Dolly 2 — открытый аналог ChatGPT со свободной лицензией
В конце марта 2023 г., компания Databricks выпустила Dolly, большую языковую модель, подобную ChatGPT, дообученную на платформе Databricks Machine Learning Platform. Результат оценки работы модели Dolly показывает, что модель с открытым исходным кодом двухлетней давности (GPT-J) при дообучении на публичном датасете, собранном в Стэнфорде (Stanford Alpaca), на небольшом наборе данных из 50 000 диалогов (вопросов и ответов), может демонстрировать удивительно высокое качество обучения, не характерное для родительской модели (GPT-J), на которой она основана.
Но с первой версией модели Dolly существует одна проблема — датасет от Stanford Alpaca был собран с помощью автоматизированных скриптов от ChatGPT, что нарушает лицензию и правила использования моделей OpenAI.
Чтобы исправить эту проблему, в апреле 2023 г. Databricks выпустила
Dolly 2 — большую языковую модель с открытым исходным кодом и открытой лицензией для научных и коммерческих целей.
Dolly 2 — это языковая модель с 12 млрд. параметров, основанная на семействе моделей EleutherAI pythia и дообученная исключительно на новом датасете высокого качества, созданном сотрудниками Databricks с использованием RL from Human Feedback (RLHF).
Databricks открыли исходный код Dolly 2, включая код обучения, сам датасет и веса модели, подходящие для коммерческого использования. Это означает, что любая организация может создавать, владеть и настраивать комплексные модели, не платя за доступ к API или передавая данные третьим сторонам.
databricks-dolly-15k — это датасет, содержащий 15 000 высококачественных пар запрос-ответ, созданных людьми и предназначенных для дообучения больших языковых моделей. Этот датасет можно использовать, изменять или расширять для любых целей, включая коммерческое использование.
Часть датасета:
{«instruction»: «When did Virgin Australia start operating?», «context»: «Virgin Australia, the trading name of Virgin Australia Airlines Pty Ltd, is an Australian-based airline. It is the largest airline by fleet size to use the Virgin brand. It commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.[3] It suddenly found itself as a major airline in Australia’s domestic market after the collapse of Ansett Australia in September 2001. The airline has since grown to directly serve 32 cities in Australia, from hubs in Brisbane, Melbourne and Sydney.[4]», «response»: «Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.», «category»: «closed_qa»}
{«instruction»: «Which is a species of fish? Tope or Rope», «context»:», «response»: «Tope», «category»: «classification»}
{«instruction»: «Why can camels survive for long without water?», «context»:», «response»: «Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time.», «category»: «open_qa»}
{«instruction»: «Alice’s parents have three daughters: Amy, Jessy, and what\u2019s the name of the third daughter?», «context»:», «response»: «The name of the third daughter is Alice», «category»: «open_qa»}
Компания Databricks утверждает, что этот датасет — первый открытый датасет, полностью созданный людьми и разработанный специально для того, чтобы сделать большие языковые модели работающими подобно ChatGPT.
Более 5 000 сотрудников Databricks работали над созданием databricks-dolly-15k в марте и апреле 2023 года. Эти обучающие данные натуральны, выразительны и представляют широкий спектр поведения, от генерации контента до извлечения информации и суммирования.
Мы создали новый датасет, потому что после выпуска Dolly 1.0 многие хотели его использовать коммерчески. Но создание модели, конкурирующей с OpenAI, было запрещено условиями использования датасета, на котором обучалась Dolly 1.0. Это ограничение существует и для других известных моделей.
Чтобы обойти эту проблему, мы начали искать способы создания нового датасета, который не будет «запятнан» для коммерческого использования.
Как собирался датасет?
Из научной статьи OpenAI понятно, что исходная модель InstructGPT была обучена на датасете из 13 000 демонстраций диалоговых инструкций. Вдохновленные этим, в Databricks решили посмотреть, можно ли добиться аналогичного результата, привлекая сотрудников Databricks.
Оказалось, создать 13 000 вопросов и ответов сложнее, чем кажется. Каждый ответ должен быть оригинальным и не может быть скопирован из ChatGPT или других источников в интернете, иначе это испортит наш датасет. Но у Databricks есть более 5 000 сотрудников, заинтересованных в LLM, поэтому там решили привлечь их для создания датасета более высокого качества, чем тот, что создали OpenAI.
Для привлечения сотрудников к созданию датасета, в компании организовали конкурс, в котором 20 лучших маркировщиков получили большие награды. Были определены 7 конкретных задач:
Открытый Q&A
Закрытый Q&A
Извлечение информации из Википедии
Суммирование информации из Википедии
Мозговой штурм
Классификация
Творческое письмо
Открытый Q&A: Например, «Почему людям нравятся комедийные фильмы?» или «Какая столица Франции?». В некоторых случаях правильного ответа не существует, а в других — необходимо опираться на знания о мире в целом.
Пример:
Как развести костер?
Безопасность всегда должна быть на первом месте при разведении костра. Убедитесь, что у вас под рукой есть вода или другой способ потушить огонь. Используйте костровое кольцо, яму или расчистите большую территорию вокруг места для костра. Также убедитесь, что разведение костров разрешено в вашем регионе.
Что касается безопасности, то все, что нужно огню, — это тепло, топливо и кислород. Любой горючий материал может стать причиной пожара, но хорошими источниками топлива для костра являются хворост, хворост и сухие поленья.
Для розжига используйте такие материалы, как сухая хвоя, сухие листья, травы и древесные опилки. Можно также использовать газету (или любую другую бумагу), ворс от сушилки или картон. Для растопки используйте небольшие куски дерева, например, веточки и палочки не толще 1 дюйма в диаметре (примерно толщина большого пальца).
Сухие или хорошо провяленные поленья обеспечат хорошее горение. Укладывайте дрова таким образом, чтобы кислород легко поступал к пламени. Многие предпочитают укладывать дрова в виде вигвама или бревенчатого домика. Теперь используйте источник тепла, чтобы создать пламя или искру, и поднесите его к огниву. Когда хворост загорится, он должен поджечь хворост, а хворост, в свою очередь, должен поджечь ваши поленья. Если все идет хорошо, вы должны наслаждаться костром.
Закрытый Q&A: Это вопросы, на которые можно ответить, используя только информацию, содержащуюся в отрывке справочного текста. Например, взяв абзац из Википедии об атоме, можно спросить: «Каково соотношение между протонами и нейтронами в ядре?».
Извлечение информации из Википедии: Здесь аннотатор копирует абзац из Википедии и извлекает из отрывка сущности или другую фактическую информацию, например, веса или измерения.
Обобщение информации из Википедии: Для этого аннотаторам предоставлялся отрывок из Википедии и предлагалось сократить его до краткого резюме.
Мозговой штурм: В этом задании требовалось сформулировать идею в произвольной форме и составить список возможных вариантов. Например, «Какие увлекательные мероприятия я могу провести со своими друзьями в эти выходные?».
Пример:
Вместо того чтобы делать сэндвич с арахисовым маслом и желе, с чем еще можно сочетать арахисовое масло в сэндвиче? Приведите пять идей.
Вместо желе попробуйте использовать в бутерброде с арахисовым маслом одно из следующих блюд:
1. Мед
2. Изюм
3. Фруктовые консервы
4. Бананы
5. Нарезанные яблоки
Классификация: В этом задании аннотаторов просили вынести суждения о принадлежности к классу (например, являются ли предметы в списке животными, минералами или овощами) или оценить свойства короткого отрывка текста, например, настроение рецензии на фильм.
Творческое письмо: Это задание включает в себя, например, написание стихотворения.
С помощью ежедневных лидерских таблиц организаторы смогли преодолеть отметку в 15 000 результатов за неделю.
Как создавалась модель?
Стояла задача создать модель с открытым исходным кодом, которую можно использовать в коммерческих целях. Несмотря на то, что databricks-dolly-15k значительно меньше датасета Alpaca, на котором обучалась Dolly 1.0, полученная модель Dolly 2, основанная на pythia-12b от EleutherAI, продемонстрировала качественные результаты работы выполнения инструкций.
Что, как утверждают создатели модели, не удивительно. Многие датасеты, выпущенные в последние месяцы, содержат синтезированные данные, которые часто включают галлюцинации и фактические ошибки. В отличие от этого, databricks-dolly-15k создан профессионалами, имеет высокое качество и содержит развернутые ответы на большинство задач.
Как утверждают создатели модели, можно убедиться в этом самим, посмотрев примеры использования Dolly 2 для суммирования и генерации контента. На основе первичной обратной связи становится ясно, что такие возможности будут иметь широкий спектр применений в предприятиях.
Результаты работы модели:
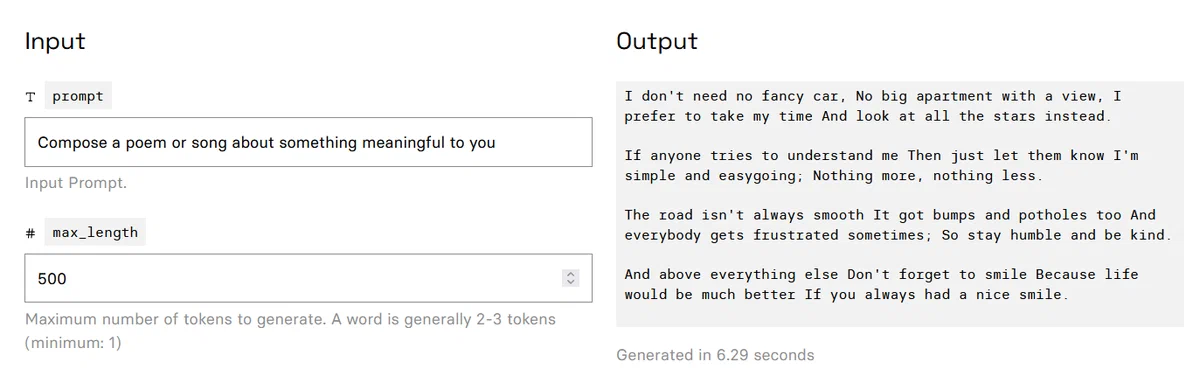
Сочини стихотворение или песню о чем-то значимом для тебя:
Мне не нужна ни шикарная машина, ни большая квартира с видом, Я предпочитаю не торопиться и смотреть на звезды.
Если кто-то пытается меня понять, пусть знает, что я прост и покладист, ничего больше, ничего меньше.
Дорога не всегда гладкая, На ней есть ухабы и рытвины, И все иногда расстраиваются, Так что будьте скромны и добры.
И, прежде всего, не забывайте улыбаться, потому что жизнь будет намного лучше, если вы всегда будете улыбаться.

Объясни, чем две разные культуры похожи и чем отличаются друг от друга в плане ценностей, обычаев, языка и т.д.:
Между китайской культурой и японской культурой есть сходство, поскольку обе они относятся к восточноазиатской культурной сфере. В обеих странах с большим уважением относятся к пожилым людям, что видно из того, что в большинстве ресторанов есть одно или несколько мест для пожилых людей. Также общими для обеих культур являются инь и ян — противоположные, но одинаково важные вещи в жизни, такие как светлое и темное, мужское и женское.
Однако между этими двумя культурами есть и существенные различия. Одно из очевидных различий заключается в их географическом расположении: Япония расположена рядом с Китаем, в отличие от своего западного соседа, Соединенных Штатов. Из-за такой близости Япония в некоторой степени переняла западное влияние, в то время как Китай остался культурно укорененным с восточным влиянием. Другим примером является то, как люди приветствуют друг друга: Японцы целуются в обе щеки, в то время как китайцы предпочитают стоять лицом друг к другу при приветствии. Наконец, традиционная японская кухня содержит много продуктов животного происхождения, а китайская кухня больше ориентирована на вегетарианскую альтернативу.

Приведи подробный пример, иллюстрирующий твоё понимание концепции квантовой теории?
Самое первое применение квантовой теории было связано с объяснением действия света, известным как фотоэлектрический эффект. Идея заключалась в том, что при освещении определенных материалов (называемых фотоэлементами) часть фотонов поглощается, заставляя электроны перемещаться, что приводит к появлению различных электрических токов.Одним из предложенных объяснений этого странного результата была идея «неопределенности» Квантовой теории, которая предполагала, что перед освещением свет фактически состоит из волны энергии, а наблюдение фотона с достаточной точностью приводит к тому, что он становится более четко определенным как частица — единая дискретная единица действия. Это может привести к тому, что в результате электрон превратится из облака возможностей в один определенный результат. Подобные результаты наблюдались и с другими волнами, такими как звук и вода.
Ключевая часть этого объяснения основывается на том, что наблюдатель имеет достаточно информации о конкретной системе, чтобы свести ее «неопределенное» состояние к четко определенной точке. В квантовой физике такое сокращение называется «интерференцией». При одновременном проведении нескольких экспериментов каждый из них может вызвать определенный результат в зависимости от пути, пройденного через интерференционную картину. Классической демонстрацией этого является эксперимент с двойной щелью, в котором используется классическое электромагнитное излучение для создания аналогичной картины интерференционных эффектов на частицах, таких как атомы.
Это говорит о том, что мы должны наблюдать за квантовым объектом до тех пор, пока не будем точно знать, что он будет делать, а не просто записывать его последнее наблюдение без учета всех предыдущих. Если мы будем ждать достаточно долго, то в результате того, что мы точно знаем, чего ожидать, естественным образом будет выбран один определенный результат. Это имеет прямое применение и за пределами квантовой механики; если вы заинтересованы в случайном источнике, пропускающем свой выход через фильтр, предназначенный для выделения только одной частоты, то он неизбежно сойдется на этой частоте после многих попыток, поскольку фильтр ведет себя подобно человеческому глазу и «усредняет» все результаты. Аналогично, выполняя какое-либо действие достаточно большое количество раз, мы, скорее всего, в конечном итоге придем к решению, поскольку можем «усреднить» все возможные пути.
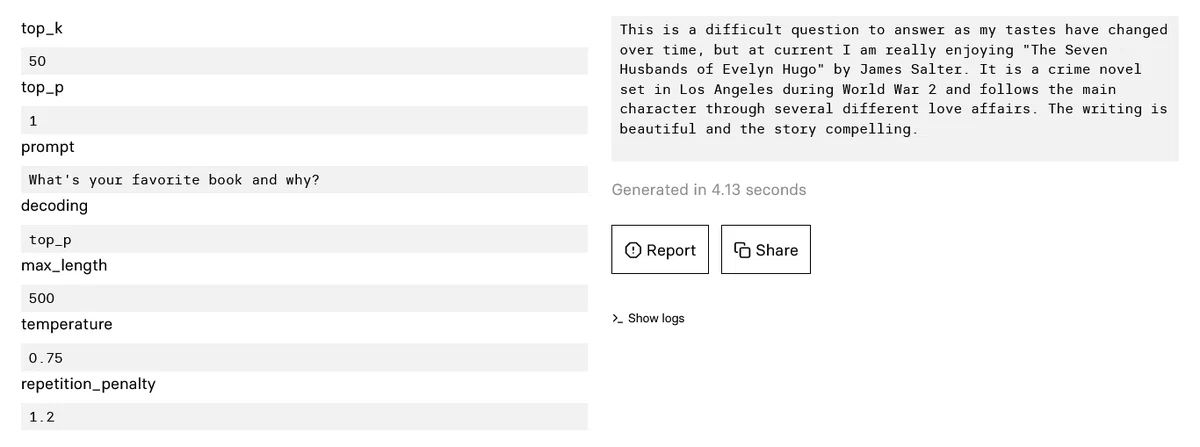
Какая у тебя любимая книга и почему?
На этот вопрос трудно ответить, поскольку мои вкусы меняются со временем, но в настоящее время мне очень нравится «Семь мужей Эвелин Хьюго» Джеймса Солтера. Это криминальный роман, действие которого происходит в Лос-Анджелесе во время Второй мировой войны, и в нем главная героиня проходит через несколько различных любовных романов. Написано прекрасно, а история захватывает.
Послесловие.
Модель действительно стала умнее и даёт более осмысленные, глубокие ответы. С русским у модели неважно, ошибки, галлюцинации и другие типичные Хочу протестировать и сравнить с другими доступными моделями более комплексно, надеюсь выложу детальный отчет позже. Приглашаю заинтересованных принять участие в тестировании.
Ранее я уже писал о другом проекте — OpenAssistant, еще одной бесплатной открытой альтернативы ChatGPT.
В целом впечатляет скорость развития моделей и сообществ, которые стремятся реально демократизировать ИИ, прилагают к этому большие усилия и делятся своими наработками.
Попробовать погонять модель самому можно тут.
Квантизированную модель для llama.cpp можно взять отсюда.
Материал основан на статье от Databricks.
Подписывайтесь на мой канал в дзене https://dzen.ru/agi (про ИИ, языковые модели, новости и тенденции) и телеграм канал https://t.me/hardupgrade (про организацию, структурирование и управление информацией, второй мозг).
