Это не чат, это GigaChat. Русскоязычная ChatGPT от Сбера

Дракончик ждёт вас ниже
Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерами нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»
Затравка

Готовимся к колонизации Марса
Для начала напомним читателям, что языковая модель — это сущность, которая вбирает в себя знания из текстов, после чего может быть использована для понимания машиной текстовой информации. Мы используем языковые модели каждый день: набирая сообщение в телефоне или при поиске чего-то в интернете, мы видим их предложения.
Простые виды таких моделей могут считать вероятности переходов между всеми возможными вариантами символов, а при генерации выдавать самый очевидный вариант.
Самые сложные на сегодняшний день модели имеют так называемую трансформерную архитектуру. Корни этого подхода берут начало в уже классической статье «Attention is all you need». Если хочется сформировать классификацию этих моделей, то можно обратиться к диаграмме из очень содержательного обзора «Transformer models: an introduction and catalog»:
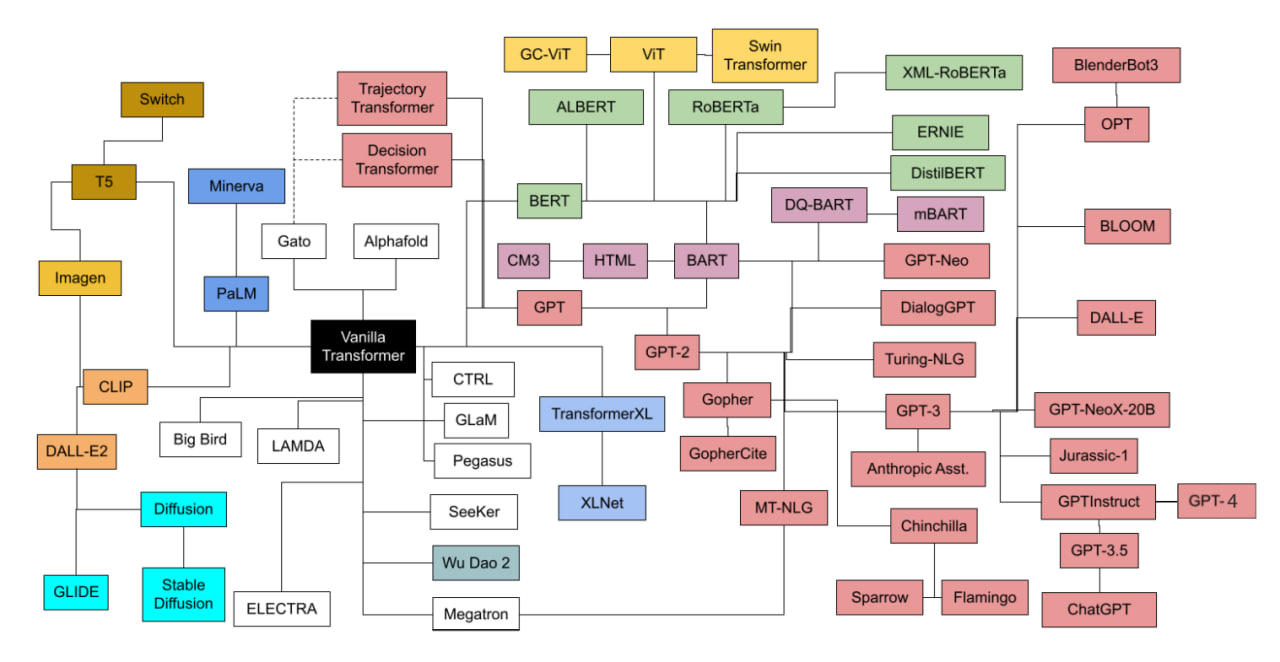
Взято из статьи «Transformer models: an introduction and catalog»
Главный объект внимания располагается в нижнем правом углу и представляет собой семейство моделей, обученных с применением инструкций. Что же это такое и как это работает?
Общий подход для тренировки подобных моделей (RLHF) примерно такой:
Взять предобученную языковую модель. В сообществе сейчас процветает подход с дообучением модели LLaMA, которая существует в нескольких размерах и «видела» немного текстов на русском, однако лицензия позволяет использовать её лишь в исследовательских целях.
