Финансовые данные: об измерении автокорреляции, тяжелых хвостах и других статистиках (Vol 1)
*Be aware: впереди математика. **Первая часть дискуссии о распределениях финансовых данных, подводных камнях при работе с ними и возможных решениях при оценке сопутствующих статистик.
Данная статья представляет собой первую (из трех) часть дискуссии о распределении финансовых данных и работе с ними. В этой части мы подробно обсудим с математической точки зрения некоторые подводные камни, возникающие при работе с финансовыми данными, а также (не-)применимость классических статистических методов при работе с ними. Во второй части статьи мы поговорим о возможных решениях трудностей, описанных в данной части. Наконец, в третьей части мы представим возможные реализации подхода, описанного во второй части, на языке Python, а также поговорим о примерах и применениях описанной методологии.
Короткое введение
Предположим, вы работаете с финансовыми данными; чаще всего (когда говорят о работе с финансовыми данными) — это доходности некоторого актива. Воспользуемся классическим определением доходности актива  в момент времени
в момент времени  :
:

где  — цена актива момент времени
— цена актива момент времени  . В качестве актива может выступать золото, нефть, Bitcoin и др.
. В качестве актива может выступать золото, нефть, Bitcoin и др.
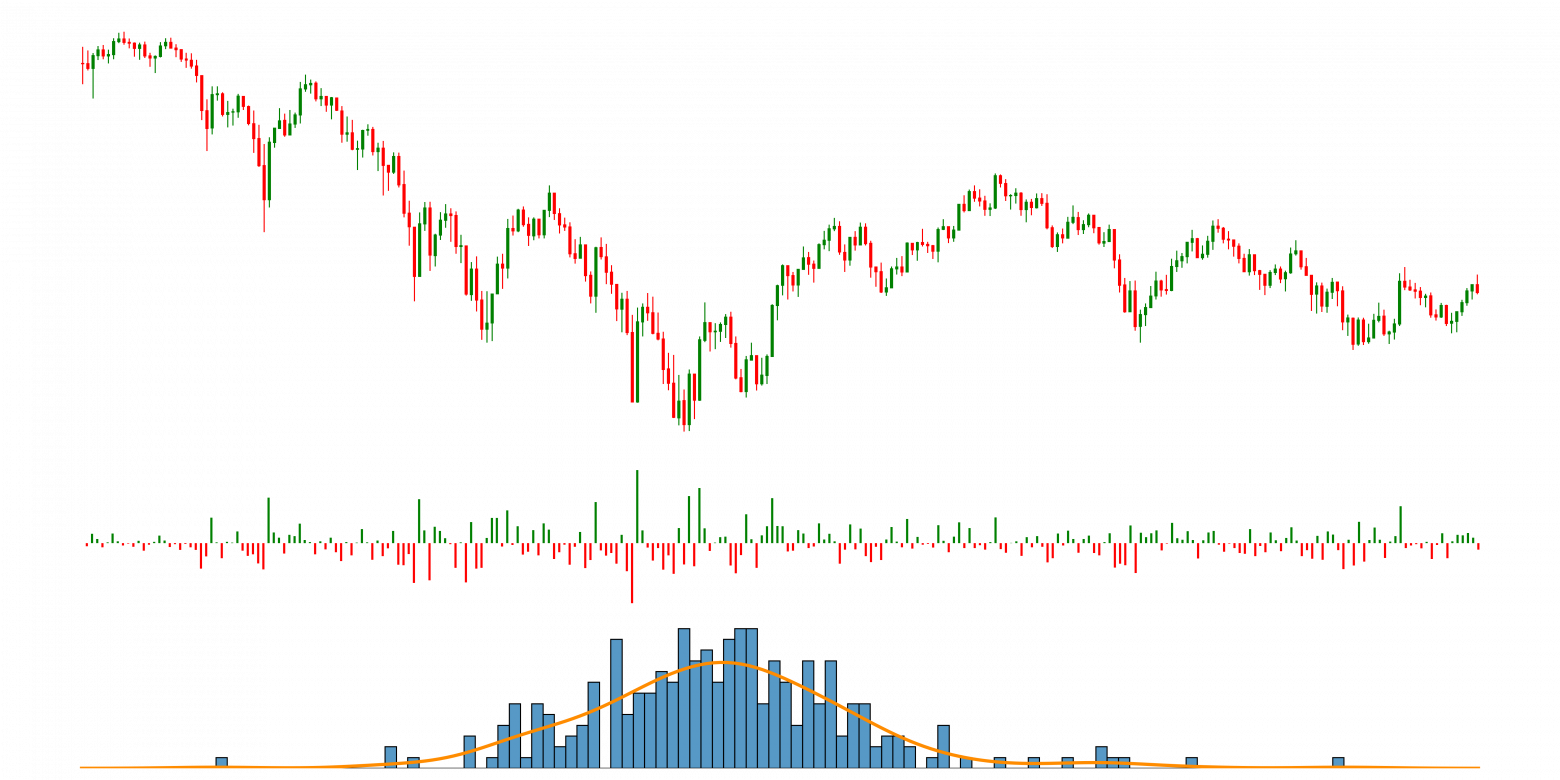
 об изменении цены Bitcoin (2) Доходности
об изменении цены Bitcoin (2) Доходности  , вычисленные по данным об изменении цены (3) Распределение доходностей
, вычисленные по данным об изменении цены (3) Распределение доходностейИнтересно, какими свойствами обладает временной ряд  ? В литературе эмпирические свойства, характерные для доходностей финансовых активов
? В литературе эмпирические свойства, характерные для доходностей финансовых активов обычно называют ситилизованными фактами и выделяют следующие ключевые из них:
обычно называют ситилизованными фактами и выделяют следующие ключевые из них:
[Гипотеза эффективного рынка] Отсутствие линейных зависимостей и автокорреляций:

[Нелинейные зависимости] Присутствие нелинейных зависимостей и кластеризация волатильности, которая обычно описывается высокой корреляцией нелинейных функций
 :
: 
[Тяжелохвостность] Тяжелые хвосты распределения:
 — слабо меняющаяся на бесконечности функция, а
— слабо меняющаяся на бесконечности функция, а  — хвостовой индекс.
— хвостовой индекс.
Задача. Допустим, вы получаете выборку
доходностей некотрого актива за промежуток времни
. По этим данным вы хотите оценить, насколько эффективен рынок на данном временном интервале, а также «измерить» кластеризацию волатильности.
Если вы будете использовать классический подход, то вы, скорее всего, захотите вычислить выборочную корреляцию (для  и
и  ), а затем, используя нормальность предельного распределения, построить статистическую оценку / протестировать гипотезу / построить доверительный интервал.
), а затем, используя нормальность предельного распределения, построить статистическую оценку / протестировать гипотезу / построить доверительный интервал.
Однако надежен ли такой подход в условиях распределения с тяжелыми хвостами? В этой части статьи мы с вами подробно в этом разберемся!
Проблемы классических подходов при работе с «тяжелохвостными» данными
В данной секции мы увидим, что выборочные автоковариация и автокорреляция имеют нестандартные статистические свойства, которые делают классические подходы по выявлению и измерению зависимостей из пунктов 1. и 2. выше ненадежными и плохо применимыми
Проблема моментов распределения доходностей
Рассмотрим свойство 3. доходностей из стилизованных фактов (тяжелохвостность). Удобно считать, что есть некоторая нижняя граница  , начиная с которой выполняется степенной закон, тогда распределение
, начиная с которой выполняется степенной закон, тогда распределение  описывается законом Парето. Напомним, что распределения Парето имеют следующие функции распределения и плотности:
описывается законом Парето. Напомним, что распределения Парето имеют следующие функции распределения и плотности:

В таком случае моменты  задаются следующими равенствами:
задаются следующими равенствами:
 определена только при
определена только при  определена при
определена при  , в то время как для развивающихся рынков
, в то время как для развивающихся рынков  .
.
Вывод 1: Тяжелые хвосты распределения доходностей делают классические статистики ненадежными, поскольку многие моменты (а иногда даже и первый) не определены в данном случае.
Проблема сходимости выборочных автокорреляций
В работе Davis and Mikosh 1998 получены результаты о сходимости функций выборочных автоковариаций и автокорреляций для  -правильно меняющихся случайных процессов. В данной секции мы рассмотрим несколько случаев сходимости выборочных автоковариаций и автокорреляций для процесса
-правильно меняющихся случайных процессов. В данной секции мы рассмотрим несколько случаев сходимости выборочных автоковариаций и автокорреляций для процесса (который, согласно третьему из стилизованных фактов, описывается уравнением
(который, согласно третьему из стилизованных фактов, описывается уравнением  .
.
Прежде чем перейти непосредственно к описанию сходимостей, определим выборочные функции автоковариации и автокорреляции:
Определение: Для стационарного процесса
выборочной функцией автоковариации называется функция:
;
Определение: Для стационарного процесса
выборочной функцией автокорреляции называется функция:
.
Рассмотрим сходимости данных функций для различных  :
:
 . Тогда имеют место следующие сходимости:
. Тогда имеют место следующие сходимости: ![\left[ n^{1 - \frac{2}{\zeta}} \gamma_{n, X}(h) \right]{m=1,\dots,m} \stackrel{d}{\longrightarrow} \left[ V_h \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/f6f/3cd/6bc/f6f3cd6bc1d5a6d52e921e1fc05ae13c.svg)
![\left[ n^{1 - \frac{2}{\zeta}} \rho_{n, X}(h) \right]{m=1,\dots,m} \stackrel{d}{\longrightarrow} \left[ \frac{V_h}{V_0} \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/de4/7f7/297/de47f729703cef9dfb616e5be9a8dfd7.svg)
и случайный вектор
![\left[ V_h \right]_{m=1,\dots,m} = (V_1, \dots, V_m)](https://habrastorage.org/getpro/habr/upload_files/de0/112/95b/de011295b91b1703870d216e08f3a4c5.svg) является
является  -устойчивым.
-устойчивым. . Тогда имеют место следующие сходимости:
. Тогда имеют место следующие сходимости: ![\left[ n^{1 - \frac{2}{\zeta}} \gamma_{n, X}(h) \right]{m=1,\dots,m} \stackrel{d}{\longrightarrow} \left[ V_h \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/a3b/c94/d59/a3bc94d59097c208a4d70a9b592d7174.svg)
![\left[ n^{1 - \frac{2}{\zeta}} \rho_{n, X}(h) \right]_{m=1,\dots,m} \stackrel{d}{\longrightarrow} \gamma^{-1}X(0) \left[ V_h \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/0a3/bfd/599/0a3bfd59965cde9baa66041790c7c9d1.svg)
и случайный вектор
![\left[ V_h \right]_{m=1,\dots,m} = (V_1, \dots, V_m)](https://habrastorage.org/getpro/habr/upload_files/5ce/a24/d43/5cea24d431b024afea5694dd112d477d.svg) является
является  устойчивым.
устойчивым. . Тогда имеют место следующие сходимости:
. Тогда имеют место следующие сходимости: ![\left[ \sqrt{n} \gamma_{n, X}(h) \right]{m=1,\dots,m} \stackrel{d}{\longrightarrow} \left[ G_h \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/834/3cd/2c7/8343cd2c7bd3b2b7a0e8fbd2338939f2.svg)
![\left[ \sqrt{n} \rho_{n, X}(h) \right]_{m=1,\dots,m} \stackrel{d}{\longrightarrow} \gamma^{-1}X(0) \left[ G_h \right]{m=1,\dots,m}](https://habrastorage.org/getpro/habr/upload_files/688/e1f/46e/688e1f46eac433f69bf35c0e8c81d7fc.svg)
и случайный вектор
![\left[ G_h \right]_{m=1,\dots,m} = (G_1, \dots, G_m)](https://habrastorage.org/getpro/habr/upload_files/30b/a5d/f49/30ba5df49357df0a20bfb69a847d48bf.svg) имеет многомерное нормальное распределение.
имеет многомерное нормальное распределение.
Из соотношений выше видно, что предельное распределение выборочных автоковариаций имеет форму нормального только при  же предельное распределение устойчиво с параметром
же предельное распределение устойчиво с параметром  (в первом случае с
(в первом случае с  ), это же в свою очередь означает (по свойству устойчивых распределений), что у предельного распределения не определен второй момент (а значит и дисперсия), а в первом случае не определен даже первый момент. Это расширяет границы доверительного интервала. Также важно отметить, что в 1 и 2 случаях скорость сходимости существенно медленнее, чем
), это же в свою очередь означает (по свойству устойчивых распределений), что у предельного распределения не определен второй момент (а значит и дисперсия), а в первом случае не определен даже первый момент. Это расширяет границы доверительного интервала. Также важно отметить, что в 1 и 2 случаях скорость сходимости существенно медленнее, чем  .
.
Вывод 2: Выборочные автоковариации и автокорреляции не всегда сходятся к нормальному распределению, а также скорость сходимости часто (в зависимости от хвостового индекса
) медленнее
.
В первой части дискуссии мы убедились, что классические подходы оценки статистик распределения доходностей часто неприменимы из-за наличия тяжелых хвостов распределения. Этот факт наталкивает на дальнейшие размышления о поиске замены классического подхода на более устойчивый и эффективный. Такой подход существует и мы поговорим о нем в следующей части статьи. Во многом дальнейшая дискуссия будет опираться на результаты, полученные в работе Ibragimov et al. 2021.
Спасибо за прочтение!
