с фотографии леса, кусочек травы из другой картинки и девочка с третьей фотографии — и мы получаем совершенно новое фотореалистичное произведение с лесом, травой и девочкой на переднем плане. Если работа выполнена профессионально, то монтаж очень сложно определить. Так в советские времена стирали из истории людей, которые внезапно стали врагами народа. Был человек на фотографии —, а теперь там пустота или другой человек.
Так и технология VoCo позволяет дополнять речь человека произвольными словами и фразами.
На конференции MAX презентацию провёл один из разработчиков Цзэюй Цзинь (Zeyu Jin). В опубликованной ранее научной работе он указан как сотрудник Принстонского университета, вместе с коллегой Адамом Финкельштейном (Adam Finkelstein). Технология разрабатывалась подразделением Adobe Research совместно с Принстонским университетом.
По задумке Adobe, технология поможет создателям контента для более простого редактирования аудидорожки: диалогов и закадрового текста, чтобы быстро исправить ошибку или внести изменения в сюжетную линию.
Adobe подчёркивает, что в данном случае уместнее говорить о «преобразовании голоса», чем о классическом голосовом синтезе. Целью голосового преобразования (voice conversion) является такое преобразование оригинального голоса, чтобы для слушателя он казался голосом другого человека по образцу голоса последнего.
Более подробно технические основы голосового преобразования описаны в вышеупомянутой научной работе, подготовленной совместно с Принстонским университетом. Её авторы показывают, что разработанная техника CUTE качественно превосходит другие методы голосовой конверсии. Альтернативные способы конверсии обычно основаны на параллельном анализе идентичных фраз источника и цели с последующим вычислением неких векторов преобразования в каком-либо адресном пространстве. После этого любой произвольный фрагмент голоса оригинала может быть преобразован с помощью полученных векторов. Но эти методы страдают от неприятных побочных эффектов — синтезированная таким образом речь получается глухой, невнятной.
Исследователям Adobe удалось преодолеть недостатки других техник с помощью гибридного метода CUTE. В названии зашифрованы четыре основные составляющие компоненты этой техники: компиляционный синтез (Concatenative synthesis); выбор единицы (Unit selection); предварительный отбор трифонов, то есть единиц из трёх фонем (Triphone pre-selection); использование свойств образца (Exemplar-based features).
Компиляционный синтез сводится к составлению сообщения из предварительно записанного словаря фонем. Это главный метод работы синтезаторов речи, которыми оснащаются различные устройства: от военных самолётов до бытовых устройств, в справочных службах операторов сотовой связи и др.
Как понятно из названия, разработанная гибридная техника сочетает в себе несколько методов синтеза речи и голосового преобразования.
В научной работе приводятся результаты сравнительных тестов с другими методами голосовой конверсии, в которых CUTE значительно превосходит конкурентов. При этом упоминаются некоторые его недостатки: он также как и все страдает от недостаточного количества фонем в базе при синтезе новых слов, из-за чего генерируются фонетически правильные, но не очень реалистичные результаты. Кроме того, он зависит от работы движка распознавания речи для корректной фонетической сегментации.
Пока неизвестно, собирается ли Adobe реализовать эту перспективную разработку в виде реального коммерческого продукта. Но уже сейчас можно сказать, что такая программа стала бы очень востребованной, при условии реалистичности синтеза голоса из фонем. Например, её могли бы использовать подкастеры для генерации подкастов из текста. Её можно использовать также для озвучивания аудиокниг, используя голос произвольного человека (например, собственной девушки). Такая технология наверняка найдёт применение в Голливуде для озвучки кадров в отсутствие актёра. Например, если с ним разорвали контракт или он умер посреди съёмок.
