Эволюция сборки логов «облака» и сборщик логов в open source
 Здравствуйте, меня зовут Юрий Насретдинов, я работаю старшим инженером в Badoo. За последние полтора года я сделал несколько докладов на тему того, как работает наше облако. Слайды и видео можно посмотреть тут и тут.
Здравствуйте, меня зовут Юрий Насретдинов, я работаю старшим инженером в Badoo. За последние полтора года я сделал несколько докладов на тему того, как работает наше облако. Слайды и видео можно посмотреть тут и тут.
Сегодня настало время рассказать о ещё одной части этой системы — о сборщике логов, который мы вместе с этой статьей выкладываем в open-source. Основная часть логики нашего облака написана на языке Go, и эта подсистема не является исключением.
Исходные коды системы: github.com/badoo/thunder
В этой статье я расскажу вам о том, каким образом мы доставляем логи приложений в наше облако, которое мы называем просто «скриптовым фреймворком».
Логи приложений
Наши приложения, запускаемые в облаке, представляют из себя классы на PHP, которые в простейшей реализации имеют метод run () и получают на вход данные задания, например, число от 1 до N, где N — максимальное число экземпляров для этого класса. У каждого задания есть свой уникальный id, и конечной целью является доставка логов в какое-то централизованное хранилище, где можно будет легко найти логи как конкретного запуска, так и все логи класса сразу.
getLogger()->info("Hello, world!");
return true;
}
}
Первая реализация: по файлу на id запуска
Поскольку каждый запуск задания в облаке представляет из себя запуск отдельного PHP-процесса, самым простым и очевидным для нас способом собирать логи каждого запуска по отдельности было перенаправление вывода каждого процесса в отдельные файлы вида …log, где out и err используется для каналов стандартного вывода и ошибок соответственно.
Таким образом, задача сборщика логов состояла в регулярном опросе директории с логами на предмет изменений и отправке новых строк, которые появлялись в файлах. В качестве средства доставки логов на центральный сервер мы использовали scribe, а последнее отправленное смещение запоминалось прямо в имени файла (это работает, если вы продолжаете писать лог в открытый дескриптор файла):
100
if ($filesize > $read_offset) {
sendToScribe($filename, $read_offset); // послать в scribe начиная с $read_offset
rename($filename, replaceOffset($filename, $read_offset); // "id.out.log.100" -> "id.out.log.200"
} else if (finishedExecution($filename)) {
unlink($filename);
}
}
sleep(1);
}
Этот подход нормально работает, пока у вас есть небольшое количество файлов в директории, в каждый из которых более-менее активно пишут. Перенаправление в отдельные файлы позволяет легко отличать вывод каждого запуска по отдельности, даже если приложение делает простое echo вместо использования «логгера», который добавляет в начало строки идентификатор запуска. По сравнению с записью в один и тот же файл, в этом случае невозможно перемешивание вывода от разных «инстансов» приложения. Также легко понять, что в файл больше никто не пишет: если процесс с заданным id уже завершился, то мы можем удалить соответствующий файл с логом, когда он полностью доставлен в scribe.
Однако, у этой схемы есть множество недостатков. Вот основные из них:
- в имени файла не содержится информации об имени класса — эту информацию нужно запрашивать из базы облака;
- в scribe можно легко «засунуть» намного больше данных, чем может успевать обрабатывать сервер-приемник. В такой ситуации scribe начинает буферизовать данные локально в файловую систему, дублируя те логи, которые уже есть на диске;
- если сборщик логов перестает успевать удалять старые файлы, то их может накопиться очень много. У нас несколько раз скапливалось по миллиону файлов на хост, и доставить нужные логи к тому времени, когда они еще были бы актуальны, уже не было никакой возможности;
- файловая система ext3 (и ext4 в меньшей степени) не очень хорошо себя ведет, когда вы постоянно создаете, переименовываете и удаляете много файлов — мы регулярно видели наши процессы «залипшими» на сотни миллисекунд в D-state при записи в файлы и при их создании;
- если вы хотите избавиться от постоянного опроса stat () файлов и начать использовать inotify, вас тоже ждет неприятный сюрприз. Из-за особенностей реализации, особенно хорошо заметных на многоядерных системах с большим количеством свободной памяти, при вызове inotify_add_watch () в директории, в которой регулярно создаются и удаляются файлы, может происходить «залипание» всех процессов, которые пишут в файлы в этой директории, и длиться это может десятки секунд.
Если вас интересуют подробности по поводу причин «плохого» поведения inotify в условиях, описанных в пункте (5), читайте спойлер ниже.
Проблему достаточно легко воспроизвести даже на одноядерной системе с небольшим количеством памяти, хоть и в меньшем масштабе. Те цифры, которые приведены в статье, получены на многоядерной машине с десятками гигабайтов памяти.
Создадим пустую директорию, назовем ее, например, tmp. После этого запустим простой скрипт:
$ mkdir tmp
$ cat flood.php
Все, что этот скрипт делает — 10 миллионов раз выполняет stat () или access () на несуществующие файлы вида fileN, где N — число от 0 до 9 999 999.
Теперь выполним системный вызов inotify_add_watch (начнем следить за изменениями в директории с помощью inotify):
$ cat inotify_test.c
#include
void main(int argc, char *argv[]) {
inotify_add_watch(inotify_init(), argv[1], IN_ALL_EVENTS);
}
$ gcc -o inotify_test inotify_test.c
$ strace -TT -e inotify_add_watch ./inotify_test tmp
inotify_add_watch(3, "tmp", …) = 1 <0.364838>
Флаг -TT для strace заставляет печатать в конце строки время выполнения системного вызова в секундах. Мы получили время в сотни миллисекунд на системный вызов, который добавляет одну пустую директорию в список для уведомлений о новых событиях. В рамках такого простого эксперимента сложно получить наблюдаемые нами десятки секунд на production-системе, но проблема все равно налицо. Давайте создадим новую пустую директорию tmp2 и проверим, что для нее все отрабатывает моментально:
$ mkdir tmp2
$ strace -TT -e inotify_add_watch ./inotify_test tmp2
inotify_add_watch(3, "tmp2", …) = 1 <0.000014>
Можно видеть, что для свежесозданной пустой директории ничего подобного не наблюдается: системный вызов отрабатывает практически мгновенно.
Чтобы выяснить, почему у нас возникают проблемы с директорией, в которой много раз выполнили stat () от несуществующих файлов, давайте немного модифицируем исходную программу так, чтобы она не выходила, и посмотрим результат работы команды perf top для этого процесса:
$ cat inotify_stress_test.c
#include
void main(int argc, char *argv[]) {
int ifd = inotify_init();
int wd;
for (;;) {
wd = inotify_add_watch(ifd, argv[1], IN_ALL_EVENTS);
inotify_rm_watch(ifd, wd);
}
}
$ gcc -o inotify_stress_test inotify_stress_test.c
$ strace -TT -e inotify_add_watch,inotify_rm_watch ./inotify_stress_test tmp
inotify_add_watch(3, "tmp", …) = 1 <0.490447>
inotify_rm_watch(3, 1) = 0 <0.000204>
inotify_add_watch(3, "tmp", …) = 2 <0.547774>
inotify_rm_watch(3, 2) = 0 <0.000015>
inotify_add_watch(3, "tmp", …) = 3 <0.466199>
inotify_rm_watch(3, 3) = 0 <0.000016>
…
$ sudo perf top -p
99.71% [kernel] [k] __fsnotify_update_child_dentry_flags
…
Можно видеть, что почти 100% времени проходит в одном вызове внутри ядра — __fsnotify_update_child_dentry_flags. Наблюдения производились на версии ядра Linux 3.16, для других версий могут быть немного другие результаты. Исходники этой функции можно посмотреть по следующему адресу: git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/fs/notify/fsnotify.c? id=v3.16.
Путем добавления отладочных printk или посмотрев на результаты perf достаточно пристально можно увидеть, что проблема происходит в следующем месте:
/* run all of the children of the original inode and fix their
* d_flags to indicate parental interest (their parent is the
* original inode) */
spin_lock(&alias->d_lock);
list_for_each_entry(child, &alias->d_subdirs, d_u.d_child) {
if (!child->d_inode)
continue;
Для того чтобы начать следить за изменениями в файлах в указанной директории, ядро проходится по структуре dentry, в которой, грубо говоря, содержится кеш вида «filename» => inode data. Этот кеш заполняется даже в случае, когда запрашиваемого файла не существует! В этом случае поле d_inode будет равно нулю, что и проверяется в условии. Таким образом, при вызове inotify_add_watch, ядро проходится по своему (в нашем случае огромному) dentry-кешу для указанной директории и пропускает все элементы, поскольку директория на самом деле пустая. В зависимости от размера этого кеша и от «конкурентности за локи» системный вызов может занимать весьма продолжительное время, блокируя при этом возможность работы с этой директорией и содержащимися внутри файлами.
К сожалению, проблема легко не решается и является архитектурной проблемой VFS-слоя и подсистемы dentry. Одним из очевидных и простых решений является наложение ограничений на максимальный размер кеша для несуществующих записей, однако это требует серьезной переделки архитектуры VFS и переписывания большого количества функций, которые рассчитывают на текущее поведение. Наличие счетчиков для кеша несуществующих файлов также наверняка ухудшит производительность подсистемы VFS в целом. Когда мы разобрались в причинах возникновения этой проблемы, то решили не пытаться ее исправить, а обойти: мы больше не создаем файлов с уникальными именами в директориях, за которыми следим с помощью inotify, и тем самым не забиваем dentry cache. Такой способ вполне решает нашу проблему и не создает значительных неудобств.
Проблему с необходимостью делать запросы в базу облака можно было бы решить добавлением имени класса в файл, а вот с остальными все не так радужно. Чтобы сохранить возможность разделять вывод от разных экземпляров одного и того же приложения, не заставляя пользователей использовать наш логгер, можно было бы перенаправлять вывод приложений не в файлы, а в «пайпы» (unix pipes), однако это создает новую проблему — если требуется обновить код прокси (который осуществляет запуск PHP-классов), работа текущих задач может прерваться при попытке записи в «сломанную трубу» (broken pipe).
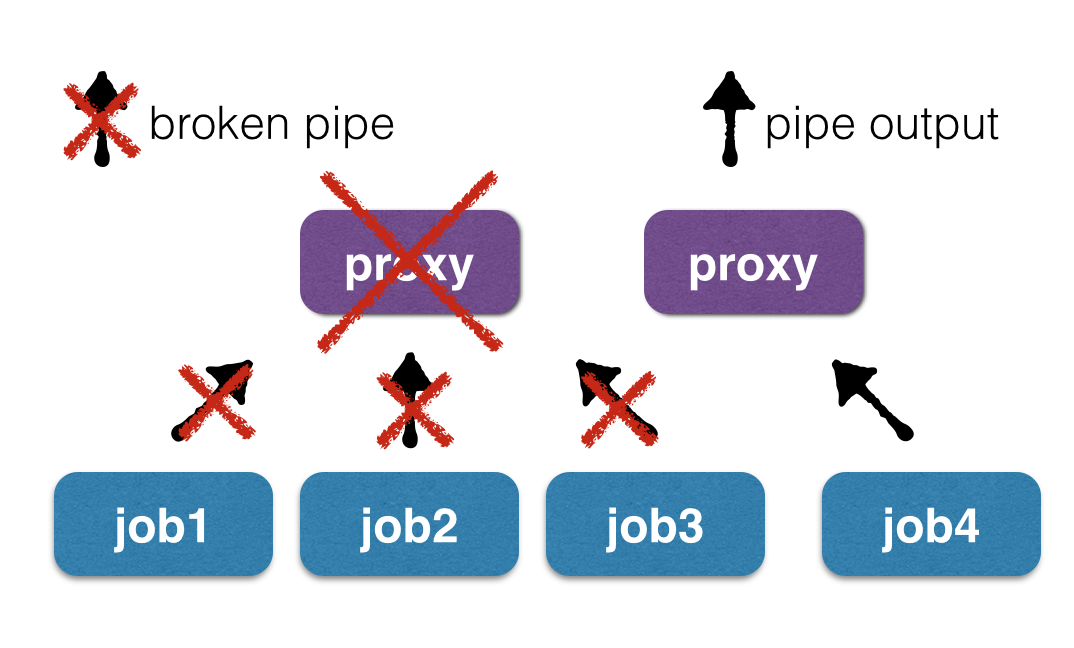
Это происходит, потому что при рестарте демона все дескрипторы, соответствующие читающей стороне пайпа, закрываются, и при попытке последующей записи в них процессы будут получать SIGPIPE, завершаясь. Кстати говоря, именно на этом механизме основана работа цепочек unix-команд с использованием утилиты head и других: команда cat some_file.txt | head не приводит ни к каким сообщениям об ошибке, потому что после прочтения необходимого количества строк команда head просто выходит, соответствующий pipe «ломается» и процесс cat, продолжающий писать в свой конец «пайпа», получает сигнал SIGPIPE, который просто завершает его исполнение. Если в цепочке было несколько процессов, то эта же ситуация произойдет с каждым элементом цепочки, и все промежуточные приложения благополучно выйдут по сигналу SIGPIPE.
Можно заменить «обычные» unix pipes на «именованные» named pipes, то есть продолжать писать в файлы, только они будут иметь другой тип — named pipes. Однако, чтобы иметь возможность легко переживать падения и рестарт прокси, нужно куда-то класть информацию о соответствии имени файла и id запуска. Одним из таких вариантов является непосредственно имя файла, что возвращает нас к исходной проблеме. Другие варианты заключаются в том, чтобы хранить это в отдельной базе, к примеру, в sqlite или rocksdb, но это кажется слишком громоздким для такой, казалось бы, простой задачи, а заодно добавляет проблемы двухфазного коммита (когда в pipe сообщили новый id запуска, а читающий процесс в это время умер, запись в базе не обновится, и следующая инкарнация читающего процесса будет считать, что id запуска все еще старый).
Решение
Какие свойства должно иметь новое решение?
- Устойчивость к перезапуску и падению любых компонентов — прокси, сборщика логов и сервера-приемника.
- Если один из классов пишет столько логов, что они не успевают обрабатываться, логи остальных классов все равно должны доставляться за приемлемое время и быть доступны для просмотра разработчиками.
- При проблемах с доставкой логов ситуация не должна выходить из-под контроля и должна быть легко исправима вручную (например, не должны создаваться миллионы файлов).
- По возможности, система должна быть real-time и иметь большой запас пропускной способности.
Из-за описанных выше проблем с inotify и засорением dentry cache, новая схема должна всегда писать в файлы с одними и теми же именами. В качестве простого и логичного решения представляется писать вывод приложений в файлы вида имя_класса.out.log и периодически их ротировать, называя, к примеру, имя_класса.out.log.old. К сожалению, запись логов от разных инстансов в один и тот же файл требует модификации приложений: если раньше допустимо было делать простое echo, то в новой схеме придется всегда использовать логгер, который добавляет к каждой строке пометку с идентификатором запуска. Использование flock () при одновременной записи также нежелательно, поскольку это сильно снижает производительность и может вызвать ситуацию, когда один «залипший процесс» может заблокировать исполнение всех остальных инстансов этого приложения на текущем сервере. Вместо использования flock () можно просто открывать файл в режиме O_APPEND (флаг a) и писать блоками не более 4 Кб (в Linux), чтобы каждая запись была атомарной.
Таким образом, пункты 1 и 3 мы решили путем простой записи в «файл-на-класс» вместо «файла-на-запуск».
Как собирать логи?
Итак, решение для проблем с inotify, большим числом файлов и устойчивостью к падению прокси мы решили. Осталось теперь понять, как эти логи собирать. Логичным решением было бы просто оставить scribe или использовать его аналоги, например, syslog-ng и прочие. Однако, по факту, мы и так пишем логи в файлы, поэтому можно было бы вместо этого написать простую «стримилку» содержимого этих файлов на центральный сервер. Схема будет выглядеть следующим образом:
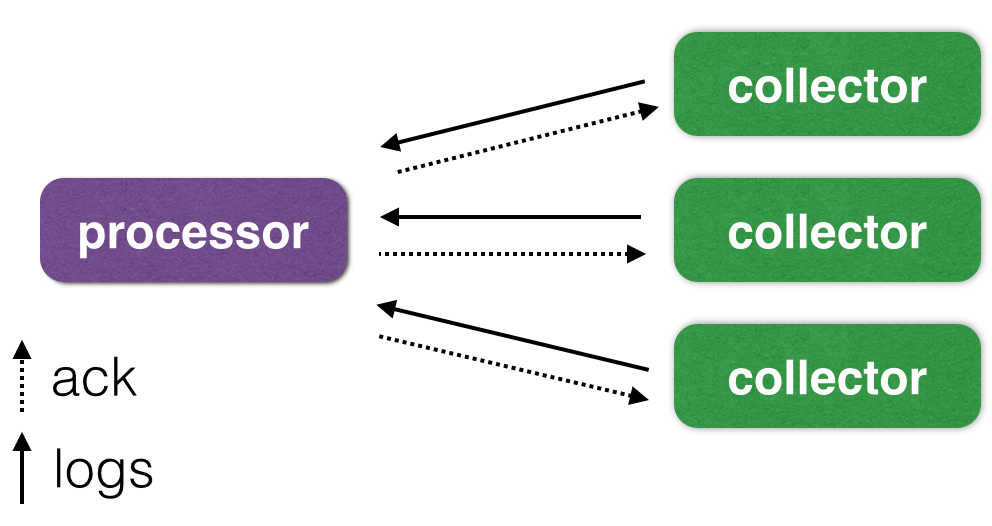
Как можно видеть на рисунке, у нас есть 2 большие подсистемы: сервер-приемник (processor) и сборщики логов на каждой машине (collector).
Общение между приемником и сборщиками осуществляется с помощью постоянно установленного TCP/IP соединения, а для упаковки пакетов используется Google Protocol Buffers. Коллекторы с помощью inotify отслеживают изменения в файлах и отправляют пакеты с новыми строками в приемник. Тот, в свою очередь, присылает обратно полученные им (и успешно записанные в файл с логом) смещения в файлах на исходном сервере.
Приемник периодически (раз в секунду в нашей реализации) сбрасывает новые смещения в отдельный файл в формате JSON в виде списка [{Inode: …, Offset: …}, …]. Такая схема позволяет быть устойчивой к сбоям сети, но не защищает от сбоев питания и kernel panic на серверах. Эта проблема для нас несущественна, поэтому приемник отсылает подтверждения о записанных данных после успешного вызова write (), не дожидаясь реального сброса данных на диск. При сбоях сети, приемника и сборщика, последние строки могут быть доставлены 2 и более раз, что нас тоже устраивает. Если вам нужна не только гарантированная, но и однократная доставка, вы можете прочитать о намного более сложной системе, которую построил Яндекс: habrahabr.ru/company/yandex/blog/239823.
«Троттлинг» доставки отдельных классов
Как я уже говорил, нас не устраивало то, что один сильно «флудящий» скрипт мог полностью забить пропускную способность и затормозить обработку всех остальных логов. Такое случалось, поскольку в scribe можно писать намного быстрее, чем будет происходить доставка до приемника, а обработка событий из scribe у нас была однопоточной из-за необходимости соблюдать порядок следования строк в логах хотя бы в пределах одного задания.
Решение этой проблемы достаточно простое: нужно сделать аналог «вытесняющей многозадачности», т.е. за один проход обрабатывать не более N строк в файле, после чего переходить к следующему. Когда все отправленные куски для «нормальных» логов будут получены на сервере, можно вернуться к отправке «жирного файла» и действовать по тому же алгоритму. Таким образом, доставка «большого файла» имеет ограниченное влияние на систему: логи всех оставшихся классов продолжают доставляться с фиксированным опозданием, которое регулируется максимальным размером пачки N. В остальном скорость доставки ничем искусственно не ограничивается — если активная запись идет только в один файл, он будет доставляться с максимально возможной скоростью.

Ротация файлов
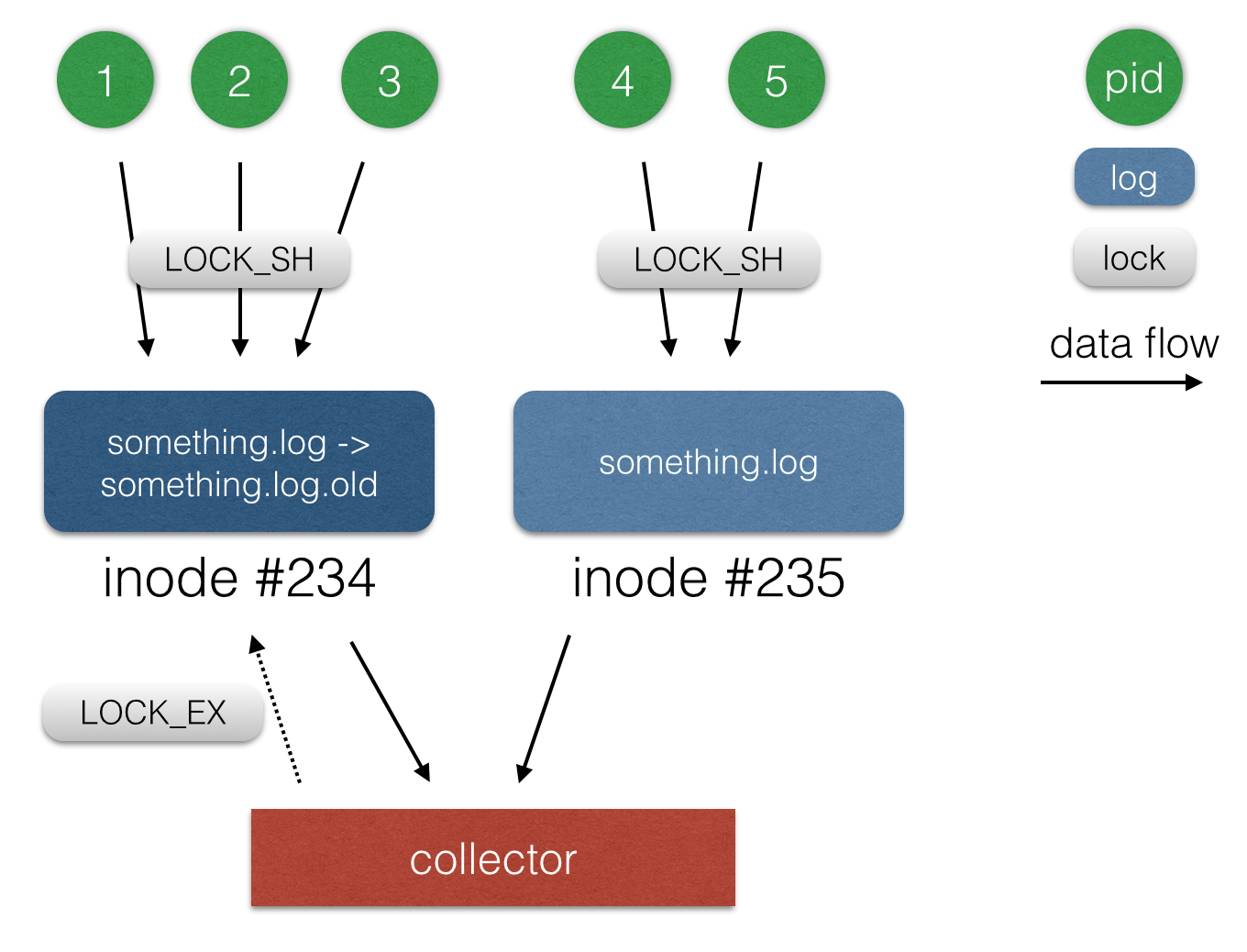
Для того, чтобы логи со временем не занимали все место на сервере, необходимо их ротировать. Ротацией логов называется процесс удаления самого старого файла с логом и переименования более свежих файлов в «старые». В нашем случае под ротацией подразумевается удаление старого файла с логом и переименование текущего (class_name.out.log → class_name.out.log.old). При переименовании файла все процессы, которые держат этот файл открытым, могут продолжать с ним работать, в нашем случае — писать. Поэтому нам нужно продолжать отправлять изменения, произошедшие как в новом, так и в старом файле с логом. У файла при переименовании также сохраняется inode, поэтому в базе мы храним успешно отправленные смещения в файлах именно для inode, а не для имен файлов.
Еще одна небольшая проблема, связанная с ротацией, заключается в том, что перед его удалением нам нужно каким-то образом определить, что в файл больше никто не пишет. Поскольку все приложения пишут в файлы с использованием флага O_APPEND, не используя flock (), мы можем использовать flock () для какой-нибудь другой цели. В нашем случае приложение перед началом работы берет разделяемую блокировку (LOCK_SH) на файловый дескриптор, в который оно пишет. Чтобы убедиться, что файл больше не используется, нам остается попробовать взять эксклюзивную блокировку (LOCK_EX). Если блокировку удалось получить, значит, файл больше не используется, его можно удалить. В противном случае нам нужно ждать, пока файл с логом освободят, и временно откладывать его ротацию.
Производительность, выводы
Поскольку предыдущая версия сборщика логов работала в один поток и была написана на PHP, сравнение будет не очень честным. Тем не менее, хотелось бы привести результаты и для старой, и для новой архитектуры.
Старая система (PHP, один поток) — 3 МиБ/сек на сервер — вполне достойный результат для PHP.
Новая система (Go, полностью асинхронная и многопоточная) — 100 МиБ/сек на сервер — упирается в сетевую карту и диски.
В результате переделки системы сборки логов мы решили все проблемы, которые у нас с ней были, и получили огромный запас по скорости доставки, а также устойчивость к «флуду» отдельных классов — теперь один скрипт не может замусорить всю систему и вызывать многочасовые задержки в доставке. Также, хотелось бы отметить, что на языке Go задача решается просто и элегантно, с великолепной производительностью конечного решения и низким требованиям к ресурсам.
Ссылки
Open-source реализация сборщика: github.com/badoo/thunder
Другие наши open-source проекты: tech.badoo.com/open-source
Юрий youROCK Насретдинов
Lead PHP developer
