Факторизация чисел и методы решета, часть I

В работе рассматривается традиционный подход, который автором в ряде статей критикуется.
Здесь я воздержусь от критики, и направлю свои усилия на разъяснение сложных моментов в традиционном подходе. Весь арсенал существующих методов не решает задачу факторизации в принципе, так как почти все решеточные и другие алгоритмы построены на жесткой связи и зависимости времени их выполнения от разрядности факторизуемого числа N. Но замечу, что у чисел имеются и другие свойства кроме разрядности, которые можно использовать в алгоритмах факторизации.
Оценки сложности — эвристические опираются на рассуждения ограниченные авторским пониманием проблемы. Пора бы уже понять, что факторизация чисел в глубоком тупике, а математикам (не только им) пересмотреть свое отношение к проблеме и создать новые модели.
Простая идея факторизации целого нечетного числа N исторически — состоит в поиске пары квадратов чисел разной четности, разность которых кратна kN, при k =1 разложение успешно реализуется так как в этом случае сразу получаем произведение двух скобок  c сомножителями N. При k>1 случаются тривиальные разложения.
c сомножителями N. При k>1 случаются тривиальные разложения.
Таким образом, проблема факторизации преобразуется в проблему поиска подходящих квадратов чисел. Понимали эти факты многие математики, но П. Ферма первым в 1643 году реализовал идею поиска таких квадратов в алгоритме, названном его именем. Перепишем иначе приведенное соотношение  .
.
Если разность слева от равенства не равна квадрату, то изменяя х, можно подобрать другой квадрат, чтобы и справа получался квадрат. Практически все нынешние алгоритмы используют эту идею (поиска пары квадратов), но судя по результатам, похоже, что идея себя исчерпала.
Предпосылки и возможности
Криптография с открытым ключом (асимметрические криптосистемы) ныне стала уже повседневностью, хотя совсем небольшой временной период (в историческом плане) отделяет нас от момента ее открытия. К основным ее отличиям от симметричной криптографии следует в первую очередь отнести возможность использования для передачи (шифрованных текстов (ШТ), других сообщений) незащищенных каналов в сетях информационного обмена, цифровую подпись, аутентификацию.
Математической основой этих фактов и явлений служат:
— односторонняя (однонаправленная) функция;
— односторонняя функция с лазейкой (с секретом).
Определение. Функция f: X → Y называется односторонней, если существует эффективный алгоритм ее вычисления при любом Х, но не существует такого алгоритма для вычисления обратной к ней функции.
Определение. Функция f: X → Y называется односторонней с секретом (с лазейкой, потайным ходом, trapdoor), если при наличии некоторой дополнительной информации (ключа) возможен эффективный алгоритм ее обращения. Под эффективным алгоритмом понимают полиномиальный в отличие от экспоненциального.
Математикам давно знакома проблема факторизации и они ищут пути ее эффективного решения. К основным достижениям (результатам) математики в области факторизации чисел следует отнести следующее:
— метод Евклида отыскания наибольшего общего делителя (НОД), в котором для пары чисел b и а, если они составные, но взаимно простые, НОД (а, b)=1. Но если эти числа имеют общий делитель, то алгоритм НОД находит больший из всех делитель d и НОД (а, b)=d.
— другой важный результат, которым располагает математика, состоит в том, что любое составное нечетное целое число N представимо разностью квадратов целых чисел разной четности или иначе  . Второе соотношение допускает
. Второе соотношение допускает  .
.
— метод факторизации П. Ферма известен с 1643 года. Он находит наибольший множитель d числа N, не превосходящий  . Метод требует О () арифметических операций и работает наиболее быстро, если множители p и q имеют близкие значения, т.е. когда их разность мала.
. Метод требует О () арифметических операций и работает наиболее быстро, если множители p и q имеют близкие значения, т.е. когда их разность мала.
— решето Эратосфена.
Метод линейного решета (алгоритм LS)
Рихард Шрёппель (Richard Schroeppel), занимаясь проблемой факторизации чисел, предложил оригинальный алгоритм для генерации соотношений следующего вида  .
.
На числовом интервале ![$I = [– N^e, N^e]$](https://habrastorage.org/getpro/habr/formulas/29a/1f0/1f1/29a1f01f124d064aa2c1581c97283107.svg) , где 0 < e ≤1/2 – фиксированное действительное число, рассматриваются две функции двух целочисленных переменных
, где 0 < e ≤1/2 – фиксированное действительное число, рассматриваются две функции двух целочисленных переменных  , определенных в этом интервале I равенствами:
, определенных в этом интервале I равенствами: 

где $inline$ h = [N^½], например, h =[15347^½] = 124; a, b ∈ Z ∩ I.$inline$
В силу сравнимости  этих функций по модулю N их можно использовать при построении требуемых соотношений. Фиксируется граница В > 0 для элементов факторной базы
этих функций по модулю N их можно использовать при построении требуемых соотношений. Фиксируется граница В > 0 для элементов факторной базы  , которую образуют все простые числа, не превосходящие В, а также целое число –1. Далее рассматривается сравнение по модулю N
, которую образуют все простые числа, не превосходящие В, а также целое число –1. Далее рассматривается сравнение по модулю N 
Допустим, что правая часть сравнения может быть представлена произведением и левая часть будет полным квадратом, если величины  входят в произведение четное число раз $inline$П_{i, j}t (a_i, b_j)=(-1)_0^γ ∆ П_{p_i}p_i^{γ_i}$inline$,
входят в произведение четное число раз $inline$П_{i, j}t (a_i, b_j)=(-1)_0^γ ∆ П_{p_i}p_i^{γ_i}$inline$,
где рi простые числа из факторной базы S, а Δ — целое число, являющееся полным квадратом.
В такой ситуации сравнение с произведениями по модулю N соответствует сравнению с известным разложением v на множители из факторной базы. Целью в методе является получение таких соотношений числом, превышающим количество элементов в факторной базе.
Если это достигается, то возможно построить, используя алгоритм гауссова исключения, сравнение , обеспечивающее разложение N на множители.
Для формирования величин (a, b) существует эффективный способ, называемый решетом, поиска значений , при которых величины (a, b) раскладываются в произведение элементов факторной базы.
И сами величины (a, b) принимают небольшие значения. Значения  ограничены и верна оценка:
ограничены и верна оценка: 
Проверка делимости величины s (a, b) на простое число р для произвольных a, b∈ I сводится к проверке делимости на р величины 
Это легко показывается. Пусть простое число р ∈ S делит значение величины s (a, b) при некоторых а. Но из равенства 

 следует, что
следует, что  для произвольных целых значений k, l.
для произвольных целых значений k, l.
Существенным недостатком метода является необходимость большого объема памяти, и отсутствие алгоритмического способа построения сравнений с известным разложением левой части в произведение множителей из факторной базы. Этот текст (компиляция) заимствован из разных публикаций, но практически не сопровождается моими комментариями. Для сравнения привожу другой текст о методе QS, но сопровождаю комментариями, которые, как я надеюсь, вносят понимание и ясность.
Квадратичное решето (QS)
Этот алгоритм (quadratic sieve-QS) предложен в 1981 году Карлом Померансом и почти 10 лет был лучшим (до предложенного в 1990 алгоритма SNFS (special number field sieve), обеспечившего разложение на множители 9-го числа П.Ферма  (155 десятичных знаков)).
(155 десятичных знаков)).
Возможности квадратичного решета ограничиваются разложением в сомножители чисел, с не более чем 110 десятичных цифр в их описании. Оценка сложности (эвристическая) алгоритма даже после многочисленных усовершенствований составляет ![$L_n[1/2;1]$](https://habrastorage.org/getpro/habr/formulas/766/a3c/517/766a3c517ea4631dece5177c0840bf7b.svg) арифметических операций.
арифметических операций.
При рассмотрении QS важными понятиями, которые желательно удерживать в уме, являются:
— вектор показателей степеней чисел -<4 0 1 1>, где, например, для имеем 
— линейная зависимость векторов (см. пример 3 здесь);
— факторная база S=(2,3,5,7) набор малых простых чисел, для которых N -квадратичный вычет;
— гладкие числа  вычеты, которые
вычеты, которые
Целью метода QS является факторизация натурального числа N путем получения для чисел х и у, множество которых строится специальным образом, соотношения  и затем проверка посредством НОД соотношения
и затем проверка посредством НОД соотношения  , завершающего факторизацию N.
, завершающего факторизацию N.
Делители p и q отыскиваются с помощью специальных чисел-значений многочлена вида $inline$q (x)=(j+[N^½])^2-N≡x (j)^2(mod N)$inline$, где $inline$x (j) =j+[N^½] и j$inline$ пробегает значения в диапазоне -М Очевидно, что увеличение значения М приведет к увеличению множества чисел х для просеивания, что способствует росту множества гладких чисел. Но при этом возрастает и время просеивания. Аналогичные проблемы возникают и при увеличении факторной базы S-больше элементов в S-дольше идет обработка таблиц Д и Q (в последней опущены аргументы х). Определение. Факторная база S — набор малых простых чисел, включающий р =-1 и все простые числа рi, рi≤В, такие, что символ Лежандра (N/pi)=+1, т.е. N является квадратичным вычетом для всех рi из факторной базы S. Определение. Пара целых чисел В методе QS формируется множество аргументов х и чисел q (x), среди которых отыскиваются гладкие относительно факторной базы. Эти числа используются для построения соотношений, декларированных в цели метода. Ниже в примере приводится вариант такого формирования (таблица Д). После формирования последовательности пар значений (х, q (x)) выполняем просеивание и находим значения хi, для которых Если процесс формирования последовательности пар значений (х, q (x)) не является трудным для понимания, то процесс просеивания при чтении текста требует нашего внимания значительно больше. Раскроем его здесь в деталях. Пусть задан многочлен q (x) є Z[x]. Будем отыскивать все целые числа K в отрезке [-М, М] такие, что некоторые значения q (x) раскладываются в произведение простых чисел из заданного множества S. Идея алгоритма просеивания множества чисел состоит в том, что если 2. Для аргумента $inline$x = [N^½ ] +1, [N^½ ] + 2, …, [N^½ ] +A$inline$, … и многочлена q (x) выписываем в таблицу Д по порядку пары целых чисел 3. Для каждого нечетного простого числа p≤ P проверяем условие Лежандра (N/p)=1 и, если оно не выполняется, удаляем p из факторной базы. Однако, если мы разложим каждое значение q (x) по степеням простых чисел, то увидим, что некоторые числа из них не имеют множителей больше порога (в примере в разложении у 4-х чисел все факторы p≤11), а р = 5 не является $$display$$ 132 = 2^2 × 3 × 11, 7623 = 3^2 × 7 × 11^2, 8316 = 2^2 × 3^3 × 7 × 11, 27783 = 3^4 × 7^3 .$$display$$ Берем значения β в порядке возрастания, пока не окажется, что уравнение не имеет решений x, сравнимых по модулю Пусть 5. При том же значении p просматриваем список значений Затем заменяем 2 на 3 у всех значений 6. Каждый раз, когда в пункте 5 ставим 1 или заменяем 1 на 2, 2 на 3 и т.д., делим соответствующее число 7. В столбце под p = 2 при N≢ 1(mod 8) просто ставим 1 против 8. Когда указанные действия будут проведены для всех простых чисел, не превосходящих P, отбросим все Тогда получится таблица того же вида, что в примере метода факторизации Ферма, в которой столбец bi будет содержать все такие значения x из интервала $inline$[(kN)^½ ] +1, [(kN)^½ ] +A$inline$, что 9. Оставшаяся часть процедуры в точности совпадает с процедурой из факторизации Ферма. Пример. Будем применять последовательно положения теории алгоритма. Пусть задано составное число N =pq =112093, которое нужно разложить на множители. Следуя концепции квадратичного решета, извлекаем квадратный корень из N, $inline$m =[N^½] =[112093^½] =334,8 =335$inline$ и округляем его значение до большего целого. Далее в методе необходимо сформировать для i =1(1)А таблицу Д пар чисел Таблица Д — Множество, содержащее В-гладкие числа (значения q (x)) с целыми аргументами В этой таблице желательно иметь гладкие числа. Их надо выявить и оставить для дальнейшей обработки, а остальные можно просто удалить. Основной признак для удаления некоторого числа — наличие среди его делителей больших множителей (хотя бы одного), которые не вошли в факторную базу. В качестве границы гладкости примем В = 11. Имеется возможность в процессе решения выбранное множество чисел изменять (уменьшать, увеличивать). В таблице Д среди значений q (х) нет полных квадратов. Теперь можно приступить к поиску чисел, которые обеспечат получение однородной системы линейных уравнений по модулю 2. Сама эта система нетривиальными решениями будет иметь переменные, произведения которых будут получать значения равные полному квадрату. Уже сформирована 2-х строчная таблица Д пар чисел (х-верхняя строка, q (x) — нижняя) Все подряд значения q (x) (нижней строки таблицы Д) последовательно делят на все рj — простые числа (и их степени) из факторной базы S. Результаты деления вписывают в прежние позиции. Те значения, которые не делятся на рj оставляют без изменений. Цель таких преобразований — не вычеркнуть полностью разделившиеся числа из таблицы, а получить в результате деления в их ячейках единичные значения, что соответствует В-гладким числам, т.е. полному разложению числа в таких позициях на степени простых из S. Также для этих ячеек выявляется аргумент х. Дальше будем обрабатывать (делить) числа из строки таблицы Д В результате получаем все четные числа, поделенные пополам в таблице Q, столбцы четных чисел чередуются с нечетными. Это закономерно. В исходной таблице четные чередовались с нечетными числами. Для любого целого d выполняется равенство Изменившиеся числа выделены заливкой в ячейках, делим на (р = 2 β=2), т.е. еще раз. Это следствие того, что квадратичное сравнение по модулю р имеет два решения (если вообще имеет решение). Делим на тройку всего три раза (р =3, β = 3), пока таблица при делении на нее не перестанет изменяться. Следующее деление на 3 таблицу Q не меняет. Переходим к делению на (р =7, β = 1) т.е. к следующему числу факторной базы. Опять возникли 2 цепочки с началом в 4-й и в 5-й ячейках. Дальнейшее деление на 7 таблицу не меняет. Переходим к делению на (р = 11, β = 2) число из факторной базы, причем также делим двукратно и в результате получаем последнюю таблицу просеивания. В ячейках таблицы (с аргументами х=335, 346, 347, 374) появились новые единицы. В позициях последней таблицы, содержащих единицы в исходном заполнении уже размещались 11-гладкие числа, но мы узнали об этом только после просеивания. Вот эти числа: 132, 7623, 8316, 27783. Выше показано, как эти четыре В-гладких числа найдены, без раскладывая всего списка чисел на множители. Соответствующая система линейных уравнений A×X = 0(mod 2) имеет матрицу коэффициентов по модулю 2 следующего вида: Верхняя строка матрицы — гладкие числа, левый столбец- факторная база. Следующим шагом нами получена нетривиальная линейная комбинация по модулю 2, в которой коэффициенты 0 и 1, и дающую в результате нулевой вектор. Для этого полученные результаты (В-гладкие числа) используют для формирования системы линейных алгебраических уравнений (СЛАУ), АХ≡0(mod2) решения которой приводят к окончательному результату-факторизации N. Формируется А матрица СЛАУ, в которой векторы показателей гладких чисел записываются в столбцах, а вектор Х — определяемый неизвестный. Решением этой СЛАУ по модулю 2 получается вектор В предшествующих обозначениях получены зависимости Возьмем тогда другое решение системы АХ≡0(mod2), а именно решение (0101), получающееся при Имеем X = Пxi = 346 · 374 = 129404, y = 14553. Находим  называется гладкой относительно факторной базы S, если: выполняется сравнение
называется гладкой относительно факторной базы S, если: выполняется сравнение  и b раскладывается в произведение элементов из S.
и b раскладывается в произведение элементов из S.  , т. е. q (x) раскладывается на сомножители в нашей факторной базе S.
, т. е. q (x) раскладывается на сомножители в нашей факторной базе S. , то при любом целом ℓ выполняется также сравнение с нулем для
, то при любом целом ℓ выполняется также сравнение с нулем для  . Это обеспечивает фиксирование сразу некоторого множества чисел х, для которых в разложении чисел q (x) на простые сомножители входит простое число р в степени не меньшей t. Это наблюдение существенно ускоряет процесс поиска (просеивания) нужных гладких чисел.
. Это обеспечивает фиксирование сразу некоторого множества чисел х, для которых в разложении чисел q (x) на простые сомножители входит простое число р в степени не меньшей t. Это наблюдение существенно ускоряет процесс поиска (просеивания) нужных гладких чисел.Алгоритм QS
Все теоретические положения QS удобно оформить в виде шагов алгоритма:
1. Выбираются границы P и A порядка  .
.![$m =[N^½] $](https://habrastorage.org/getpro/habr/formulas/5e4/ad0/44f/5e4ad044f9fe687ee31c11f2ba40ad91.svg) вид многочлена просеивания
вид многочлена просеивания  и диапазон значений.
и диапазон значений. .
.
делителем ни одного из них, следовательно, факторную базу примера мы ограничим такими простыми числами S = (2,3,7,11):
4. Предполагая, что p такое нечетное простое число, что N –квадратичный вычет по модулю p; решаем сравнение $inline$x^2≡ N (mod p^β) для β = 1, 2,$inline$ …  с каким-либо из чисел в области $inline$[(kN)^½ ] +1 ≤ x≤ [(kN)^½ ] +A$inline$. Обозначим через β наибольшее из таких чисел, для которых в указанной области найдется число x со свойством $inline$x^2≡ N (mod p^β)$inline$.
с каким-либо из чисел в области $inline$[(kN)^½ ] +1 ≤ x≤ [(kN)^½ ] +A$inline$. Обозначим через β наибольшее из таких чисел, для которых в указанной области найдется число x со свойством $inline$x^2≡ N (mod p^β)$inline$.  — два решения $inline$x^2≡ N (mod p^β)$inline$ и $inline$x_2 ≡N- x_1(mod p^β)$inline$. Не требуется, чтобы принадлежали отрезку $inline$[(kN)^½ ] +1 ≤ x≤ [(kN)^½ ] +A$inline$.
— два решения $inline$x^2≡ N (mod p^β)$inline$ и $inline$x_2 ≡N- x_1(mod p^β)$inline$. Не требуется, чтобы принадлежали отрезку $inline$[(kN)^½ ] +1 ≤ x≤ [(kN)^½ ] +A$inline$. , полученный в пункте 2. В столбце, соответствующем p, ставим 1 против всех значений , для которых x отличается от x1 на некоторое кратное p. После этого заменяем 1 на 2 для всех таких значений , что x отличается от x1 на кратное
, полученный в пункте 2. В столбце, соответствующем p, ставим 1 против всех значений , для которых x отличается от x1 на некоторое кратное p. После этого заменяем 1 на 2 для всех таких значений , что x отличается от x1 на кратное  . , для которых x отличается от x1 на кратное
. , для которых x отличается от x1 на кратное  , и так далее до . Затем делаем то же самое с
, и так далее до . Затем делаем то же самое с  . Наибольшим числом, которое появляется в этом столбце, будет β. на p и сохраняем полученный результат в той же ячейке. с нечетным x и делим соответствующее на 2. При N≡ 1(mod 8) решаем уравнение
. Наибольшим числом, которое появляется в этом столбце, будет β. на p и сохраняем полученный результат в той же ячейке. с нечетным x и делим соответствующее на 2. При N≡ 1(mod 8) решаем уравнение  и продолжаем в точности также, как в случае нечетного p (за исключением того, что при β ≥ 3 уравнение будет иметь 4 различных решения
и продолжаем в точности также, как в случае нечетного p (за исключением того, что при β ≥ 3 уравнение будет иметь 4 различных решения  )., кроме тех, которые обратились в 1 после деления на все степени p, не превосходящие P. есть B-число, а остальные столбцы будут соответствовать тем значениям p ≤ P, для которых N — квадратичный вычет.
)., кроме тех, которые обратились в 1 после деления на все степени p, не превосходящие P. есть B-число, а остальные столбцы будут соответствовать тем значениям p ≤ P, для которых N — квадратичный вычет. , возрастающих по i с шагом 1 значений аргументов (ограничимся для А = 40 значениями) и соответствующих им значений функции.
, возрастающих по i с шагом 1 значений аргументов (ограничимся для А = 40 значениями) и соответствующих им значений функции.
Просеивание
Рассмотрим в деталях как из множества значений в таблице Д выявляются В-гладкие числа, без представления каждого из них произведением простых сомножителей. Это очень трудоемкая работа и ее не делают. таблицы Д, которые соберем в одной новой Q таблице (41 позиция). Все числа этой новой таблицы делим на р = 2, β = 1. Аргументы i в таблицу не пишем, так как это просто номера ячеек. 
 , так что, если число из набора q (х) делится на d, то все числа отстоящие от него на расстоянии, кратном d также делятся на d
, так что, если число из набора q (х) делится на d, то все числа отстоящие от него на расстоянии, кратном d также делятся на d

Теперь все числа в таблице Q нечетные. Деление на простое р =2 и его степени 2×2=4 завершилось. Начинаем делить на следующее простое число из факторной базы (р =3, β = 1) 
Если некоторое число разделилось на три, то каждое третье после него также делится на три. Таких цепочек чисел в таблице Q возникло две: 1-я цепочка начинается с первой ячейки; 2-я — с третьей. 

Еще два прохода с делителем (р = 7, β = 3) приводят к появлению первой единицы в таблице (предпоследнее число таблицы 49:7:7 =1).

Система линейных алгебраических уравнений и ее решение
Ни одно из значений таблицы Д вида  не квадрат. Но нам вообще-то нужны квадраты, следовательно, надо подобрать такие подмножества из В-гладких чисел (в таблице Q им соответствуют в ячейках единицы), которые при их перемножении обеспечивают формирование полных квадратов.
не квадрат. Но нам вообще-то нужны квадраты, следовательно, надо подобрать такие подмножества из В-гладких чисел (в таблице Q им соответствуют в ячейках единицы), которые при их перемножении обеспечивают формирование полных квадратов.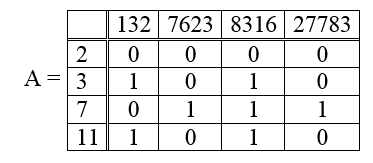
 . При
. При  — это решение нетривиально: (1110), что означает — полным квадратом будет произведение первых трех чисел.
— это решение нетривиально: (1110), что означает — полным квадратом будет произведение первых трех чисел.
X = П xi = 335 · 346 · 347=40220770, y = 91476.
Здесь X − y = 40220770 − 91476 = 40129294.
Находим НОД (X − y, N) = НОД (40129294, 112093) = 112093.
К сожалению, найденный делитель числа N = 112093 тривиален. Заметим, что и
НОД (X + y, N) = НОД (40312246, 112093) = 1 — тривиальный делитель.  . Оно означает, что точным квадратом будет произведение второго и четвёртого чисел:
. Оно означает, что точным квадратом будет произведение второго и четвёртого чисел: 
НОД (X − y, N) = НОД (114851, 112093) = 197.
Найден нетривиальный делитель 197 числа N = 112093. Теперь число N можно разложить на множители: N = 112093 = 569 · 197.Заключение
В работе с определенной детальностью приводится изложение основных шагов и этапов алгоритма квадратичного решета (QS) для факторизации чисел ограниченной разрядности.
В отличие от подавляющего большинства публикаций, в которых практически не приводятся числовые примеры, в этой работе как раз такой пример дан с подробными комментариями. На этом примере удается продемонстрировать основные характерные действия излагаемого алгоритма.
Для своего времени алгоритм QS сыграл весьма положительную роль. Было показано, что «не боги горшки обжигают», но движения дальше не проявилось, так как последующие методы замкнулись на совершенствовании того же решета. Список, использованной литературы
1. Агафонова И.В. Факторизация больших целых чисел и криптография 2006.
2. Брассар Ж. Современная криптология. М.: ПОЛИМЕД, 1999.
3. Василенко О.Н. Теоретико-числовые алгоритмы в криптографии. М.: МЦНМО, 2003
4. Нестеренко А.Ю. Теоретико-числовые алгоритмы в криптографии. Москва 2012
5. Rivest R. L., Shamir A., Adleman L.M. A method for obtaining digital signatures and public-key cryptosystems // Communications of the ACM. 1978. V. 21, P. 120–126.
6. The RSA Challenge Numbers // RSA Laboratories. www.rsasecurity.com/rsalabs/node.asp? id=2093
7. Стренг Г. Линейная алгебра и её применения. М.: Мир, 1980.
8. Смарт Н. Криптография. М.: Техносфера, 2005.
9. Shanks D. Five number-theoretic algorithms // Proceedings of the Second Manitoba Conference on Numerical Mathematics (Winnipeg), Utilitas Math. 1973. P. 51–70. Congressus Numerantium, No. VII.
