Does the latency matter?

Есть исследование от Google, которое говорит, что если ваш сайт открывается больше трех секунд, то вы потеряете около 40% десктопных пользователей и более 50% — мобильных. Еще есть репорт от Amazon, который говорит, что для Amazon каждые 100 мс дополнительного latency стоит им 1% продаж. В объемах Amazon это миллионы долларов.
В зависимости от вашего бизнеса вам стоит тоже ответить на вопрос: Does the latency matter?
Я работаю как системный инженер уже более 8 лет. Хочу поделиться опытом, который получил в процессе решения задач в компании Big Data Technologies. У нас есть какой-никакой highload. В пике это 30 тысяч rps, и вопрос с latency довольно остро стоит перед бизнесом.
Когда разработчику ставят задачу улучшить latency, он идет на Google PageSpeed Insights, прогоняет свой домен и смотрит, сколько выдало попугаев и какие этот сервис дает советы. Например, минифицировать JS, CSS, использовать изображения правильного формата и более 20 других советов.

Но что делать, если все эти советы уже выполнены? На локалхосте уже все летает, а в проде для каких-то пользователей вы испытываете высокое latency? Или, например, вам вообще этот сервис не подходит, у вас API. Первое, что вам нужно сделать — это нажать F12 в вашем браузере, открыть девелопер-консоль, зайти в раздел Network Timings и там ваш браузер сам расскажет структуру latency от вашего приложения со стороны клиента.
 Browser Network Timings
Browser Network Timings
Тут вы увидите много пунктов, которые вашего приложение вроде как не касаются — DNS, latency на установку TCP-соединений, установка шифрования. На все это уходит сотни миллисекунд. И только последний блок (Sending, Waiting, Receiving) — ответ от вашего приложения.
Сейчас мы пройдемся по всем этим пунктам, я посоветую bestpractises и протоколы, которые помогут вам протюнить latency.
Делая статистику, я использовал следующую методологию:
Утилита DIG с ключом trace, которая позволяет получить некэшированные DNS-ответы;
Утилита CURL с ключом -w, которая показывает тайминги;
Делал всегда 1000 запросов;
Считал 99 перцентиль.
Output утилита HTTPSTAT, которая показывает красивую визуализацию.
После всех настроек, которые я сегодня посоветую, вы сможете получить буст от 2 до 10 раз. В абсолютных значениях это около секунды для клиентов на оптике. Для клиентов на мобильных телефонах эти цифры могут быть значительно больше. Вот так получилось у нас:
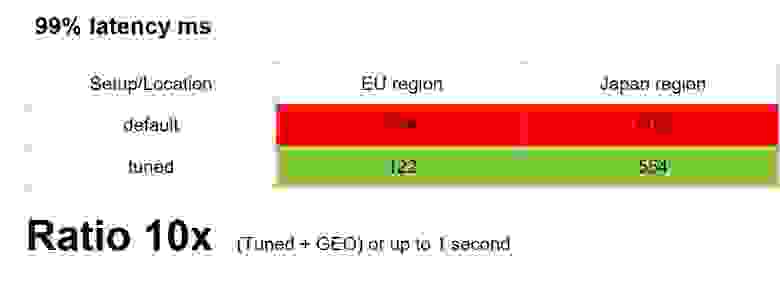 Final Stats
Final Stats
DNS
Как решить, какой name-сервер быстрый, и вообще как понять, стоит ли использовать текущего провайдера, хороший ли он? Можно воспользоваться, например, публичными сервисами — такими, как dnsperf.com или solvedns.com. Там есть топ, который показывает latency.
DNS resolution
 DNS resolution
DNS resolution
Но зачем нам его использовать, если мы можем легко сами измерить?
Я взял 7 различных DNS-провайдеров из трех основных облаков: GCP, AWS, Azure. Добавил CloudFlare как лидера и Afraid.org как аутсайдера рейтингов. А также добавил по одному российскому и белорусскому провайдеру DNS. После проверил домены, которые хостятся у этих DNS провайдеров.

DNS resolvers
У DNS есть две стороны — это resolver и name-сервер. Чтобы не проверять Google им же и иметь более честную статистику, я взял еще 4 популярных DNS-resolver и прогнал кросс-тестом 1000 запросов на все DNS name-серверы.

 99% NS responce time (ms)
99% NS responce time (ms)
Публичные рейтинги нас не обманули — CloudFlare как был в топе, так и остался. При этом видно, что у Amazon на 40 мс latency лучше, чем у Google, а Reg.ru в два раза лучше, чем Hoster.by. Если вы захотите сэкономить и возьмете максимально дешёвый name-сервер, не зная рейтинга, то можете получить разницу 400 мс на каждый запрос.
Вы можете подумать, что 50–100 мс — это очень мало, можно не обращать на это внимания. Но если, например, ваш бизнес производит какие-то live-транзакции, как биржа или банк, то это существенно.
Также бизнес имеет свойство расширяться. Возможно, вы пойдете в другие географические регионы, например, в Азию или в Южную Америку. Вы внезапно можете увидеть рост latency, который будет очень сложно затраблшутить, просто потому что ваш текущий DNS-провайдер не представлен в этих регионах и DNS-запросы гоняются через океан.
Первый шаг мы рассмотрели — это DNS-resolution или DNS-Lookup. Возьмите топовый name-сервер и проверьте, какой вообще у вас.
TCP
Следующий шаг, который делает ваш браузер — это устанавливает TCP-соединение. На установку handshake всегда требуется 1 RTT (Round-trip time), и вроде бы с этим ничего не сделать.
Но есть здравый смысл, который подсказывает: чем ближе наши пользователи локально к нашим серверам, тем более короткая сеть маршрутов. Поэтому логично хостить ваше приложение близко к большинству ваших пользователей.
Но если они геораспределены, классически будет использовать CDN для статики, а менее классически — включить CDN для динамики. Это стоит сделать, потому что у вас все равно будет буст за счет того, что между CDN и вашим сервером уже будет всегда установлено TCP-сессия, а пользователи будут ходить до ближайшего CDN-сервера.
Но самый интересный вариант — это разнести вашу инфраструктуру по геопринципу. Предположим, вы подняли свою инфраструктуру в разных регионах, но как донести пользователям, чтобы они ходили до ближайших до них серверов?
GEO DNS
С этим нам поможет GEO DNS — extension в DNS, который позволяет DNS-резолверу пробрасывать к name-серверу маску подсети клиента. То есть DNS-провайдер может вычислять клиента по IP, определять его геолокацию и отдавать для разных клиентов разные значения A-записей.
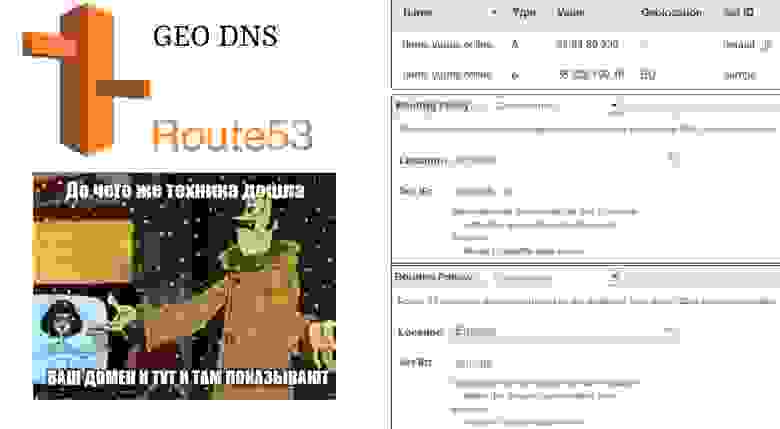
Многие DNS-провайдеры не поддерживают GEO DNS, но в AWS Route 53 такой функционал есть. В данном случае сайт по дефолту хостится в Японии, но для пользователей из Европы будет отдаваться IP европейского сервера. Я провел кросс-тест latency сервера AWS в Европе и Японии как клиент, до сервера Google Cloud в Европе и Японии.
 TCP connection time depending on Geolocation
TCP connection time depending on Geolocation
Тест показал, что даже на таком небольшом расстоянии, как Европа-Азия получаем за счет GEO DNS буст по latency 250–300 мс, и это на каждый round-trip. Это уже намного больше, чем 50 мс от выбора DNS-resolver.
TCP Fast Open (TFO)
В рамках TCP есть малоизвестный протокол TCP Fast Open (TFO), который позволяет сократить один round-trip на установку handshake для второго и последующих соединений до 0. TCP-соединение будет устанавливаться сразу же при ответе сервера.
Checking on client:

Сhecking on server:

Здесь видно, как это работает. Первый запрос занимает 260 мс, а второй уже с ключом TCP Fast Open — 4 мс.
Сам TCP Fast Open настраивается довольно легко:

Этот протокол работает с помощью так называемой TFO-куки, когда при первом соединении генерируется файл куки, который в последующем переиспользуется. Когда сервер видит валидный куки от клиента на стадии SYN, то на стадии SYN acknowledge сразу устанавливается соединение и можно не ждать полный handshake.
Но у него есть ряд проблем. Основные — это middleboxes и трекинг.
Middleboxes — это старое или дорогое ПО или железо, которое не знает про протокол TFO. TCP так устроен, что если железо видит непонятные настройки, оно просто отбрасывает эти пакеты, и сессию придется устанавливать заново.
Получается, мы, наоборот, проиграем во времени на установку TCP-соединения. Так как таких middleboxes в интернете довольно много. Согласно исследованию — порядка 14% трафика проходит через них, то есть нам потребуется повторное TCP соединение.
Но еще больше проблем вызовет трекинг. В браузерах есть приватные вкладки. Если мы будем использовать TCP Fast Open, они будут полностью скомпрометированы, потому что сервер сможет по TFO-куке определить пользователя вне зависимости от того, в приватной он вкладке или нет. Для браузеров это неприемлемо. Тем не менее, в браузерах есть суппорт TFO. По умолчанию он выключен, его нужно включать в настройках.
Кейс, где можно использовать TFO свободно — это общение сервер-сервер. Когда вы предоставляете какое-то API, ваши клиенты — это тоже сервера, и расположены вы географически далеко, то можно просто включить TFO и выигрывать 1 round-trip. Например, от Европы до Японии — это 300 мс.
Второй шаг TCP мы рассмотрели — это initial connection, или connecting: используем CDN, пробуем GEO DNS и, если вам подходит, можете попробовать TFO.
TLS
TLS — очень старый протокол, он развивается. Но все его развитие до версии 1.2 было направлено только на улучшение безопасности: отказ от скомпрометированных алгоритмов шифрования, добавление более сложных и устойчивых алгоритмов.
На апрель 2020, по данным CCLabs, только 22% из ТОП 150 тысяч веб-сайтов использовали TLS 1.3. Через эта цифра стала уже 44%. Этот было обусловлено, скорее всего, тем, что не так давно браузеры депрекейтили старые протоколы TLS 1.1, и администраторам было несложно вместе с депрекейтом старых протоколов добавить суппорт TLS 1.3.
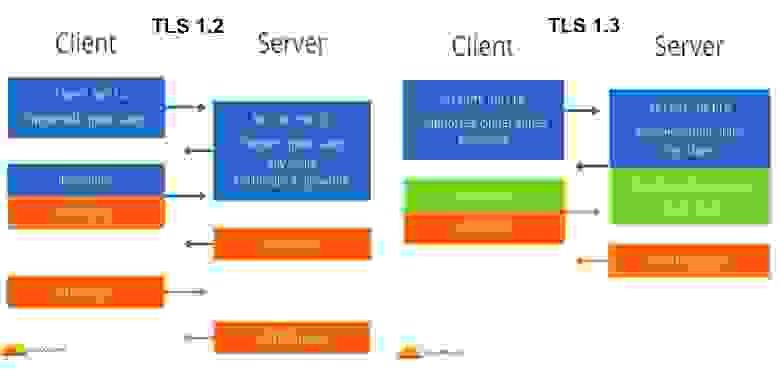
До его выхода на latency это не влияло абсолютно — всегда было полноценных два round-trip time. Но с выходом TLS 1.3 протокол изменили, и из коробки он стал тратить один round-trip. Теперь для установки шифрованного соединения достаточно одного пути: клиент — сервер — клиент.
 TLS 1.2 (2 RTT) vs TLS 1.3 (1RTT)
TLS 1.2 (2 RTT) vs TLS 1.3 (1RTT)
Но все же 44% — это даже не половина интернета, которая перешла на этот протокол.
Посмотрим, как это работает.
 TLS Handshake
TLS Handshake
При TLS 1.3 клиент сразу же при запросе «Client Hello» генерирует так называемый PSK-ключ (Pre-Shared Key) и отправляет его на сервер, а сервер с помощью этого PSK шифрует свой ответ «Server Hello», добавляет туда необходимую информацию. Клиент уже следующим вторым запросом вместе с «Finished» может отправлять шифрованный HTTP запрос.
HTTPSTAT наглядно показывает, чем отличаются TLS 1.2 и TLS 1.3:
При TLS 1.2 мы получаем 600 мс latency, а при TLS 1.3 — 300 мс. Это полноценный round-trip time. Но только разовым запросам нельзя верить, поэтому мы соберем статистику.
 TLS 1.2 vs TLS 1.3
TLS 1.2 vs TLS 1.3
Явно видно, что мы получаем один round-trip benefit просто за счет включения этого протокола. Но у TLS 1.3 есть еще такой функционал, как Zero Round Trip.
TLS 1.3 0-RTT
0-RTT работает очень похоже, как TCP Fast Open. Клиент при втором и последующих соединениях может использовать файл Early-Data, который добавляется в «Client Hello». Сервер валидирует Early-Data и отправляет в финиш, что позволяет установить TLS соединение 0-RTT.
 TLS 1.3 Zero Round Trip
TLS 1.3 Zero Round Trip
Это включается довольно просто:
nginx > 1.15.4, OpenSSL 1.1.1 or higher or BoringSSL
Вам нужен не древний веб-сервер и ОС, где OpenSSL не старше, чем 1.1.1, например Ubuntu 18, и три строчки в конфиге Nginx:
ssl_protocols TLSv1.3 — версия протокола;
ssl_early_data on;
proxy_set_header Early-Data $ssl_early_data — добавление специального хедера early_data или под любым другим названием, которое сможет обработать ваш бэкенд.
Этот хэдер необходим для защиты от так называемых replay-атак, когда человек в середине может взять слепок шифрованного трафика и начать его повторять. Если ваше приложение уязвимо — например, вы банк и явно не хотите, чтобы запросы с транзакциями повторялись бесконечно, — то вам нужно на бэкенде обрабатывать этот кастомный хэдер. И это не очень большой limitation, чтобы получить отличный буст.
К сожалению, с помощью curl нельзя проверить TLS 1.3 с early_data, но мы можем проверить с помощью утилиты OpenSSL. При первом запросе мы генерируем файл session.pem, а при втором — используем с ключом early_data.
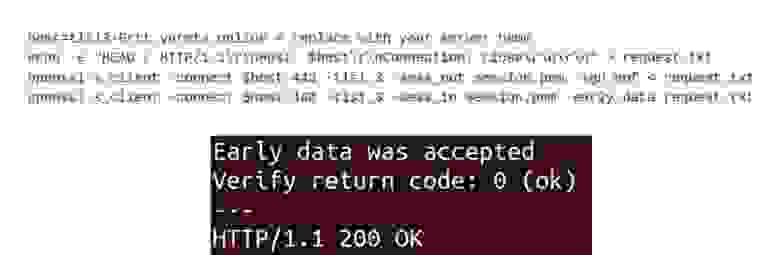 Checking
Checking
Если на сервере правильно все настроено, вы увидите «Early data was accepted». Early data, в отличие от TFO, включена во всех браузерах по умолчанию. Вы получите буст от ваших клиентов сразу же.
RSA key length
Также в рамках TLS хочется поднять тему длины RSA ключа.
По дефолту сертификаты, например от Let’s Encrypt, шифруются ключом длиной 2048 бит. Вы можете купить более секьюрный сертификат, шифрованный ключом в 3072 или 4096 бит. Но при этом всегда надо держать в уме, что время на терминацию трафика будет увеличиваться в 6–7 раз за каждое удвоение длины ключа.
 RSA key length
RSA key length
У меня есть реальный кейс из практики — security team купила за недорого, как они считали, более секьюрный сертификат и выкатили его на прод. Пришел вечерний load и началась деградация прода — сервера задыхались под CPU. Это решилось только увеличением процессорных мощностей. А root cause про новые SSL сертификаты мы поняли только на следующий день.
TLS config best practice
Последнее, что я хотел бы затронуть в рамках TLS — это прекрасный сайт Mozilla SSL Configuration Generator, в котором можно просто накликать конфигурацию вашего веб-сервера.
 TLS config best practice, https://ssl-config.mozilla.org
TLS config best practice, https://ssl-config.mozilla.org
Например, можно взять Nginx, выбрать Modern, указать версию OpenSSL и вы получите сгенерированный конфиг — пользуйтесь!
Третий шаг — TLS setup, или же SSL мы рассмотрели: включаем TLS 1.3 и Early-Data.
Мы пришли к самом интересному — это наш HTTP-запрос от клиента в браузере.
HTTP
По данным W3Techs на апрель этого года 49% от ТОП 10 млн веб-сайтов поддерживают HTTP/2, то есть 51% интернета не поддерживает HTTP/2. А мы в с вами 2021 году, и с 2018 года уже идет активная разработка протокола HTTP/3, на который уже очень скоро нужно будет переходить. Но сначала обсудим, зачем нам HTTP/2.
HTTP/2
По дефолту все веб-сервера настроены на HTTP/1, и многие не знают, что включение протокола HTTP/2 может улучшить response для ваших клиентов. Например, один из бенефитов, который нам дал HTTP/2 — это возможность параллельно отправлять ответы и запросы по одному TCP соединению.

Для протокола HTTP/1.1 у каждого браузера есть захардкоженная цифра от 6 до 9 TCP-соединений на один домен, и запросы/ответы идут последовательно в рамках этих TCP-соединений. В протоколе HTTP/2 вы можете для второго и последующих запросов отправлять ответы в рамках одного соединения.
Также есть технология HTTP/2 Server Push, которая позволит отправлять клиенту больше данных, чем он даже запрашивал. Например, вы точно знаете, что с запросом на индекс HTML нужно отправить JS и CSS, и вы можете преднастроить так, что к юзеру будут отправляться дополнительные данные. Это может дать хороший performance boost, но на самом деле Server Push почти не используется, потому что есть проблемы с браузерным кэшом. Вы не можете знать, что есть в кэше у вашего пользователя. Поэтому отправка CSS может стать, наоборот, лишней, если пользователь уже имеет этот CSS у себя в кэше.
Если взять большую картинку, разбитую на множество маленьких для увеличения скорости загрузки, то такой кейс отлично показывает лимит из-за последовательных запросов и ответов. Наглядно разницу между HTTP/1.1 и HTTP/2 можно увидеть по ссылке:
Но сегодня мы уже очень близки к HTTP/3.
HTTP/3
HTTP/3, он же QUIC (Quick UDP Internet Connections) — протокол, который изначально придумали в Google, чтобы решить проблему с растущим трафиком на YouTube. А теперь это уже почти законченный официальный протокол. Под капотом HTTP/3 все, что есть при классическом TCP-соединении, но только завернутое в UDP.
А когда мы слышим UDP, мы вспоминаем анекдот который, если до вас не дошел, то я его не повторю. Потому что проблема UDP — это потеря пакетов и Congestion Control (контроль потока).
В QUIC это решено за счет так называемой абстракции QUIC Streams, которая, кроме этого, решает проблему свитчинга сетей у ваших клиентов. Например, клиент пользуется Wi-Fi с телефона, потом переключится на 3G, на 4G и обратно на Wi-Fi. В рамках TCP, где определение клиента — это его IP-адрес и порт, при смене сети каждый раз нужно устанавливать соединение заново. А при QUIC Streams, которые присваиваются клиенту, можно продолжать переиспользовать соединение.
Давайте протестим как работает HTTP/3 и как его нам внедрить. Так как на текущий момент поддержка QUIC в nginx в разработке, то, чтобы ее включить в nginx, нам нужно его скомпилить.
К счастью, есть мануал, по которому довольно легко это сделать. А можно переиспользовать мой docker image: ymuski/nginx-quic и просто добавить в nginx две строки в конфиг:
Nginx config:
listen 443 quic reuseport;
add_header alt-svc 'h3-29=":443"; ma=86400';
В хэдере указывается версия протокола (h3–29 — это версия драфта) и порт, на котором у нас HTTP/3. Когда вы это включите, скорее всего, ничего не заработает (или хочется верить, что не заработает), потому что вы точно забудете открыть на firewall 443/UDP (кто вообще открывает UDP?). Открываем порт и идем тестировать.
Для теста можно зайти на сайт HTTP/3 Check и посмотреть, включен ли у вас HTTP/3 и на какой версии. Но онлайн тесты — это не наш путь. Давайте сами проверим с помощью curl — что нам мешает?
Для этого и curl тоже скомпилить. Открываем другой мануал или используем docker image, который я скомпилил — docker image: ymuski/curl-http3
docker run -it --rm ymuski/curl-http3 curl -Lv https://http3.yurets.online --http3
Видим, что на мой запрос в nginx log HTTP/3 — 200.

Более наглядно output от curl:
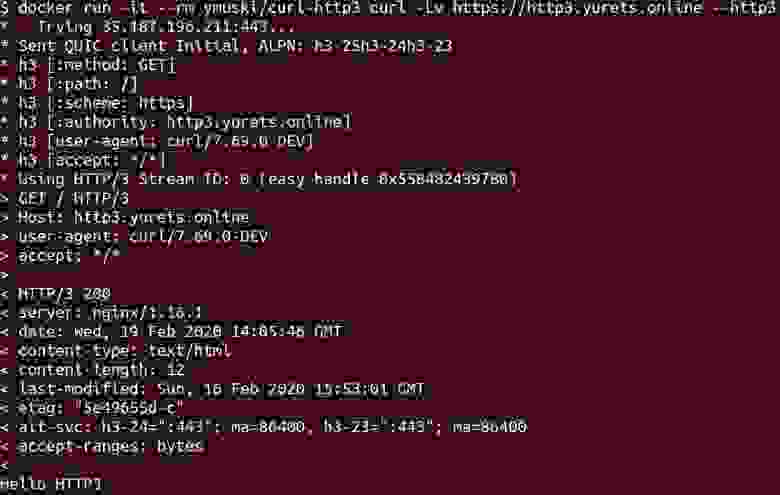
Тут нет привычной установки TLS-соединения. Есть блок h3, который создает QUIC Streams.
В браузерах на сегодняшний день уже впилена поддержка HTTP/3, ее нужно включить в настройках. Но хороший вопрос — вообще зачем нужен HTTP/3, дает ли он вообще какой-то буст по latency?
Я провел тест на один и тот же домен на HTTP/2 и HTTP/3.
 HTTP/2 vs HTTP/3
HTTP/2 vs HTTP/3
Буст показал из разных точек мира, что HTTP/3 отвечает в 1.14x-1.5x быстрее, чем HTTP/2 — это от 14 до 50% преимущество. Вроде бы неплохо. Но первый запрос по дефолту прилетит вам на HTTP/1.1. Там он увидит редирект на HTTPS (если вы его сконфигурировали), хэдер Alt-Svc, и только потом уже перейдет на HTTP/3 или HTTP/2.
Как этого избежать? У нас есть новые DNS-записи.
Сейчас идет утверждение в Internet Engineering Task Force новых DNS-записей HTTPS. Поэтому мы можем создать дополнительную DNS-запись, и браузер ее будет запрашивать вместе с A-записью. И наш самый первый запрос прилетит уже по HTTP/3.
Например, в CloudFlare уже можно добавлять записи и наслаждаться. Это довольно крутой буст, который нас ждет. Mozilla и Safari уже поддерживают DNS-запись HTTPS, в Chrome это еще пока в разработке.
HTTP Compression
Кажется, тут все понятно — чем меньше наши данные, тем быстрее они будут у клиента. Но это не совсем так, нам нужно добавить время на сжатие этого контента.
Я сравнил два протокола: старый добрый Gzip и модный Brotli:
 Json 137kb file check
Json 137kb file check
В принципе, получились схожие цифры. На разных уровнях сжатия они ведут себя по-разному — что-то лучше сжимает, что-то быстрее отдает. На моем тестовом файле лучший response time я получил на среднем уровне сжатия.
Вам нужно понять, какой у вас трафик и эмпирически поиграться с компрессией, но включать ее определенно нужно.
HTTP Cache
Юзайте кэш!
Etag and Last-modified headers — weak caching headers (validators)
Expires and Cache-control — strong caching headers (refresh information)
Его очень легко включить, он гибок. Если вы будете использовать так называемый strong caching headers, то latency будет 0 мс, потому что все будет закэшено в браузере клиента.
Это был последний шаг. Подключайте HTTP/2, включайте компрессию и кэш. Попробуйте потестить HTTP/3 — он может вам дать значительный буст, плюс первого редиректа вы тогда тоже лишитесь.
Итого

Useful links
Мой сайт на HTTP/3 и github repo, где я считал статистику. Там есть все скрипты, как я это делал, настройки Nginx для каждого случая и дополнительные данные, например, не по 99, а по 50 перцентилю. Видео моего выступления на HighLoad++ Весна 2021.
Тех, кто соскучился по профессиональному нетворкингу и хочет быть в курсе всех передовых решений ждёт ещё два HighLoad++ в этом году: 20–21 сентября в Санкт-Петербурге и 25–26 ноября — в Москве. Питерское расписание уже готово.
И еще доступен — бандл из двух конференций: Saint HighLoad и HighLoad++ 2021 c 20% cкидкой. Предложение действительно до 19 сентября 2021 года.
