Еще раз о Hyper-Threading
Было время, когда понадобилось оценить производительность памяти в контексте технологии Hyper-threading. Мы пришли к выводу, что ее влияние не всегда позитивно. Когда появился квант свободного времени, возникло желание продолжить исследования и рассмотреть происходящие процессы с точностью до машинных тактов и битов, используя программное обеспечение собственной разработки.Исследуемая платформаОбъект экспериментов — ноутбук ASUS N750JK c процессором Intel Core i7–4700HQ. Тактовая частота 2.4GHz, повышаемая в режиме Intel Turbo Boost до 3.4GHz. Установлено 16 гигабайт оперативной памяти DDR3–1600 (PC3–12800), работающей в двухканальном режиме. Операционная система — Microsoft Windows 8.1 64 бита. Рис. 1 Конфигурация исследуемой платформы.
Рис. 1 Конфигурация исследуемой платформы.
Процессор исследуемой платформы содержит 4 ядра, что при включении технологии Hyper-Threading обеспечивает аппаратную поддержку 8 потоков или логических процессоров. Эту информацию Firmware платформы передает операционной системе посредством ACPI-таблицы MADT (Multiple APIC Description Table). Поскольку платформа содержит только один контроллер оперативной памяти, таблица SRAT (System Resource Affinity Table), декларирующая приближенность процессорных ядер к контроллерам памяти, отсутствует. Очевидно, исследуемый ноутбук не является NUMA-платформой, но операционная система, в целях унификации, рассматривает его как NUMA-систему с одним доменом, о чем говорит строка NUMA Nodes = 1. Факт, принципиальный для наших экспериментов — кэш память данных первого уровня имеет размер 32 килобайта на каждое из четырех ядер. Два логических процессора, разделяющие одно ядро, используют кэш-память первого и второго уровней совместно.
Исследуемая операция Исследовать будем зависимость скорости чтения блока данных от его размера. Для этого выберем наиболее производительный метод, а именно чтение 256-битных операндов посредством AVX-инструкции VMOVAPD. На графиках по оси X отложен размер блока, по оси Y — скорость чтения. В окрестности точки X, соответствующей размеру кэш-памяти первого уровня, ожидаем увидеть точку перегиба, поскольку производительность должна упасть после того, как обрабатываемый блок выйдет за пределы кэш-памяти. В нашем тесте, в случае многопоточной обработки, каждый из 16 инициируемых потоков, работает с отдельным диапазоном адресов. Для управления технологией Hyper-Threading в рамках приложения, в каждом из потоков используется API-функция SetThreadAffinityMask, задающая маску, в которой каждому логическому процессору соответствует один бит. Единичное значение бита разрешает использовать заданный процессор заданным потоком, нулевое значение — запрещает. Для 8 логических процессоров исследуемой платформы, маска 11111111b разрешает использовать все процессоры (Hyper-Threading включен), маска 01010101b разрешает использовать по одному логическому процессору в каждом ядре (Hyper-Threading выключен).На графиках используются следующие сокращения:
MBPS (Megabytes per Second) — скорость чтения блока в мегабайтах в секунду;
CPI (Clocks per Instruction) — количество тактов на инструкцию;
TSC (Time Stamp Counter) — счетчик процессорных тактов.
Примечание.Тактовая частота регистра TSC может не соответствовать тактовой частоте процессора при работе в режиме Turbo Boost. Это необходимо учитывать при интерпретации результатов.
В правой части графиков визуализируется шестнадцатеричный дамп инструкций, составляющих тело цикла целевой операции, выполняемой в каждом из программных потоков, или первые 128 байт этого кода.
Опыт №1. Один поток
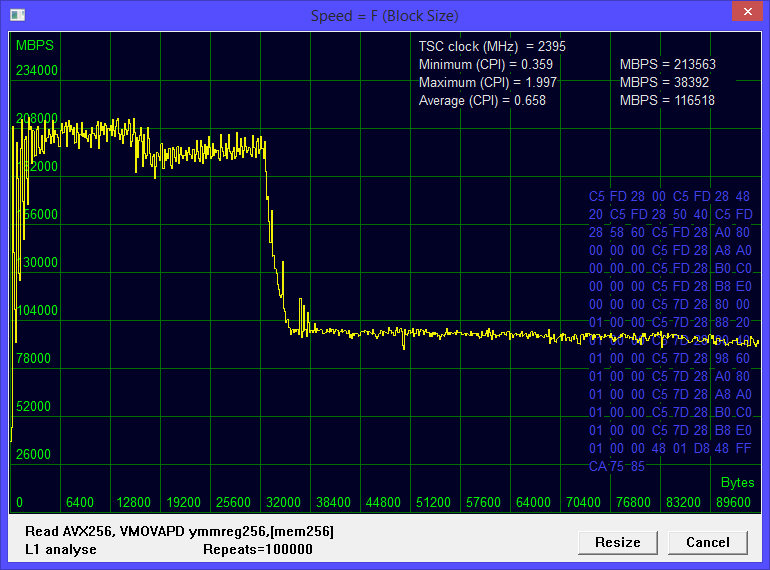 Рис. 2 Чтение одним потокомМаксимальная скорость 213563 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт.
Рис. 2 Чтение одним потокомМаксимальная скорость 213563 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт.
Опыт №2. 16 потоков на 4 процессора, Hyper-Threading выключен
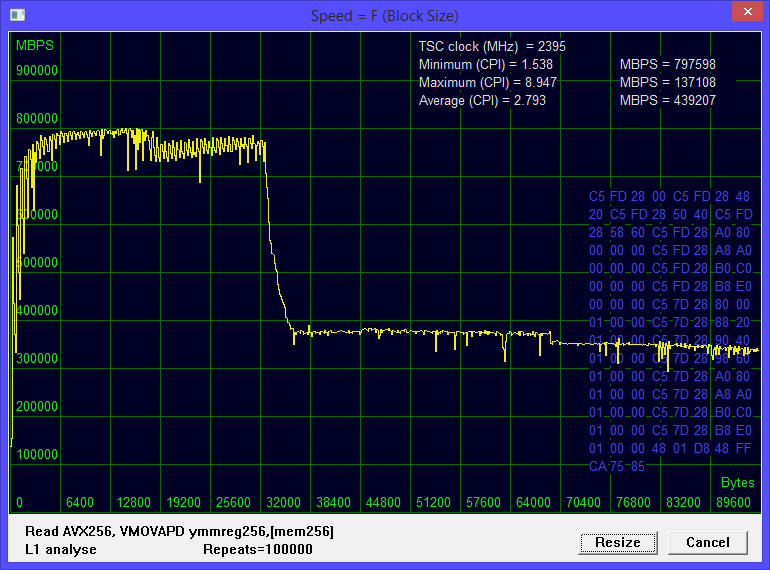 Рис. 3 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно четыремHyper-Threading выключен. Максимальная скорость 797598 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт. Как и ожидалось, по сравнению с чтением одним потоком, скорость выросла приблизительно в 4 раза, по количеству работающих ядер.
Рис. 3 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно четыремHyper-Threading выключен. Максимальная скорость 797598 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт. Как и ожидалось, по сравнению с чтением одним потоком, скорость выросла приблизительно в 4 раза, по количеству работающих ядер.
Опыт №3. 16 потоков на 8 процессоров, Hyper-Threading включен
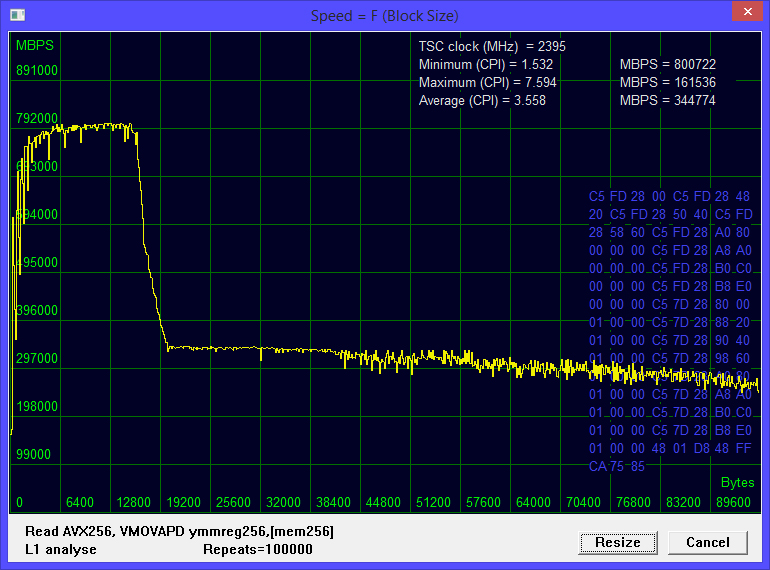 Рис. 4 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно восьмиHyper-Threading включен. Максимальная скорость 800722 мегабайт в секунду, в результате включения Hyper-Threading почти не выросла. Большой минус — точка перегиба имеет место при размере блока около 16 килобайт. Включение Hyper-Threading немного увеличило максимальную скорость, но падение скорости теперь наступает при вдвое меньшем размере блока — около 16 килобайт, поэтому существенно упала средняя скорость. Это не удивительно, каждое ядро имеет собственную кэш-память первого уровня, в то время, как логические процессоры одного ядра, используют ее совместно.
Рис. 4 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно восьмиHyper-Threading включен. Максимальная скорость 800722 мегабайт в секунду, в результате включения Hyper-Threading почти не выросла. Большой минус — точка перегиба имеет место при размере блока около 16 килобайт. Включение Hyper-Threading немного увеличило максимальную скорость, но падение скорости теперь наступает при вдвое меньшем размере блока — около 16 килобайт, поэтому существенно упала средняя скорость. Это не удивительно, каждое ядро имеет собственную кэш-память первого уровня, в то время, как логические процессоры одного ядра, используют ее совместно.
Выводы Исследованная операция достаточно хорошо масштабируется на многоядерном процессоре. Причины — каждое из ядер содержит собственную кэш-память первого и второго уровней, размер целевого блока сопоставим с размером кэш-памяти, и каждый из потоков работает со своим диапазоном адресов. В академических целях мы создали такие условия в синтетическом тесте, понимая, что реальные приложения обычно далеки от идеальной оптимизации. А вот включение Hyper-Threading, даже в этих условиях дало негативный эффект, при небольшой прибавке пиковой скорости, имеет место существенный проигрыш в скорости обработки блоков, размер которых находится в диапазоне от 16 до 32 килобайт.
