Disaster Recovery Plan: Как правильно заваривать чай, когда горит серверная

Компания у на full-remote, поэтому заседание кружка параноиков мы проводим как-то так. Иногда под банджо в углу.
В жизни любого проекта наступает катастрофа. Мы не можем заранее знать, что именно это будет — короткое замыкание в серверной, инженер, дропнувший центральную БД или нашествие бобров. Тем не менее, оно обязательно случится, причем по предельно идиотской причине.
Насчет бобров, я, кстати, не шутил. В Канаде они перегрызли кабель и оставили целый район Tumbler Ridge без оптоволоконной связи. Причем, животные, как мне кажется, делают все для того, чтобы внезапно лишить вас доступа к вашим ресурсам:
Короче, рано или поздно, кто-то обязательно что-то сломает, уронит, или зальет неверный конфиг в самый неподходящий момент. И вот тут появляется то, что отличает компании, которые успешно переживают фатальную аварию от тех, кто бегает кругами и пытается восстановить рассыпавшуюся инфраструктуру — DRP. Вот о том, как правильно написать Disaster Recovery Plan я сегодня вам и расскажу.
Когда надо начинать писать DRP
Любой потраченный час сотрудника стоит денег. Час эксперта, который знает в лицо каждый вставленный костыль и понимает, что может сломаться, стоит еще больше. А еще часто эксперт и человек, который может писать понятным языком, — это разные люди. Короче, хороший документ стоит не очень дешево и нужно точно понимать, когда его стоит делать.
Вам точно стоит этим заняться, если:
У вас есть явная точка отказа, но понятных инструкций по ее восстановлению нет
При падении сервера, группы узлов или базы данных ваш бизнес встанет и запустится быстро крутящийся счетчик убытков.
Собственно, основная история тут в первую очередь про деньги. Узел с вашим telegram-ботом для заказа кофе в офис может упасть, но где-то валяются исходники? Пусть полежит, восстановим, когда будет время.
Из-за разрыва связности между датацентрами окуклился кластер Hashicorp Vault? Вашему биллингу будет грустно без паролей. Тут точно нужен DRP, который можно совместить с рефакторингом архитектуры.
Пишите документацию
Документацию очень редко любят писать. Мне, например, наоборот нравится, так как помогает отвлечься от рутинных задач и сфокусироваться на прозрачности архитектуры. Тем не менее, это крайне важная история, так как несколько десятков минут, потраченные на заметку, могут сэкономить вам потом много тысяч долларов при серьезной аварии.
Сразу, хочу обозначить очень важный момент: документация по troubleshooting — это очень важная вещь, что еще не DRP. Мы придерживаемся вот такого подхода:
Сотрудник, который лучше всего разбирается в системе, садится и пишет паспорт информационной системы. Он включает в себя основное описание, зачем эта штука вообще нужна, какие системы с ней связаны и к кому бежать, если что-то отломалось.
Дежурный натыкается на проблему в логах, либо фиксирует аварию. Если в процессе устранения аварии приходилось делать что-то не очень очевидное, он записывает все детали вплоть до списка команд в консоли и вносит в раздел Troubleshooting.
Если авария повторяется — создаем тикет на устранение ее причин.
Если причины устранить невозможно по архитектурным или финансовым соображениям, прикрепляем к описанию алерта ссылку на внутреннюю документацию, которая описывает, как это чинить.
Все, у нас уже есть какой-то базовый процесс, который позволяет любому сотруднику быстро устранить проблему.
Включаем внутреннего параноика
В целом, у нас уже есть документация, есть понимание того, как чинить основные проблемы, но все еще нет DRP. Для настоящего Disaster Recovery Plan нам надо сначала определиться с моделью угроз.
Есть относительно ограниченный список того, что может сломаться. Обычно это сводится к небольшому числу категорий вроде этого:
Отказ приложения
Отказ сервисов ОС
Отказ сети
Отказ железа
Отказ виртуализации
Отказ системы оркестрации
На этом этапе мы обычно собираемся всей командой, наливаем кофе, чай и начинаем думать, как эффективнее можно сломать нашу систему. Бонусные очки и доставку пиццы получает тот, кто найдет способ уронить на как можно более долгий срок минимальным воздействием.
В результате такой работы у нас обычно резко разрастается бэклог за счет задач вида «Если скрипт N сработает перед скриптом М, то это необратимо разрушит центральную БД. Надо бы починить». То, что осталось после устранения технического долга, и есть ваша модель угроз, которая включает тех самых бобров-рецидивистов, уборщицу в серверной и прочие стихийные бедствия вне вашего контроля.
Смириться с неизбежным и пойти пить чай

Итак, вы осознали тот факт, что в итоге все сломается. Вы учли все возможные факторы, включая перекрытие радиорелейной линии фестивалем летающих шаров и новый пожар у одного из ваших провайдеров.
Теперь задача написать сам DRP. Нет, это не тот обширный раздел по troubleshooting, который вы писали ранее. DRP, по своей сути, это некий красный конверт, где после вскрытия будут инструкции вида:
Снять синюю телефонную трубку
Продиктовать дежурному: «Желание — Ржавый — Семнадцать — Рассвет — Печь — Девять — Добросердечный — Возвращение на Родину — Один — Грузовой вагон»
Ждать ответного гудка
Даже если у вас команда, которая состоит исключительно из топовых экспертов в своей области, документ должен быть написан так, чтобы быть понятным человеку с IQ не выше 80. Анализ реальных ситуаций показал, что в момент тяжелых аварий инженер в стрессе часто не только не устраняет, но, напротив, добивает полуживую систему окончательно.
Поэтому, наши документы начинаются почти всегда одинаково:
«Краткий верхнеуровневый гайд для сценария по умолчанию. Дальше будет много букв и варианты с деталями. Начнем с базовой последовательности:
Заварить чай и перестать нервничать.
Оповестить ответственных»
И да, чай обязателен. За 5 минут мертвой системе хуже уже не станет, но риски того, что инженер будет экстренно дергать все рубильники, которые знает, значительно ниже. Последний пункт звучит как »Достать из холодильника холодный Гиннес (должен храниться в НЗ на случай аварии). DRP завершен.»
Структура DRP
Вот приблизительная структура, которую мы используем как шаблон. Конечно, вы можете взять что-то свое.
Тип документа | DRP |
Информационная система | Enigma cluster |
Дата создания | 07.06.2022 |
Дата последней актуализации | 13.02.2024 |
Периодичность актуализации и тестирования | 1 год |
Дата тестирования DRP | 13.02.2024 |
Архитектура информационной системы
Информационные системы
Оповещение ответственных
Ключевые вопросы перед DRP
Что мне делать по умолчанию?
Краткий верхнеуровый гайд для сценария по умолчанию.
Когда применяется этот DRP?
Принципы выбора площадки для развертывания
Как понять куда будет идти развертывание?
Принятие решения и анализ ситуации
Очередность развертывания сервисов и тайминг
RPO и RTO
Инструкция по развертыванию DRP инфраструктуры
Дополнительные материалы
Таким образом, инженер, впервые открывший документ в момент аварии должен сразу понять, как провести первую диагностику, и начать восстановление. Общая структура должны отвечать на несколько простых вопросов:
Кого нужно сразу оповестить о начале аварии?
Как правильно провести первичную диагностику перед тем, как что-то трогать? Готовые простые команды в консоль, ссылки на дашборды и другие полезные вещи.
Сколько у меня есть времени? Могу ли я попробовать починить систему или мне нужно сразу поднимать все с нуля?
Как понять, что авария завершилась и мы перешли на обычный режим?
Очень важно не путать паспорт системы с подробным ее описанием и DRP. Не перегружайте его излишней информацией. Инженер должен иметь возможность просто идти по инструкции, копируя команду за командой.
Хорошей практикой будет добавление раздела «Дополнительные материалы» в конец документа. Туда можно ссылаться по мере необходимости из основной краткой инструкции и других документов. Тот Troubleshooting, который мы описывали ранее, вполне впишется в этот блок. Любую другую дополнительную информацию тоже стоит переносить в конец, чтобы не нарушать минималистичный стиль основной инструкции.
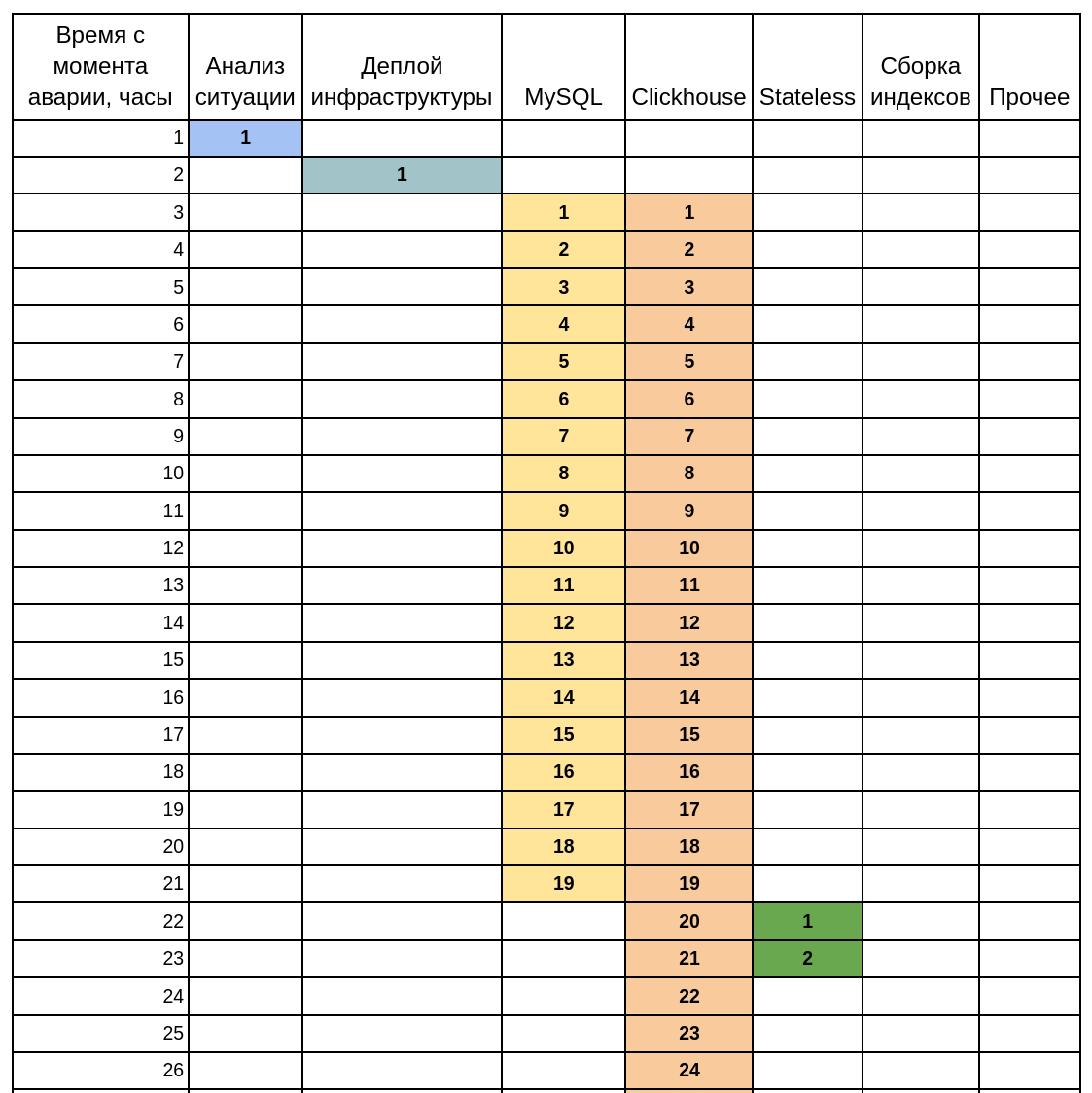
Вертикальная диаграмма Ганта, сильно помогает в сложных системах
Если сервис сложный и отдельные элементы развертываются параллельно, то я бы настоятельно рекомендовал добавить диаграмму Ганта, которая наглядно описывает очередность восстановления и примерные сроки для каждого этапа. В текстовом виде такая информация воспринимается сложнее.
В самом конце вашего документа должно быть понятное описание условий отмены аварийного режима, чтобы было понятно, в какой момент надо переключать нагрузку обратно и переходить на повседневное функционирование.
Важность IаC
В целом, концепция Infrastructure-as-a-code формально не обязательна для реализации Disaster Recovery Plan. Тем не менее, в большинстве крупных информационных систем инженер не сможет уложиться в обозначенные сроки, если будет бегать от сервера к серверу и экстренно что-то править в конфигурации, попутно меняя DNS-записи.
Намного правильнее будет описать всю основную и резервную инфраструктуру в terraform, а ее конфигурацию в ansible. Опционально, вы можете даже запечь готовые образы в Hashicorp Packer, если вы придерживаетесь концепции иммутабельной инфраструктуры.
В этом случае, можно добиться околонулевых затрат на поддержание DRP в состоянии боевой готовности. Структурно это будет выглядеть примерно следующим образом.
Опишите вашу тестовую и продуктивную инфраструктуру в terraform.
Опишите вашу DRP-инфраструктуру в terraform, но добавьте переменные для активации развертывания.
В variables.tf добавьте что-то вроде этого:
variable "enable_mysql_drp" {
description = "Condition for creation of DRP MySQL droplet. Droplet is created only if variable is true"
type = bool
default = false
}В main.tf опишите необходимые параметры вашей временной инфраструктуры и свяжите с условиями:
resource "digitalocean_droplet" "rover3-mysql-central-nl-1" {
image = var.ol7_base_image
count = var.enable_mysql_drp ? 1 : 0
name = "mysql-central-nl-1.example.com"
region = var.region
size = "c2-32vcpu-64gb"
tags = ["enigmа", "enigma-central", "enigma-mysql-central"]
monitoring = true
}
resource "digitalocean_droplet" "rover3-mysql-central-nl-1" {
image = var.ol7_base_image
count = var.enable_mysql_drp ? 1 : 0
name = "mysql-central-nl-1.example.com"
region = var.region
size = "c2-32vcpu-64gb"
tags = ["enigmа", "enigma-central", "enigma-mysql-central"]
monitoring = true
}Теперь, инженер сможет развернуть всю временную инфраструктуру в несколько подобных команд из вашей инструкции:
cd ~/enigma/terraform/DO
terraform apply /
-var='enable_mysql_drp=true' /
-var='enable_indexator_drp=true' /
-var='enable_clickhouse_drp=true' /
-var='enable_statistics_drp=true'Если вы в качестве источника для развертывания аварийной инфраструктуры выбрали уже запеченные с Packer«ом образы, то вы получите почти готовую инфраструктуру в течение нескольких минут. Накладные расходы на хранение самих образов обычно невелики, но они требуют постоянной актуализации.
Другой вариант — это непосредственное использование ansible, который настроит всю новую инфраструктуру в соответствии с вашими требованиями к конфигурации. Не забудьте про время загрузки и восстановления БД из холодного бэкапа. Это может быть недешево и долго, поэтому учтите это при планировании.
Короткий чек-лист
Вот несколько ключевых моментов, которые нужно учесть:
Законы Мерфи никто не отменял. Если что-то упасть, то оно рано или поздно упадет. С грохотом и побочными эффектами в неожиданных местах.
Перед началом работы проведите полный анализ и покажите бизнесу, сколько ему будет стоит возможная авария, и сколько резервный сценарий для DRP. Чаще всего после этого ресурсы выделяют. Иногда понимают, что будет дешевле, если все упадет на сутки, чем иметь полный резерв в запасе.
Убедитесь, что у вас выполняются бэкапы.
Убедитесь, что бэкапы не только выполняются, но и восстанавливаются.
Включите творческого параноика и опишите модель угроз.
Напишите DRP. Потом возьмите и выбросьте из него большую часть текста так, чтобы не терялся смысл. Все избыточное добавьте в конец документа. Если будет нужно, инженер туда заглянет.
Включите в документ номера телефонов, аккаунты в telegram и прочие контакты всех ключевых людей.
DRP нужно тестировать. Серьезно, это обязательно. У бизнеса никогда нет времени на эти задачи, но это очень важный процесс. Инфраструктура любого живого проекта за год может измениться до неузнаваемости, токены протухнуть, доступы пропасть, а конфигурация стать невалидной. Поэтому, заложите в бизнес-процессы хотя бы ежегодную ограниченную симуляцию.
Выдавайте DRP стажерам в ограниченной среде и смотрите как они мучаются с костылями с интересом изучают документ. Ваш план хорош, если с ним в состоянии разобраться даже самый неопытный член команды.
Кстати, если корпоративная политика вашей компании такое позволяет, то я бы настоятельно рекомендовал присмотреться к LLM-нейросетям в качестве помощника по внутренней документации. Да, нужно понимать, что условный GPT-4 вовсе не истина в последней инстанции. Тем не менее, намного удобнее устранять аварию посреди ночи, если рядом «сидит» эксперт, который «держит перед глазами» 120 листов документации по уникальным костылям в вашей системе. Мы только начали внедрять этот подход и он уже показывает себя с лучшей стороны.
Нейросеть может быстро проанализировать сырой лог и построить гипотезы о причинах аварии. Это очень ценно в тех случаях, когда дежурный инженер не знает всех тонкостей упавшей системы. Об этом я расскажу подробнее в следующий раз.
