DSP на .Net под Windows. Джедайской Силы Пост
Всем привет!
В первой статье мы рассказали о нашей инфраструктуре в целом. Теперь пришло время сосредоточиться на конкретных продуктах. В этой статье речь пойдёт о DSP. Как многие знают, DSP (Demand Side Platform) — автоматизированная система покупки рекламы. Требования к системе жёсткие: она должна держать высокую нагрузку (тысячи запросов в секунду), быстро отвечать (до 50 мс, а то и меньше) и, самое главное, выбирать максимально подходящие объявления. Чаще всего такие проекты разрабатываются под Linux, мы же смогли создать по-настоящему высокопроизводительный сервис под Windows Server. Как этого добиться, и как это удалось нам? Об этом я и расскажу.

У нас DSP состоит из двух приложений: собственно биддер — Windows-сервис для взаимодействия с SSP, и DspDelivery — ASP.NET приложение для конечной доставки и регистрации интерактивных действий пользователя. С доставкой всё более-менее просто, а вот на биддер посмотрим повнимательнее.
Платформа
В качестве платформы используется .NET, основной язык — C#. Раз мы пишем биддер, то нам нужен веб-сервер и обвязка. Сначала мы пошли по простому пути: прикрутили IIS, создали ASP.NET-приложение с фреймворком ASP.NET Web API и начали пилить бизнес-логику. Быстро стало понятно, что вся эта конструкция не держит больше 500–700 запросов в секунду. Как бы мы ни заклинали IIS, ни подкручивали 100500 параметров, проблема не решалась. И совсем доставало, что залезть внутрь IIS нет возможности, а значит полного контроля над ситуацией нам не добиться. IIS — пресловутый черный ящик, в котором тяжело что-то кардинально изменить.
Тогда мы попробовали сервер проекта Katana (реализация OWIN-инфраструктуры от Microsoft). Katana — проект с открытым исходным кодом, поэтому можно было увидеть внутренности. К тому же, у Web API есть поддержка OWIN, а значит, сильно менять код не придется. Katana предоставляет возможность работать как с IIS, так и с их простым сервером, написанным на основе .NET-овского HttpListener. Именно его мы и взяли. Результат порадовал: теперь сервер держал около 2000 запросов в секунду, а ASP.NET приложение трансформировалось в Windows-сервис.
Однако нагрузка на сервера увеличивалась, пилились новые фичи. Становилось понятно, что и этот вариант нас тоже не устраивает. Тогда мы пошли на кардинальные меры: от всей Катаны остался только HttpListener с небольшой обвязкой для асинхронности, от Web API не осталось ничего, то есть приложение стало полностью заточено под HTTP-запросы для биддера. В результате сервер стал способен обрабатывать до 9000 запросов в секунду. Вывод прост: вся OWIN- и Web API-обвязка оказывает критическое влияние на высокопроизводительные приложения. Хотите быстрее — пишите проще и неуниверсально. (Это не говорит о том, что внутри приложения должен быть ядерный говнокод. У нас всё модульно, вполне расширяемо: DI, паттерны и всё такое). Пример кода обработки запросов:
var listener = new HttpListener();
listener.IgnoreWriteExceptions = true;
// Настройка прослушиваемых хостов
listener.Start();
var listenThread = new Thread(() =>
{
while (listener.IsListening)
{
try
{
var result = listener.BeginGetContext(ar =>
{
try
{
var context = listener.EndGetContext(ar);
byte[] buffer = null;
object requestObj = "";
if (context.Request.HttpMethod == "POST")
{
try
{
if (context.Request.RawUrl.Contains("/openrtb"))
{
buffer = HandleOpenRtbRequestAndGetResponseBuffer(context.Request, out requestObj);
}
else if (context.Request.RawUrl.Contains("/doubleclick"))
{
buffer = HandleDoubleClickRtbRequestAndGetResponseBuffer(context.Request, out requestObj);
}
// обработки от других систем
}
catch (Exception ex)
{
// Логгирование
}
if (buffer != null)
{
WriteNotEmptyResponse(context.Response, buffer, "application/json");
}
else
{
WriteEmptyResponse(context.Response);
}
}
else
{
WriteNotFoundResponse(context.Response);
}
context.Response.Close();
}
catch (Exception ex)
{
// Логгирование
}
}, listener);
result.AsyncWaitHandle.WaitOne();
}
catch (Exception ex)
{
// Логгирование
}
});
listenThread.Start();
Схема работы
Вернёмся к предметной области и посмотрим на схему работы биддера:
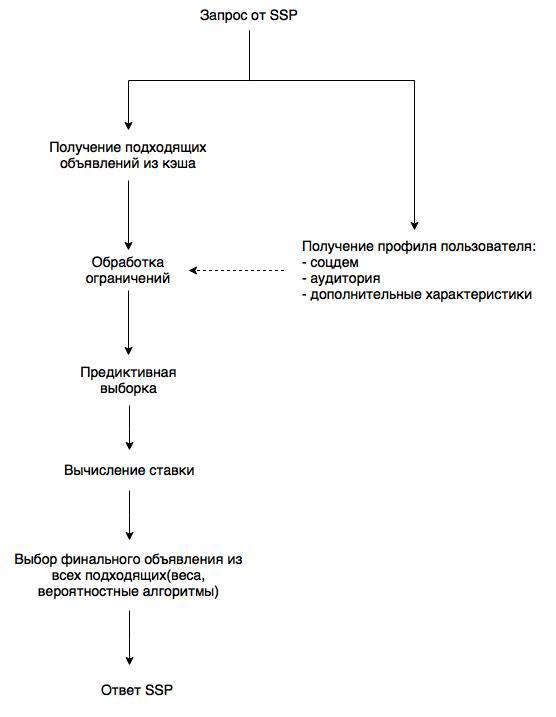
Схема упрощенная, однако по ней понятно, на что стоит обратить внимание. Во-первых, инвентарь (то есть список объявлений с ограничениями). Список хранится в памяти и раз в минуту обновляется. А вот за профилем пользователя необходимо каждый раз лезть в базу. В этой же базе DMP обновляет профили, что позволяет не тратить ресурсы на удаленное взаимодействие с источниками данных. Ограничения задаются по гибкой схеме: любые атомарные фильтры (принадлежность к аудитории, гео, черно-белые списки доменов, соцдем и т.д.) объединяются в любые последовательности и/или-контейнеров. Предиктор позволяет наилучшим образом оптимизировать покупку. И здесь мы подходим к вопросу выбора базы данных. Без быстрого и масштабируемого решения невозможно обеспечить максимальную производительность.
База данных
Здесь нам тоже не удалось попасть с первого раза и начинали мы с красивых раскрученных решений (нет, не с MS SQL). Сначала взяли MongoDB (2.4): привлекали хорошая производительность, JSON-схема, репликация, шардирование из коробки, якобы простая поддержка расширения кластера. На деле всё оказалось не столь радужно. Блокировки на операциях записи сильно тормозили работу системы, шардирование оказалось сложно конфигурируемым (до сих пор помню как мы спорили, какой ключ шарда для коллекции выбрать) — данные никак не хотели распределяться равномерно, а сброс данных на диск (не столь частый, впрочем) добавлял дополнительных блокировок.
Следующей попыткой была Couchbase. Здесь уже не было блокировок и структура данных была попроще — обычное key-value. Но недостатки всё равно имелись: нагрузка на дисковую подсистему была чрезмерной, а также недостаточная конфигурируемость и отвратительная расширяемость (вернее отсутствие таковой). Техподдержка тоже оставляла желать лучшего.
Но именно тогда у суровой и дорогой БД Aerospike появилась свободная лицензия. Это оказалось подходящим решением. Возросла скорость, упала нагрузка на диск, упростилось конфигурирование кластера. У Aerospike тоже находились баги. Но после описания проблемы на форуме (например, проблема с выборкой по диапазону) она оперативно фиксилась в обновлении. В итоге у нас Aerospike-кластер из 7 серверов, легко обрабатывающий всю нагрузку.
Интеграция
Главная интеграция DSP — это, конечно, сторонние SSP. И они явно делятся на две всем известные группы: российские и западные. С российскими всё просто: они работают по протоколу OpenRTB 2.* и отличаются только наличием или отсутствием дополнительных фич (типа поддержки fullscreen-баннера). Каждая западная SSP работает по собственному протоколу и интеграция занимает не столь короткое время. То есть приходится реализовывать поддержку их протокола. Самый известный пример — Google.
Стоит сказать про чисто техническое взаимодействие. Во-первых, информация о действиях посетителей посылается в DMP через Apache Flume. Ещё одно направление: выгрузка статистики в Trading Desk. В данном случае соотвествующий сервис Trading Desk сам запрашивает статистику за некоторый минимальный период и получает её в запакованном виде (zMQ + MessagePack). после чего группирует и записывает в свою БД (как раз так работает Hybrid).
Синхронизация
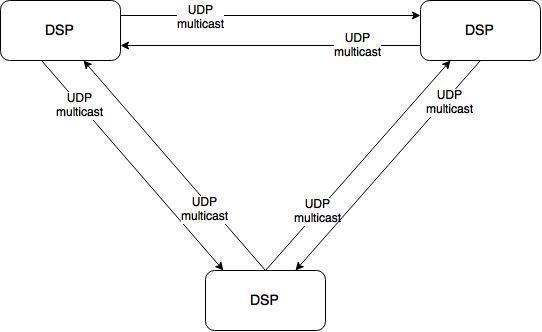
Теперь поднимемся на уровень выше и посмотрим на систему целиком. Это 10 серверов, на каждом по одному экземпляру DSP. Для корректной работы инстансам нужно обмениваться данными. Например, о степени откуртки кампании (чтобы избежать перекрута) и корректной работы ограничения показов конкретной кампании конкретному пользователю (frequency capping). Для этого при каждом действии посетителя рассылается уведомление другим инстансам DSP по UDP multicast. Таким образом производится синхронизация. Никаких суровых фреймворков тут не используется, только чистый и незамутненный хардкор.
Результат
В итоге мы получили высокопроизводительную и отказоустойчивую систему, где каждый сервер обрабатывает до 9000 запросов в секунду с ответом до 10 мс. Мы прошли непростой путь и теперь точно понимаем, какой должна быть современная DSP и знаем на практике, как её построить. Впереди у нас планы по интеграции с новыми системами, улучшению оптимизации закупок и распределения бюджета. И ещё много всего интересного))
Для интересующихся, конфигурация системы:
- 10 серверов (Windows Server 2008 R2) для приложения (bidder + delivery) — 2x Xeon E5 2620 по 6 ядер на каждый, 64 ГБ ОЗУ,
- 7 серверов (CentOS 6.6) Aerospike — 1x Xeon E5 2620, 200 ГБ ОЗУ.
