Формула доверия
Сегодня мы расскажем об одной из ключевых фишек нашей DLP-системы — уровне доверия. Это показатель, который присваивается каждому человеку в компании и отражает вероятность того, что данный сотрудник окажется нарушителем.
Сейчас в DLP-решениях на первый план выходит аналитика. Пару лет назад все российские вендоры стали понемногу пытаться «разворачивать» DLP-системы от борьбы с утечками в сторону выявления и предотвращения других нелегитимных действий сотрудников — мошенничества, откатов, сговоров и т.п. Однако каждый человек генерирует такое количество информации в день, что отслеживать действия каждого невозможно даже в средних компаниях, не говоря о крупном бизнесе. Поэтому способность системы сделать качественную аналитику в автоматическом режиме и очертить круг лиц «под подозрением» была бы очевидным преимуществом. Так возникла идея создания уровня доверия, основной целью которого была прозрачность ситуации с внутренними угрозами в компании.
Мы хотели, чтобы безопасник мог быстро, без долгого анализа данных DLP-системы, понять, к кому в компании стоит присмотреться повнимательнее. Очень простая и изящная концепция, не так ли? Казалось бы, идея лежит на поверхности. Однако чтобы создать такую формулу доверия, которая не вызывала бы бешеного количества ложных срабатываний, потребовалось проделать серьезную работу и связать в одно целое результаты социальной инженерии, статистики и бизнес-анализа. В этой статье мы расскажем о том, как вывести формальное выражение величины доверия к сотрудникам с точки зрения защиты от умышленной или случайной утечки. Судя по реальной статистике совершающихся инцидентов, формула эта оказалась достаточно точной.
Немного теории
Идея автоматического профилирования персон в системах DLP не просто витает в воздухе, но и часто фигурирует в международных стандартах и рекомендациях по безопасности. А вот ее реализация на сегодняшний день не имеет общепринятой методологии. Естественным путем является построение такого показателя на основе анализа большого объема данных (Big Data). На языке Big Data техники эта проблема относится к управлению репутацией и доверием («Trust and reputation management» [1]).
По своей природе профилирование относится к области поведенческого анализа. С точки зрения бизнес-поведения здесь применяются методы современной психологии, физиологии, социологии [2, 3].
В качестве вычислительного аппарата рассматриваются методы математической статистики, случайных процессов, статистической физики [4–9]. Отдельная ветвь моделей опирается на теорию нейронных сетей [10, 11].
Формула доверия — точность и простота
Консультации с экспертами в области защиты информации от утечки позволили выделить среди теоретических методов наиболее эффективные: социология, математическая статистика, бизнес-анализ. Даже такой набор методов очень обширен, и их верификация весьма трудоемка, несмотря на то, что комбинировать эти методы — занятие увлекательное. Поэтому мы начали с отбора наиболее подходящих для нашей цели методик. Основными критериями при выборе были точность и простота.
Мы решили, что лучшим показателем точности служит то, сколько человек из числа реальных злоумышленников, обнаруженных офицерами безопасности, система смогла автоматически определить в качестве потенциальных нарушителей. Таким образом, мы сравнивали результаты работы офицера безопасности и расчеты разных методик.
Второй критерий — простота — отвечает за то, чтобы в модели уровня доверия отсутствовали избыточные переменные (факторы). Дело в том, что каждый дополнительный фактор вносит неопределенность, вследствие этого теряется прозрачность результата. Иными словами, если уровень доверия, присвоенный человеку, резко изменится, безопаснику будет труднее понять, чем вызваны эти изменения. Это бы свело на нет наши усилия по достижению главной цели — сделать данные DLP-аналитики максимально наглядными и прозрачными для пользователя.
Согласно этим критериям был принят оптимальный алгоритм, заложенный впоследствии в DLP-систему.
Исходные данные
Мы располагаем очень обширным массивом данных по реальным инцидентам безопасности. В ходе каждого внедрения и пилотного проекта создаются отчеты по событиям и инцидентам. Эти отчеты также содержат информацию о нарушителях — кадровые сведения, список событий, связанных с этим сотрудником, признаки для занесения человека в группу повышенного риска.
В качестве реальных данных выступали данные инцидентов по 8-ми отраслям:
- промышленность,
- IT&Telecom,
- государственные органы,
- энергетика,
- банки,
- нефтегазовая отрасль,
- торговля и услуги,
- транспорт.
В расчет также были приняты некоторые измеримые факторы, в том числе:
- объем переписки;
- количество событий и инцидентов ИБ;
- распределение событий по группам персон особого контроля;
- распределение сообщений по каналам коммуникации;
- распределение событий по уровням критичности;
- персоны, попавшие в отчет проведения пилотов или внедрений — реальные участники инцидентов безопасности;
- и другие.
В итоге мы выбрали три инструмента для создания формулы доверия — статистика, социология, специфика бизнеса. Эти три «С» должны были обеспечить нам трехмерное видение активности сотрудников.
«С» №1 — Статистика
В качестве статистического инструмента мы выбрали традиционную модель авторегрессии с ошибкой в виде белого шума. Такая модель позволяет подобрать лучшую линию (закон) на графике зависимости учитываемых факторов. Эта модель показала хороший результат на ряде подобных задач.
Факторный анализ мы начали со сравнения объема переписки персоны и числа событий, обнаруженных в этой переписке. Полагая, что события линейно зависят от объема переписки, мы получим такой закон зависимости событий от числа сообщений:

График функции зависимости обозначен пунктиром по причине того, что в некотором смысле «точность» этого закона (величина R2) недостаточна, чтобы считать этот закон сколь-нибудь приемлемым для всех персон. Обычно для критериев точности мы принимаем нижний порог этой величины в 0,8.
Следующим шагом, который позволяет сделать статистика, стало «слепое» разделение персон по группам. Разделение дихотомическое — делим все персоны на 2 группы, и, если точность модели становится достаточной, принимаем такое разбиение. В противном случае, делим каждую подгруппу еще на 2 и так далее. На практике достаточно 1–2 итераций.
Статистическое деление на группы персон уже на первой итерации дало убедительную «точность» — более 90%. Естественно, отдельно решается вопрос достаточности объема выборки для такого вывода.
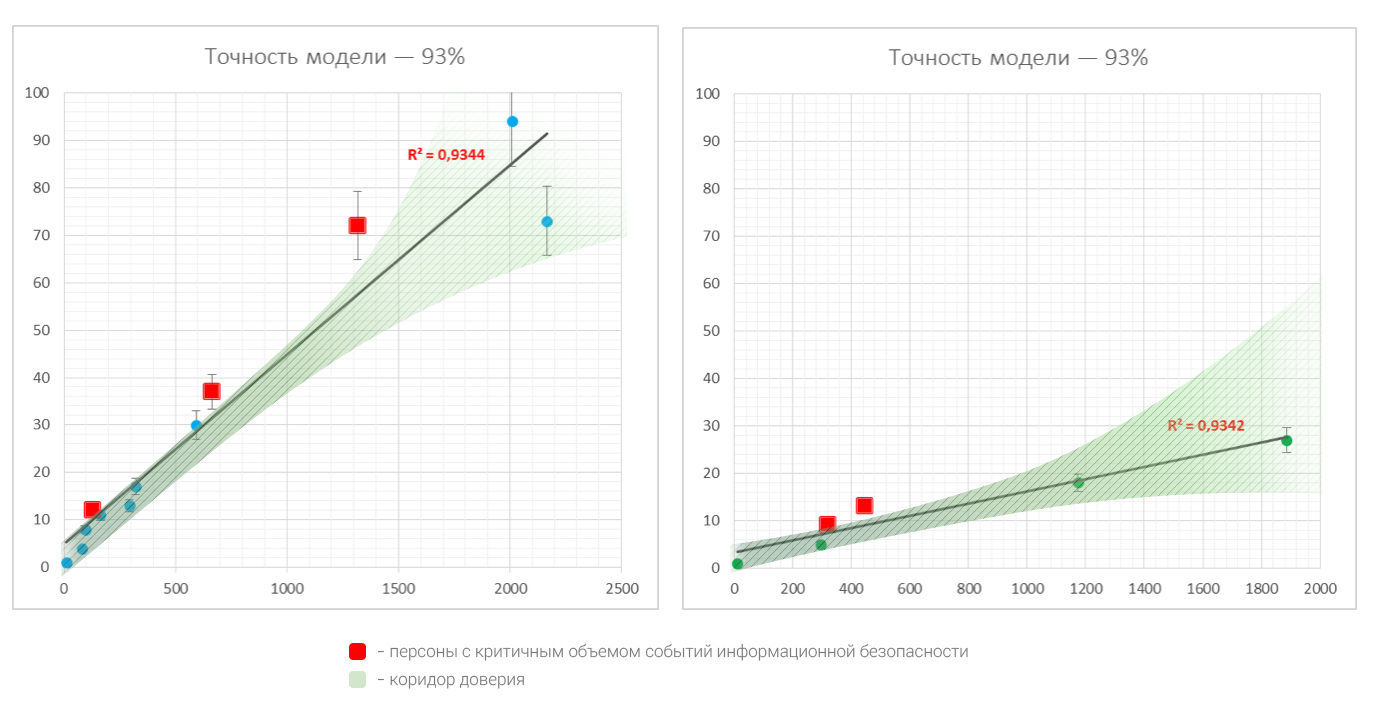
При достаточно хорошей выборке, линия регрессии (закон зависимости) может применяться как прогноз для любой персоны. И отклонения персон от этого закона можно с точки зрения статистики относить к аномалиям.
Все бы хорошо, но статистика, не подкрепленная бизнес-смыслом, зачастую дает неадекватные реальному положению дел результаты.
«С» №2 — Социология
На третьем этапе мы несколько скорректировали нашу модель. Нам необходимо было понять, что связывает персон внутри каждой статистически выделенной группы. Поэтому возникла необходимость поиска особенностей, согласующихся со статистическим разбиением. Для этого мы воспользовались методами социологии и бизнес-анализа.
Мониторинг социологических исследований и практическая их оценка дали такие варианты категорий персон:
- халатные пользователи;
- осторожные пользователи;
- продвинутые пользователи;
Каждая группа имеет свою схему поведения, которой люди невольно придерживаются. При этом на базе каждой схемы поведения можно построить определенные предиктивные модели угроз. Например, действия пользователей, халатно относящихся к передаче и хранению данных, будут нести с собой более высокий риск случайной компрометации информации, причем вне зависимости от канала коммуникации. Осторожные пользователи, напротив, скорее являются источником угроз намеренного характера. Их активность обычно затрагивает каналы коммуникаций, не описанные в корпоративных правилах.
Продвинутые пользователи хорошо знакомы с IT-инфраструктурой и особенно продвинуты в модификации, подмене данных. Для этой группы требуется особый контроль рабочих станций и используемых программ на уровне ядра ОС. Интерес представляют также коммуникации продвинутых пользователей и халатных пользователей, так как первые могут воспользоваться недостаточной ИБ-компетентностью вторых. В группе продвинутых пользователей распространены инциденты, связанные с кибербезопасностью, лавинные события, события, связанные с корпоративными системами документооборота и базами данных.
«С» №3 — Специфика бизнеса
Касаясь бизнес-факторов, особенно важно определить степень детализации, чтобы избежать неэффективного усложнения модели.
Конечно, в идеальном случае у офицера безопасности имеются схемы бизнес-процессов, в которые вовлечены коммерчески важные данные. В реальности такое встречается крайне редко.
В этих ситуациях выручает возможность систем DLP определять в информационном потоке виды документов и визуализировать их перемещение. При этом даже на небольшом периоде наблюдения накопленные сведения дают наглядную картину того, как в рамках тех или иных процессов перемещаются данные. Мы выделили несколько групп сотрудников, в их числе:
- лица, согласующие документы;
- лица, имеющие привилегированные права доступа;
- сотрудники, несущие материальную ответственность,
- и некоторые другие.
С точки зрения трудовых особенностей можно выделять персон в следующие группы:
- сотрудники на аутсорсинге, подрядчики;
- бизнес-активные пользователи;
- сотрудники, находящиеся на испытательном сроке или, напротив, увольняющиеся.
Все эти группы имеют определенные особенности работы с информацией, и соответственно требуют раздельного контроля. Так, сотрудники на аутсорсинге и бизнес-активные пользователи отличаются не только объемом генерируемых событий ИБ, но и каналами коммуникации.
Особым положением пользуется группа материально ответственных сотрудников. Для них характерно преобладание событий, связанных с экономическими событиями безопасности. В сфере учета обычно используется некоторый отраслевой workflow, который можно успешно учитывать правилами политик автоматизированной системы DLP.
Итоговая формула уровня доверия
В ходе оценки различных моделей уровня доверия стало ясно, что он должен зависеть от:
- количества событий;
- группы риска, в которые входят источники и отправители сообщений;
- распределения событий по уровням критичности — от низкого к высокому
Таким образом, уровень доверия — это вещественнозначная ограниченная функция. Можно формально определить ее так:

где S — количество событий, GRn — распределение событий на множестве групп риска, n — размерность GRn, DK — распределение событий на множестве уровней критичности, K — число уровней критичности (в нашем случае K=5), t — рассматриваемый момент времени.
С помощью модели, учитывающей эти факторы, мы смогли автоматически определить более 60% от общего числа нарушителей, независимо выявленных офицерами безопасности в ходе расследований и разборов инцидентов.
Такой результат стал весомым аргументом для того, чтобы на практике реализовать в DLP-решении динамический уровень доверия.
Заключение
Несмотря на то, что сейчас уровень доверия успешно работает и является одним из ключевых элементов аналитики в нашей DLP-системе, мы постоянно работаем над усовершенствованием формулы. Возможно, когда-нибудь в будущем сможем написать продолжение этой статьи под названием «Как мы сделали формулу доверия точнее в несколько раз».
Вероятнее всего, в развитии технологии поможет и конкуренция. Пока мы одни из DLP-вендоров всерьез играем на этом поле, однако, как уже говорилось в начале статьи, поведенческий анализ сейчас в тренде, так что наверняка скоро в эту сторону массово начнут смотреть и другие отечественные разработчики.
Источники
- Omar Hasan, Benjamin Habegger, Lionel Brunie, Nadia Bennani, Ernesto Damiani. University of Lyon, Department of Computer Technology, University of Milan. A Discussion of Privacy Challenges in User Profiling with Big Data Techniques: The EEXCESS Use Case.
- George W. Fairweather, Louis G. Tornatzky. Experimental Methods for Social Policy Research.
- Long Jin, Yang Chen, Tianyi Wang, Pan Hui, Athanasios V. Vasilakos. Understanding User Behavior in Online Social Networks: A Survey // IEEE Communications Magazine September 2013.
- Lanouar Charfeddine Wadie Nasri. The Behavior Intention of Tunisian Banks» Customers on using Internet Banking // International Journal of Innovation in the Digital Economy, 4(1), 16–30, January-March 2013.
- Gunjan Mansingh & Lila Rao & Kweku-Muata Osei-Bryson & Annette Mills. Profiling internet banking users: A knowledge discovery in data mining process model based approach // Springer Science+Business Media New York 2013.
- Rathindra Sarathy, Krishnamurty! Muralidhar. Evaluating Laplace Noise Addition to Satisfy Differential Privacy for Numeric Data // TRANSACTIONS ON DATA PRIVACY 4 (2011) 1 —17.
- Chang-Moo Lee. Criminal profiling and industrial security // Springer Science+Business Media New York 2014.
- Yanli Yu, Keqiu Li, Wanlei Zhou, Ping Li. Trust mechanisms in wireless sensor networks: Attack analysis and countermeasures // Journal of Network and Computer Applications 35 (2012) 867–880.
- W.T. Luke Teacya, Michael Luckb, Alex Rogersa, Nicholas R. Jenningsa. An Efficient and Versatile Approach to Trust and Reputation using Hierarchical Bayesian Modelling.
- Weihua Song, Vir V. Phoha. Neural Network-Based Reputation Model in a Distributed System // Proceedings of the IEEE International Conference on E-Commerce Technology.
- Bo Zong, Feng Xu, Jun Jiao and Jian Lv. A Broker-Assisting Trust and Reputation System Based on Artificial Neural Network // Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics.
