Dive into Centrifugo
 В предыдущей статье о Центрифуге я рассказывал, что сервер был переписан с Python на Go (код Centrifugo на github, описание на opensource.mail.ru). C тех пор прошло несколько месяцев, за это время Центрифуга успела получить версию 1.0.0 и даже уйти немного дальше (последняя версия на момент этого поста — 1.4.2).
В предыдущей статье о Центрифуге я рассказывал, что сервер был переписан с Python на Go (код Centrifugo на github, описание на opensource.mail.ru). C тех пор прошло несколько месяцев, за это время Центрифуга успела получить версию 1.0.0 и даже уйти немного дальше (последняя версия на момент этого поста — 1.4.2).
В этой статье нас ждет быстрый старт работы с Центрифугой, примеры реального использования, размышления о месте и предназначении Центрифуги в реалиях 2016 года, описание некоторых архитектурных особенностей/возможностей реал-тайм-сервера и примеры кода на Go, отвечающие за реализацию главных фич. Welcome aboard!
Напомню, что такое Центрифуга. Это сервер, который работает рядом с бэкендом вашего приложения. Пользователи приложения подключаются к Центрифуге, используя протокол Websocket или полифил-библиотеку SockJS. Подключившись и авторизовавшись с помощью HMAC-токена (полученного с бэкенда приложения), они подписываются на интересующие каналы. Бэкенд приложения, узнав о новом событии, отправляет его в нужный канал в Центрифугу, используя HTTP API или очередь в Redis. Центрифуга, в свою очередь, рассылает сообщение всем подключенным заинтересованным пользователям. Ничего принципиально нового: достаточно много продуктов предназначены для решения реал-тайм-задач, некоторые из них работают по похожей схеме.
Если вы слышали о сервисе pusher.com — то в некотором приближении можно рассматривать Centrifugo как self-hosted аналог.

То есть концептуально ничего не поменялось. Давайте посмотрим подробнее, как Центрифуга устроена и как решаются некоторые сопутствующие проблемы. Но начнем с того, как внутреннее устройство сервера преподнесено пользователям-разработчикам снаружи.
Покажем на быстром примере, как воспользоваться Центрифугой для прототипирования простой real-time-идеи. В реальном production-случае всё чуть сложнее и, например, потребует генерации параметров подключения на стороне бэкенда вашего приложения, но сейчас мы будем отключать всевозможные проверки, чтобы обойтись без бэкенда. Это позволит поскорей получить рабочий вариант и понять основное предназначение Центрифуги.
Задача будет простая: пользователь заходит на страничку в браузере и видит картинку. C помощью JavaScript-клиента Центрифуги мы подпишемся на канал screen-updates в Центрифуге и будем ждать входящих сообщений из него. Далее мы из административного веб-интерфейса Центрифуги будем отправлять (публиковать) в этот канал сообщения вида:
{
"image": "https://habrastorage.org/files/6b3/ae5/fcb/6b3ae5fcbeaf49c480baca60f88e7d40.jpg"
}
где image — это url картинки.
При получении этого сообщения у всех пользователей картинка автоматически изменится на ту, что мы прислали в сообщении.
Скачиваем последний релиз Центрифуги для вашей операционной системы отсюда. На момент написания статьи это версия 1.4.2. Распаковываем zip-архив и запускаем бинарный исполняемый файл:
CENTRIFUGO_SECRET=secret ./centrifugo --insecure --insecure_admin --web
Открываем http://localhost:8000 и видим веб-интерфейс, из которого будем отправлять сообщения клиентам с помощью формы во вкладке Actions.
Кстати, установить Centrifugo можно и иным способом. Например, использовать Docker image или скачать RPM/DEB-пакет с packagecloud.io.
Создадим в новой директории файл `index.html` с содержимым:


После этого мы можем запустить HTTP-сервер, отдающий эту HTML-страничку:
python -m SimpleHTTPServer 3000
и открыть несколько вкладок с адресом http://localhost:3000 в браузере.
Во вкладке Actions административного веб-интерфейса Центрифуги мы можем написать имя канала screen-updates в поле channel, JSON указанного выше вида в поле data и опубликовать его в канал. Вот такой, например:
{
"image": "https://habrastorage.org/files/6b3/ae5/fcb/6b3ae5fcbeaf49c480baca60f88e7d40.jpg"
}
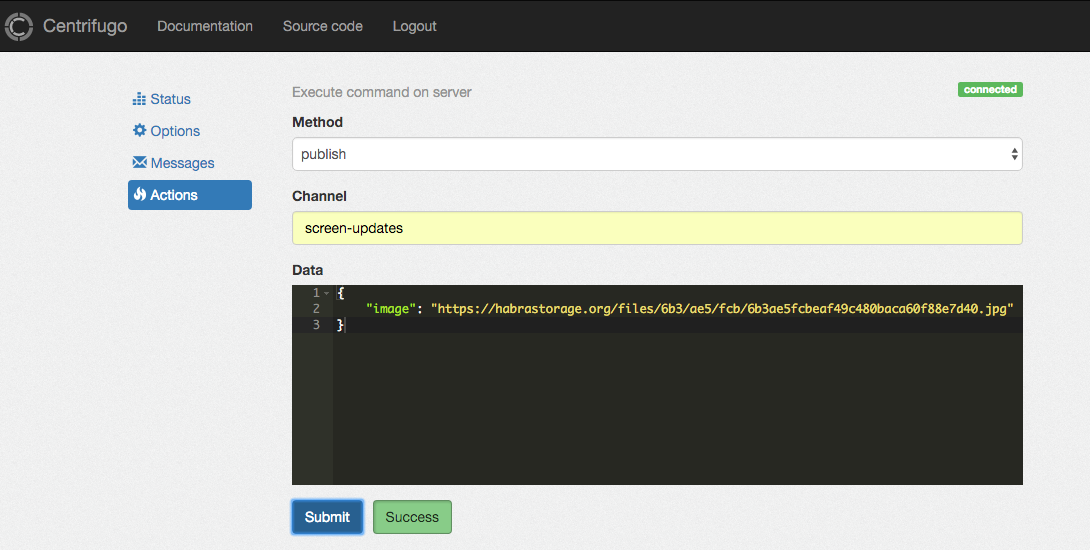
На всех открытых страницах картинка сменится на только что отправленную. Вот готовый пример на codepen, использующий демоинстанс Centrifugo на Heroku:

Это чуть более симпатичная версия примера выше. Можете пройти демоинстанс на Heroku (пароль для входа: demo) и из вкладки Actions отправлять сообщения в канал screen-updates, наблюдая результат в окнах codepen. В этом случае ничего не придется устанавливать, чтобы получить общее представление.
Это был быстрый старт, и результат достаточно примитивен. Но представьте, какие возможности открываются, как только вы перенесете это на реалии живого веб-приложения — они ограничены только фантазией. В реальном проекте новые сообщения вы будете отправлять не вручную из интерфейса, а с помощью API Центрифуги и библиотек-клиентов для этого API. Также, скорее всего, не будут использоваться insecure флаги и параметры, которые вы могли наблюдать выше. Полное описание всех возможностей вы найдете в документации.
Как я уже говорил, у нас в Mail.Ru Group Центрифуга используется в интранете (внутренней социальной сети для сотрудников компании) — для лайков, комментариев, статуса занятости переговорных, результатов голосования и другого. Cейчас у нас 700 пользователей онлайн одновременно и публикуется около 300 новых сообщений в минуту. Это, конечно, совсем мало. Потребление CPU — в среднем около 1%, памяти — около 200 Мб. Бывают случаи (например, после корпоративных рассылок), когда количество опубликованных сообщений достигает 2 тыс. в минуту, а fan-out (то есть количество разосланных в соединения пользователей) достигает 300 тыс. сообщений в минуту. Опять же, ничего фантастического. Вот как раз такой случай можно увидеть на графике ниже:
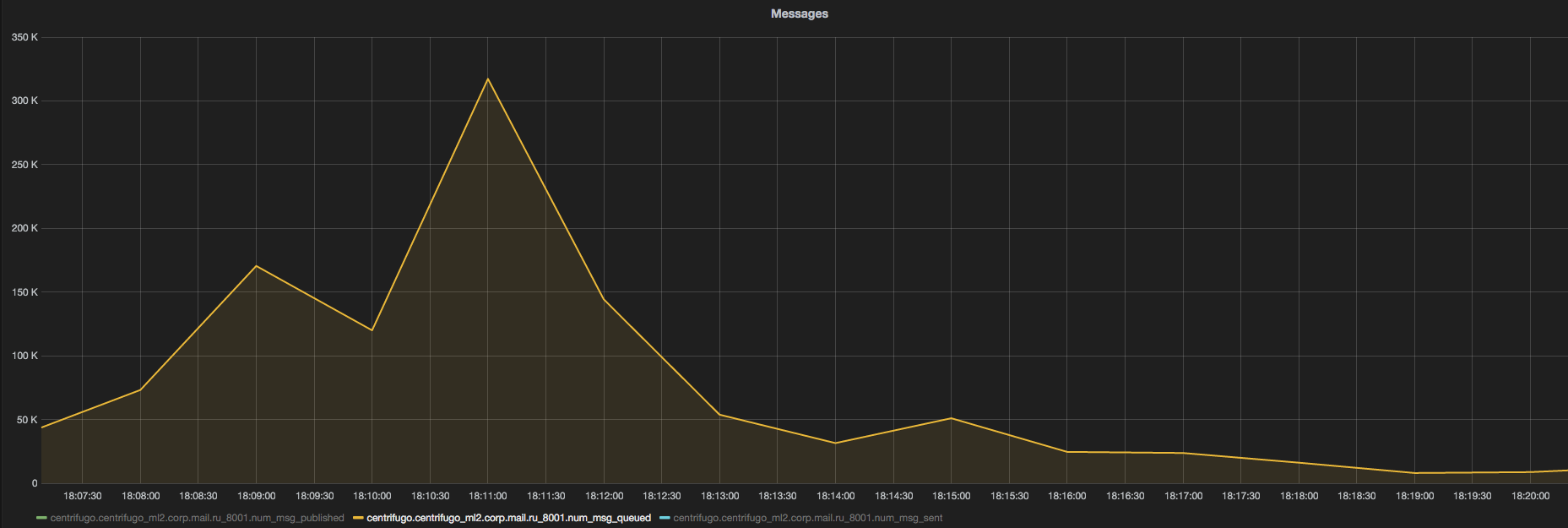
К сожалению, в данный момент правильно сделанных бенчмарков Центрифуги нет, поэтому приходится оперировать цифрами из реальных проектов — в нашем случае нагрузка на Centrifugo незначительная.
Есть в Mail.Ru Group и еще несколько интересных применений Центрифуги, о которых хотелось бы рассказать.
Во-первых, это игра для сотрудников. Игроки собираются вместе в одном помещении, нажатием кнопки делятся на команды. Далее, как только команды рассаживаются за столы, начинается сама игра. Игроки заходят на сайт со своих мобильных устройств — смартфонов, планшетов, ноутбуков, — получают при помощи пуш-сообщений вопросы и отвечают на них. При этом на большом экране (телевизор, изображение с проектора) возникает статистика игры, а ведущий со своего устройства управляет игрой: переводит ее от раунда к раунду, рассылая игрокам новые вопросы и потом правильные ответы на них. Если вы слышали о The Jackbox Party Games, то это что-то похожее.
Мой коллега сейчас работает над проектом https://drawr.ru. Это кооперативная реал-тайм-игра, в которой люди могут весело провести время, рисуя и угадывая то, что изображено на рисунках других. Игра по своей внутренней архитектуре во многом напоминает ту, что я описывал в предыдущем абзаце, — Django + Centrifugo под капотом. Центрифуга отвечает за рассылку уведомлений об изменении игрового состояния пользователям и за внутриигровой чат. Попробовать можно прямо сейчас, но нужно найти с кем: минимальное количество игроков — три.
Далее, в нашем большом офисе Mail.Ru очень много дверей. Двери открываются после прикладывания пропуска к устройству-считывателю. Это позволило сделать несколько интересных вещей. Например, так называемый exit-poll — сотрудник входит в помещение и отвечает на вопрос, который моментально появляется на экране перед ним. Таким ненавязчивым образом сотрудники нашего отдела персонала могут собирать самую разнообразную статистику и мнения сотрудников по тем или иным вопросам. Интерфейс на экране — это просто вкладка браузера, подписанная на канал в Центрифуге, через который приходят данные о проходах через дверь.
Наши администраторы из техподдержки при входе сотрудника, используя примерно ту же схему, показывают на большом экране информацию о человеке и таск в Jira, с которым он к ним заглянул: экономит несколько секунд при дальнейшем общении.
Один из разработчиков сайта из Alexa TOP 250 (если очень интересно, какого именно сайта, — почитайте чат Centrifugo на gitter.com) в тестовом режиме запустил Центрифугу на 50 тыс. пользователей онлайн. При этом публикуется 6 тыс. новых сообщений в секунду (это именно новые, а не fan-out сообщения). Для балансировки клиентов использовались два m4.xlarge инстанса c Центрифугой на Amazon«е. Этот пример доказывает, что подавляющему большинству проектов производительности Центрифуги должно хватить с головой.
В примере выше мы использовали пуш клиентам со стороны сервера. Центрифуга позволяет публиковать новые сообщения напрямую с клиента в обход бэкенда приложения, но всё же ее основное применение — именно server-side only push: отправка сообщений, инициируемая сервером в одном направлении — от сервера клиенту.
Такой однонаправленной схемы достаточно для решения реал-тайм-задач в большинстве приложений, возможно, кроме динамичных мультиплеерных игр и подобных, требующих максимально низкого времени отклика и более тесной интеграции бэкенда и реал-тайм-ядра.
Большинство современных приложений в основном read-only, новый контент создается редко, поэтому любой бэкенд должен без проблем справиться с новыми событиями, которые генерируют пользователи приложения. Например, если пользователь добавил комментарий в веб-приложении, то вы просто отправляете его HTTP POST-запросом (обычным или AJAX) — обрабатываете, валидируете, сохраняете в базу данных, —, а потом рассылаете всем. Для этого совсем не нужно организовывать общение между пользователем и сервером через двустороннее соединение, что предоставляют веб-сокеты. Meteor — и Derby-подобные фреймворки по-своему прекрасны —, но они не единственные инструменты для простой реализации реал-тайм-приложений.
Значимое преимущество Центрифуги: используя ее, вы никак не меняете способ генерации новых событий в вашем приложении. Это особенно критично, если бэкенд приложения написан на языке или фреймворке, не поддерживающем работу с большим количеством постоянных соединений (PHP и множество фреймворков на нем, Django и т. д.).
Еще раз подчеркну основную мысль, которую я пытаюсь озвучить: в большинстве случаев нам не нужно двунаправленное взаимодействие между клиентом и сервером через постоянное соединение. Все, что нужно, — это способ быстро доставлять пользователям новый контент, как только бэкенд приложения узнаёт о его появлении.
Недавно фреймворк Django получил MOSS Grant. Cудя по этой новости, скоро нас (пользователей Django) ждет принятие в ядро фреймворка проекта Channels. Это превратит Джанго в набор воркеров, которые посредством каналов будут общаться с так называемыми интерфейс-серверами через брокер. Интерфейс-сервер может обслуживать запросы клиентов по самым разным протоколам — HTTP, Websocket и т. д. Концепт очень красивый и интересный, и среди фич, которые станут возможны, — двунаправленное общение клиента и бэкенда на Джанго через веб-сокеты. За него будут отвечать специальные Websocket интерфейс-серверы. Однако вместе с этим появляются проблемы, когда события приходят в разном порядке на разные воркеры Джанго, — понадобится синхронизировать их, используя локи в брокере (один из возможных брокеров — Redis). К чему в итоге приведут нововведения на практике — непонятно, но появление локов в отдельном брокере — как минимум спорное решение. Благодаря этому Джанго займет дополнительную нишу на рынке фреймворков и реал-тайм-решений, но хорошо ли это с учетом вышесказанного — посмотрим.
Django — не единственный пример. Я не большой знаток того, что происходит в мире Ruby on Rails, но, судя по этой статье, «рельсы» также в скором времени получат (уже получили?) поддержку двунаправленного общения с пользователем через веб-сокеты, и некоторых разработчиков это справедливо настораживает.
Самое забавное: как только интернет практически полностью перебрался на браузеры с поддержкой веб-сокетов (ведь мы так этого ждали, правда?) — появляются сомнения, насколько вообще хороши Websocket«ы для веба в эру появления HTTP/2. Каждый открытый в браузере таб — это новое постоянное соединение клиента с сервером. Зачем избыточность, если HTTP/2 позволяет мультиплексировать все запросы к домену в разных табах браузера через одно соединение? Уже сейчас при соединении клиента и сервера по HTTP/2 пропадает ограничение спецификации HTTP/1.1 на количество открытых до одного домена соединений. Можно открыть большое количество вкладок браузера, каждая из которых использует Eventsource или XHR-Streaming для доставки сообщений пользователю, и не упереться в лимит (обычно пять-шесть, в зависимости от браузера).
При всем при этом нельзя не отметить, что Websocket как протокол очень даже хорош и, что немаловажно, позволяет соединяться с сервером из небраузерной среды: клиенты для веб-сокетов есть практически для всех языков программирования. Озвученный недостаток (использование отдельных соединений при открытии вкладок) в основном касается только веб-сайтов, но есть и другие приложения — десктопные, мобильные. Очень жаль, что так и не довели до ума драфт о мультиплексировании веб-сокетов через HTTP/2 соединение: видимо, на то были веские причины, я их не знаю — может, у кого-то есть догадки?
К сожалению, сейчас, в начале 2016 года, у нас нет идеального транспорта для реал-тайм-общения. Так или иначе у всех существующих есть ряд преимуществ и недостатков. Как и во многих вещах в программировании, выбор транспорта — это trade-off. Будем ждать новых возможностей, особенно с учетом спецификации PUSH PROMISE фреймов в HTTP/2 (вот, например, рабочий драфт по доставке нотификаций (онлайн и офлайн) в браузеры на основе PUSH PROMISE, реализация должна в скором времени появиться в Firefox, а потом и в остальных браузерах). Возможно, и Центрифуга в каком-то будущем станет поддерживать этот драфт, чтобы отправлять офлайн пуш-сообщения пользователям сайтов.
Так или иначе Центрифуга позволяет забыть о головной боли с транспортами и доставлять реал-тайм-сообщения клиентам, даже если бэкенд вашего приложения для этого изначально не подходит (или пока не подходит — Rails, Django из примеров выше). При этом не нужно менять ни код, ни философию работающего проекта — можно и дальше использовать любимый фреймворк и возложить ответственность за поддержание постоянных соединений и рассылку реал-тайм-сообщений на Centrifugo. Даже если вы пишете приложение на Go или Node.js — вы можете сосредоточиться на ядре и основной функциональности приложения, используя Центрифугу для реал-тайм-сообщений. Позже при желании вы легко откажетесь от нее в пользу собственного интегрированного в код проекта решения (напишете обработку постоянных соединений самостоятельно, перейдете, например, на Primus в случае с Node.js). В качестве транспорта, как я уже упоминал выше, можно использовать «чистые» веб-сокеты или все доступные транспорты SockJS. В ближайшем будущем Центрифуга научится общаться с клиентами по HTTP/2 — благодаря реализации HTTP/2, встроенной в стандартную библиотеку Go 1.6. Это положительно скажется на соединениях, использующих SockJS HTTP-транспорты (eventsource, xhr-streaming и др.).
Не стоит забывать о быстром примере real-time-приложения, который мы реализовали выше: можно без бэкенда (и с бэкендом) прототипировать реал-тайм-приложение — для этого есть готовый JavaScript-клиент и сервер в виде бинарного файла без зависимостей. На мой немного предвзятый взгляд — это одно из самых удобных и быстрых для старта решений.
Интересную модель можно получить, если использовать Центрифугу в связке с RethinkDB на бэкенде: подписавшись на changefeed документов, вы можете делать приложения, где требуется синхронизировать структуру данных между сервером и бэкендом, — а-ля Firebase.
Теперь о том, что внутри. В предыдущих статьях я много писал о возможностях Центрифуги, но мало о том, каким образом все это работает. Многое видоизменялось при эволюции проекта, в том числе и язык (Python → Go). Сейчас используемые подходы и инструменты достаточно стабильны. Поэтому, кажется, cамое время рассказать о внутреннем устройстве сервера.
HTTP/Websocket-сервер
В простом приближении Centrifugo — это Websocket/HTTP-сервер. На отдельном порту поднимается стандартный Go HTTP server c зарегистрированными функциями — обработчиками запросов. Обработчики можно разделить на три категории:
- Клиентские соединения (Websocket или SockJS).
- HTTP API (публикация сообщений, выгрузка метрик и т. д.).
- Административные ресурсы, необходимые в том числе для работы веб-интерфейса.
Клиентские соединения — это не короткие stateless HTTP-запросы, а постоянные соединения. В случае с Websocket-соединениями и HTTP streaming-транспортами (xhr-streaming, eventsource), которые используют SockJS при недоступности веб-сокетов, все достаточно понятно. После установления соединения мы не закрываем его до тех пор, пока клиент онлайн (на самом деле это не совсем верно, так как в случае со streaming-транспортами иногда все же приходится сбрасывать клиентское соединение, чтобы Garbage Collector мог подчистить разросшееся до определенного размера тело ответа). Благо Go позволяет практически беззаботно работать с огромным количеством таких соединений. Есть небольшая проблема с polling-транспортами, например xhr-polling (он же long-polling), так как при отправке сообщения соединения с клиентами рвутся и переустанавливаются заново. Нужно хранить сессию клиента еще некоторое время, достаточное для реконнекта. Это берет на себя серверная реализация SockJS. А клиенту, в свою очередь, желательно реконнектиться к тому же самому инстансу сервера (это берет на себя балансер — например, sticky-сессии в Nginx).
Об HTTP API. Хотите опубликовать новое сообщение в канал — отправьте правильно сформированный POST-запрос на url `/api/`. Хотелось бы отметить, что каждый API-запрос по умолчанию должен быть подписан секретным ключом, который знают только Центрифуга и ваш бэкенд. В большинстве случаев эту дополнительную защиту можно отключить, так как запросы в API наверняка будут отправляться с определенного IP — так что правил firewall«a в production вполне достаточно. В таком случае запрос к API — это просто POST-запрос с JSON«ом, содержащим команды. Примерно такого вида:
{
"method”: "publish”,
"params”: {
"channel”: "updates”,
"data”: {
"text”: "hello world”
}
}
}
Касаемо административного веб-интерфейса — это endpoint, позволяющий залогиниться по паролю, хендлер, который раздает статические файлы административного веб-интерфейса и websocket endpoint, через который веб-интерфейс в реальном времени получает сообщения, опубликованные в тот или иной канал (опционально), а также исполняет команды (например, публикует сообщение в канал — то что мы видели в примере выше).
Engine
Пожалуй, самое интересное под капотом Центрифуги сосредоточено в так называемых Engine«ах.
Однако прежде чем приступить к описанию работы встроенных Engine«ов, давайте посмотрим на особенности Центрифуги, которые так или иначе завязаны на Engine:
- возможность запустить несколько инстансов Центрифуги на разных машинах, чтобы балансировать клиентские соединения между ними;
- presence-информация — то есть информация о том, какие клиенты находятся в данный момент в канале;
- history-информация — последние сообщения, отправленные в канал.
Первая особенность выливается в проблему: клиенты, подписанные на один и тот же канал, могут быть подключены к разным инстансам, поэтому при публикации сообщения в канал оно должно быть доставлено и тому и другому клиенту. Примерно то же самое для presence и history: каждый инстанс Центрифуги должен обладать доступом к полной информации о канале, чтобы предоставить ее клиенту в случае запроса.
Добавим к этому замечание, что Центрифуга не хранит ничего в постоянном хранилище. В случае с presence-информацией это не проблема: мы храним столько данных, сколько сейчас пользователей в каналах. А вот в случае с историей сообщений место в памяти исчерпалось бы достаточно быстро — поэтому Центрифуга хранит историю ограниченного размера и ограниченное время (конфигурируется разработчиком на глобальном уровне или на уровне отдельных каналов) — для реал-тайм-нужд этого более чем достаточно.
На данный момент, чтобы удовлетворять требованиям, Engine должен имплементировать вот такой Go-интерфейс:
type Engine interface {
name() string
run() error
publish(chID ChannelID, msg []byte, opts *publishOpts) <-chan error
subscribe(chID ChannelID) error
unsubscribe(chID ChannelID) error
channels() ([]ChannelID, error)
addPresence(chID ChannelID, uid ConnID, info ClientInfo) error
removePresence(chID ChannelID, uid ConnID) error
presence(chID ChannelID) (map[ConnID]ClientInfo, error)
history(chID ChannelID, opts historyOpts) ([]Message, error)
}
Полная версия в исходном коде по ссылке.
Этот интерфейс достаточно велик — это противоречит хорошей практике делать Go-интерфейсы небольшими. Однако этот интерфейс применяется только внутри Центрифуги, и его предназначение отличается от предназначения интерфейсов, которые разработчики используют в каждодневной практике. Не предполагается, что его будет использовать кто-либо извне. По сути, это единственный способ сделать поддержку нескольких разных движков в Go. У меня есть мысли, как сделать этот интерфейс чище —, но не меньше. Имена методов достаточно говорящие, чтобы понять, за что они отвечают, — далее мы посмотрим, как этот интерфейс реализуют доступные для использования Memory Engine и Redis Engine.
Memory Engine
В самом простом случае, при небольшой нагрузке или для разработки нам достаточно одного инстанса Центрифуги без каких-либо дополнительных зависимостей. Существует так называемый Memory engine, который реализует интерфейс, обозначенный выше, и работает по умолчанию.
В случае использования Memory Engine«а мы ограничены только одним инстансом Центрифуги. Presence и history хранятся в памяти процесса. Все клиенты соединены с одним инстансом Центрифуги — так что никаких проблем с доставкой опубликованных сообщений всем клиентам нет — они все у нас под боком.
Управлять presence-данными несложно: клиент появляется — добавляем в структуру данных, клиент уходит — удаляем из структуры.
Пожалуй, самое хитрое тут — это история в канале. Как я уже говорил, она должна храниться заданное время. Давайте посмотрим, как это реализовано в Memory Engine«е. Чтобы в примере не привязываться к внутренним типам Центрифуги, предположим, что в истории мы должны хранить сообщения типа string, которые принадлежат определенному каналу (тоже string).
type historyItem struct {
messages []string
expireAt int64
}
func (i historyItem) expired() bool {
return i.expireAt < time.Now().Unix()
}
type memoryHistoryHub struct {
sync.RWMutex
history map[string]historyItem
queue priority.Queue
nextCheck int64
}
func newMemoryHistoryHub() *memoryHistoryHub {
hub := &memoryHistoryHub{
history: make(map[string]historyItem),
queue: priority.MakeQueue(),
nextCheck: 0,
}
go hub.expire()
return hub
}
где queue — это priority queue прямиком из документации Go. Код этой очереди полностью можно посмотреть тут.
Это структура, позволяющая добавлять новые элементы с помощью метода Push и доставать элементы с минимальным значением с помощью метода Pop. Обе операции в этой реализации выполняются за O (log (n)).
Пожалуй, необходимость тянуть код priority queue в проект — единственная причина, по которой я пожалел об отсутствии generics в Go.
Давайте посмотрим на то, как в инициализированную структуру мы можем добавлять новые сообщения:
func (h *memoryHistoryHub) add(channel string, message string, size, lifetime int) error {
h.Lock()
defer h.Unlock()
_, ok := h.history[channel]
expireAt := time.Now().Unix() + int64(lifetime)
heap.Push(&h.queue, &priority.Item{Value: channel, Priority: expireAt})
if !ok {
h.history[channel] = historyItem{
messages: []string{message},
expireAt: expireAt,
}
} else {
messages := h.history[channel].messages
messages = append([]string{message}, messages...)
if len(messages) > size {
messages = messages[0:size]
}
h.history[channel] = historyItem{
messages: messages,
expireAt: expireAt,
}
}
if h.nextCheck == 0 || h.nextCheck > expireAt {
h.nextCheck = expireAt
}
return nil
}
Здесь мы добавляем в историю канала новое сообщение, при этом указываем такие параметры, как size и lifetime, — они отвечают за максимальное количество сообщений в истории и за время в секундах, которое история должна храниться, соответственно.
Метод, отвечающий за получение сообщений для канала из истории, выглядит вот так:
func (h *memoryHistoryHub) get(channel string) ([]string, error) {
h.RLock()
defer h.RUnlock()
hItem, ok := h.history[channel]
if !ok {
return []string{}, nil
}
if hItem.expired() {
delete(h.history, channel)
return []string{}, nil
}
return hItem.messages, nil
}
Наконец, завершающая часть реализации — функция expire, выполняющаяся в отдельной горутине и раз в секунду подчищающая неактуальные данные в структуре:
func (h *memoryHistoryHub) expire() {
var nextCheck int64
for {
time.Sleep(time.Second)
h.Lock()
if h.nextCheck == 0 || h.nextCheck > time.Now().Unix() {
h.Unlock()
continue
}
nextCheck = 0
for h.queue.Len() > 0 {
item := heap.Pop(&h.queue).(*priority.Item)
expireAt := item.Priority
if expireAt > time.Now().Unix() {
heap.Push(&h.queue, item)
nextCheck = expireAt
break
}
channel := item.Value
hItem, ok := h.history[channel]
if !ok {
continue
}
if hItem.expireAt <= expireAt {
delete(h.history, channel)
}
}
h.nextCheck = nextCheck
h.Unlock()
}
}
Обратите внимание, что чистка истории не делает лишней работы благодаря полю nextCheck — его значение соответствует моменту времени, когда чистка данных в структурах действительно становится нужна.
Таким образом мы можем добавлять сообщения в канал, забирать список последних сообщений из канала, при этом структура поддерживает размер истории в канале и в отдельной горутине подчищает неактуальные данные. Как я уже писал выше, в примере я использовал немного другие типы данных, чтобы упростить восприятие не самого короткого для статьи кода.
Redis Engine
Как несложно понять из названия — этот Engine работает, используя Redis в качестве брокера для сообщений и как хранилище для presence и history данных.
Запустить Центрифугу, используя этот движок, можно следующим образом:
centrifugo --config=config.json --engine=redis
У Redis Engine«а есть ряд преимуществ по сравнению с рассмотренным выше Memory Engine«ом:
- можно запустить инстансы (ноды) Центрифуги на разных машинах (будут связаны PUB/SUB механизмом Редиса), балансируя подключения клиентов между этими нодами;
- при перезапуске инстанса Центрифуги не теряется история сообщений в каналах;
- можно публиковать сообщения через очередь в Редисе (используя RPUSH команду) — это позволяет сохранить порядок сообщений, опубликованных в канал, если они были добавлены в очередь Редиса в верном порядке.
Каждая нода Центрифуги подписывается на канал в Редисе, используя команду SUBSCRIBE, как только появляется первый клиент, желающий получать сообщения из канала. Когда заинтересованных клиентов не остается — инстанс Центрифуги отписывается от канала (UNSUBSCRIBE). Таким образом, каждая нода Центрифуги подписана только на те каналы в Редисе, которые интересуют клиентов, подключенных к ноде.
O presence. Так как при перезапуске инстанса Центрифуги данные о пользователях остаются в Редисе — важно иметь для них expiration-механизм. Это несложно сделать для ключей с помощью команды EXPIRE. Но в нашем случае presence-информация для канала — это HASH-структура в Редисе, нужен способ «экспайрить» не HASH целиком, а его отдельные значения. Redis Engine достигает этого, используя комбинацию двух структур данных Редиса — HASH«a и SET«a. Давайте посмотрим на функции, реализующие добавление/обновление presence-информации, ее удаление и получение. Centrifugo использует Redigo в качестве Redis-клиента, поэтому в примерах кода фигурируют вызовы API этой библиотеки.
Для начала взглянем на добавление presence-информации клиента в канале:
func (e *RedisEngine) addPresence(ch string, uid string, info []byte) error {
conn := e.pool.Get()
defer conn.Close()
expire := 60
expireAt := time.Now().Unix() + int64(expire)
hashKey := "hash.” + channel
setKey := "set.” + channel
conn.Send("MULTI")
conn.Send("ZADD", setKey, expireAt, uid)
conn.Send("HSET", hashKey, uid, info)
conn.Send("EXPIRE", setKey, expire)
conn.Send("EXPIRE", hashKey, expire)
_, err = conn.Do("EXEC")
return err
}
Как только клиент появляется в канале (подписывается на него) — мы вызывaем addPresence, после чего, пока подписка клиента на канал активна, раз в 25 секунд (по умолчанию) обновляем информацию, вызывая этот же самый метод. В примере выше channel — это имя канала, uid — уникальный ID клиента, info — полезная информация о его подключении. В методе мы работаем с HASH- и SET-структурами. HASH хранит информацию, которая нам нужна, а SET позволяет индивидуально экспайрить значения HASH«a. При отсутствии обновления в течение 60 секунд мы считаем информацию в канале неактуальной и избавляемся как от отдельного ключа в HASH«е, так и от всех структур в целом.
Удаление presence-информации, когда клиент отписывается от канала, выполняется очень просто:
func (e *RedisEngine) removePresence(channel string, uid string) error {
conn := e.pool.Get()
defer conn.Close()
conn.Send("MULTI")
conn.Send("HDEL", "hash.” + channel, uid)
conn.Send("ZREM", ”set.” + channel , uid)
_, err := conn.Do("EXEC")
return err
}
Наконец, когда кто-либо запрашивает presence-информацию — вызываем метод presence, отдавая только актуальную информацию и попутно подчищая неактуальную (в большинстве случаев неактуальной не будет):
func (e *RedisEngine) presence(channel string) (map[string][]byte, error) {
conn := e.pool.Get()
defer conn.Close()
now := time.Now().Unix()
hashKey := "hash.” + channel
setKey := "set.” + channel
reply, _ := conn.Do("ZRANGEBYSCORE", setKey, 0, now)
expiredKeys, _ := redis.Strings(reply, nil)
if len(expiredKeys) > 0 {
conn.Send("ZREMRANGEBYSCORE", setKey, 0, now)
for _, key := range expiredKeys {
conn.Send("HDEL", hashKey, key)
}
}
reply, _ = conn.Do("HGETALL", hashKey)
return replyToPresenceInfo(reply)
}
В коде Centrifugo этот метод написан как Lua-скрипт, выполняемый с помощью вызова EVALSHA команды с параметрами. Благодаря этому операция внутри Редиса атомарна. В случае с получением presence-информации это еще позволяет сэкономить на round-trip задержках при обращении к Редису. На самом деле на Lua написаны и другие методы, рассмотренные выше.
В случае с историей в Redis engine«е нет ничего сложного — все сводится к использованию команд LPUSH, LTRIM, LRANGE и EXPIRE.
Наконец, еще одна особенность Redis Engine«a — возможность слушать очередь (очереди) в Редисе, в которую бэкенд вашего приложения может складывать новые сообщения для публикации. Команда RPUSH добавляет сообщение в очередь на публикацию, а Центрифуга использует вызов BLPOP, чтобы сообщения из очереди забирать. Все достаточно просто, но есть небольшой нюанс: все сообщения, принятые из очереди, обрабатываются последовательно, чтобы сохранить их порядок в каналах. Это узкое место, если у вас публикуется очень много новых сообщений.
Для преодоления этого барьера возможно запустить Центрифугу таким образом, что она будет обрабатывать сообщения, полученные из разных очередей в отдельных горутинах, тем самым распределяя работу между ядрами процессора. Собственно, так можно существенно поднять пропускную способность на публикацию новых сообщений. Чтобы при этом сохранять порядок сообщений в каналах, бэкенд вашего приложения может выбирать номер очереди, в которую нужно положить сообщение, на основе имени канала, используя что-то вроде:
crc16(CHANNEL_NAME) mod N
где N — количество очередей в Редисе, которые слушает Центрифуга.
Напомню, что в большинстве случаев для публикации сообщений вы будете использовать HTTP API, а не возможности Redis engine. Но это зависит от конкретного случая.
Redis — это единая точка отказа. И хотя Редис сам по себе очень стабилен и не имеет свойства неожиданно падать, ничто в его исходном коде не обезопасит от поломок машин, отключения электричества в дата-центре, потери сетевой связности и т. д. Существуют способы добиться от Редиса отказоустойчивости (см. например). В первую очередь в этом поможет официальный способ — использование репликации вкупе с Redis Sentinel. Также существуют различные конфигурации прокси — Haproxy, twemproxy, codis. Большинство PaaS-платформ предлагают High-Availability (HA) Redis из коробки.
С версии 1.4.2 Центрифуга научилась работать с Sentinel — достаточно указать имя мастера из конфигурации Sentinel и хотя бы один Sentinel-адрес. К сожалению, Центрифуга не может работать с twemproxy и codis, так как последние не поддерживают PUBSUB-команды. C haproxy проблем нет — при желании можно придумать хитрую конфигурацию.
Последнее, что я затрону, описывая Redis Engine, — батчинг опубликованных сообщений. Большое количество параллельных запросов на публикацию новых сообщений (а это, как вы уже могли заметить, основная операция, которую используют приложения, работая в связке с Центрифугой) приводит к необходимости много раз сходить в Redis, чтобы вызвать там команду PUBLISH и тем самым опубликовать сообщение в нужный канал. Понятно, что такой случай можно серьезно оптимизировать, используя Redis pipeline, т. е. отправку большого количества запросов в одном раунд-трипе (RTT) до Redis«а, — тем самым мы уменьшаем latency и увеличиваем общую пропускную способность. Многие, когда дело касается реализации автоматического батчинга, в первую очередь думают о том, чтобы копить буфер сообщений в течение небольшого конфигурируемого промежутка времени и затем по событию таймера (или достижению определенного размера) сбрасывать накопленные данные в соединение. Это рабочий вариант, но есть гораздо более эффективный и простой подход, позволяющий максимально уменьшить latency и
