[Из песочницы] Опыт разработки программы-тренажера для проведения практических работ студентов
Столкнувшись с необходимостью проверить шесть десятков студенческих работ (6 практических работ * 10 студентов), я поняла, что этот процесс должен быть автоматизирован. Не говоря уже о сложности проверки рукописных решений, надо как-то решать проблему списывания. Еще в мою собственную бытность студенткой мне довелось сдавать практики по одной из дисциплин на компьютере со специально разработанной контрольно-обучающей программой-тренажером (под DOS). Сейчас захотелось повторить этот опыт.
Уточню, что речь идет о тренажере, а не системе тестирования. Различие между ними я бы обозначила так: система тестирования получает на вход набор тестов и набор ответов к ним, а в ходе работы выдает студенту тест и проверяет совпадение с ответом. Напротив, в тренажер заложены алгоритмы решения каждой задачи, поэтому каждый раз генерируется уникальное задание и осуществляется его решение, а затем ответ студента сверяется с ответом системы. Преимущество этого варианта в том, что нельзя обойти систему путем составления базы вопросов-ответов. Каждую вновь сгенерированную задачу приходится решать с нуля.
Вопрос о выборе языка и технологии разработки тренажера не стоял. Надо обеспечить заочникам и отстающим возможность сдавать работы, не выходя из дома. Поэтому только веб-приложение, а следовательно, PHP как самый удобный для меня язык. СУБД — MySQL.
Дисциплина, по которой мне потребовалось проверить практические работы, называется «Информационный поиск». Задачи — из книги Кристофер Д. Маннинг, Прабхакар Рагхаван, Хайнрих Шютце. Введение в информационный поиск. Необходимость обработки естественного языка усложнила дело.
Прежде всего надо было составить коллекцию документов, из которой будут генерироваться задания. Начала со словаря русских пословиц, но пришлось отказаться от этой идеи из-за сложности морфологического анализа русского языка и взять такой же англоязычный словарь, оговорив при этом в задании, что различные морфологические формы слова считаются разными словами, и указав регулярное выражение, в соответствии с которым проверяющий скрипт будет разбивать предложения на слова.
Для многих задач непростым делом оказалась и генерация исходных данных. К примеру, построение инвертированного индекса коллекции документов требует, чтобы пословицы, использующиеся в качестве таких «документов», имели по нескольку общих слов между собой. Иначе задачу будет неинтересно решать. Поэтому пришлось придумать целый алгоритм: выбрать случайное слово, найти все пословицы, в которых оно употребляется, попарно сравнить их, посчитать для каждой пары количество общих слов и записать в результат те пословицы, где это количество превышает заданный порог. Если в получившемся списке элементов меньше, чем другой заданный порог, то начать все сначала. Понятно, что на лету такие вещи генерировать сложно, поэтому пришлось заодно проиндексировать все пословицы, разбив их по словам и записав результат в базу данных. Сложно? И такой алгоритм пришлось придумать едва ли не для каждого задания!
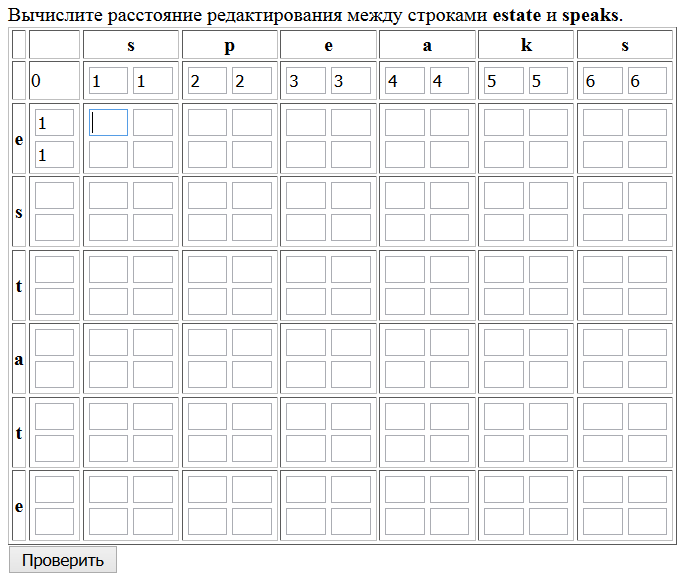
Форма записи ответа — тоже не всегда тривиальный вопрос. Порой для ответа достаточно записать число или строку, но эти число или строка легко просчитываются на глаз и не требуют применения каких-либо формул. А проверить-то нужно именно знание формул! Поэтому форма записи ответа варьировалась. Где-то обычный textbox, где-то textarea. А вот для задачи вычисления расстояния Левенштейна между двумя словами пришлось вывести целую матрицу, поскольку важно проверить, что студент понял алгоритм расчета.
Что касается порядка работы с тренажером, то для получения доступа к заданиям требуется регистрация. Залогинившийся пользователь видит список всех работ и всех задач, причем те задачи, которые он сдал, даже отображаются без гиперссылки — к ним доступ запрещен.

Исправления ошибок не предусматривается — при каждом обращении к заданию скрипт генерирует его заново.
Расскажу теперь о том, как студенты восприняли такую систему контроля их знаний. На первых порах много нервов вызвала необходимость перерешивать задачу заново при малейшей ошибке. Вскоре были найдены два способа обойти это обстоятельство. Первый — использовать браузер Opera, в котором при нажатии кнопки «Назад» восстанавливалась вся страница целиком вместе со старым заданием. Второй — подменять post-запрос, в котором отправлялся на проверку не только ответ студента, но и задание, в скрытых элементах html-формы. Через пару занятий студентов озарило, что можно использовать подмену post-запроса для отправки не своего старого задания, а чужого. Таким образом научились списывать даже тут.
Впрочем, списывали не все, да и в любом случае одно-то решение точно надо сделать, хоть и на несколько человек. Поэтому вид компьютерного класса на наших практиках представлял собой замечательную картину напряженного умственного труда всех учащихся.
Для просмотра успеваемости я сделала скрипт, который выводил список сданных задач, отсортированный либо по убыванию даты-времени, либо по студентам.

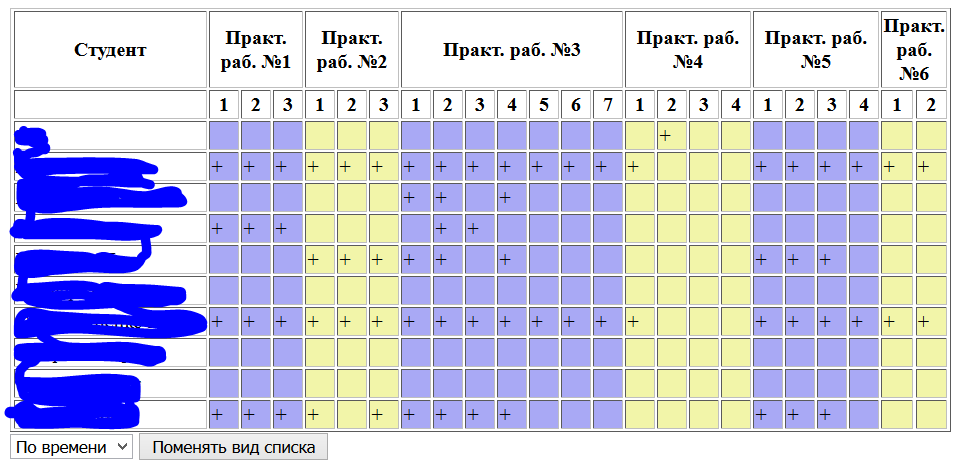
Теперь можно было открыть этот список в воскресный день и увидеть, что пока ты отдыхаешь, твои студенты продолжают сдавать задачи.
Какие выводы можно сделать из этого опыта? Конечно, тренажер нуждается в совершенствовании. Нужно ограничить число попыток сдачи задания и предотвратить возможность подмены исходных данных. Я решила, что в этом семестре буду только наблюдать за процессом сдачи/обхода/взлома (мало ли) системы и ничего не буду исправлять. В дальнейшем думаю приспособить этот тренажер и для других дисциплин — везде, где есть задачи.
К сожалению, проверять таким же способом программный код, написанный студентами на лабораторных работах, едва ли получится. Тут мог бы использоваться разве что метод черного ящика, как на олимпиадах по программированию ACM/ICPC. Но тогда надо искать способы проверки работ на плагиат. Кроме того, никакая программа не заменит преподавателя-человека.
Вот, собственно, и все. Спасибо тем, кто прочел статью до конца. Жду комментариев, замечаний и советов.
Потестировать тренажер можно здесь: science-search.ru/ir_students Логин: test, пароль: test.
