Для мониторинга CronJob в Kubernetes нужен простой советский…
Привет, Олимпийский Хабр! Меня зовут Аня, я работаю в Ozon: строю и развиваю инфраструктуру мониторинга в Observability-платформе. Моя команда помогает разработчикам следить за своими сервисами и своевременно получать алерты, если что-то идёт не так.
На Хабре довольно много статей о том, что такое кроны, как и где можно запускать их по расписанию, о плюсах и минусах каждого варианта и о том, как запускает кроны Kubernetes. Поэтому в моей статье об этом мы говорить не будем.
Я расскажу, как мы решали конкретную проблему мониторинга CronJob, запущенных в Kubernetes.

Инфраструктура мониторинга
Чтобы сделать наш кейс более понятным, стоит немного рассказать про то, как устроен мониторинг в целом. В этой статье под мониторингом понимаются сбор метрик и алертинг.
Сейчас мы в Ozon используем связку Prometheus-Thanos-Grafana. В общем случае мониторинг у нас представляет собой pull-модель, состоящую из большого количества Prometheus c поднятыми рядом Thanos Sidecar.
Prometheus сгруппированы по своему назначению:
- для микросервисов;
- для инфраструктуры;
- для серверов.
В платформе большинство метрик стандартизированы, они выдаются по определённому порту и адресу. С некоторым интервалом Prometheus приходит за метриками, затем осуществляется подсчёт агрегаций и алертов.
Prometheus не рассчитан на длительное хранение метрик. Он складывает метрики на диск, а Thanos Sidecar в свою очередь доставляет их в long-term-хранилище. Дальше Thanos и его модули отвечают за долгосрочное хранение метрик, а также предоставляют единую точку входа для их чтения и просмотра.
В Grafana мы настроили некоторое количество базовых дашбордов, в которых разработчику достаточно выбрать свой сервис из выпадающего списка — и он получит исчерпывающую информацию о нём.
Все микросервисы создаются в рамках нашей конвенции разработки и имеют набор стандартных метрик. Эти стандартные метрики позволяют сервисам из коробки иметь базовые инструменты мониторинга: базовые алерты, базовые дашборды в Grafana. Если командам не хватает базовых алертов или дашбордов, они всегда могут создать свои.
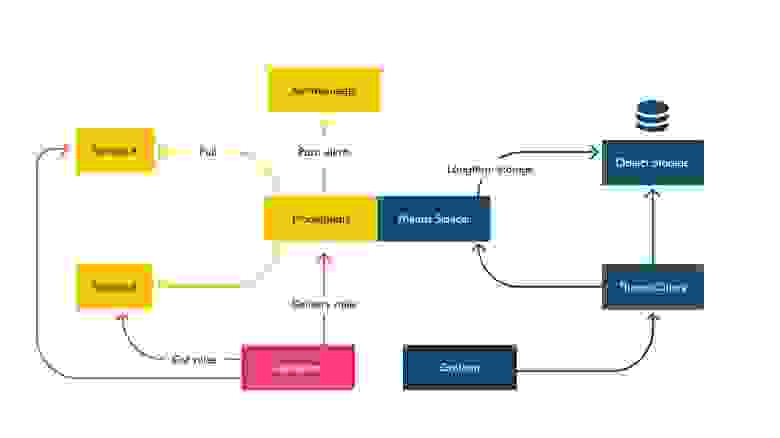
Упрощённая схема мониторинга
В редких случаях, когда требовалось отправлять метрики и сбор непосредственно с источника по pull-модели был невозможен, команды поднимали под свои нужны преднастроенный Prometheus Pushgateway, c которого мы потом забирали метрики.
Как можно понять из вышесказанного, вся наша инфраструктура сбора метрик и алертинга предназначена для существующих длительное время объектов. Однако по своей сути CronJob очень отличается от сервиса. СronJob — это повторяющаяся и работающая короткое время задача. Именно это и делает мониторинг кронов проблематичным: нельзя собрать с них метрики тем же способом, что с сервиса.
Почему для нас это актуально?
Сейчас в Ozon очень много CronJob (в основном написанных на Go и С#), которые используют множество технологий и отвечают за разные задачи. Большинство разработчиков хотели знать состояние кронов в случаях:
- когда задача не запустилась;
- когда задача упала;
- когда задача работает слишком долго.
Продуктовые команды в дополнение к этому хотели писать свои метрики и получать по ним алерты.
В итоге задача звучала так: организовать мониторинг CronJob с минимальным влиянием на разработчиков и джобы.
Для себя мы разделили задачу на несколько этапов:
- Подготовить базовые алерты, доступные для любых кронов (вне зависимости от языка программирования), запущенных в Kubernetes.
- Организовать сбор и доставку кастомных метрик для Go.
- Предоставить возможность создания алертов по кастомным метрикам.
Распределение языков программирования, используемых в СronJob в Ozon
kube-state-metrics
Для организации базовых алертов мы решили дистанцироваться от содержания CronJob. Для этого мы стали использовать те данные, которые предоставляет о них сам Kubernetes. Для этого у нас используется kube-state-metrics (KSM). KSM — это сервис, который слушает Kubernetes API и генерирует метрики о состоянии объектов. В нашем случае нас интересовали метрики для CronJobs, Jobs и Pods. В результате мы написали набор базовых алертов.
Агрегации, на основе которых написаны алерты, представлены ниже:
Кронджоба зафейлилась. Алерт базируется на комбинации метрик kube_job_status_start_time (джоба начала свою работу) и kube_job_failed{conditon=«true»} (джоба зафейлилась). Агрегация, которая лежит в основе алерта:
expr: | # for excluding old cronJobs in alert ((time() - kube_job_status_start_time{}) / 60 ) * on (job_name, namespace) # get failed job (kube_job_failed{condition="true"} > 0 unless kube_job_failed{condition="true"} offset 2m > 0)Крон не запустился. Алерт базируется на метрике kube_cronjob_status_last_schedule_time (когда крон был запущен последний раз):
expr: "(time()-kube_cronjob_status_last_schedule_time{}) / 60"Долгое время работы крона. Алерт базируется на метриках kube_job_status_start_time и kube_job_status_active (крон работает в данный момент):
expr: "(((time() - kube_job_status_start_time{}) / 60) * on (job_name, namespace) kube_job_status_active{} != 0)"
Все агрегации затем сравниваются с порогами, которые разработчики выставляют сами для своих кронов.
Особенностью написания алертов по метрикам является то, что Kubernetes в общем виде работает с джобами, а кронджоба — это настройка расписания запусков, политика рестартов, политика времени работы. И многие метрики существуют до тех пор, пока существует объект в Kubernetes: если задача когда-то давно зафейлилась, но при этом до сих пор существует pod, то метрика kube_job_failed{conditon=«true»} будет существовать всё это время. Данный аспект делает необходимым отсечение заведомо старых джоб от последних запущенных в выражениях. В результате многие алерты разрастаются и становятся трудночитаемыми.
Сбор кастомных метрик
На первый взгляд задача по сбору кастомных метрик с кронджоб является довольно простой, но стоит помнить о масштабах уже существующей инфраструктуры. Новый функционал должен вписываться в концепцию развёрнутой системы мониторинга.
Для начала надо определиться, по какой модели мы будем собирать метрики: push или pull.
Pull-модель
Кроны будут отдавать метрики, как обычные сервисы, по пути /metrcis и ждать, пока Prometheus придёт и заберёт метрику.
Плюсы:
- не требуются новые компоненты в инфраструктуре;
- возможность контролировать количество собираемых метрик.
Минусы:
- кронджобе нужно работать в режиме веб-сервера;
- Prometheus может не прийти за метриками;
- джобе придётся бездействовать, пока Prometheus не заберёт метрики;
- если просто отдавать метрики, то последние изменения потеряются;
- минимальный период работы кронджобы зависит от инфраструктуры мониторинга, а именно от частоты скрейпов.

Pull-модель
Push-модель
Кронджоба отправляет метрики в Thanos Receive / Prometheus Pushgateway. Мы предоставляем либу, которая в фоновом режиме отправляет метрики.
Плюсы:
- кронджоба никак не зависит от систем мониторинга;
- разработчикам требуется только подключить и инициализировать библиотеку.
Минусы:
- каждая джоба должна знать endpoint для отправки метрик. Для этого придётся в явном виде прописывать точку в библиотеке или сообщать подам с кронами (например, с помощью Kubernetes Admission Controller), куда им пушить;
- необходимость поддержки нового компонента (Thanos Receive / Prometheus Pushgateway);
- в случае общего компонента мы не можем контролировать качество и количество метрик без дополнительного прокси;
- библиотеки сложно обновлять в большом количестве CronJobs.
Стоит отметить, что к моменту перехода мониторинга в стадию тестирования в Prometheus версии 2.25.0 появился новый флаг, который позволяет включать экспериментальную функциональность, в частности возможность обрабатывать запросы remote_write (пушить в Prometheus). Но поскольку в дальнейшем эта опция может быть удалена, мы не стали рассматривать данный вариант.
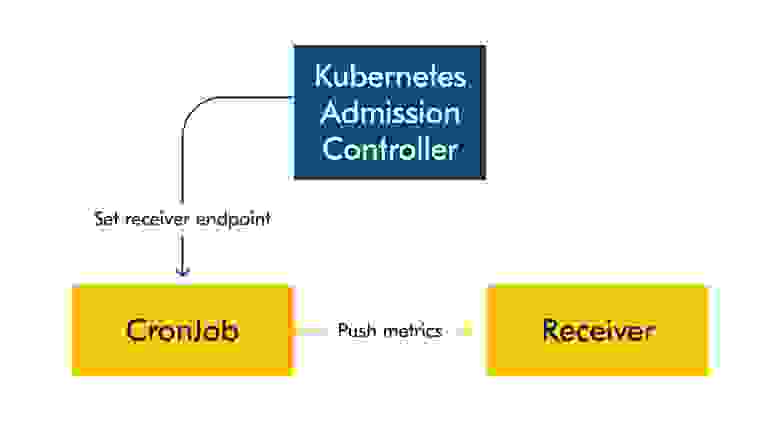
Push-модель
Мы выбрали push-модель, так как нам было важно сохранить независимость кронджоб от систем мониторинга. Нестабильность инфраструктуры мониторинга не должна влиять на работу других систем. Если принимающий метрики сервис недоступен, то крон продолжит свою работу по расписанию.
С моделью мы разобрались. Но реализовывать её можно двумя разными способами.
Prometheus Pushgateway
По своей сути Pushgateway — это некий мост между push- и pull-моделями. Кронджоба будет пушить в гейтвей, а Prometheus затем заберёт из него метрики.
Но возникает вопрос удаления метрик. Метрика, отправленная в Pushgateway, существует в нём, пока не будет в явном виде удалена или перезаписана.
Удаление по таймеру не подходит: у нас огромное количество кронов, все они разные, и мы не можем предположить, когда тот или иной крон остановится.
Внедрение управляющего сигнала с крона не подходит. Мы не можем обновить или удалить метрику, если её не успел забрать Prometheus, — в этом случае мы просто все полученные метрики выбрасываем. Да и патчить Pushgateway или ставить проксю не хотелось, чтобы не плодить новые сервисы, которые надо будет поддерживать.
Thanos Receive
Thanos Receive является полноценным модулем Thanos. Он реализует Prometheus Remote Write API и построен поверх базы Prometheus TSDB, добавляя функциональные возможности за счёт длительного хранения и горизонтальной масштабируемости.
Фактически внутри Thanos Receive реализован инстанс Prometheus, который настроен на непрерывную запись. Он пишет метрики в TSDB-блоки на диск, а затем ресивер (shipper) загружает TSDB-блоки в Object Storage каждые два часа по умолчанию.
Thanos Receive предоставляет StoreAPI, благодаря чему Thanos Query может запрашивать метрики в реальном времени.
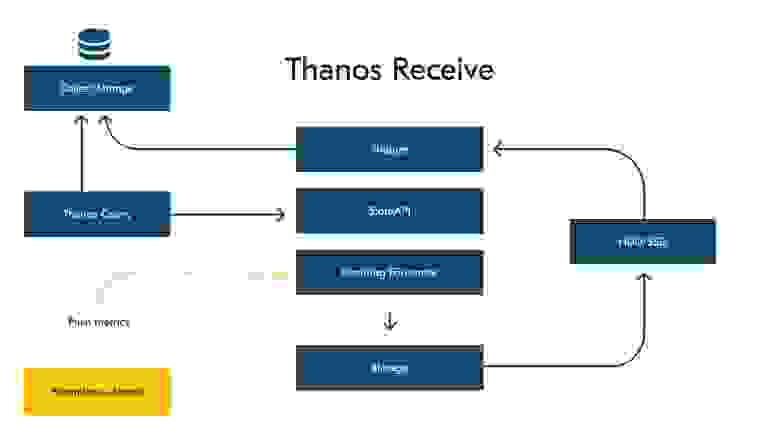
Упрощённая схема Thanos Receive
В отличие от варианта с использованием Pushgateway, большим плюсом ресивера является то, что мы отправляем метрики и нам не надо следить за ними: удалять или специальным образом обновлять.
Как мы организовали сбор кастомных метрик и алертинг
Мы выбрали полноценную push-модель на основе Thanos Receive. В итоге мы написали небольшую библиотеку для Go, которая отправляет метрики в фоновом режиме раз в 15 секунд и перед завершением работы крона.
Под капотом библиотеки запускается тикер. На каждый тик запрашиваются метрики у prometheus.Gatherer, который в свою очередь запрашивает все метрики у коллекторов и отдаёт их в виде лексикографически отсортированного слайса. Если возникает ошибка, то Gatherer пытается собрать столько метрик, сколько может.
Однако Prometheus работает с метриками типа dto.MetricFamily, а remote write API принимает prompb.WriteRequest. Поэтому нам пришлось написать некий мост: из полученных от Gatherer метрик формируем реквест с нужным типом данных, который и отправляем на ресивер.
Bridge
Библиотека обогащает метрики служебными лейблами, чтобы определять, кому они принадлежат, и избегать конфликта наименований:
- окружение;
- неймспейс;
- имя пода;
- имя крона;
- имя джобы.
Также она предоставляет определённый набор готовых для использования метрик:
- когда крон стартанул;
- статус работы крона с точки зрения бизнес-логики (успешно или нет).
// Pusher push to receiver endpoint using prometheus remote write
type Pusher interface {
Push(context.Context, prompb.WriteRequest) error
}// Bridge pushes metrics to the configured receiver.
type Bridge struct {
interval time.Duration
timeout time.Duration
pusher Pusher
g prometheus.Gatherer
additionalLabels map[model.LabelName]model.LabelValue
}
func (b *Bridge) getWriteRequest() (*prompb.WriteRequest, error) {
// запрашиваем метрики через prometheus.Gatherer
mfs, err := b.g.Gather()
if err != nil {
return nil, fmt.Errorf("could not gather metrics: %w", err)
}
vec, err := expfmt.ExtractSamples(
&expfmt.DecodeOptions{
Timestamp: model.Now(),
}, mfs...)
if err != nil {
return nil, fmt.Errorf("could not extract samples: %w", err)
}
timeseriesList := make([]prompb.TimeSeries, 0)
t := timestamp.FromTime(time.Now())
// формируем массив из таймсерий
for _, v := range vec {
// добавляем необходимые служебные лейблы
newLabels, err := b.addAdditionalLabels(v.Metric)
if err != nil {
logger.Errorf(context.Background(), "could not add additional labels: %s", err.Error())
continue
}
ts := prompb.TimeSeries{
Labels: getLabelsAsStruct(newLabels),
Samples: []prompb.Sample{
prompb.Sample{
Value: float64(v.Value),
Timestamp: t,
},
},
}
timeseriesList = append(timeseriesList, ts)
}
// формируем конечные данные для отправки
req := prompb.WriteRequest{
Timeseries: timeseriesList,
Metadata: getMetadatas(mfs),
}
return &req, nil
}
Разработчикам, со своей стороны, достаточно инициализировать пакет в main.go:
// main.go
func main() {
// init cronjob
closer, err := cronjob.Init()
if err != nil {
fmt.Println(err.Error())
}
defer closer.Close()
...
}Способ регистрации метрик и их использование никак не отличаются от сервисов:
labels := map[string]string{
"example_lable": "my_label",
}
newCounter := prometheus.NewCounter(
prometheus.CounterOpts{
Namespace: NS,
Name: "example_counter",
Help: "number of responses from hello handler",
ConstLabels: labels,
},
)
prometheus.DefaultRegisterer.MustRegister(newCounter)
do.Smth()
newCounter.Inc()
Endpoint ресивера проставляем в env-переменную пода через Admission Controller. Admission Controller проверяет поды при создании или изменении и, если под относится к кронджобе, проставляет receiver endpoint.
Данный подход позволяет нам в любой момент изменить endpoint без участия разработчиков, не требуется редеплой кронджобы. При новом запуске крона у пода будет уже новый адрес.
Кронджоба пушит метрики в ресивер, далее ресивер доставляет метрики в Object Storage.
Но теперь у нас все метрики минуют Prometheus, где мы до этого считали алерты. Поэтому мы подняли Thanos Rule. Но стоит помнить о том, что Thanos Rule зависит от доступности и работоспособности Thanos Query, который, в свою очередь, запрашивает данные из Store APIs.
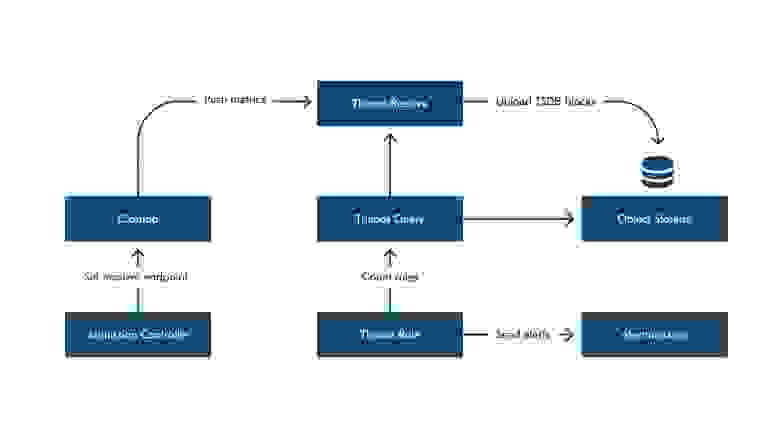
Упрощённая итоговая схема мониторинга CronJob
Мониторили, мониторили да вымониторили
В итоге мы реализовали инфраструктуру мониторинга CronJob следующим образом:
- на основе kube-state-metrics написали набор алертов, доступных для всех CronJobs;
- предоставили библиотеку на Go, которая позволяет отправлять кастомные метрики в Thanos Receive;
- подняли Thanos Rule для алертинга по кастомным метрикам.
C момента ввода в эксплуатацию прошло четыре месяца, в течение которых нашу систему мониторинга стали использовать на проде (игрушечные кластеры не учитываю) более чем для 200 кронджоб. 150 кронджоб используют базовые алерты, 125 кронов отправляют метрики. Команды написали более 50 кастомных алертов. Суммарно на проде было получено свыше 100 базовых алертов.
Стоит отметить, что Thanos Rule используется далеко за пределами мониторинга CronJob. Этот модуль позволил реализовать алерты, которые считаются за большой промежуток времени (несколько дней или недель).
