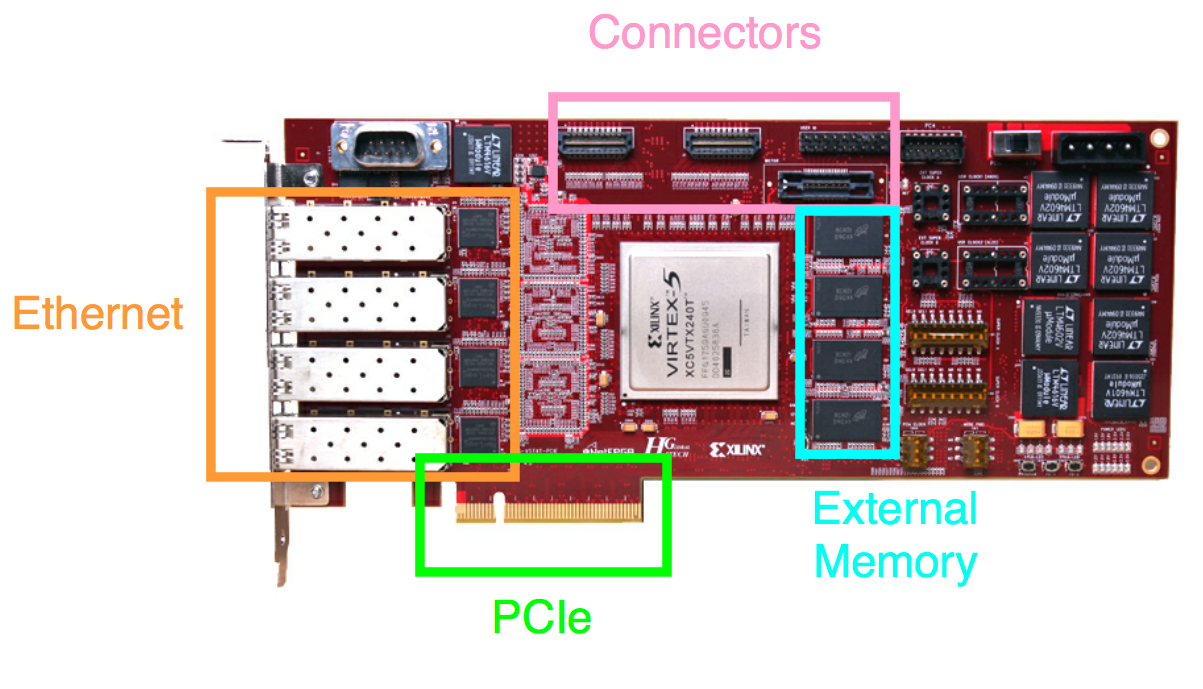
Ethernet + PCIe + FPGA = LOVE

Доступ по Ethernet невозможен без сетевых карточек (NIC). На небольших скоростях (до 1G) NIC встраивают в материнки, а на больших (10G/40G) NIC размещается на отдельной PCIe плате. Основном ядром такой платы является интегральный чип (ASIC), который занимается приемом/отправкой пакетов на самом низком уровне. Для большинства задач возможностей этого чипа хватит с лихвой.
Что делать, если возможностей сетевой карточки не хватает? Либо задача требует максимально близкого доступа к низкому уровню? Тогда на сцену выходят платы с перепрограммируемой логикой — ПЛИС (FPGA).
Какие задачи на них решают, что размещают, а так же самых интересных представителей вы увидите под катом!
Осторожно, будут картинки!
План:
Применения FPGA-плат
DPI, фильтрация и фаервол
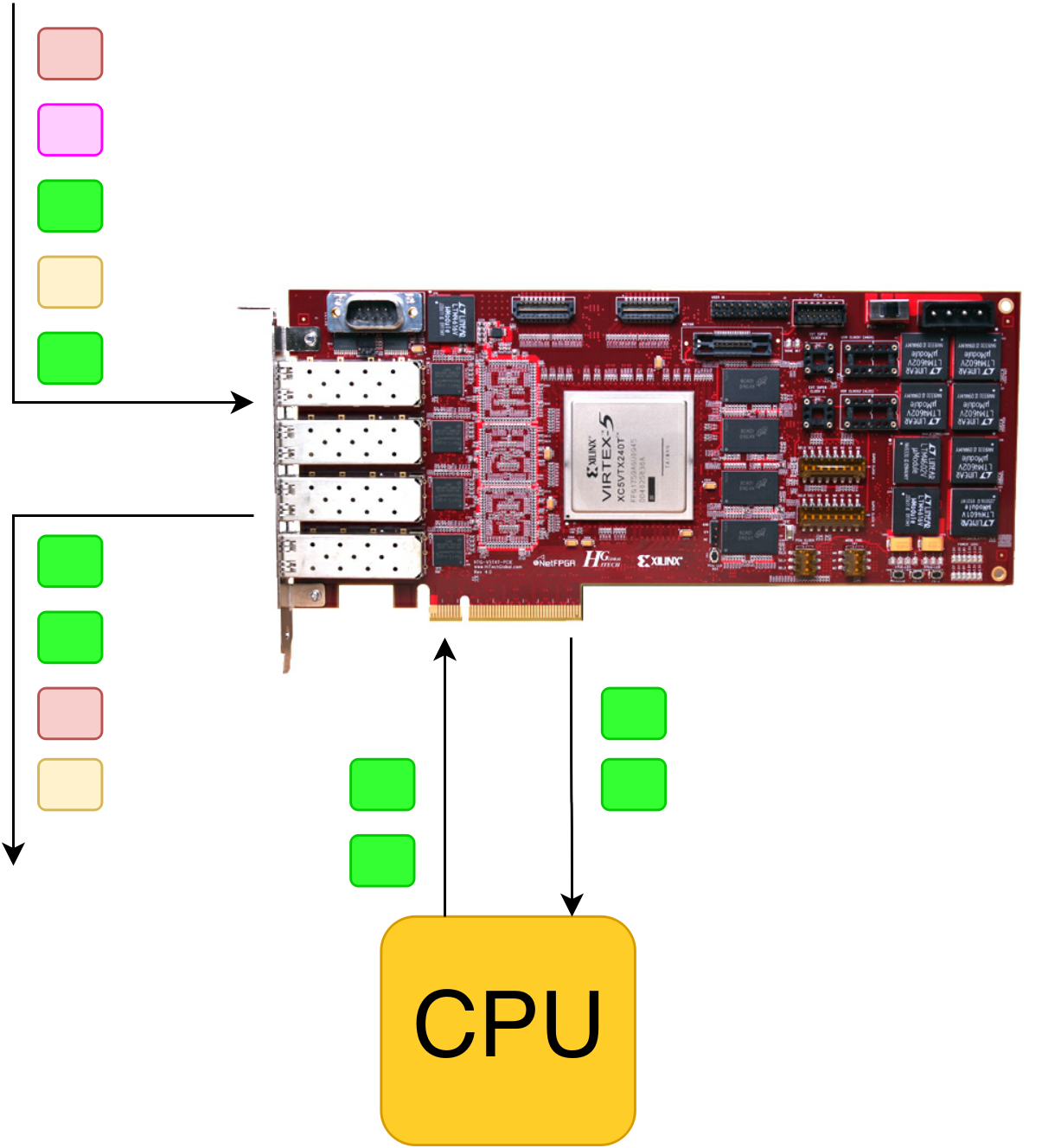
Сервер с такой платой может встать в «разрыв» и мониторить все пакеты, проходящие через него. Интеллектуальный DPI реализуется на базе процессора, а переброска пакетов и простая фильтрация (например, много правил 5-tuple) реализуется на базе ПЛИС.
Как это можно сделать:
- Потоки, которым мы доверяем, либо решение по ним уже находится в таблице по FPGA, проходят насквозь чипа с небольшой задержкой, остальные копируются на CPU и там делается обработка.
- FPGA может снимать часть нагрузки с CPU и искать подозрительные сигнатуры у себя, например, по алгоритму Блума. У этого алгоритма есть вероятность ложно-положительного срабатывания, поэтому если в пакете нашлась строчка, на которую среагировал Блум, то такой пакет копируется на CPU для дополнительного анализа.
- На процессоре обрабатывается только тот трафик, который интересен — FPGA отбирает по заданным критериям пакеты (например, HTTP-запросы или SIP трафик) и копирует их на CPU, всё остальное (торренты, видео и пр.) проходят через FPGA без значительной задержки.
Все эти три варианта могут быть скомбинированы в различных вариациях. Так же FPGA может делать какую-нибудь еще грязную работу, например, выступать в качестве шейпера/полисера, либо собирать статистику по потокам.
На иллюстрации выше зеленые пакеты обрабатываются на CPU, бордовые и желтые прошли через фильтры в FPGA, а розовые были дропнуты (тоже в FPGA).
Анализ и захват трафика
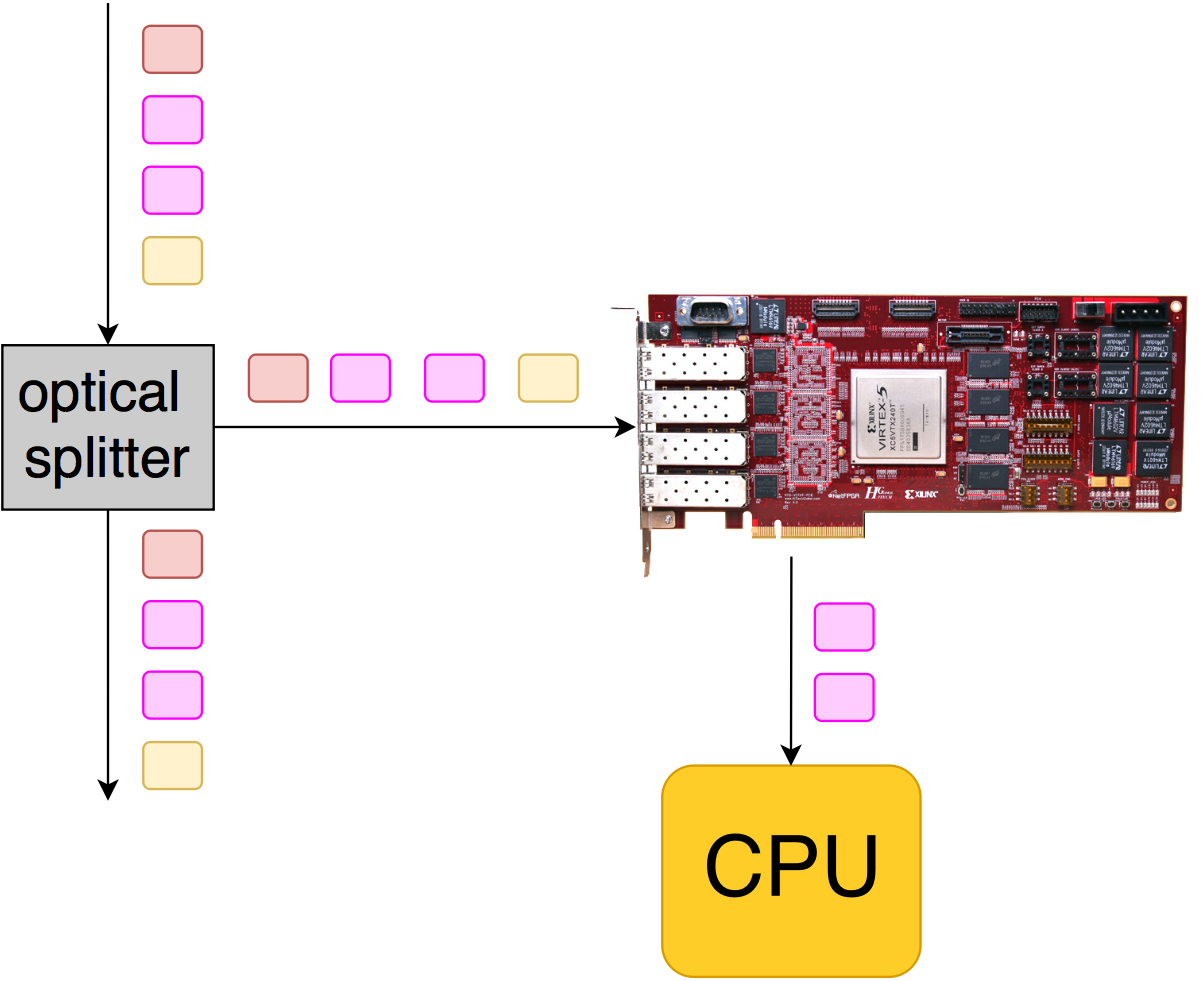
Иногда такие платы используют для захвата трафика и дальнейшей постобработке на CPU (запись в pcap, анализ задержек и пр.). В таком случае в линки вставляется сплиттер (или трафик забирается с миррор порта). Получается неинтрузивное подключение, аналогичное тому, как мы делали в проекте мониторинга RTP-потоков.
Здесь от ПЛИС требуется:
- Фильтрация по полям (типа 5-tuple): для отбора только того трафика, который интересен.
- Синхронизация по PTP, для аппаратного timestamping пакетов: защелкивается время, когда пришел пакет, и эта метка размещается в конец пакета. Затем на CPU можно посчитать, например, время отклика на запрос.
- Слайсинг — отрезание только необходимого куска данных (чаще всего это первые N байт от пакета — для того, чтобы копировать только заголовки, т.к. очень часто данные не очень интересны, ведь если в IPdst стоит 31.192.117.132, то итак понятно, что за данные).
- Буферизация пакетов:
- если CPU не успевает записывать в случае каких-то берстов, то можно это сгладить, если разместить пакеты во внешней памяти на пару гигабайт
- если мы хотим гарантировать запись пакетов в течении небольшого времени (например, после срабатывания триггера) — чаще всего применимо для больших скоростей (40G/100G).
- Раскидывания пакетов по очередям и ядрам CPU.
Имея доступ к самому низкому уровню (ну, почти), можно поддержать любой протокол или туннелирование, а не ждать, пока Intel это сделает в своих карточках.
На приведенной иллюстрации FPGA принимает все пакеты после ответвления трафика, но на CPU копируются только те, которые нас интересуют (розовенькие).
Сетевая карточка
Карточки с ПЛИС можно использовать в качестве обычного NIC, но смысла в этом не много:
- На сегодняшний момент на всех скоростях Ethernet (до 100G включительно) есть сетевые карточки на базе ASIC'ов. По цене они будут дешевле, чем решения на FPGA.
- Если писать карточку самому, то для более менее серьезной производительности необходимо в такой карточке накрутить огромное количество плюшек (RSS, LSO, LRO).
Смысл появляется только тогда, когда необходимо обеспечить уникальную фишку, которой никогда не будет в чипе от Intel'a. Например, аппаратного шифрования по ГОСТу или Кузнечику.
Cетевой ускоритель
Снижение нагрузки с CPU
Когда появляются большие скорости, процессор не успевает всё делать: хочется часть задач с него снять. Например, что происходит когда вы копируете какой-то большой объем данных по сети?
Процессор должен:
- взять какой-то кусок данных
- засунуть в TCP, разбить на несколько пакетов, согласно MTU
- подставить заголовок (MAC/IP-адреса)
- рассчитать чексуммы IP и TCP (хотя большинство NIC это уже берут на себя)
- передать дескриптор в NIC
Так же надо:
- следить за ответами
- перепосылать пакеты, если пакет потерялся
- снижать/повышать tcp-window и так далее
TCP-стек может быть реализован на FPGA: CPU достаточно предоставить указатель на сырые данные и IP+порт получателя, а всей низкоуровневой работой (установкой соединения, перепосылками, и пр.) займется железка.
Есть готовые IP-ядра, которые всё это делают: например, реализации TCP и UDP стеков от компании PLDA.
Они имеют стандартные интерфейсы (Avalon или AXI), что позволяет их легко соединять с другими IP-ядрами.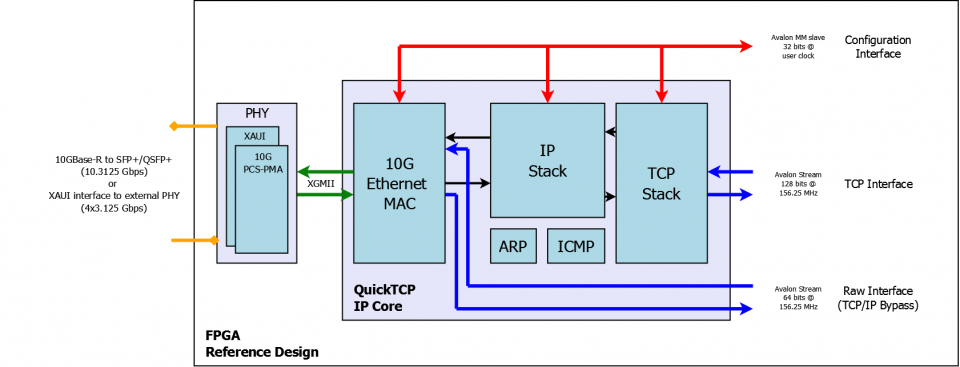
Ускорение ответа
Есть класс задач, где деньги приносят не процессоры, а скорость реакции. Конечно, я о High Frequency Trading. О роли FPGA в HFT можно прочитать в этой статье.
На сайте PLDA приведено видео и пример архитектуры, как это делается. Использование аппаратных TCP и UDP ядер позволяет уменьшать лэтенси на покупки/продажи.
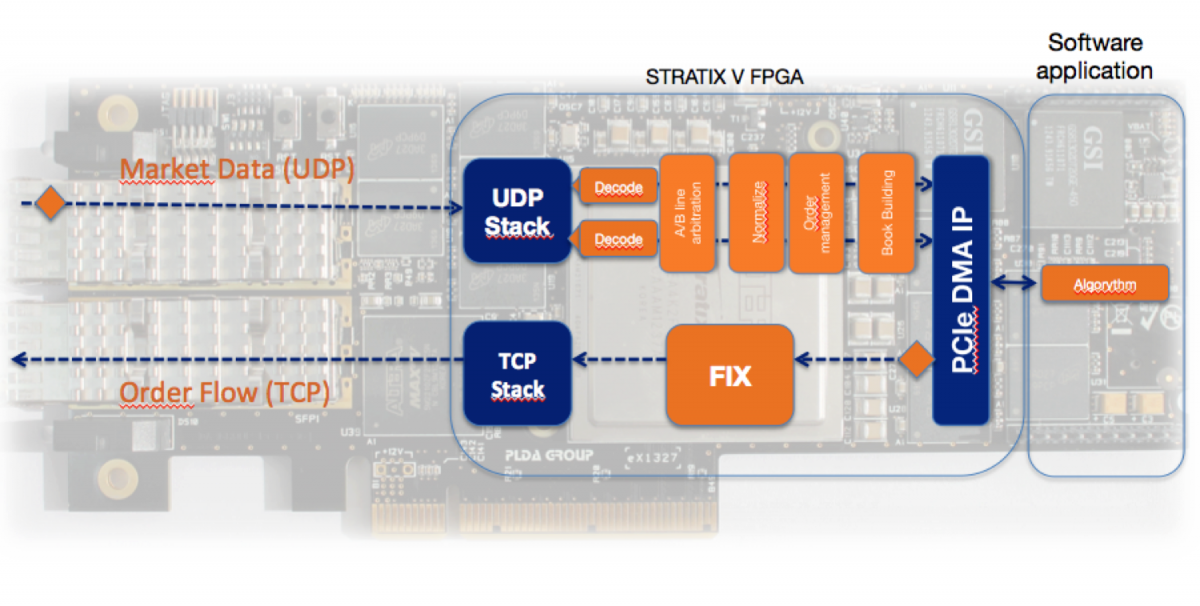
Прошу прощения за красные подчеркивания — картинка взята с сайта PLDA, и у них так в оригинале...
Есть специальные IP-ядра, которые декодируют данные с рынков и готовы к сопряжению с аппаратными TCP и UDP стеками.
Разумеется, использование стандартных ядер или подходов преимущества перед конкурентами не даст: разрабатываются эксклюзивные решения, т.к. «хотят еще меньшую задержку».
Оборудование для измерений
Эмуляторы сетей
Очень часто происходит, что надо проверить инженерное решение в лаборатории, т.к. в боевых условиях это может быть очень дорого.
Недавно была статья от КРОК, про оптимизацию трафика в условиях Севера и большого RTT. Для проверки того, какое будет качество услуг в реальных условиях, сначала надо создать эти условия у себя в лаборатории. Для этого можно применить и обычную линуксовую машину, но есть специальные железки, которые занимаются эмуляцией сети.
Чаще всего необходимо уметь задавать такие параметры как задержка/джиттер, потери (ошибки) пакетов. Без аппаратной поддержки (читай, ПЛИС) здесь не обойтись, но так же нужен и «умный» процессор, для эмуляции различных протоколов (сессий пользователей). Для того, что бы не разрабатывать железо с нуля можно взять сервер и вставить PCIe карточку с FPGA.
Ускорение вычислений
Такие карточки так же можно использовать для ускорения каких-то вычислений или моделирования, например, для биологии или химии. О примере такого моделирования рассказывала Algeronflowers в этой статье. В таком случае порты Ethernet могут и не понадобиться, а с другой стороны могут быть полезны, если захочется сделать ферму из плат: входные или выходные данные для расчета передавать через Ethernet.
OpenCL

Иногда нет необходимости выжимать из железа все соки: очень часто важен time-to-market. Многие разработчики отказываются от использования FPGA, т.к. их пугает низкоуровневая оптимизация до тактов (плюс необходимо знать новый язык(и) и инструмент). Хотелось бы писать код на «выcоком» уровне, а компилятор уже всё разложит по триггерам/блокам памяти. Один из таких вариантов является OpenCL. Altera и Xilinx поддерживают.
OpenCL на FPGA это тема отдельной статьи (и не одной). Рекомендую для ознакомления презентацию от Альтеры про обзор технологии и маршрут разработки под FPGA.
HighLoad
В интернете можно найти много новостей, о том, что гиганты присматриваются к ПЛИС для обработки больших данных в датацентрах.
Так, была заметка о том, что Microsoft для ускорения поисковой системы Bing использует FPGA. Технические подробности можно найти в публикации A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services.
К сожалению, хорошей технической статьи на русском языке об этом нет, хотя тема очень интересная. Может olgakuznet_ms или её коллеги исправят этот недостаток?
Надеюсь, что выпуск чипов CPU + FPGA подстегнет разработчиков высоконагруженных систем переносить часть вычислений на FPGA. Да, разработка под FPGA «сложнее» чем под CPU, но на конкретных задачах может давать замечательный результат.
Разработка/отладка IP-ядер и софта
Такие платы еще могут использовать ASIC/FPGA разработчики для верификации своих IP-ядер, которые потом могут запускаться на совершенно других железках.
Очень часто бывает, что софт пишется одновременно с тем, как разрабатывается/производится железка, и отлаживать софт где-то уже надо. В данном контексте софт это как прошивка FPGA + различные драйвера и юзерспейсные программы. В проекте 100G анализатора и балансировщика возникли задачи, которые мы никогда не решали:
- настройка FPGA (CSR: контрольно-статусные регистры) должна происходить через PCIe
- для linux'a FPGA с кучей интерфейсов должна выглядеть как сетевая карточка: необходимо написать драйвер(ы), и переброску пакетов c/на хост
Конечно, параллельно были и другие задачи (типа генерации/фильтрации 100G трафика), но они спокойно решались в симуляторе, а вот эти две задачи в симуляторе не особо погоняешь. Что мы сделали? Оказалось, что у нас есть девборда от Альтеры. Не смотря на то, что там совершенно другой чип, другой PCIe и пр. мы на ней отладили связку FPGA + драйвера, а когда отдел производства передал нам плату для b100, то после поднятия железа вся эта связка без проблем заработала.
Общая схема
Перед обзором карточек, рассмотрим общую схему таких PCIe карточек.
Ethernet
Платы оснащаются стандартными Ethernet-разъемами:
- SFP — 1G
- SFP+ — 10G
- QSFP — 40G
- CFP/CFP2/CFP4 — 100G
Чаще всего встречаются такие комбинации:
- 4 x SFP/SFP+
- 2 x QSFP
- 1 x CFP
О том, что происходит на низком уровне и как происходит подключение к 10G к интегральным схемам можно прочитать, например, тут.
PCIe
Стандартный разъем, который можно воткнуть в компьютер с обычной материнкой. На текущий момент, топовые FPGA поддерживают аппаратные IP-ядра Gen3 x8, но этой пропускной способности (~63 Gbps) хватает не для всех задач. На некоторых платах стаят PCIe свитч, который 2 канала Gen3 x8 объединяет в один Gen3 x16.
На будущих чипах Altera и Xilinx заявляют о аппаратной поддержке Gen3 x16, и даже о Gen4.
Коннекторы

Иногда размещают разъем(ы) для подключения плат расширения, однако единого стандарта де-факто нет (типа USB). Чаще всего встречаются VITA ( FMC ) и HSMC.
Avago MiniPod

У вышеобозначенных коннекторов есть небольшой недостаток — они металлические и на высоких частотах/длинных расстояниях затухание может быть значительным.
В ответ на эту проблему Avago разработало Avago Minipod: оптические приемо-передатчики. Они готовы передавать 12 лейнов по 10-12.5GBd. По размерам коннектор сравним с монеткой. С помощью такого разъема можно соединять не только рядом стоящие платы, но и делать связь в суперкомпьютерах или в стойках между серверами.
Когда наши коллеги показывали демку MiniPod'a на вот такой борде, то рассказывали, что никаких дополнительных IP-ядер или Verilog-кода не надо вставлять — эти модули просто подключаются в входам/выходам трансиверам FPGA, и всё работает.
Внешняя память
Памяти в ПЛИС не так много — в топовых чипах их 50-100 Mbit. Для обработки больших данных к чипу подключают внешнюю память.
Выделяют два типа памяти:
При выборе учитывают такие параметры как цена, объем, задержки на последовательное/случайное чтение, пропускная способность, энергопотребление, доступность контроллеров памяти, простота разводки/замены и так далее.
У Альтеры есть External Memory Interface Handbook, который как не сложно догадаться, посвящен внешней памяти. Заинтересовавшийся читатель в главе Selecting Your Memory найдет таблицы сравнения различных типов памяти и советы по выбору. Сам гайд доступен тут (осторожно, файл большой).
Если смотреть на применение памяти в сетях связи, то советы примерно такие:
- DRAM используют для создания больших буферов (под пакеты)
- SRAM:
- таблицы/структуры принятий решения куда отправлять пакет
- структуры для управления очередями
- подсчет пакетной статистики (RMON и пр.)
- возможен гибридный подход — DRAM используют для хранения полезной нагрузки пакета, а в SRAM размещают только заголовок
Если открыть презентацию Anatomy of Internet Routers от Cisco, то можно увидеть, что в качестве DRAM они в некоторых роутерах используют именно RLDRAM.
HMC
HMC (Hybrid Memory Cube) — это новый тип ОЗУ памяти, которая может в некоторых приложениях вытеснить DDR/QDR память: обещают значительное ускорение пропускной способности и меньшее энергопотребление. На хабре можно найти новости: раз и два. В комментариях к ним можно найти опасения, что до этого еще далеко и так далее.
Заверяю вас, что всё не так плохо. Так, полгода(!) назад, наши коллеги из EBV показывали работающую демоборду из четырех Stratix V (по бокам) и HMC (в центре).

Ожидается, что коммерческие образцы (для масспродакта) будут доступны в 2015 году.
Обзор PCIe карточек
Обзор, наверно, это слишком громкое слово — я попытаюсь показать самых интересных представителей от разных компаний. Никаких таблиц сравнения или анпакинга не будет. На самом деле большого разнообразия между платами не будет, они все вписываются в «шаблон», который был описан ранее. Уверен, что можно найти еще около пяти-семи фирм, который выпускают такие платы, а самих плат еще с десяток.
NetFPGA 10G
- Xilinx Virtex-5 TX240T
- 240K logic cells
- 11,664 Kbit block RAM
10-Gigabit Ethernet networking ports
- 4 SFP+ connectors
Quad Data Rate Static Random Access Memory (QDRII SRAM)
- 300MHz Quad data rate (1.2 Giga transactions every second), synchronous with the logic
- Three parallel banks of 72 MBit QDRII+ memories
- Total capacity: 27 MBytes
- Cypress: CY7C1515KV18
Reduced Latency Random Access Memory (RLDRAM II)
- Four x36 RLDRAMII on-board device
- 400MHz clock (800MT/s)
- 115.2 Gbps peak memory throughput
- Total Capacity: 288MByte
- Micron: MT49H16M36HT-25
Это не самая топовая карточка, но про неё я не рассказать не мог:
- платы NetFPGA позиционируются как «открытые платформы для исследований»: они используются по всему миру (в более чем 150 заведениях). Студенты/научные сотрудники могут делать на них различные лабораторные работы/проекты.
- проект позиционируется как opensource: на гитхабе есть одноименная организация. На гитхабе в приватном репозитории лежат различные референсные дизайны (сетевая карточка, свитч, роутер и пр.), которые написаны на Verilog'e и распространяется под LGPL. Они станут доступны после простой регистрации.
Advanced IO V5031

- Altera Stratix V
- Quad 10 Gigabit Ethernet SFP+ optical ports
- 2 banks of 1GB to 8GB 72-bit 1066MHz DDR3 SDRAM
- 4 banks of 36Mbit to 144Mbit 18-bit 350MHz QDRII+ SRAM
- x8 PCI Express Gen 3
- PPS Interface for time synchronization with microsecond resolution
У этой платы есть брат-близнец: captureXG 1000, но он уже позиционируется как карточка для записи потоков данных:
- Time Synchronization: IRIG-A, B and G time synchronization via a front panel SMA connector
- Filters: 128 programmable 5-tuple filters ( IPv4, TCP, UDP, ICMP, ARP )
- Packet Capture: PCAP Next Generation format or raw data format
Фактически к карточке, которая была показана выше, написали прошивку для FPGA, а так же драйвера. И это уже фактически получается другой продукт, который готов к работе «из коробки». Интересно какая разница по деньгам между этими двумя продуктами.
Napatech NT40E3-4-PTP

Еще одна карточка для записи и анализа трафика:
- FPGA: Xilinx Virtex-7
- Quad 10 Gigabit Ethernet SFP+ optical ports
- 4 GB DDR3
- PCIe x8 Gen 3
Увы, больше технических подробностей из маркетинговой брошюры выжать не удалось.
В таком корпусе она выглядит очень симпатично. Принципиально по железу эта карточка не особо отличается от других, но Napatech её рассматривает как законченный продукт и навернул туда кучу фич, которые реализуются на FPGA:
- Hardware Time Stamp
- Full line-rate packet capture
- Frame buffering
- Frame and protocol information
- Time Stamp Injection
- Buffer size configuration
- Onboard IEEE 1588-2008 (PTP v2) support
- Inter-Frame Gap Control
- Frame Classification
- HW Time Synchronization
- Extended RMON1 port statistics
- Advanced Statistics
- Synchronized statistics delivery
- Flow identification based on hash keys
- Dynamic hash key selection
- Frame and flow filtering
- Deduplication
- Slicing
- Intelligent multi-CPU distribution
- Cache pre-fetch optimization
- Coloring
- IP fragment handling
- Checksum verification
- Checksum generation
- GTP tunneling support
- IP-in-IP tunneling support
- Filtering inside tunnels
- Slicing inside tunnels
Всё это можно сделать и на других карточках. Просто надо потратить на это время.
COMBO-80G

- Virtex-7 FPGA chip manufactured by Xilinx company
- 2× QSFP+ cage multi/single mode, CWDM or copper
- 4× 10G to 40G fanout modules for 10G Ethernet technology
- PCI Express 3.0 x8, throughput up to 50Gb/s to software
- 2× 72Mbits QDRII+ SRAM memory
- 2× 1152Mbits RLDRAM III memory
- 2× 4GB DDR3 memory
- External PPS (Pulse per second) synchronization
- Unique on-the-fly FPGA boot system (no need for host computer reboot)
Nallatech 385A и Nallatech 385C

- Arria 10 1150 GX FPGA with up to 1.5 TFlops
- Network Enabled with (2) QSFP 10/40 GbE Support
385C:
- Altera Arria 10 GT FPGA with up to 1.5 TFlops
- Network Enabled with (2) QSFP28 100 GbE support
Общее:
- Low Profile PCIe form factor
- 8 GB DDR3 on-card memory
- PCIe Gen3 x8 Host Interface
- OpenCL tool flow
Как видим, это два брата близнеца: в 385A стоит более бюджетная FPGA (GX) с трансиверами на 17.4 Gbps, что достаточно для 10/40G, а в 385С уже используется Arria 10 GT, т.к. нужны 28 Gpbs трансиверы для поддержки 100G, которые идут в исполнении 4x25G.
Отмечу, что Nallatech предоставляет OpenCL BSP для этих карточек.
HiTech Global 100G NIC

- x1 Xilinx Virtex-7 H580T
- x16 PCI Express Gen3 (16x8Gbps)
- x1 CFP2 (4x25Gbps)
- x1 CFP4 (4x25Gbps)
- x1 Cypress QDR IV SRAM
- x2 DDR3 SODIMMs (with support up to 16GB)
- x4 Avago MiniPod (24 Tx and 24 Rx) for board-to-board high-speed communications
- x1 FMC with 8 GTH transceivers and 34 LVDS pairs (LA0-LA33)
Здесь мы наблюдаем и FMC разъем для подключения других плат, и Avago MiniPod, о котором говорили ранее.
Бонус:
Nallatech 510T

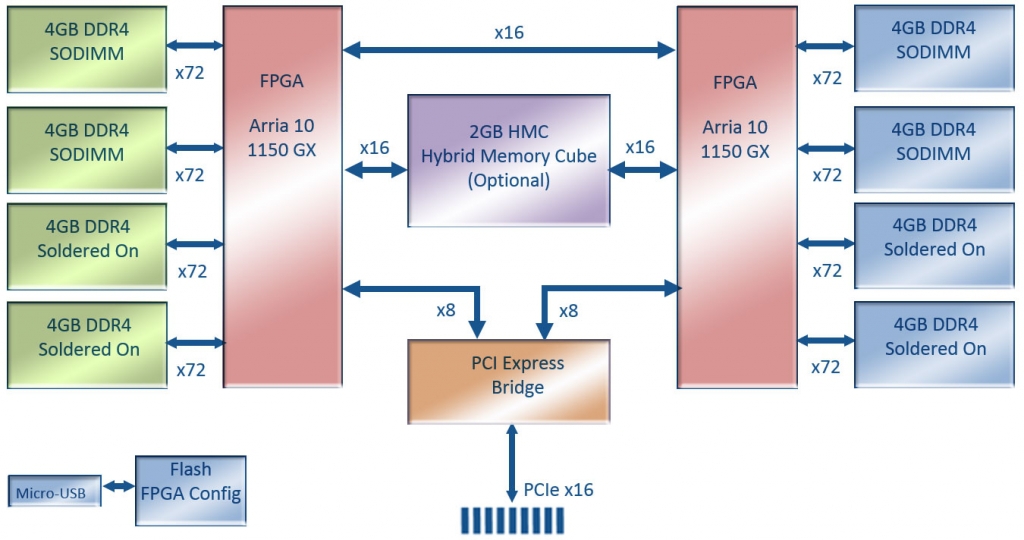
В этой карточке нет Ethernet'a, но это реально бомба.
- GPU Form Factor Card with (2) Arria 10 10A1150GX FPGAs
- Dual Slot Standard Configuration
- Single Slot width possible, if user design fits within ~100W power footprint
- PCIe Gen3 x 16 Host Interface
- 290 GBytes/s Peak Aggregate Memory Bandwidth:
- 85GB/s Peak DDR4 Memory Bandwidth per FPGA (4 Banks per FPGA)
- 30GB/s Write + 30GB/s Read Peak HMC Bandwidth per FPGA
Здесь и два жирных топовых чипа, которые клепаются по 20-нм технологии, и DDR4, и HMC. Производительность обещается до 3 TFlops!
Судя по рендеру, до реальной железки там еще далеко, но чувствуется, что будет она золотой (по цене), но свою нишу займет: её позиционируют как сопроцессор для датацентров. Обещают поддержку OpenCL, а это значит, что никто до такта с этой платой нянчится не будет: загонят готовые алгоритмы и будут прожигать ватты. Кто знает, может на этой плате Youtube, Facebook, ВК будут конвертить видео, заменяя десятки серверов? Или может спецэффекты для нового Аватара будут рендерится на таких фермах?
Заключение
Посмотрев, на всё это разнообразие плат мы с коллегами подумали: почему бы нам тоже не сделать такую карточку?
По сложности печатной платы она не будет сложнее чем B100, софт под FPGA и Linux писать мы вроде бы умеем, да и спрос у определенных компаний и ведомств есть на такие железки.
Мы с коллегами немного спорили какую карточку делать, и нам интересно что вы думаете по этому поводу.
Спасибо за внимание! Готов ответить на вопросы в комментариях, в личке или по почте i.shevchuk@metrotek.spb.ru.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
