FAISS: Быстрый поиск лиц и клонов на многомиллионных данных
Однажды в преддверии клиентской конференции, которую ежегодно проводит группа DAN, мы размышляли над тем, что интересного можно придумать, чтобы у наших партнеров и клиентов остались приятные впечатления и воспоминания о мероприятии. Мы решили разобрать архив из тысяч фотографий с этой конференции и нескольких прошлых (а всего их к тому моменту было 18): человек отправляет нам свою фотографию, а мы ему через пару секунд отправляем подборку фотографий с ним за несколько лет из наших архивов.
Велосипед мы не придумывали, взяли всем известную библиотеку dlib и получили эмбеддинги (векторные представления) каждого лица.
Добавили Telegram-бота для удобства, и всё было отлично. С точки зрения алгоритмов распознавания лиц всё работало на ура, но конференция завершилась, а расставаться с опробованными технологиями не хотелось. От нескольких тысяч лиц хотелось перейти к сотням миллионов, но конкретной бизнес-задачи у нас не было. Через некоторое время у наших коллег появилась задача, которая требовала работы с такими большими объемами данных.
Вопрос был в том, чтобы написать умную систему мониторинга ботов внутри сети Instagram. Тут наша мысль породила простой и сложный подходы:
Простой путь: Рассматриваем все аккаунты, у которых подписок гораздо больше, чем подписчиков, нет аватарки, не заполнено full name и т.д. В итоге получаем непонятную толпу полумертвых аккаунтов.
Сложный путь: Так как современные боты стали намного умнее, и теперь они выкладывают посты, спят, да еще и контент пишут, встаёт вопрос: как таких поймать? Во-первых, внимательно следить за их друзьями, так как часто они тоже бывают ботами, и отслеживать дублирующие фотки. Во-вторых, редко какой бот умеет генерировать свои фотки (хотя и такое возможно), а значит, дубли фото людей в разных аккаунтах в Инстаграме являются хорошим триггером для поиска сети ботов.
Что дальше?
Если простой путь вполне предсказуем и быстро дает некоторые результаты, то сложный путь сложен именно потому, что для его реализации нам придется векторизовать и индексировать для последующих сравнений похожести невероятно большие объемы фотографий — миллионы, и даже миллиарды. Как это реализовать на практике? Ведь встают технические вопросы:
- Скорость и точность поиска
- Размер занимаемого данными места на диске
- Размер используемой RAM памяти.
Если бы фотографий было немного, хотя бы не более десятка тысяч, мы могли бы ограничиться простыми решениями с векторной кластеризацией, но для работы с громадными объемами векторов и поиска ближайших к некоторому вектору соседей потребуются сложные и оптимизированные алгоритмы.
Существуют известные и зарекомендовавшие себя технологии, такие как Annoy, FAISS, HNSW. Быстрый алгоритм поиска соседей HNSW, доступный в библиотеках nmslib и hnswlib, показывает state-of-the-art результаты на CPU, что видно по тем же бенчмаркам. Но его мы отсекли сразу, так как нас не устраивает количество используемой памяти при работе с действительно большими объемами данных. Мы стали выбирать между Annoy и FAISS и в итоге выбрали FAISS из-за удобства, меньшего использования памяти, потенциальной возможности использования на GPU и бенчмарков по результативности (посмотреть можно, например, здесь). К слову, в FAISS алгоритм HNSW реализован как опция.
Что такое FAISS?
Facebook AI Research Similarity Search — разработка команды Facebook AI Research для быстрого поиска ближайших соседей и кластеризации в векторном пространстве. Высокая скорость поиска позволяет работать с очень большими данными — до нескольких миллиардов векторов.
Основное преимущество FAISS — state-of-the-art результаты на GPU, при этом его реализация на CPU незначительно проигрывает hnsw (nmslib). Нам хотелось иметь возможность вести поиск как на CPU, так и на GPU. Кроме того, FAISS оптимизирован в части использования памяти и поиска на больших батчах.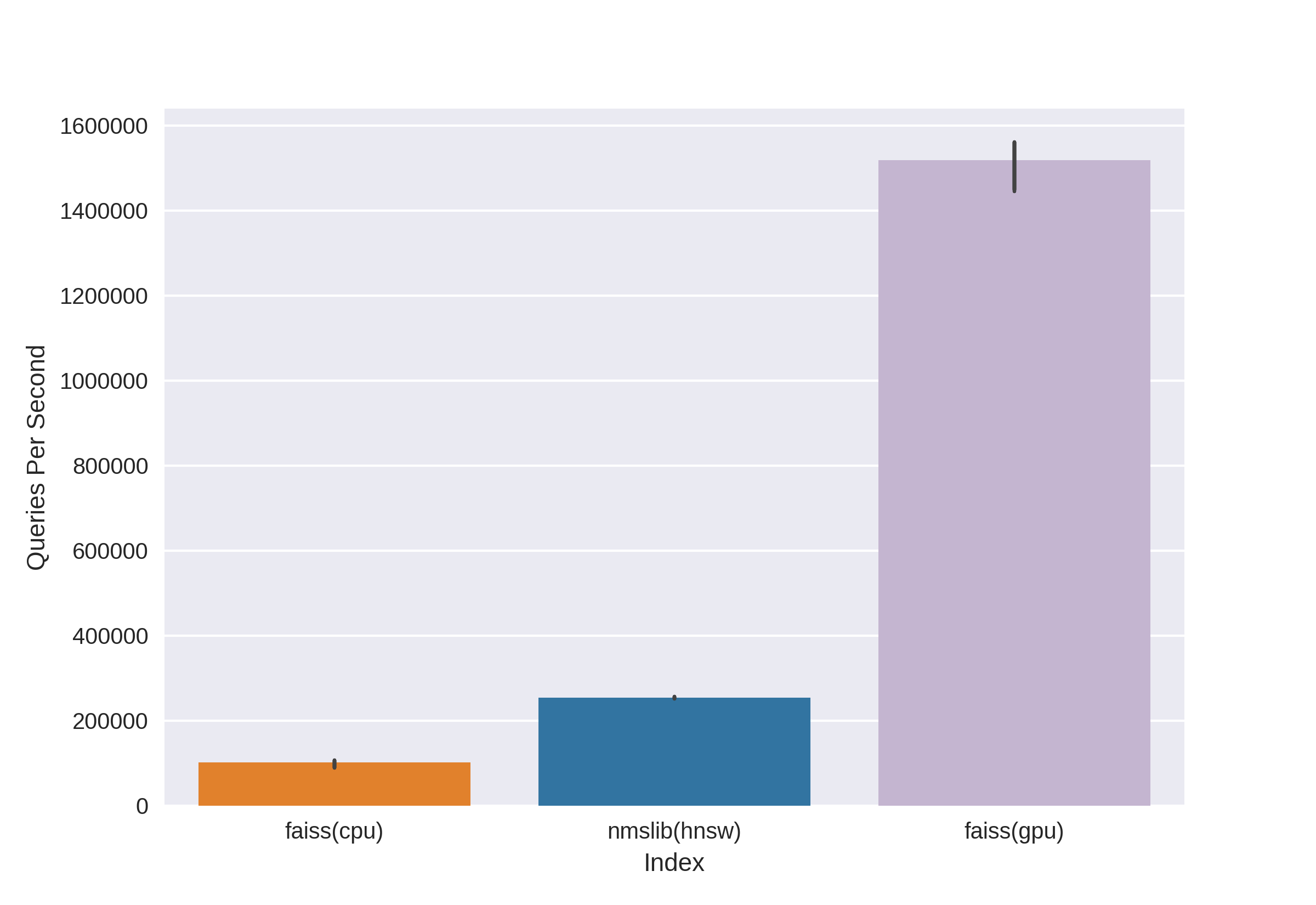
Source
FAISS позволяет быстро осуществлять операцию поиска k ближайших векторов для данного вектора x. Но как же этот поиск устроен под капотом?
Индексы
Главное понятие в FAISS — это index, и, по сути, это просто набор параметров и векторов. Наборы параметров бывают совершенно разные и зависят от нужд пользователя. Векторы могут оставаться неизменными, а могут перестраиваться. Некоторые индексы доступны для работы сразу после добавления в них векторов, а некоторые требуют предварительного обучения. Имена векторов хранятся в индексе: либо в нумерации от 0 до n, либо в виде числа, влезающего в тип Int64.
Первый индекс, и самый простой, который мы использовали ещё на конференции, — это Flat. Он лишь хранит в себе все вектора, а поиск по заданному вектору осуществляется полным перебором, поэтому обучать его не нужно (но об обучении ниже). На маленьком объеме данных такой простой индекс может вполне покрыть нужды поиска.
Пример:
import numpy as np
dim = 512 # рассмотрим произвольные векторы размерности 512
nb = 10000 # количество векторов в индексе
nq = 5 # количество векторов в выборке для поиска
np.random.seed(228)
vectors = np.random.random((nb, dim)).astype('float32')
query = np.random.random((nq, dim)).astype('float32')
Создаем Flat индекс и добавляем векторы без обучения:
import faiss
index = faiss.IndexFlatL2(dim)
print(index.ntotal) # пока индекс пустой
index.add(vectors)
print(index.ntotal) # теперь в нем 10 000 векторов
Теперь найдем 7 ближайших соседей для первых пяти векторов из vectors:
topn = 7
D, I = index.search(vectors[:5], topn) # Возвращает результат: Distances, Indices
print(I)
print(D)
[[0 5662 6778 7738 6931 7809 7184]
[1 5831 8039 2150 5426 4569 6325]
[2 7348 2476 2048 5091 6322 3617]
[3 791 3173 6323 8374 7273 5842]
[4 6236 7548 746 6144 3906 5455]]
[[ 0. 71.53578 72.18823 72.74326 73.2243 73.333244 73.73317 ]
[ 0. 67.604805 68.494774 68.84221 71.839905 72.084335 72.10817 ]
[ 0. 66.717865 67.72709 69.63666 70.35903 70.933304 71.03237 ]
[ 0. 68.26415 68.320595 68.82381 68.86328 69.12087 69.55179 ]
[ 0. 72.03398 72.32417 73.00308 73.13054 73.76181 73.81281 ]]
Видим, что самые близкие соседи с расстоянием 0 — это сами векторы, остальные отранжированы по увеличению расстояния. Проведем поиск по нашим векторам из query:
D, I = index.search(query, topn)
print(I)
print(D)
[[2467 2479 7260 6199 8640 2676 1767]
[2623 8313 1500 7840 5031 52 6455]
[1756 2405 1251 4136 812 6536 307]
[3409 2930 539 8354 9573 6901 5692]
[8032 4271 7761 6305 8929 4137 6480]]
[[73.14189 73.654526 73.89804 74.05615 74.11058 74.13567 74.443436]
[71.830215 72.33813 72.973885 73.08897 73.27939 73.56996 73.72397 ]
[67.49588 69.95635 70.88528 71.08078 71.715965 71.76285 72.1091 ]
[69.11357 69.30089 70.83269 71.05977 71.3577 71.62457 71.72549 ]
[69.46417 69.66577 70.47629 70.54611 70.57645 70.95326 71.032005]]
Теперь расстояния в первом столбце результатов не нулевые, так как векторов из query нет в индексе.
Индекс можно сохранить на диск и затем загрузить с диска:
faiss.write_index(index, "flat.index")
index = faiss.read_index("flat.index")
Казалось бы, всё элементарно! Несколько строчек кода — и мы уже получили структуру для поиска по векторам высокой размерности. Но такой индекс всего с десятком миллионов векторов размерности 512 будет весить около 20Гб и занимать при использовании столько же RAM.
В проекте для конференции мы использовали именно такой базовый подход с flat index, всё было замечательно благодаря относительно маленькому объему данных, однако сейчас речь идет о десятках и сотнях миллионов векторов высокой размерности!
Ускоряем поиск с помощью Inverted lists

Source
Основная и наикрутейшая особенность FAISS — IVF index, или Inverted File index. Идея Inverted files лаконична, и красиво объясняется на пальцах:
Давайте представим себе гигантскую армию, состоящую из самых разношерстных воинов, численностью, скажем, в 1 000 000 человек. Командовать всей армией сразу будет невозможно. Как и принято в военном деле, нужно разделить нашу армию на подразделения. Давайте разделим на  примерно равных частей, выбрав на роли командиров по представителю из каждого подразделения. И постараемся отправить максимально похожих по характеру, происхождению, физическим данным и т.д. воинов в одно подразделение, а командира выберем таким, чтобы он максимально точно представлял свое подразделение — был кем-то «средним». В итоге наша задача свелась от командования миллионом воинов к командованию 1000-ю подразделениями через их командиров, и мы имеем отличное представление о составе нашей армии, так как знаем, что из себя представляют командиры.
примерно равных частей, выбрав на роли командиров по представителю из каждого подразделения. И постараемся отправить максимально похожих по характеру, происхождению, физическим данным и т.д. воинов в одно подразделение, а командира выберем таким, чтобы он максимально точно представлял свое подразделение — был кем-то «средним». В итоге наша задача свелась от командования миллионом воинов к командованию 1000-ю подразделениями через их командиров, и мы имеем отличное представление о составе нашей армии, так как знаем, что из себя представляют командиры.
В этом и состоит идея IVF индекса: сгруппируем большой набор векторов по частям с помощью алгоритма k-means, каждой части поставив в соответствие центроиду, — вектор, являющийся выбранным центром для данного кластера. Поиск будем осуществлять через минимальное расстояние до центроид, и только потом искать минимальные расстояния среди векторов в том кластере, что соответствует данной центроиде. Взяв k равным  , где
, где  — количество векторов в индексе, мы получим оптимальный поиск на двух уровнях — сначала среди центроид, затем среди векторов в каждом кластере. Поиск по сравнению с полным перебором ускоряется в разы, что решает одну из наших проблем при работе с множеством миллионов векторов.
— количество векторов в индексе, мы получим оптимальный поиск на двух уровнях — сначала среди центроид, затем среди векторов в каждом кластере. Поиск по сравнению с полным перебором ускоряется в разы, что решает одну из наших проблем при работе с множеством миллионов векторов.

Пространство векторов разбивается методом k-means на k кластеров. Каждому кластеру в соответствие ставится центроида
Пример кода:
dim = 512
k = 1000 # количество "командиров”
quantiser = faiss.IndexFlatL2(dim)
index = faiss.IndexIVFFlat(quantiser, dim, k)
vectors = np.random.random((1000000, dim)).astype('float32') # 1 000 000 "воинов”
А можно это записать куда более элегантно, воспользовавшись удобной штукой FAISS для построения индекса:
index = faiss.index_factory(dim, "IVF1000,Flat”)
Запускаем обучение:
print(index.is_trained) # False.
index.train(vectors) # Train на нашем наборе векторов
# Обучение завершено, но векторов в индексе пока нет, так что добавляем их в индекс:
print(index.is_trained) # True
print(index.ntotal) # 0
index.add(vectors)
print(index.ntotal) # 1000000
Рассмотрев такой тип индекса после Flat, мы решили одну из наших потенциальных проблем — скорость поиска, которая становится в разы меньше по сравнению с полным перебором.
D, I = index.search(query, topn)
print(I)
print(D)
[[19898 533106 641838 681301 602835 439794 331951]
[654803 472683 538572 126357 288292 835974 308846]
[588393 979151 708282 829598 50812 721369 944102]
[796762 121483 432837 679921 691038 169755 701540]
[980500 435793 906182 893115 439104 298988 676091]]
[[69.88127 71.64444 72.4655 72.54283 72.66737 72.71834 72.83057]
[72.17552 72.28832 72.315926 72.43405 72.53974 72.664055 72.69495]
[67.262115 69.46998 70.08826 70.41119 70.57278 70.62283 71.42067]
[71.293045 71.6647 71.686615 71.915405 72.219505 72.28943 72.29849]
[73.27072 73.96091 74.034706 74.062515 74.24464 74.51218 74.609695]]
Но есть одно «но» — точность поиска, как и скорость, будет зависеть от количества посещаемых кластеров, которое можно задать с помощью параметра nprobe:
print(index.nprobe) # 1 – заходим только в один кластер и ведем поиск только в нём
index.nprobe = 16 # Проходим по топ-16 центроид для поиска top-n ближайших соседей
D, I = index.search(query, topn)
print(I)
print(D)
[[ 28707 811973 12310 391153 574413 19898 552495]
[540075 339549 884060 117178 878374 605968 201291]
[588393 235712 123724 104489 277182 656948 662450]
[983754 604268 54894 625338 199198 70698 73403]
[862753 523459 766586 379550 324411 654206 871241]]
[[67.365585 67.38003 68.17187 68.4904 68.63618 69.88127 70.3822]
[65.63759 67.67015 68.18429 68.45782 68.68973 68.82755 69.05]
[67.262115 68.735535 68.83473 68.88733 68.95465 69.11365 69.33717]
[67.32007 68.544685 68.60204 68.60275 68.68633 68.933334 69.17106]
[70.573326 70.730286 70.78615 70.85502 71.467674 71.59512 71.909836]]
Как видно, после увеличения nprobe имеем совсем другие результаты, топ наименьших расстояний в D стал лучше.
Можно брать nprobe равным количеству центроид в индексе, тогда это будет эквивалентно поиску полным перебором, точность будет наибольшая, но скорость поиска заметно уменьшится.
Ведем поиск по диску — On Disk Inverted Lists
Отлично, первую проблему мы решили, теперь на десятках миллионов векторов мы получаем приемлемую скорость поиска! Но всё это бесполезно до тех пор, пока наш огромный индекс не умещается в RAM.
Конкретно для нашей задачи основное преимущество FAISS — в возможности хранить Inverted Lists IVF индекса на диске, загружая в RAM только метаданные.
Как мы создаем такой индекс: обучаем indexIVF с нужными параметрами на максимально возможном объеме данных, который влезает в память, затем в обученный индекс по частям добавляем векторы (побывавшие в обучении и не только) и записываем на диск индекс для каждой из частей.
index = faiss.index_factory(512, ",IVF65536, Flat”, faiss.METRIC_L2)
Обучение индекса на GPU осуществляем таким образом:
res = faiss.StandardGpuResources()
index_ivf = faiss.extract_index_ivf(index)
index_flat = faiss.IndexFlatL2(512)
clustering_index = faiss.index_cpu_to_gpu(res, 0, index_flat) # 0 – номер GPU
index_ivf.clustering_index = clustering_index
faiss.index_cpu_to_gpu (res, 0, index_flat) можно заменить на faiss.index_cpu_to_all_gpus (index_flat), чтобы использовать все GPU вместе.
Крайне желательно, чтобы обучающая выборка была максимально репрезентативна и имела равномерное распределение, поэтому мы заранее составляем обучающий датасет из необходимого количества векторов, рандомно выбирая их из всего датасета.
train_vectors = ... # предварительно сформированный датасет для обучения
index.train(train_vectors)
# Сохраняем пустой обученный индекс, содержащий только параметры:
faiss.write_index(index, "trained_block.index")
# Поочередно создаем новые индексы на основе обученного
# Блоками добавляем в них части датасета:
for bno in range(first_block, last_block+ 1):
block_vectors = vectors_parts[bno]
block_vectors_ids = vectors_parts_ids[bno] # id векторов, если необходимо
index = faiss.read_index("trained_block.index")
index.add_with_ids(block_vectors, block_vectors_ids)
faiss.write_index(index, "block_{}.index".format(bno))
После этого объединяем все Inverted Lists воедино. Это возможно, так как каждый из блоков, по сути, является одним и тем же обученным индексом, просто с разными векторами внутри.
ivfs = []
for bno in range(first_block, last_block+ 1):
index = faiss.read_index("block_{}.index".format(bno), faiss.IO_FLAG_MMAP)
ivfs.append(index.invlists)
# считать index и его inv_lists независимыми
# чтобы не потерять данные во время следующей итерации:
index.own_invlists = False
# создаем финальный индекс:
index = faiss.read_index("trained_block.index")
# готовим финальные invlists
# все invlists из блоков будут объединены в файл merged_index.ivfdata
invlists = faiss.OnDiskInvertedLists(index.nlist, index.code_size, "merged_index.ivfdata")
ivf_vector = faiss.InvertedListsPtrVector()
for ivf in ivfs:
ivf_vector.push_back(ivf)
ntotal = invlists.merge_from(ivf_vector.data(), ivf_vector.size())
index.ntotal = ntotal # заменяем листы индекса на объединенные
index.replace_invlists(invlists)
faiss.write_index(index, data_path + "populated.index") # сохраняем всё на диск
Итог: теперь наш индекс это файлы populated.index и merged_blocks.ivfdata.
В populated.index записан первоначальный полный путь к файлу с Inverted Lists, поэтому, если путь к файлу ivfdata по какой-то причине изменится, при чтении индекса потребуется использовать флаг faiss.IO_FLAG_ONDISK_SAME_DIR, который позволяет искать ivfdata файл в той же директории, что и populated.index:
index = faiss.read_index('populated.index', faiss.IO_FLAG_ONDISK_SAME_DIR)
За основу был взят demo пример из Github проекта FAISS.
Мини-гайд по выбору индекса можно посмотреть в FAISS Wiki. Например, мы смогли поместить в RAM тренировочный датасет из 12 миллионов векторов, поэтому выбрали IVFFlat индекс на 262144 центроидах, чтобы затем масштабироваться до сотен миллионов. Также в гайде предлагается использовать индекс IVF262144_HNSW32, в котором принадлежность вектора к кластеру определяется по алгоритму HNSW с 32 ближайшими соседями (иными словами, используется quantizer IndexHNSWFlat), но, как нам показалось при дальнейших тестах, поиск по такому индексу менее точен. Кроме того, следует учитывать, что такой quantizer исключает возможность использования на GPU.
Значительно уменьшаем использование дискового пространства с Product Quantization
Благодаря методу поиска с диска удалось снять нагрузку с RAM, но индекс с миллионом векторов всё равно занимал около 2 ГБ дискового пространства, а мы рассуждаем о возможности работы с миллиардами векторов, что потребовало бы более двух ТБ! Безусловно, объем не такой большой, если задаться целью и выделить дополнительное дисковое пространство, но нас это немного напрягало.
И тут приходит на помощь кодирование векторов, а именно Scalar Quantization (SQ) и Product Quantization (PQ). SQ — кодирование каждой компоненты вектора n битами (обычно 8, 6 или 4 бит). Мы рассмотрим вариант PQ, ведь идея кодирования одной компоненты типа float32 восемью битами выглядит уж слишком удручающе с точки зрения потерь в точности. Хотя в некоторых случаях сжатие SQfp16 до типа float16 будет почти без потерь в точности.
Суть Product Quantization состоит в следующем: векторы размерности 512 разбиваются на n частей, каждая из которых кластеризуется по 256 возможным кластерам (1 байт), т.е. мы представляем вектор с помощью n байт, где n обычно не превосходит 64 в реализации FAISS. Но применяется такая квантизация не к самим векторам из датасета, а к разностям этих векторов и соответствующих им центроид, полученным на этапе генерации Inverted Lists! Выходит, что Inverted Lists будут представлять из себя кодированные наборы расстояний между векторами и их центроидами.
index = faiss.index_factory(dim, "IVF262144,PQ64", faiss.METRIC_L2)
Выходит, что теперь нам не обязательно хранить все векторы — достаточно выделять n байт на вектор и 2048 байт на каждый вектор центроиды. В нашем случаем мы взяли  , то есть
, то есть  — длина одного субвектора, который определяется в один из 256 кластеров.
— длина одного субвектора, который определяется в один из 256 кластеров.
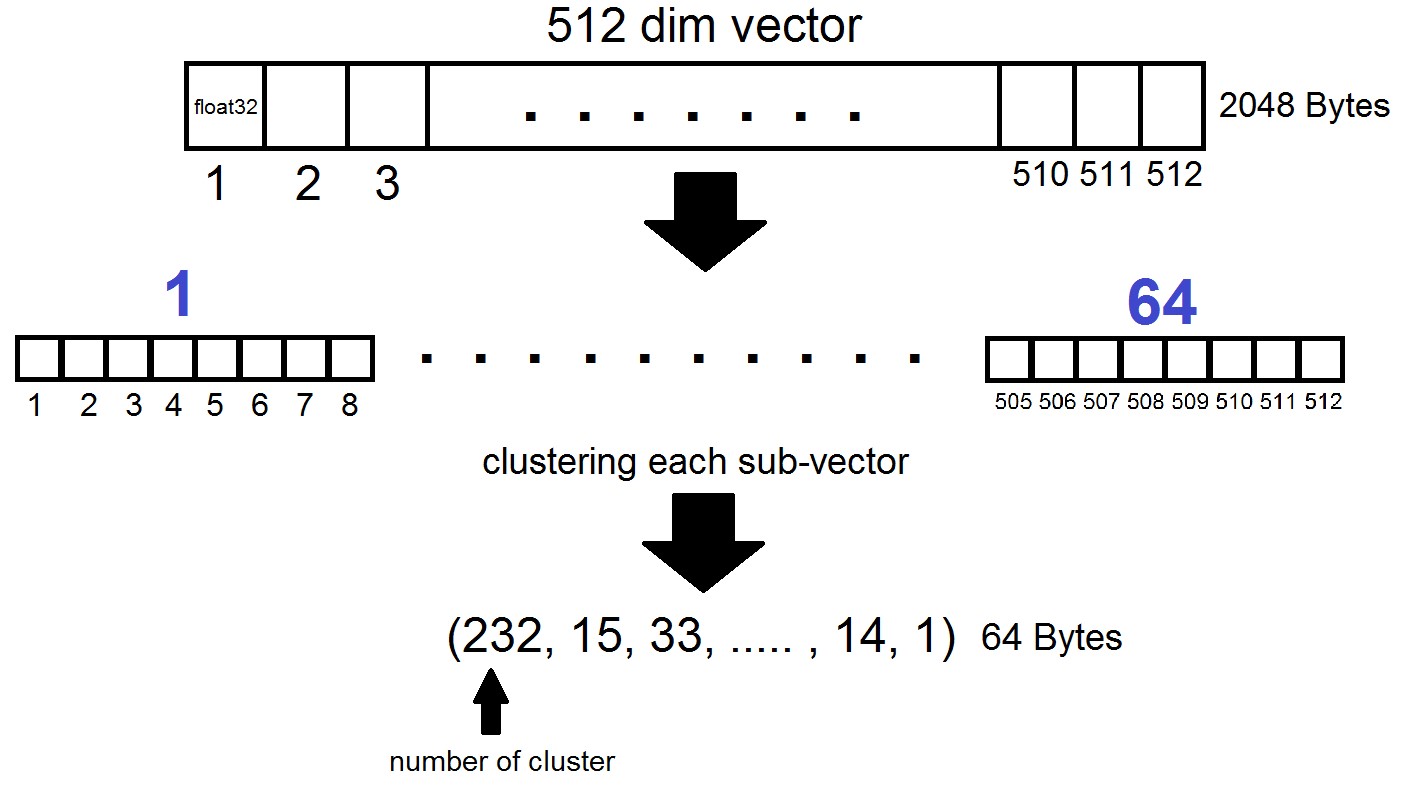
При поиске по вектору x сначала обычным Flat квантайзером будут определяться ближайшие центроиды, а затем x так же разделяется на суб-векторы, каждый из которых кодируется номером одной из 256 соответствующей центроиды. И расстояние до вектора определяется как сумма из 64 расстояний между суб-векторами.
Что в итоге?
Мы остановили свои эксперименты на индексе «IVF262144, PQ64», так как он полностью удовлетворил все наши нужды по скорости и точности поиска, а также обеспечил разумное использование дискового пространства при дальнейшем масштабировании индекса. Если говорить конкретнее, на данный момент при 315 миллионах векторов индекс занимает 22 Гб дискового пространства и около 3 Гб RAM при использовании.
Еще одна интересная деталь, которую мы не упоминали ранее, — метрика, используемая индексом. По умолчанию расстояния между любыми двумя векторами считаются в евклидовой метрике L2, или более понятным языком, расстояния считаются как квадратный корень из суммы квадратов покоординатных разностей. Но задать метрику можно и другую, в частности, мы тестировали метрику METRIC_INNER_PRODUCT, или метрику косинусных расстояний между векторами. Косинусная она потому, что косинус угла между двумя векторами в Евклидовой системе координат выражается как отношение скалярного (покоординатного) произведения векторов к произведению их длин, а если все векторы в нашем пространстве имеют длину 1, то косинус угла будет в точности равен покоординатному произведению. В таком случае чем ближе расположены векторы в пространстве, тем ближе к единице будет их скалярное произведение.
Метрика L2 имеет непосредственный математический переход к метрике скалярных произведений. Однако при экспериментальном сравнении двух метрик сложилось впечатление, что метрика скалярных произведений помогает нам анализировать коэффициенты похожести изображений более удачным образом. К тому же эмбеддинги наших фотографий были получены с помощью InsightFace, в котором реализована архитектура ArcFace, использующая косинусные расстояния. Также есть и другие метрики в индексах FAISS, о которых можно почитать здесь.
Однако, стоит заметить, что для использования индекса с PQ квантилизацией на GPU требуется ограничить размер кода 56-ю байтами, либо в случае большего размера сменить float32 на float16, связано это с ограничениями на используемую память.
В итоге о FAISS на GPU мы думать перестали, потому что CPU реализация нас полностью устроила по скорости, и хотелось сохранить работу с метрикой скалярных произведений, что на GPU недоступно. Чтобы регулировать нагрузку на процессоры при работе с индексами, можно задать максимальное число используемых процессоров:
faiss.omp_set_num_threads(N)Заключение и любопытные примеры
Итак, вернемся же к тому, с чего всё начиналось. А начиналось, напомним, с мотивации решить задачу поиска ботов в сети Instagram, а конкретнее — искать дубликаты постов с людьми или аватарок в определенных множествах юзеров. В процессе написания материала стало понятно, что подробное описание нашей методологии поиска ботов тянет на отдельную статью, о чем мы расскажем в следующих публикациях, а пока ограничимся примерами наших экспериментов с FAISS.
Векторизовать картинки или лица можно по-разному, мы выбрали технологию InsightFace (векторизация изображений и выделение n-мерных фичей из них — это отдельная долгая история). В ходе экспериментов с полученной нами инфраструктурой были обнаружены довольно интересные и забавные свойства.
Например, заручившись разрешением коллег и знакомых, мы загрузили в поиск их лица и быстро нашли фотографии, на которых они присутствуют:

Наш коллега попал на фотографию посетительницы Comic-Con, оказавшись на заднем фоне в толпе. Источник

Пикник в многочисленной компании друзей, фотография из аккаунта подруги. Источник

Просто проходили мимо. Неизвестный фотограф запечатлел ребят для своего тематического профиля. Они не знали, куда попала их фотография, а спустя 5 лет и вовсе забыли, как их фотографировали. Источник

В этом случае и фотограф неизвестен, и сфотографировали тайно!
Сразу вспомнилась подозрительная девушка с зеркальным фотоаппаратом, сидевшая в тот момент напротив:) Источник
Таким образом, путём нехитрых действий FAISS позволяет собрать на коленке аналог всем известного FindFace.
Другая интересная особенность: в индексе FAISS чем больше лица похожи друг на друга, тем ближе друг к другу расположены соответствующие им векторы в пространстве. Я решил повнимательнее изучить чуть менее точные результаты поиска по своему лицу и обнаружил до ужаса похожих на себя клонов:)

Некоторые из клонов автора.
Источники фото: 1, 2, 3
Вообще говоря, FAISS открывает огромное поле для реализации каких-либо творческих идей. Например, по тому же принципу векторной близости похожих лиц можно было бы строить пути от одного лица к другому. Или в крайнем случае сделать из FAISS фабрику по производству подобных мемов:

Source
Благодарим за внимание и надеемся что этот материал будет полезен читателям Хабра!
Статья написана при поддержке моих коллег Артёма Королёва (korolevart), Тимура Кадырова и Арины Решетниковой.
R&D Dentsu Aegis Network Russia.
