[Перевод] Почему текст в нижнем регистре сжимается лучше
Буквы в нижнем и верхнем регистре содержат одинаковое количество данных — по 1 байту каждая, поэтому удивительно, что замена заглавных букв на строчные снижает объём данных.
Пример: я взял главную страницу Hacker News и переписал заголовок каждой статьи, капитализировав только первые буквы в предложениях (sentence case) вместо первых букв во всех словах (title case). Это позволило мне снизить размер на 31 байт.
Sentence case: The cat sat on the mat
Title case: The Cat Sat on the Mat
Как может замена нескольких заглавных букв на строчные снижать объём? Всё дело в сжатии.
Это непривычно, но если понять, как работает сжатие текста, то начинает выглядеть логичным.
В этой статье я постараюсь…
помочь вам понять, как работает сжатие текста на примерах (в оригинале статьи они интерактивные)
показать, как я пришёл к выводу о том, что
title caseна сайте Hacker News приводит к выбросам углекислого газа, эквивалентного выбросам автомобиля, проехавшего Шри-Ланку по ширине с востока на западпродемонстрировать примеры того, где это знание можно использовать для систематической экономии объёмов данных.
Почему строчные буквы экономят объём данных?
Сжатие текста эффективнее, когда…
вариативность символов в тексте меньше
наименее распространённые символы используются менее часто
символы или группы символов чаще повторяются.
Замена заглавных букв на чаще встречающиеся строчные помогает по всем трём пунктам.
Чтобы понять, почему это работает, нужно разобраться, как работает сжатие.
Как работает сжатие текста?
Чтобы объяснить, как работает сжатие текста, мы рассмотрим алгоритм deflate, применяемый в файлах zip. Для других алгоритмов принципы будут такими же.
Deflate использует два метода сжатия, код Хаффмана и LZSS; на оба этих метода влияет замена заглавных букв строчными.
Код Хаффмана
Алгоритм deflate начинает свою работу с кода Хаффмана.
Каждый символ в несжатом тексте занимает одинаковый объём данных. (Это не совсем правда, но для нашего объяснения достаточно.)
В utf-8 это 8 битов. (Бит — это двоичная 1 или 0)
Текстовый файл, в котором используется utf-8, кодирует буквы следующим образом:
B — это 01000010
b — это 01100010
a — это 01100001
o — это 01101111
Теперь возьмём слово, в котором используются только эти четыре символа, например, Baobab.
При помощи utf-8 текст Baobab кодируется так: 010000100110000101101111011000100110000101100010.
Если мы знаем, что нам не понадобятся никакие другие буквы, то сможем сэкономить много данных, заменив кодировку так, чтобы она использовала меньше битов.
Можно заменить B на 10, b на 11, a на 00, а o на 01.
Текст Baobab сожмётся в 100001110011.
Слово Baobab содержит четыре уникальных символа, так что мы можем описать их минимум последовательностью из 2 битов.
Но если бы мы сделали B строчной, то нам понадобилось только три уникальных символа и мы могли бы улучшить кодирование.
Можно изменить кодирование так, чтобы наиболее часто используемый символ, то есть b, описывался только 1 битом. При этом сжатая версия baobab уменьшилась бы до 101001011
Мы сделали это при помощи кода Хаффмана.
Применяя код Хаффмана, мы можем описать самые часто используемые символы меньшим количеством битов.
Вот пример того, как это работает (в оригинале статьи можно вводить код, наблюдая за его несжатым и сжатым двоичным видом).
Входной текст: Baobab
Двоичный код без сжатия: 010000100110000101101111011000100110000101100010
Всего 6 байтов
Сжатый кодом Хаффмана: 100111010110
Всего 1 байт и 4 бита
Для сжатия текста при помощи кода Хаффмана нам сначала нужно создать таблицу частотности всех символов текста. Для этого мы…
подсчитываем количество вхождений каждого символа
упорядочиваем эти значения по частоте.
Входной текст для генерации таблицы частотности: Baobab
b — 2
a — 2
o — 1
B — 1
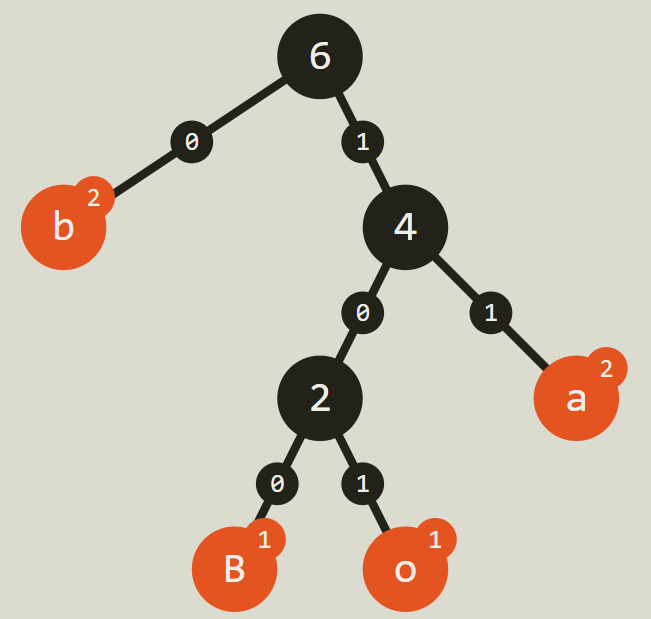
Далее мы строим дерево Хаффмана по следующим правилам:
Делаем каждый символ
листомдерева.Берём два символа с наименьшей частотностью и соединяем их узлом, присваивая таким образом этому узлу суммарную частотность обоих листьев.
Удаляем эти два листа из списка, вместо них добавляя в список соединяющий из узел.
Повторяем описанный выше процесс, пока в списке больше не останется листьев или узлов.
Процесс немного сложен, но закончив, мы получим примерно вот такую красивую диаграмму:
Входной текст для генерации дерева Хаффмана: Baobab

Входные единицы и нули для декодирования дерева Хаффмана: 100111010110
Декодированный вывод: Baobab
Мы можем использовать приведённое выше дерево для создания новой кодировки каждого из наших символов.
Чтобы определить кодировку каждого из символов, мы начинаем с вершины дерева и спускаемся к нужному символу. Каждый раз, когда мы при спуске сдвигаемся влево, добавляем 0, а когда вправо — добавляем 1.
Символы, чаще встречающиеся в тексте, требуют более короткого спуска вниз, поэтому их можно закодировать меньшим количеством единиц и нулей.
Чем меньше дерево, тем больше экономии
Мы не можем декодировать код Хаффмана без дерева. Поэтому при отправке текста, сжатого кодом Хаффмана, мы отправляем вместе с ним и дерево.
Используя в тексте меньшее количество заглавных букв, мы увеличиваем вероятность того, что нам не встретится конкретная заглавная буква. Это значит, что и отправляемое дерево тоже будет меньше.
Например, если мы переведём текст «Decompression is the Mission of the Compression Commission» из title case в sentence case , то нам не понадобятся в дереве листья для заглавных M and C. Это повышает эффективность сжатия, но в то же время и уменьшает дерево Хаффмана.
LZSS
Deflate также использует другой метод сжатия. Он сжимает данные кодом Хаффмана, а затем использует алгоритм Lempel-Ziv-Storer-Szymanski (LZSS).
LZSS находит повторяющиеся блоки данных и заменяет их на более короткую ссылку на место, где они встретились впервые.
Ссылка реализуется заменой повторяющейся последовательности указателем. Этот указатель состоит из двух чисел:
первое число сообщает, насколько далеко нужно вернуться назад, чтобы найти исходную последовательность
второе число сообщает длину исходной последовательности
Вот упрощённый пример работы алгоритма LZSS, в нём указатели обозначены как <1,2> (в оригинале статьи пример интерактивен).
Входной текст для кодирования при помощи LZSS: baobaba
Закодированный при помощи lzss: baoba<3,3> (7 байтов)
Какой объём данных может сэкономить нижний регистр?
Прежде чем начинать преобразовывать всё в нижний регистр, стоит вспомнить, что существует гораздо более объёмный онлайн-мусор, в том числе неоптимизированные изображения, видео с автовоспроизведением, неиспользуемый JavaScript. Сначала избавьтесь от них!
Как бы то ни было, преобразование в нижний регистр на удивление эффективно. Вот пример:
Замена title case на sentence case на сайте Hacker News
Как говорилось во введении к статье, я взял главную страницу Hacker News и переписал заголовок каждой статьи в sentence case вместо title case.
Каждый файл html имел одинаковое количество символов, но при сжатии в файл zip файл с title case имел размер 5992 байта, а файл в sentence case — 5961 байт. Мы сэкономили 31 байт!
Возможно, это не так уж много, но у такой замены есть и приятный побочный эффект — заголовки становится проще читать.
Воспользовавшись формулой с sustainablewebdesign.org, мы получим, что каждое посещение страницы Hacker News, написанной в sentence case, позволит сэкономить 0,00001059642 г углекислого газа.
Считая, что ежедневно выполняется примерно 10 миллионов1 просмотров Hacker News, то перейдя на sentence case, мы бы экономили ежедневно 105 г углекислого газа. Это эквивалент сжигания 16,3 литров бензина в год2. Этого количества топлива достаточно, чтобы проехать на Mini Cooper 221,4 км3, а это примерно ширина Шри-Ланки с востока на запад.
[1. Комментарий модератора Hacker News dang]
[2. Выбросы парниковых газов стандартного легкового транспорта — EPA]
[3. Лучшие и худшие по экономии топлива автомобили 2024 года — fueleconomy.gov]
Я выбрал Hacker News только потому, что этот сайт невелик и в основном состоит из текста. Вероятно, это наименее активно выбрасывающий углекислый газ сайт в мире, если учесть его популярность. А ещё мне не нравится, что все заголовки там написаны в title case.
Систематическое преобразование нечувствительного к регистру кода в нижний регистр
Некоторые минификаторы автоматически преобразуют часть кода в нижний регистр, чтобы сэкономить несколько байтов после сжатия, но это бывает не так часто и используется не повсеместно.
Минификаторы — это инструменты, снижающие размер файла кода, не меняя работу кода.
По отдельности каждая из выполняемых минификатором оптимизаций, вероятно, слишком мала, чтобы о ней заботиться, но суммарно они экономят большой объём данных, что ускоряет веб-сайты и делает их менее энергозатратными.
Например, многие файлы html начинаются с объявления doctype в верхнем регистре:
но в спецификации HTML5 говорится, то оно нечувствительно к регистру, поэтому минификатор html может сэкономить немного данных, поменяв объявление на такое:
Такие оптимизации реализованы html-minifier, но не в других минификаторах.
Некоторые примеры кода, который можно преобразовать в нижний регистр
Существует множество примеров кода, который для экономии данных можно преобразовать в нижний регистр. Вот несколько примеров распространённого использования верхнего регистра там, где это необязательно.
шестнадцатеричные значения цветов
* {color:#ABCDEF}* {color:#abcdef}кодировки символов
экспоненты JavaScript
const trillion = 10E12const trillion = 10e12атрибуты lang