Электронные таблицы, как средство разработки бизнес-приложений
Excel часто используется как универсальное средство для разработки бизнес-приложений. В этой статье я хочу сравнить, существующие без особых изменений уже более 30 лет, электронные таблицы с современной классической императивной парадигмой программирования глазами архитектора ПО. Затем я хочу рассказать о своей работе над новым табличным процессором, который исправляет многие недостатки, выявленные при сравнении, тем самым позволяя создавать более надежные, масштабируемые и легкие для поддержки и дальнейшего развития, бизнес-приложения.
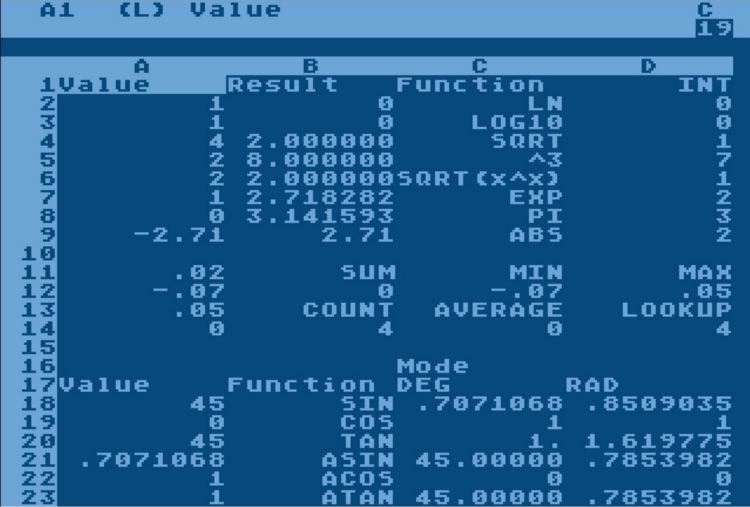
Электронные таблицы и их возможности
Принцип, по которому работают современные электронные таблицы (Microsoft Excel, LibreOffice Calc или Google Sheets) появился в конце 70-х — середине 80-х годов. Двухмерный массив ячеек, как модель данных, и возможность автоматических вычислений с помощью формул появились в VisiCalc в 1979 году. Трехмерный массив ячеек (возможность пользоваться несколькими листами) впервые появился в 1985 в Boeing Calc.
В теории, электронные таблицы ничем не уступают любому языку программирования. Существует машина Тьюринга на формулах Excel (линк), а это значит, что любой алгоритм, который можно реализовать с помощью компьютера, можно реализовать в Excel. Вопрос только в удобстве и эффективности такой реализации.
На практике я встречал очень сложные системы, реализованные в Excel. Например, финансовая модель развития международного аэропорта с возможностью вносить множество разных типов объектов (парковки, склады, полосы, …) и пересчетом квадратных метров и парковочных мест в cash flow (расходы за годы строительства vs прибыль за годы эксплуатации) с учетом разных моделей инфляции. На то чтобы «переписать» такой «эксельчик» на Java с использованием реляционной базы данных может уйти от нескольких человеко-месяцев до нескольких человеко-лет. В этом конкретном случае реляционная модель в базе данных насчитывала более 50 таблиц. Самое интересное, что такого «переписывания» можно было бы избежать, если бы электронные таблицы позволяли не только создавать программное обеспечение, но и делали бы возможным его сопровождение и масштабирование. Для конечного пользователя (экономиста) система на Java это шаг назад, потому что он больше не видит промежуточные результаты и не может сам изменить или дополнить модель.
Выходит, что одну и ту же задачу можно решить, как электронной таблицей, так и универсальным языком программирования. Значит, мы можем сравнить сильные и слабые стороны этих двух инструментов, как средств создания бизнес-приложений. Здесь мы попробуем взглянуть на Excel глазами программиста-архитектора и применим правила архитектуры ПО, которые уже устоялись в классической разработке софта.
Достоинства электронных таблиц
- Интуитивно понятный концепт: каждый из нас в школе видел и заполнял таблички на листочках в клеточку и играл в морской бой. Большинство людей, которые работают с Экселем, никогда не проходили никакого специального обучения (в лучшем случае коллега за полчаса показал на какие кнопки нажимать). Это большое преимущество перед языками программирования, где «C++ за 21 день» звучит даже слишком оптимистично.
- Открытое и статичное состояние облегчает отладку: сложность поиска ошибки в программе чаще всего заключается в том, чтобы поймать тот момент времени, когда что-то пошло не так. Приходиться использовать breakpoints и прокручивать программу по шагам. В электронной таблице состояние статично. Поиск ошибки сводится к тому, чтобы найти первую ячейку с неправильным результатом.
- Реактивность: мы просто задаем формулу, а система сама знает в каком порядке и когда пересчитывать ячейки. Этот концепт, который относительно недавно стал популярным в разработке UI, был основой электронных таблиц с самого начала.
Недостатки электронных таблиц
- Слабо структурированная модель данных: электронные таблицы используют трехмерный массив ячеек как модель данных. Это лучше чем неструктурированный текст в Notepad, но значительно хуже строгой типизации Java или нормализованной реляционной структуры базы данных. В любую ячейку можно записать любой тип данных. Заголовки или значения не различаются. Сказать заранее, что будет в момент исполнения по ссылке E5 невозможно. Зависимости между таблицами неявно хранятся в параметрах функции VLOOKUP и ломаются при неосторожном добавлении колонки. По-моему, это и является одной из основных причин ошибок.
- Высокая избыточность: у программистов хорошо себя зарекомендовал так называемый принцип DRY (Don«t repeat yourself — не повторяйся). Чаще всего мы стараемся писать логику один раз, давать ей название (например, в виде имени функции/метода) и потом ссылаться на нее когда это необходимо. В табличных процессорах мы копируем формулы. Сначала это конечно удобно, но в итоге, понять, где применяется та или другая формула очень сложно. Любое изменение объема данных ведет к необходимости копировать формулы. Это очень сильно затрудняет поддержку и дальнейшее развитие моделей в табличных процессорах.
- Отсутствие интерактивности интерфейса: электронные таблицы не позволяют динамически изменять способ отображения данных. Также отсутствует возможность создавать запрограммированные операции выполняемые, например, по нажатию кнопки.
Как сделать электронные таблицы лучше?
Меня зовут Вадим. Я CTO в CubeWeaver и уже довольно давно занимаюсь разработкой нового табличного процессора. Несколько лет назад я уже писал (линк) про раннюю версию системы, но с тех пор многое изменилось и в этом году проект дошел до коммерческой стадии.
Вот список новшеств моего проекта, которые позволяют устранить перечисленные выше недостатки, стараясь при этом сохранить преимущества электронных таблиц:
Многомерная модель данных
Многомерная модель данных широко используется в Business Intelligence и OLAP системах, предназначенных для анализа данных. Суть модели заключается в том, чтобы хранить данные в ячейках многомерного куба, грани которого подписаны заголовками бизнес-объектов:
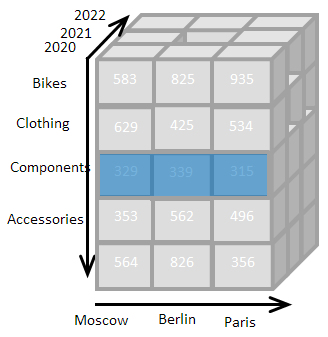
В интерфейсе программы отображается не весь многомерный куб, а его двумерный срез, соответствующий выбранной нами комбинации фильтров:

При реализации такой модели в реляционной BI системе, часто используют схему снежинки (snowflake schema). Кубы реализуются таблицами фактов (fact table), а заголовки на гранях хранятся в таблицах измерений (dimension table).
В моей системе кубы называются рабочими листами (worksheets), а заголовки на гранях куба называются элементами списков (list items).
Каждая ячейка такого многомерного рабочего листа имеет уникальный адрес, состоящий из надписей на гранях. Например, значение 935 на изображении имеет адрес: Bikes, 2020, Paris.
Каждый элемент списка имеет название и идентификатор. В ссылках на ячейки используются идентификаторы, и вышеуказанный адрес в формуле мог бы выглядеть так (ссылки заключаются в квадратные скобки):
[PROD:23, YEAR:2020, CITY:24], где PROD это идентификатор списка «продукт», а 23 идентификатор элемента «Bikes».
Применение многомерной модели позволяет значительно улучшить ситуацию с недостатком номер 1. Во-первых, заголовки теперь хранятся отдельно от численных данных. Во-вторых, введение дополнительного измерения «метрика» (или «позиция отчета») позволяет адресовать ячейки не по порядковому номеру, а по семантическому смыслу, исключая ошибки из-за добавления или удаления столбцов или строк.
Конечно, нужно сказать, что такой подход слегка портит ситуацию с преимуществом номер 1. В морской бой играли все, а в четырехмерные шахматы только некоторые студенты-математики. Но опыт показывает, что благодаря двумерному представлению куба, большинство пользователей довольно быстро привыкают к новой модели данных.
Функция JOIN и метаданные
Многомерная модель позволяет использовать метаданные для описания ячеек. Метод адресации описанный выше означает, что каждая ячейка рабочего листа соответствует определенному набору элементов списка (например, году, продукту и точке продажи). Списки в свою очередь могут иметь атрибуты (колонки), что делает их похожими на обычные реляционные таблицы. Например, можно добавить колонку «валюта» к списку «точка продажи», связывая таким образом списки «точка продажи» и «валюта» в реляцию с кардинальностью many-to-one. Функция JOIN дает возможность динамически ссылаться на ячейки, используя такую связь. Эта функция заменяет VLOOKUP, устраняя при этом необходимость работать с индексами.
Пример: для того чтобы посчитать сумму продаж по миру, нужно сначала сконвертировать сумму продаж по каждой стране в единую валюту (умножить позицию «продажи» на курс обмена). В Excel мы бы хранили 2 таблицы: список стран с валютой для каждой страны и список валют с курсом обмена. Для того чтобы найти правильный курс мы бы использовали функцию VLOOKUP два раза: найти код валюты по названию страны и найти курс обмена по коду валюты.
Ссылка на ячейку с курсом обмена, могла бы выглядеть так: EX_RATES.[COUNTRY.join(CURRENCY)], гдеEX_RATES — название рабочего листа с курсами обмена валютCOUNTRY — измерение со странамиCURRENCY — измерение с валютами
Цепочки связей могут быть любой длины, например: STORE.join(COUNTRY).join(CURRENCY)
Фактически, строя модель, мы создаем схему снежинки. Функция JOIN позволяет формулам динамически ссылаться на ячейки рабочих листов, используя связи между таблицами (списками) этой схемы. При этом зависимости между ячейками явно указаны в аргументах функции JOIN.
Зона действия формул
Возможность указать зону действия формулы (area of effect) позволяет избавиться от необходимости копировать формулы.
По каждому измерению куба мы задаем набор элементов, на которые действует формула, как например: все года, продукты типа «велосипед», позиция отчета «выручка». На практике это выглядит вот так (Синим цветом отмечена цель формулы, красным и оранжевым её аргументы. Список выбранных элементов по каждому измерению находиться внизу экрана):
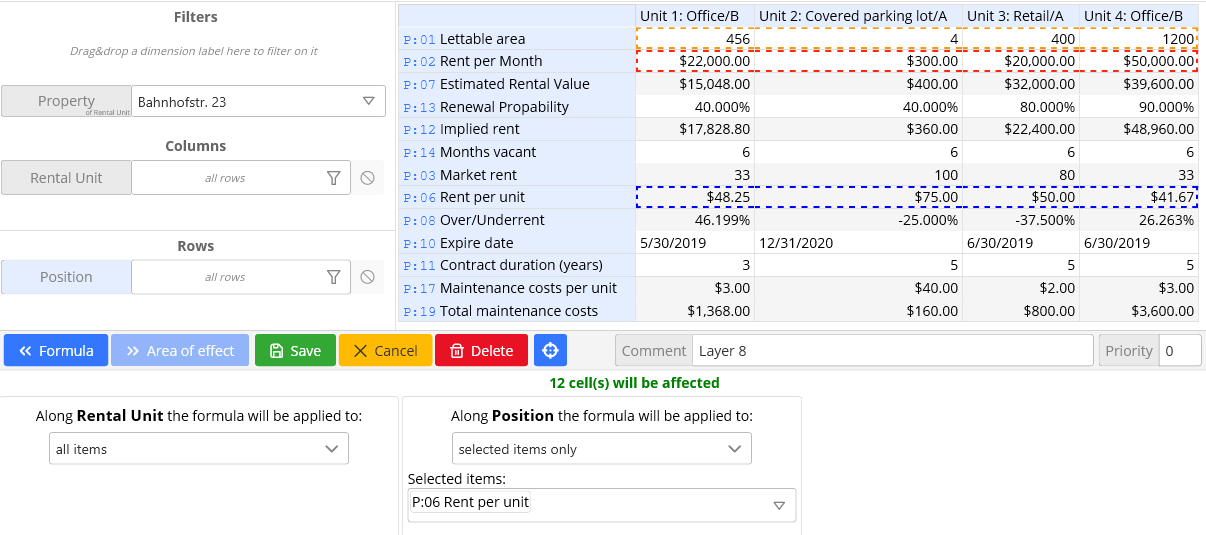
Этот подход устраняет недостаток номер 2 и позволяет добавлять и удалять элементы или даже измерения, не изменяя формулу. Также отпадает необходимость искать все ячейки, в которые формула была скопирована, каждый раз, когда мы хотим ее изменить.
Интерактивность ячеек
Это нововведение позволяет создавать интерактивные интерфейсы, используя формулы. Формулы можно использовать не только для того чтобы вычислить значение ячейки, но и для форматирования ячеек (cell formatting), изменения цвета ячеек (cell color) и для того чтобы спрятать или показать группу ячеек или целые колонки или строки (cell visibility). Ячейки можно форматировать не только как числа, даты и текст, но и как кнопки, флажки (checkbox) и списки выбора (dropdown).
Таким образом, например, цвет ячеек может меняться в зависимости от значения ячейки. Флажок или список выбора в одном листе может отображать, прятать или блокировать на запись ячейки в другом листе.
Кнопки в ячейках позволяют создавать довольно сложные операции со значениями ячеек. Создавая кнопку, мы задаем цель операции (cell range) и формулу, которая выполняется один раз для каждой из целевых ячеек. На одной кнопке может быть несколько операций. Так, нажатие на кнопку может, например, скопировать данные из предыдущего года в следующий или распределить содержимое ячейки по нескольким другим ячейкам, пропорционально какой-то величине (splashing).
Кнопки в сочетании с ограничениями доступа пользователя позволяют создавать необратимую функциональность. Так, например пользователь получивший доступ к кнопке, но не получивший доступ к целевой ячейке, сможет записать в ячейку только то, что позволит ему формула в кнопке.
Заключение
Новый табличный процессор позволяет создавать значительно более сложные модели, чем это возможно в других системах. При этом модели остаются понятными и простыми в сопровождении. Также значительно уменьшается вероятность ошибок в формулах.
Платой за эти преимущества является повышенная сложность системы. Прежде чем начать работать, пользователь должен создать модель данных в виде списков и кубов.
В целом система рассчитана на технически более грамотного пользователя, чем Excel (например, экономисты с базовыми знаниями программирования или программисты, работающие над экономическими моделями).
С удовольствием отвечу на ваши вопросы в комментариях или личных сообщениях. Также, в интернете можно найти документация к системе и несколько обучающих видео.
