Еще один способ оптимизации docker-образов для Java приложений
История по оптимизации образов для java приложений началась с выхода статьи в блоге спринга — Spring Boot in a Container. В ней обсуждались различные аспекты по созданию docker образов для spring boot приложений, в том числе и такой интересный вопрос, как уменьшение размеров образов. Для наших команд это было актуально в силу ряда причин, поэтому мы решили применить это решение к нашим приложениям.
Как это часто бывает, не все взлетело с первого раза, возникли нюансы с многомодульными проектами и попыткой гонять все это на CI системе, так что в данной статье вы найдете решение этих проблем.
Целью оптимизации является сокращение разницы между получаемыми образами от сборки к сборке, что дает хороший результат в процессе непрерывной поставки, так что если вас интересует минимизация размера образа как такового, можете обратиться к другим статьям на хабре.
Если причины, зачем вообще что-то делать с многометровым бутовым приложением перед помещением его в образ, вам объяснять не надо, можете сразу перейти к описанию подхода по оптимизации. Если вы успели ознакомиться со статьей из спрингового блога, можете перейти к решению найденных проблем.
По умолчанию jar, который производит Spring Boot, представляет собой исполняемый jar-файл, содержащий код приложения и всех его зависимостей.
Плюс такого подхода очевиден: с одним файлом удобно работать, в нем есть все необходимое для запуска через java -jar . Dockerfile тривиален и не представляет интереса.
Минус — неэффективное хранение. В классическом бутовом приложении соотношение кода и библиотек явно не в пользу нашего кода. Например, пустое приложение с web-частью и библиотеками для работы с базой, которое можно сгенерировать через start.spring.io, займет 20mb, из которых 98% будут библиотеками. И это соотношение в процессе разработки меняется не сильно.
А ведь приложение мы собираем не один раз, а регулярно на CI-сервере, и потом деплоим по цепочке сред. Таким образом 10 сборок вырастают в 200mb, а 100 — уже в 2gb, из которых модификации займут очень мало.
Можно возразить, что для текущей стоимости хранения это смешные цифры и можно не тратить время на такие оптимизации, но все зависит от масштаба организации и числа приложений, образы которых нужно хранить. Условия деплоймента тоже могут сильно мотивировать: когда реестр и сервер находятся рядом, разница даже в 100 мб не сильно заметна, но в распределенных системах это может иметь гораздо большее значение, особенно когда вам нужно деплоиться в такие специфичные страны как Китай с его файерволом и нестабильными каналами во внешний мир.
Итак, с причинами разобрались, пора оптимизировать.
Статья предлагает разумное решение: вместо одного слоя, порождаемого командой COPY my-jar.jar app.jar, нам нужно сделать несколько слоев.
Один слой будет содержать библиотеки, второй — наш собственный код. Для этого jar-файл нужно распаковать и скопировать содержимое в разные слои образа.
Скрипт для подготовки jar-файла выглядит так:
#!/bin/sh
set -e
path_to_jar=$1
dir=$(dirname "${path_to_jar}")
jar_name=$(basename "${path_to_jar}")
mkdir -p "${dir}/docker-dist" && cd "${dir}/docker-dist"
jar -xf ../"${jar_name}"Dockerfile с использованием multi-stage сборки может выглядеть так
FROM openjdk:8-jdk-alpine as build
WORKDIR /wd
COPY prepare_for_docker.sh /usr/local/bin/prepare_for_docker
COPY target/demo.jar /wd/app.jar
RUN prepare_for_docker /wd/app.jar
FROM openjdk:8-jdk-alpine
COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib
COPY --from=build /wd/docker-dist/META-INF /app/META-INF
COPY --from=build /wd/docker-dist/BOOT-INF/classes /app
ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]На первой стадии мы копируем все необходимое, запускаем наш скрипт для распаковки jar-файла, а на второй уже по слоям раскладываем отдельно библиотеки и отдельно наш код.
Убедиться в работоспособности легко:
- Собираем в первый раз
- Вносим любое изменение в наш код
- Запускаем
docker buildеще раз и видим заветные строчкиUsing cacheпри копировании всей директории lib... Step 5/10 : RUN prepare_for_docker app.jar ---> Running in c8e422491eb2 Removing intermediate container c8e422491eb2 ---> c7dcec4ae18a Step 6/10 : FROM openjdk:8-jdk-alpine ---> a3562aa0b991 Step 7/10 : COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib ---> Using cache ---> 01b600d7e350 Step 8/10 : COPY --from=build /wd/docker-dist/META-INF /app/META-INF ---> Using cache ---> 5c0c03a3c8f1 Step 9/10 : COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ---> 5ffed6ee5696 Step 10/10 : ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"] ---> Running in 99957250fe5d Removing intermediate container 99957250fe5d ---> 6735799d9f32 Successfully built 6735799d9f32 Successfully tagged boot2-sample:latest
Очевидный способ улучшения данного подхода — сборка маленького базового образа со скриптом, чтобы не таскать его из проекта в проект. Таким образом первый слой становится более лаконичным.
FROM zeldigas/java-layered-builder as build
COPY target/demo.jar app.jar
RUN prepare_for_docker app.jarКак уже говорилось в начале статьи, решение рабочее, но в процессе эксплуатации были обнаружены пару проблем о решении которых и пойдет речь далее.
Не все файлы в lib одинаково библиотечны
Если ваш проект многомодульный (как минимум есть модуль А, от которого зависит модуль B, собираемый как spring fat jar), применив к нему оригинальное решение, вы обнаружите, что никакого кэширования слоя не происходит. Что же пошло не так?
Дело как раз в дополнительных модулях: они являются источниками постоянных изменений для слоя, даже если вы не вносите в код модуля никаких правок. Это связано с особенностью создания jar-файлов maven’ом (с gradle’ом ситуация чуть лучше, но не уверен). Задача получения воспроизводимых артефактов не является темой этой статьи (хотя, безусловно, интересна и достижима), поэтому перейдем к достаточно простому решению.
Разнесем содержимое lib на 2 директории, после распаковки отделив модули проекты от других библиотек. Доработаем скрипт распаковки fat jar’а:
#!/bin/sh
set -e
path_to_jar=$1
shift #(1)
app_modules=$* #(2)
dir=$(dirname "${path_to_jar}")
jar_name=$(basename "${path_to_jar}")
mkdir -p "${dir}/docker-dist" && cd "${dir}/docker-dist"
jar -xf ../"${jar_name}"
if [ -n "${app_modules}" ]; then #(3)
mkdir app-lib
for i in $app_modules; do
mv "BOOT-INF/lib/$i"* app-lib #(4)
done
fiВ результате скрипт начал поддерживать передачу дополнительных параметров (см. 1 и 2). Если переданы дополнительные аргументы (3), каждый из них рассматривается как префикс названия файла, который мы перемещаем (4) в отдельную директорию.
Пример Dockerfile’а для сценария с одним доп. модулем shared-module и версией 1.0-SNAPSHOT
FROM openjdk:8-jdk-alpine as build
COPY target/demo.jar /wd/app.jar
RUN prepare_for_docker /wd/app.jar shared-module-1.0
FROM openjdk:8-jdk-alpine
COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib
COPY --from=build /wd/docker-dist/app-lib /app/lib
COPY --from=build /wd/docker-dist/META-INF /app/META-INF
COPY --from=build /wd/docker-dist/BOOT-INF/classes /app
ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]Запускаем на CI-сервере
Отладив все локально, довольные результатом мы перешли к запуску на CI-сервере и из логов сборки обнаружили, что чуда не происходит, точнее результаты были не постоянными: в одних случаях кэширование выполнялось, а при следующем запуске все слои получались новые.
В итоге виновник был обнаружен — docker cache, вернее его отсутствие в случае с разными агентами (у нас сборка не прибита к конкретному агенту CI-системы). Как оказалось, если в кэше докера нет подходящих слоев, то из того же самого набора файлов получаются слои с другой контрольной суммой. Проверить это можно и локально, запустив сборку с опцией --no-cache, или собрать второй раз, предварительно удалив образ и все промежуточные слои. В результате вы получите абсолютно другую контрольную сумму слоя, что сводит на нет все предыдущие усилия.

Решить проблему можно разными способами:
- Если ваша CI-система поддерживает это из коробки (например у Circle CI в части планов есть встроенная поддержка шареного кэша при сборках)
- Шарить раздел с кэшом докера между агентами
- Воспользоваться встроенными средствами докера по управлению кэшем (
--cache-from)
Мы пошли третьим путем, так как в нашем случае он был самым простым. Опция позволяет указать докер-демону, какие образы он должен учитывать и пытаться использовать для кэширования при сборке. Указать можно столько образов, сколько вы считаете нужным, главное, чтобы они были на файловой системе. Если указанного образа нет, он будет просто проигнорирован, поэтому нужно сделать pull перед сборкой.
Вот как выглядит сборка контейнера при таком подходе:
set -e
version=...
# забираем последнюю версию нашего образа
docker pull registy.example.com/my-image:latest || true
#собираем новый используя только слои из последнего для кэша
docker build -t registry.example.com/my-image:$version --cache-from registry.example.com/my-image:latest .
# пушим в registry конкретную версию и latest
docker tag registry.example.com/my-image:$version registry.example.com/my-image:latest
docker push registry.example.com/my-image:$version
docker push registry.example.com/my-image:latestМы пытаемся переиспользовать слои только с самого последнего образа, чего зачастую достаточно, но никто не мешает накрутить более сложной логики и отступать на несколько версий назад или опираться на id коммитов vcs.
Адаптируем этот подход под возможности вашего CI и получаем надежное переиспользование слоев с библиотеками.
Решение показывает хорошие результаты, особенно когда применяется в проектах с активной стадией разработки и настроенным CD пайплайном. На графике ниже показан результат применения оптимизации к одному из приложений. Хорошо видно, что линейный рост сменился на скачкообразный начиная с 70-й сборки (провалы в 60-х связаны как раз с отладкой работы на билд агентах). Выбросы после связаны с обновлением базового образа (высокие) и библиотек (пониже)
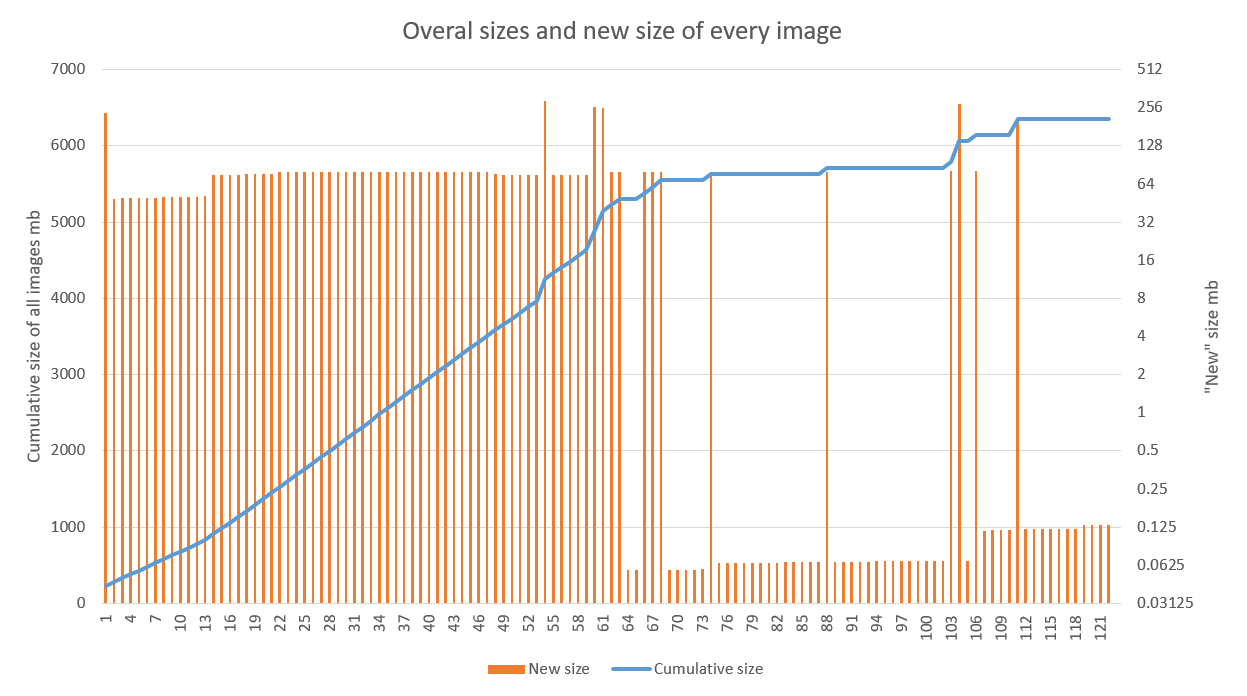
Оптимизация хранения в нашем случае является приятным, но скорее вторичным бонусом. Ускорение деплоя новой версии поверх старой в несколько регионов радует куда сильнее.
Хочется отметить, что данная техника вполне совместима с другими подходами, ориентированными на уменьшение размера отдельного образа (alpine и прочие легковесные базовые образы, custom runtime для приложения). Главное следовать общим правилам сборки образа в плане кэширования и убедиться, что получаемый результат является воспроизводимым.
