Эволюция приложений или куда мы идем
Называть статью «Эволюция прикладных информационных систем и перспективы развития их архитектуры» было бы слишком академично, а ведь тут будет очень краткая выжимка из реального практического опыта, возможные варианты развития технологий, вызвавшие их потребности и пути решения. Я надеюсь, что статья поможет обобщить и переосмыслить широкий круг задач, связанных с прикладными ИС, и сразу хочу уточнить, что понимаю под этими терминами. ИС — это системы, обеспечивающие обработку, передачу и хранение данных. Это далеко не все программирование, но сейчас ИС чаще всего ассоциируются с веб и мобильными приложениями, хотя и не совпадают с ними полностью, знак равенства между UI и ИС нельзя ставить тем более. Очень прошу всех посмотреть на вопрос как можно шире и присоединяться к обсуждению в комментариях. И еще, я намеренно не буду использовать названия фреймворков и технологий, чтобы избежать лишних холиваров, ограничившись общепринятыми названиями архитектур, стандартов и протоколов, что и вам рекомендую в комментариях.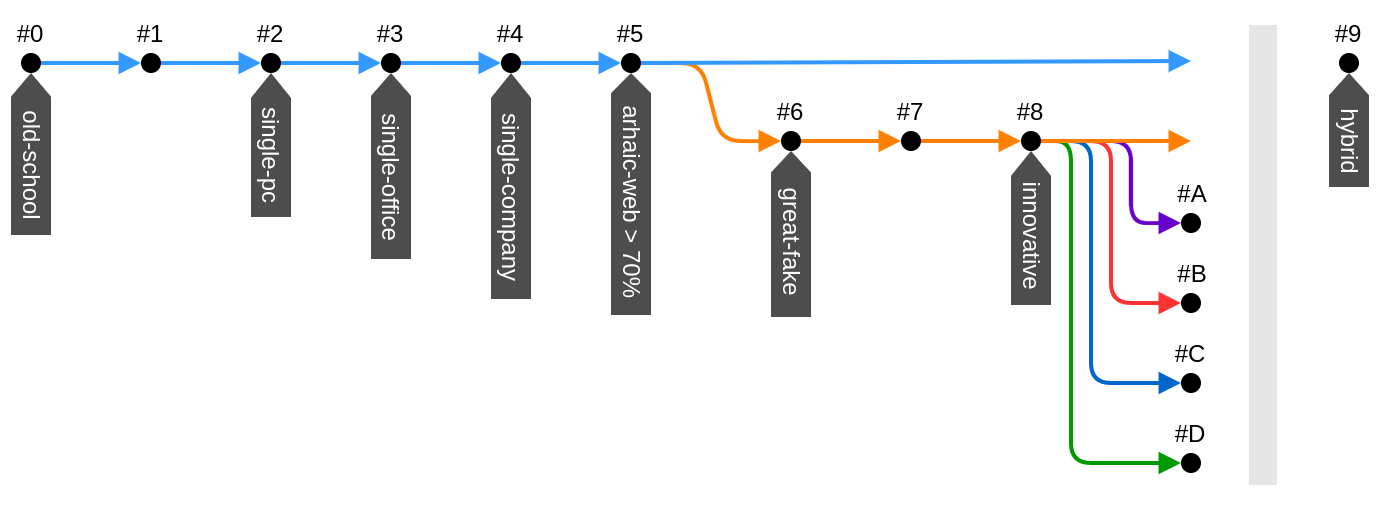
Разветвления в технологиях случались много раз в истории, но за периодом неопределенности всегда следует этап устойчивого развития, когда несущественные ветки уходят в тень, а актуальные особенности объединяются в самый жизнеспособный гибрид. Для начала мы кратко проследим, как ИС развивались с самого их появления. Чтобы воспоминания нахлынули, нам хватит всего 9 строк и картинки.
| Архитектура | Основные особенности | Обмен |
|---|---|---|
| #0 Data files | Все хранили свои данные в файлах разных неведомых форматов | файлы |
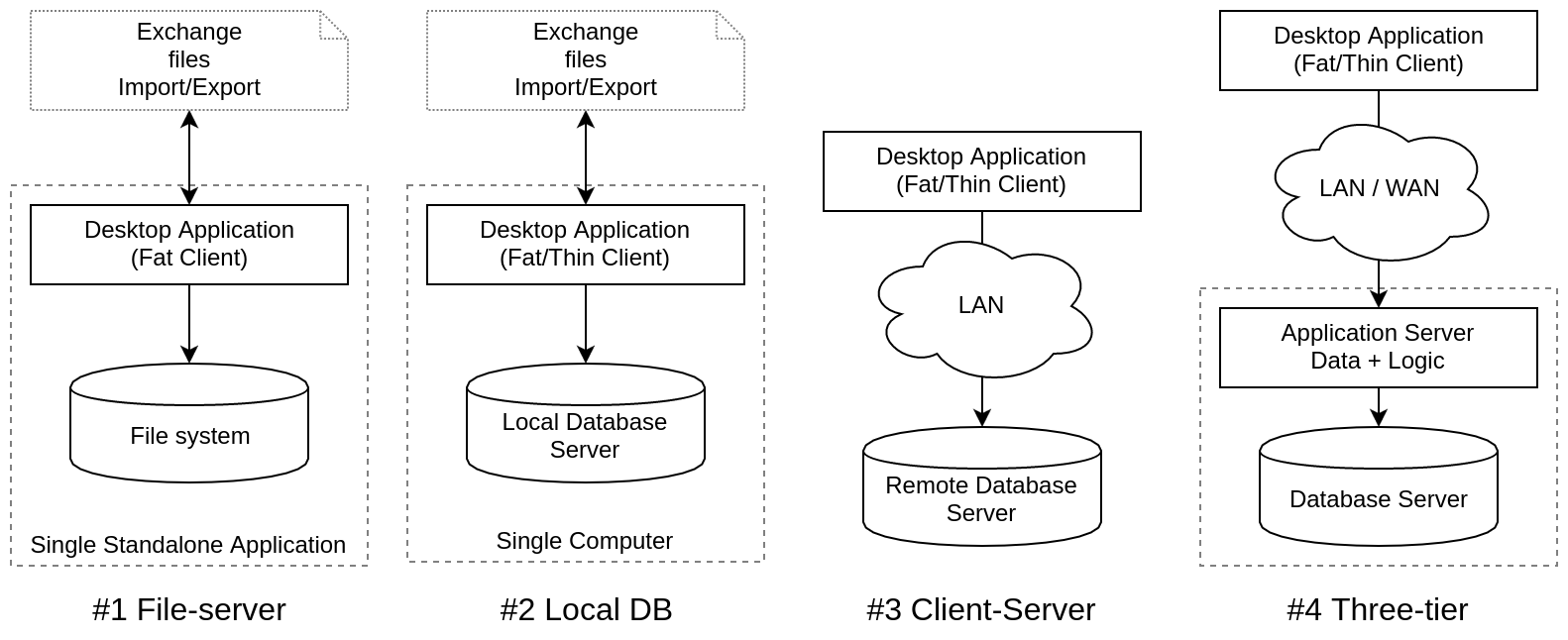
| #1 File-server | Движки БД, работающие в одном процессе с приложением | файлы |
| #2 Local DB | СУБД выделились в отдельные процессы — сервера СУБД | IPC |
| #3 Client-Server | СУБД доступны по локалке разным типам АРМов (клиентских рабочих мест) | RPC |
| #4 Three-tier | Выделился слой сервера приложений, трехзвенка, работа из удаленных офисов | RPC |
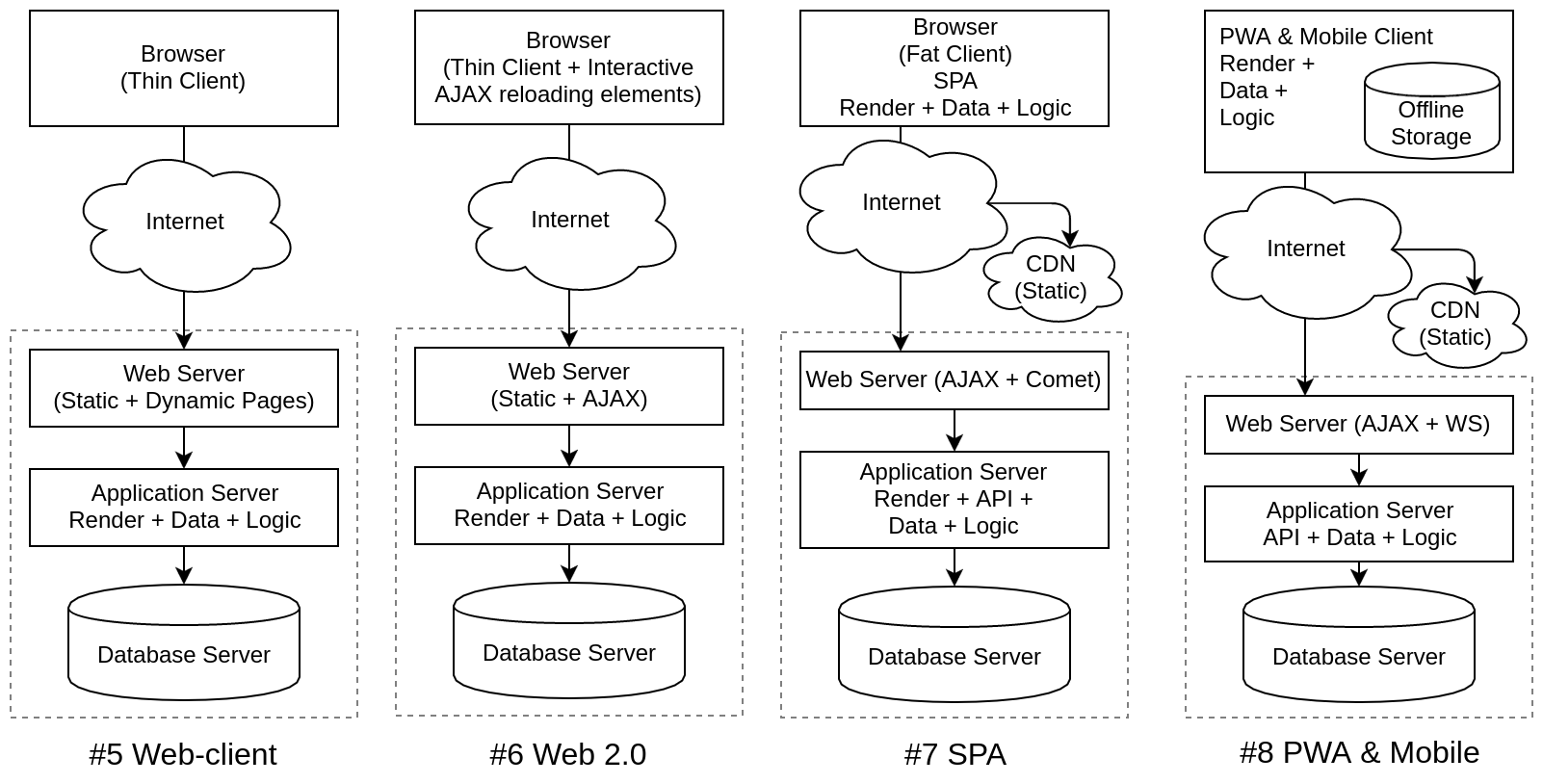
| #5 Web-client | Появились тонкие клиенты для доступа к данным из веб-браузера | HTTP |
| #6 Web 2.0 | Частичная интерактивная перезагрузка элементов через AJAX, Comet, SSE | AJAX |
| #7 SPA / WebApp | Полнофункциональные браузерные приложения без перезагрузки страниц | AJAX |
| #8 PWA & Mobile | Progressive Web Application и мобильные приложения | HTTPS |
Я не указывал времени существования для архитектур, потому, что и сейчас в своих нишах параллельно существуют почти все из перечисленных решений. Для современных ИС преобладающая технология все еще #5, т.е. обычные веб страницы с перезагрузкой по ссылкам (тонкий клиент) и всей логикой на сервере. Для многих задач большего и не нужно. На переднем краю #8, тут веб-приложения и мобильные приложения слились архитектурно, хоть и имеют множества отличий в технологиях и реализации. Что же дальше? Тенденции уже наметились: сервер это API, базы данных на клиенте, рендеринг на клиенте, богатый GUI, работа в оффлайне, высокие нагрузки и много пользователей. Но технологически эти потребности удовлетворяются настолько разными платформами, что произошло разветвление. Это в равной степени актуально и для веба и для мобильных приложений. Нужно сказать, что для десктопных приложений ситуация тоже совпадает, с некоторыми оговорками, но они сейчас не в тренде и мы будем подразумевать, что следующие 4 варианта развития могут быть применены к прикладным ИС вообще.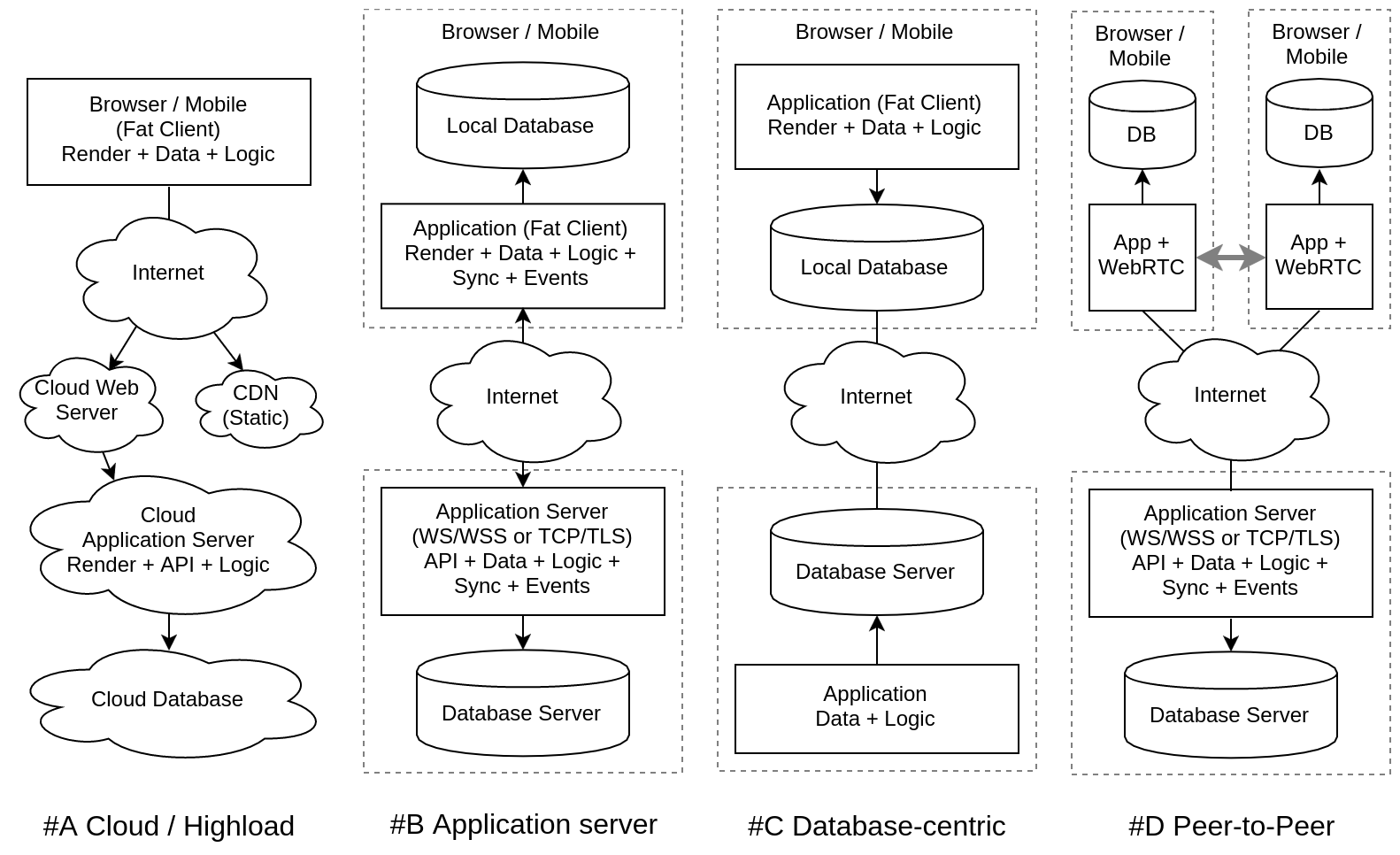
Обслуживание высоких нагрузок облаком (#A Cloud Highload)
Преимущества: Облака прекрасно справляются с масштабированием, используя принцип REST, приложения могут обслуживать десятки миллионов абонентов, если отказываются от состояния, т.е. серверные процессы не хранят состояния в памяти, все сетевые вызовы независимы и не переводят сессию ни в какое состояние.
Недостатки: В реальных приложениях часто отходят от REST именно потому, что для решения задачи нужно состояние. Получается псевдо-REST, не масштабируемый, но с кучей ограничений. А главное, совершенно не подходящий для приложений, интерактивно взаимодействующих с пользователем или обеспечивающих взаимодействие между пользователями.
Вывод: Во многих случаях это оптимальное решение: публикация контента, информационные ресурсы, СМИ, могут быть эффективно построены в облаке, но для сложных приложений с базами данных и интерактивностью, это шаг назад от архитектуры #8.
Сервера приложений (#B Application servers)
Преимущества: Место веб-сервера занимает сервер приложений, т.е. не приложение запускается под управлением веб-сервера, а веб-сервер встраивается в приложение или сервер приложений. Более того, для повышения эффективности, HTTP/HTTPS могут быть заменены специализированными протоколами на базе TCP/TLS. Особенно это актуально для мобильных и десктопных приложений, что дает возможность строить RPC, шину событий, синхронизацию БД.
Недостатки: Такие приложения пока не имеют универсальных облачных решений, но все идет к тому, что они скоро появятся. А до этого, нужно изобретать свой стек технологий и самим строить приватное облако. Это сложно поддерживать и обслуживать. Кроме того, синхронизация БД на сервере и клиенте делается вручную, через приложение, обычно сверхусилями разработчиков, а использовать такие решения повторно обычно не удается.
Вывод: Это направление сейчас доступно только крупным компаниям, имеющим потребность в обслуживании миллионов пользователей, создании интерактивных приложений или R&D лабораториям, готовящим подобные решения для массового пользователя.
БД-центрический подход (#C Database-centric)
Преимущества: Очень привлекательно поставить БД вперед приложения и настроить синхронизацию (частичную репликацию) между базами данных. Таким образом, мы имеем СУБД встраиваемые в приложения и работаем не с сервером, а с локальной БД. Для этого уже придумано множество методов: optimistic replication, operational transformation, conflict-free replicated data type, ведь СУБД существуют уже достаточно давно и научились масштабироваться.
Недостатки: Общение между приложениями только через данные явно ограничивает наши возможности. Это редукция всего к работе с базой. А как же передача событий, интеграция на уровне API, вызов удаленных процедур? Обо всем этом нужно забыть при БД-центрическом подходе.
Вывод: Для определенного класса задач это шикарное решение, а вместе с интроспекцией и скаффолдингом UI такая архитектура автоматически «раскатает» в очень широкой сфере применения более сложных конкурентов, интегрирующихся при помощи API и требующих все время писать взаимодействие программно.
Одноранговое или пиринговое взаимодействие (#D Peer-to-Peer)
Преимущества: Это разгрузит сервера, которые будут выполнять только функцию связывания/брокера. Локальное взаимодействие между пользователями часто более эффективны, чем через удаленный сервер, особенно при больших потоках данных. Дает надежду на анонимность обмена приватными данными.
Недостатки: Вопрос «доверия» в пиринговых сетях все еще полностью не преодолим. Строить распределенные ИС только на P2P не получится, сервера все равно будут в этой схеме. Пока нет распространенных протоколов, библиотек, фреймворков и других программных средств для реализации в объеме, необходимом для построения прикладных ИС.
Вывод: Элементы одноранговых сетей будут встраиваться в централизованные ИС.
Обобщение тенденций
Какой гибрид выйдет в итоге слияния этих направлений, пока не ясно, но уже можно построить несколько предположений и, как минимум, выделить тенденции.
Уже очевидно, что ветвление архитектур на этом этапе будет происходить, в первую очередь, за счет встраивания системных компонентов в само приложение:
- Встраиваемые в приложение коммуникационного сервера: HTTP/WS, HTTPS/WSS, TCP/TLS и т.д.
- Встраиваемые в приложение СУБД с автоматической синхронизацией.
- По аналогии можно вспомнить и про еще одну функцию ИС, это обработка данных или вычисления. Так что, встраиваемые в приложения систем распределенных вычислений рано или поздно тоже произойдет. Ведь пользовательские устройства в наше время обладают большой вычислительной мощностью и не использовать их для распределенной обработки данных, это непозволительное архитектурное упущение.
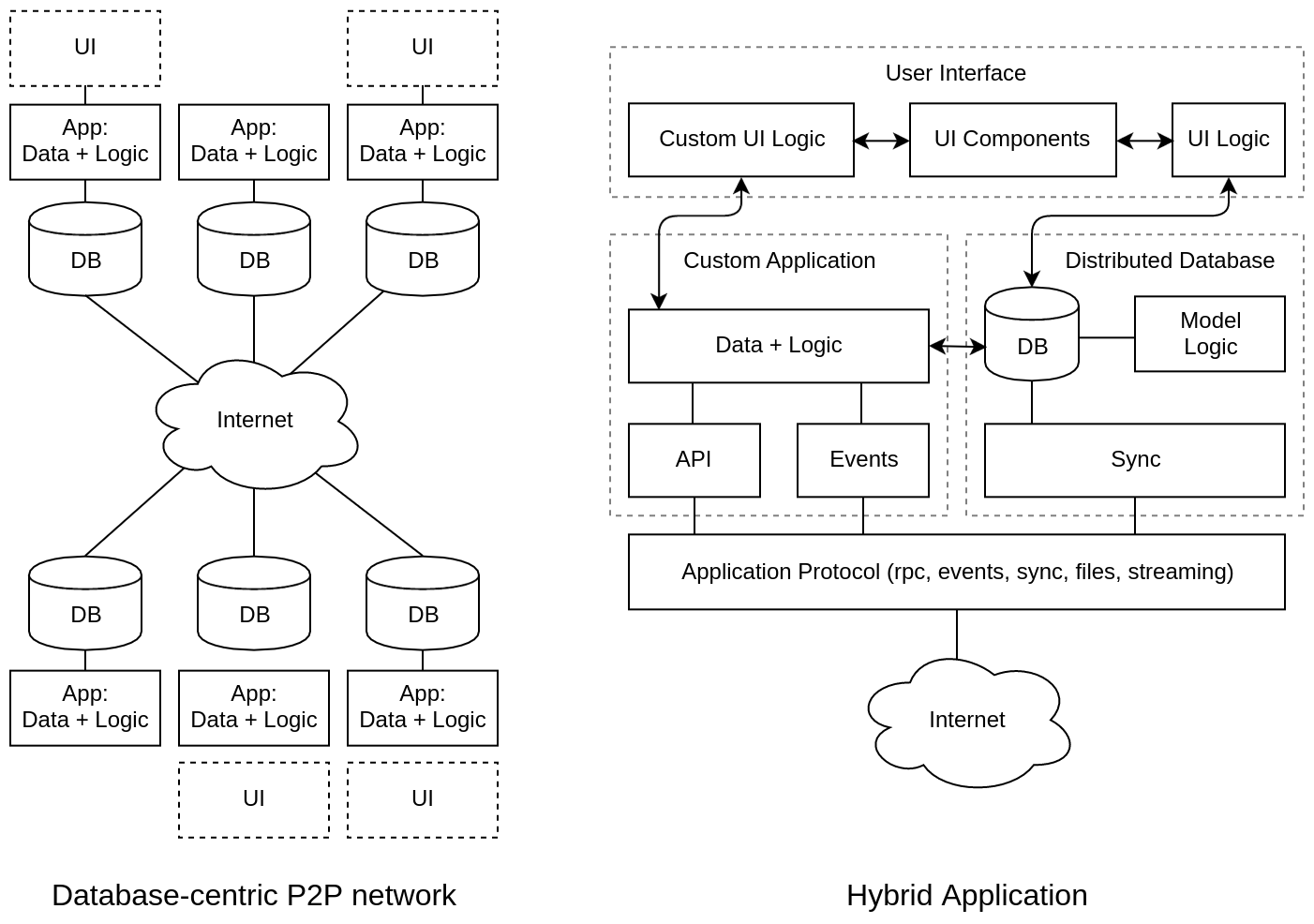
Лично я хочу объединить Data-centric архитектуру (которая, по принципу Парето, накроет 80% потребностей полной автоматизацией) с сервером приложений (который даст возможность сделать интеграцию на уровне API или шины событий для оставшихся 20% случаев). Для этого протокол взаимодействия ИС должен поддерживать одновременно 5 типов взаимодействия: RPC, REST, Event BUS, DB Sync, Binary streaming. Над таким комплексным решением и работает сейчас наша команда.
Кроме четырех крупных архитектур можно строить гибриды из комбинации отдельных возможностей:
- Synchronization — синхронизация структур данных между приложениями в распределенных системах в режиме времени, приближенном к реальному;
- Offline — возможность работать с частью данных, сохраненных в локальном хранилище в браузере или мобильном приложении, а при выходе в онлайн синхронизировать;
- Interactivity — возможность двустороннего обмена событиями с сервером и построение реактивных компонентов: UI, курсоров баз данных, логики приложения, обмена по сети и т.д.;
- Low latency (или High availability) — характеристика готовности обработки запросов и оптимизация времени отклика сервера (не путать с пропускной способностью);
- Highload — обработка интенсивного потока запросов (request per second), что включает их частоту, размер, приоритет, время ожидания в очереди, время жизни и ресурсы для обслуживания;
- High connectivity — большое количество конкурентных (одновременных и долгоживущих) соединений клиентов к серверу с возможностью двустороннего обмена данными по инициативе любой из сторон;
- High interconnection — характеристика интенсивности взаимодействия между конкурентными соединениями, а также размер взаимодействующих групп соединений;
- Scalability — группа характеристик горизонтального и вертикального масштабирования, обеспечивающих прозрачность масштабирования для программных и аппаратных средств (без переписывания кода);
- Big data — возможность обрабатывать большие объемы данных, например потоковая обработка данных или построение запросов к распределенным хранилищам;
- Big memory и in-memory DB — высокая утилизация объемов памяти или перенос баз данных полностью в оперативную память с дополнительными индексами для быстрого исполнения запросов;
- Integration flexibility — характеристика гибкости и простоты интеграции решений, на базе интроспекции, автоматического связывания интерфейсов, скаффолдинга и динамической интерпретации метамоделей.
Для того, чтобы мы все понимали тенденции, предлагаю ответить на вопросы, а так же, буду благодарен за конструктивную критику и комментарии.
