Explyt Spring Plugin. Патчим байткод Spring или как мы улучшили распознавание контекста приложений
Всем привет! Одной из уникальных особенностей нашего плагина, является практически стопроцентное понимание контекста Spring приложений. Где мы максимально нативным способом, через публичное Spring Boot Api, смогли получить доступ к контексту приложения и использовали эту информацию у себя в плагине для поддержки Spring Dependency Injection и навигации к «бинам». Но время не стоит на месте, и мы сделали еще один шаг в сторону улучшения распознавания Spring Context, путем модификации текущего байт-кода Spring через параметр jvm: -javaagent, который позволил избавиться нам от большинства недостатков текущего подхода, кому интересно узнать детали реализации, то добро пожаловать под кат.
Данная статья является продолжением нашей предыдущей публикации, где мы рассказывали о способе получения информации о контексте Spring проектов. Поэтому рекомендуем сначала ознакомится с ней для лучшего понимания проблемы.
Недостатки текущего решения
Для получения информации о бинах, мы использовали публичное Spring Boot API. При запуске этого процесса, мы на лету подменяли реальный метод запуска Spring Boot приложения:
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}На наш вариант:
@SpringBootApplication
public class DemoApplicationV3 {
public static void main(String[] args) {
ExplytApplicationStartup applicationStartup = new ExplytApplicationStartup();
SpringApplication springApplication = new SpringApplication(DemoApplicationV3.class) {
@Override
protected ConfigurableApplicationContext createApplicationContext() {
applicationStartup.context = super.createApplicationContext();
return applicationStartup.context;
}
};
springApplication.setApplicationStartup(applicationStartup);
springApplication.run(args);
}
}Где сохраняли ссылку на текущую переменную Spring Context и подставляли свою имплементации для ApplicationStartup, которая отвечала за прерывание инициализации приложения после фазы построения всех Bean Definitions и получение самих данных из переменной контекста.
Помимо своей простоты и того что данный способ, позволяет получить доступ к контексту через публичное API безо всякой «рефлексии» и прочих «трюков», он не был лишен недостатков:
подходит только для Spring Boot проектов;
данное API доступно, начиная с версии «бута» 2.4, которая вышла в октябре 2020 года.
кастомная логика по инициализации «бинов» в main методе, не поддерживается данным процессом. Т.к. мы меняем его на свой main. И за время поддержки нашего плагина, уже пришлось столкнуться с одним таким случаем;
требуется компиляция проекта.
Вообщем, не смотря на то, что данный способ успешно работает для большинства современных Spring Boot проектов, как видно, он имеет ряд серьезных ограничений.
Вспомним еще раз как выглядит процесс создания контекста Spring (полный код — AbstractApplicationContext#refresh):
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
} catch (BeansException ex) Наша кастомная реализация ApplicationStartup кидала исключение на шаге beanPostProcess.end() и выводила в консоль текущее состояние контекста — bean definitions. Но у меня в голове постоянно витала идея — было бы неплохо как то изменить байт код Spring, чтобы выводить на этом шаге «бины» и прерывать процесс. Это позволило нам избавить от перечисленных выше недостатков.
Патчим байткод Spring
Ранее мне никогда не доводилось заниматься генерацией/модификацией байт-кода, хотя теоретически я знал о таком параметре JVM как -javaagent, через который можно загружать дополнительные модули, на этапе загрузки классов и как следствие менять поведение исполняемого кода. Но спасибо @alextokarev и его докладу на Joker 2024, , а также статья на Хабр, который помог мне перейти от теории к практике и написать свой первый javaagent и решить при этом актуальную практическую задачу.
После просмотра доклада, меня заинтересовал данный инструмент для модификации байт-кода. По сути там также как в Spring используется декларативный подход, где с помощью аннотаций, мы можем указать, какой класс и метод, нам необходимо изменить. Все выглядело очень просто и легко. Да и задача у нас очень похожая, они у себя «патчили» Apache Spark, а нам у себя нужно было пропатчить Spring Context, таким образом чтобы после инициализации Bean Definitions вывести информацию о «бинах» и прервать дальнейшую инициализацию контекста, чтобы приложение не стартовало целиком, т.к. это может привести к множеству нежелательный сайд-эффектов, о которых мы писали в предыдущей статье: инициализация БД, веб-сервера и прочее.
Что получилось
Как видно из листинга инициализации контекста, фаза построения Bean Definitions уже закончена после выполнения шага registerBeanPostProcessors и все данные лежат в beanFactory. Нам надо вклинится в этот процесс, вывести в консоль инфо о «бинах» и прервать процесс инициализации. Вот так это выглядит с помощью библиотеки от ytsaurus:
@Decorate
@OriginClass("org.springframework.context.support.AbstractApplicationContext")
public class AbstractApplicationContextDecorator {
@DecoratedMethod
protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {
__registerBeanPostProcessors(beanFactory);
explytPrintBeans(beanFactory);
throw new RuntimeException(SPRING_EXPLYT_ERROR_MESSAGE);
}
protected void __registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {
}
@AddMethod
private void explytPrintBeans(ConfigurableListableBeanFactory beanFactory) {
String[] definitionNames = beanFactory.getBeanDefinitionNames();
for (String beanName : definitionNames) {
BeanDefinition definition = beanFactory.getBeanDefinition(beanName);
System.out.println(definition);
}
} Где мы:
Создаем класс «декоратор» для базового класса контекста Spring —
@OriginClass("org.springframework.context.support.AbstractApplicationContext”);С помощью аннотации
@DecoratedMethodуказываем метод, который мы будем декорировать. Его имя и сигнатура должны совпадать с реальным методом в изменяемом классе;через спец-символ »__» (двойное подчеркивание) указываем что нужно вызывать оригинальный метод »
__registerBeanPostProcessors(beanFactory)». Для него необходимо создать пустую реализацию, совпадающую с оригинальной, чтобы код компилировался.
Вот собственно и все. В новом методе registerBeanPostProcessors мы реализуем нужную нам логику — выводим инфо о бинах и прерываем процесс кастомной ошибкой. Код по выводу бинов, оформлен в виде отдельного метода explytPrintBeans (он приведен в упрощенном виде, для экономии места, полный код в нашем репозитории на GitHub) и чтобы этот метод также попал в инструментируемый класс AbstractApplicationContext, его надо пометить аннотацией @AddMethod. Это уже наша собственная доработка, чтобы можно было вынести часть логики в приватные методы, чтобы код был «чище». Иначе нам пришлось бы писать всю логику в изменяемом методе — registerBeanPostProcessors.
Но возникла небольшая проблема, связанная с тем что данный функционал, является частью проекта ytsaurus и не оформлен в виде какого либо артефакта. Мы попробовали решить эту проблему и оформили его в виде отдельной библиотеки, которая доступна на Maven Central.
Также мы добавили примеры по ее использованию:
пример на простом java проекте, похоже на то как это было на Joker 2024;
пример для Spring Boot проекта по выводу бинов;
вот так это выглядит у нас в плагине.
Больше информации о том как это работает и как запускать примеры, есть в README библиотеки.
В итоге мы смогли решить следующие проблемы:
теперь мы можем анализировать любые Spring проекты, не только Boot. Так как мы патчим базовые классы Spring Context которые являются частью любого Spring проекта.
мы проверяли свой функционал на проектах Spring версии — 3.0. А это на минуточку аж… 2010 год.
мы не зависим от кастомной логики запуска в main методе, т.к. теперь мы не изменяем классы для запуска приложения, а встраиваемся в базовый функционал Spring по созданию контекста.
такой подход по настоящему платформонезависимый и может быть использован для поддержки Spring Dependency Injection для любой IDE.
Рассмотрим на примере как это работает. Возьмем специально старый обычный Spring проект (не Spring Boot) версии 3.0.5.RELEASE, где контекст создается посредством вызова ClassPathXmlApplicationContext в main методе.
org.springframework
spring-core
3.0.5.RELEASE
org.springframework
spring-context
3.0.5.RELEASE

Напротив метода main в gutter мы добавили значок Spring для поиска бинов. При «клике» на котором происходит загрузка бинов из проекта в плагин. Да, для этого надо по прежнему чтобы проект компилировался из IDEA без ошибок. По умолчанию мы пытаемся использовать для этого текущую выбранную «ран» конфигурацию, при условии что она подходит для запуска данного класса, иначе мы создадим ее сами «на лету». Поэтому, если у вас уже есть готовая «ран» конфигурация с дополнительными настройками проекта, то лучше выбрать ее сразу, перед запуском функционала, по получению бинов из Spring.
Теперь запуск процеса для получения информации о «бинах» выглядит вот так:
java -javaagent:explyt-java-agent-0.1.jar -classpath other.jarsВот так это работает на реальном Spring Boot проекте — Spring Petclinic:

После загрузки бинов из проекта, у нас появляется Explyt Spring Tool Window. Где как и раньше отображаются все «бины» проекта и библиотек Spring, разбитые по категориям: контроллеры, репозитории, брокеры сообщений и прочее. После этого процесса, мы максимально точно отображаем информацию о контексте приложения. Если загрузку не выполнять, то будет работать упрощенная логика на основании анализа исходного кода проекта.
Также благодаря нативной загрузке бинов, у нас помимо навигации по проекту, работает еще и навигация по бинам внутри Spring, в результате чего стало гораздо удобнее анализировать его исходники, так мы можем осуществлять переход к реальной имплементации класса, а не к его интерфейсу. На скриншотах ниже мы навигируемся из Bean метода по созданию JdbcTemplate непосредственно к DataSource — HikariDataSource.
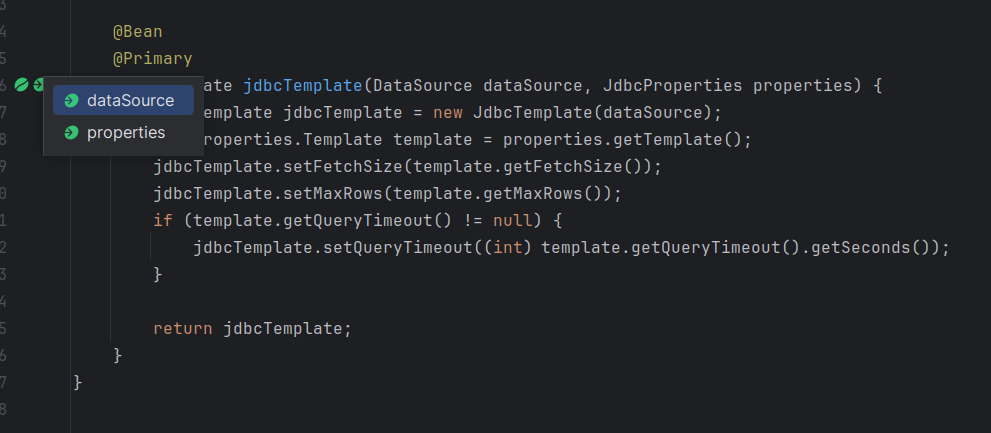

Также как и раньше, но уже с помощью — javaagent мы получаем инфо и о аспектах Spring AspectJ. Кроме нашего плагина и Spring из IDEA Ultimate, мне не известны другие решения, которые умели бы распознавать аспекты и позволять навигироваться от декларации к использованию и обратно.

Заключение
Вот так мы постарались улучшить наш процесс распознавания Spring Context. Теперь нужно лишь чтобы проект успешно компилировался в IDEA. Надеемся что это будет полезно и поможет вам в работе с вашими Spring проектами.
Скачать последнюю версию плагина можно тут или напрямую с GitHub Releases. Поддержка -javaagent для распознавания Spring Context доступна, начиная с версии 2*.1.3375.
Для обратной связи и сообщений об ошибках: github
Для общения: t.me/explytspringchat
Будем рады любой обратной связи и предложениям.
