Десять человек на 90 тысяч сайтов: как не сойти с ума
Привет, меня зовут Вера Сивакова. Я работаю с ключевыми партнёрами Яндекс.Кассы — подключаю большие магазины и сервисы, запускаю проекты и езжу на встречи по всему миру. В общем, слежу, чтобы всё было хорошо.
Каждый сотрудник Яндекс.Денег раз в год может сменить род деятельности — выбрать какой-нибудь отдел и поработать там несколько дней. Поэтому месяц назад и я села в Сапсан и приехала в Петербург. Там работает отдел мониторинга, который тоже следит, чтобы у 90 тысяч сайтов, подключенных к Кассе, всё было хорошо, — и мы решили объединить силы.

Как не сойти с ума? Точно не так (источник: reddit.com)
Это рассказ о том, как у нас устроен мониторинг, и чему я научилась за пару дней в другом департаменте.
Каждую секунду через сервис проходит порядка 600 транзакций и за всё это нужно мониторить в реальном времени —, но в какой именно момент пора бить тревогу, если что-то случилось? Нужен системный взгляд примерно на всё.
Хорошая практика — анализировать систему с технической стороны и не забывать о бизнес-метриках — количестве платежей, обороте и других параметрах.
В небольших системах хватает и зоркого взгляда главного (чаще всего и единственного) админа. Но когда процессов становится много, сотрудники не могут мониторить всё вручную, поэтому лучшей стратегией будет максимальная автоматизация. Без экспертного знания и усилий команды ничего не будет работать само, так как мониторинг — это постоянное совершенствование, анализ и умение выбрать грамотные метрики и триггеры. Они сработают в случае отклонения от заданных условий и сообщат об аномалии.
Мы выделяем три уровня мониторинга, на каждом из которых есть свои важные показатели — уровень системы, уровень бизнес-логики и уровень контрагентов.
Уровень системы
Самое важное здесь — круглосуточный мониторинг инфраструктуры. Из инструментов мы используем Zabbix для сбора данных в реальном времени — он уведомляет о работе серверов и дата-центров, качестве работы сети, доступности компонентов и источников данных.
Мониторинг ИТ-инфраструктуры — очень ответственная работа, так как отказ на этом уровне чреват неработоспособностью системы и отчаянными мерами. Поэтому важно не только реагировать на «мигающие» проблемы, но и анализировать тренды и исторические данные — это позволит вовремя предупредить потенциальные точки отказа и спрогнозировать необходимость масштабирования. Правило работает для всех показателей и уровней мониторинга, в том числе бизнесового.
Для критичных точек пороги срабатывания триггеров следует выбирать ниже. Например, в случае роста времени ответа от одного роутера мы переводим трафик на другой и устраняем причину на первом. Это сработал предупреждающий триггер, который позволяет получать уведомления о потенциальных проблемах сильно заранее, что даёт запас времени на реагирование, возможность прогнозировать изменения и избегать катастроф.
Уровень бизнес-логики
Каждая команда определяет процессы, которые необходимо отслеживать, их приоритет и персональные метрики. Например, команда Кассы имеет десятки бизнес-процессов, таких как оплата каждым доступным методом — картами, электронными кошельками, через онлайн-банки и терминалы, мобильную коммерцию, отправку реестров и т.д. В качестве основного инструмента для сбора и отображения данных по работе бизнес-логики мы используем Graphite в связке с Grafana.
На этом уровне важно придерживаться системного подхода и стараться уходить от бинарного и малоинформативного «работает/не работает».
Например, есть метрика «Число успешных платежей картой». Если она начинает мигать, это означает, что поток операций уменьшился. При этом надо понять, в чём именно причина, и учесть все компоненты, которые задействованы в данном процессе. В случае со снижением количества транзакций можно сразу подумать про то, что есть сложности на стороне банка-эквайера. Но графики показывают, что с доступностью банков всё хорошо. Тогда надо исследовать дальше, и в итоге окажется, например, что все вопросы к вёрстке: по какой-то причине пропала кнопка «Оплатить» или она стала неактивна.
Уровень контрагентов
Здесь речь о конкретных контрагентах — например, банках-эквайерах и мерчантах.
У нас выделены отдельные графики и триггеры под эквайеров, доступность которых мы должны отслеживать всё время. Для нас, как платёжного сервиса, очень важна стабильность работы, поэтому в случае фиксации сбоя одного из банков мы сразу переводим поток на резерв.

Один банк отказал, но автоматически подключился другой
Мы научились довольно хорошо и своевременно перенаправлять поток операций, если начались ошибки.
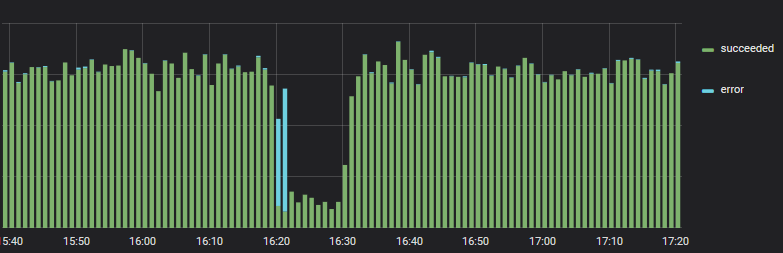
В одном из банков зафиксировали рост ошибок при оплате
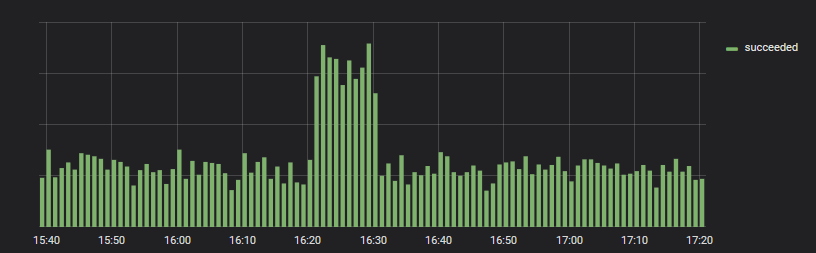
Перевели — и всё в порядке. Значения по оси Y не соизмеримы
Сбои у эквайеров могут случаться по самым разным причинам на уже описанных уровнях — системы и бизнес-логики. Никто не застрахован от непредвиденных проблем и не может гарантировать 100% доступности. Также стоит помнить и про запланированные технические работы и релизы, когда надо пристально следить за ходом дел. Вопрос резервирования и автоматического переключения критический, так как простой означает остановку платежей для бизнеса.
Мы работаем сразу с несколькими банками для минимизации рисков простоя и оптимизации SR карточных платежей. SR (success rate) или иначе конверсия — это бизнес-метрика, которая вычисляется как отношение числа успешных платежей к общему количеству транзакций. Разные компании измеряют конверсию по-своему: например, кто-то начинает замер со страницы оплаты, другие после нажатия кнопки «Оплатить». Но в целом на SR влияют много разных факторов — МСС, есть ли 3D-Secure в платеже, география плательщиков, рекуррентные платежи или нет. «Среднее по больнице» SR определить невозможно и знать не нужно — в каждом случае это будет своё значение, которое необходимо оптимизировать.
Всё многообразие ошибок можно поделить на две большие группы.
- Ошибки, которые можно предотвратить — например, платёж из этой страны запрещён. Если вы уверены, что это не мошенническая атака и у вас есть пользователи по всему миру, то в этом случае необходимо подключить возможность оплаты с карт любых эмитентов. Это, кстати, можно сделать в личном кабинете Яндекс Кассы.
- Ошибки, на которые нельзя повлиять — например, карта заблокирована. Тут поможет только перевыпуск или попытка повторить платёж другой картой в рамках новой транзакции.
Многие выбирают платёжного провайдера по ставке. На самом деле, ставка — не единственное значение, которое стоит принимать в расчёт. Нужно смотреть ещё и на процент успешных платежей (SR) — потому что 100% конверсии не бывает ни у кого и это значение сильно меняется от банка к банку. Также необходимо учитывать, как в целом выглядит пользовательский сценарий: сколько шагов нужно пройти до оплаты, понятен ли интерфейс и т.д.
Как конверсия влияет на прибыль
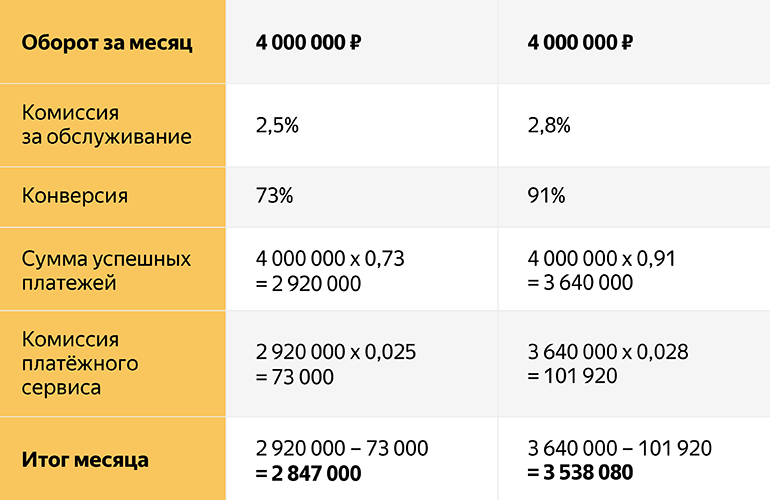
Во втором случае выше комиссия за обслуживание, но выше и конверсия, потому что используются резервирование и грамотная настройка шлюза.
Как видно из примера, выгодным для бизнеса решением будет взять более качественный сервис и, несмотря на то, что комиссия выше из-за разницы качества эквайринга, в итоге имеем 3 538 080 — 2 847 000 = 691 080 разницы рублей в месяц! А это уже 8 миллионов в год, что очень большие деньги для бизнеса.
Конверсия, оборот и ставки условны, но пример демонстрирует, что основное в сервисе — его стабильность и качество. А уже это влечёт за собой повышенную конверсию и, как следствие, больший оборот для мерчанта.
Как подключается мерчант
Как упоминалось ранее, мы стараемся максимально покрыть всё метриками и триггерами, которые автоматически срабатывают по событию. Давайте разберём, как всё происходит на примере мониторинга одного из мерчантов.
После подключения к Кассе мерчант при необходимости ставится на мониторинг. Мы строим график в Grafana и настраиваем метрики, по которым срабатывают автоматические алерты в случае отклонения от заданных «нормальных» значений.
Мы используем Moira для отправки уведомлений в чат группы мониторинга, которая оперативно проверит детали. Уведомление содержит ссылку на график и детали инцидента.

Совершенно точно реальный пример сообщения от бота
После анализа графика специалист группы мониторинга чаще всего использует Kibana для просмотра логов. Тут ситуация может быть прозаичной, и тогда в логах, очевидно, будет видна ошибка либо потребуется дополнительное участие аналитиков для анализа причин сбоя.
В перспективе мы хотим настроить автоуведомления мерчантов об ошибках на их стороне, например, о недоступности сервера или ответах не по протоколу. Это позволит оперативно отреагировать на сбой и дать контрагентам информацию для устранения причин.
Помимо технической стороны, мы также внимательно смотрим за такими бизнес-метриками, как оборот, доход и отток, но это, кажется, уже тема для следующих рассказов.
Самое главное
Мой «день непослушания» (а именно так у нас называется временный переход в другой отдел) закончился, и я вернулась в Москву. За 2 дня в отделе мониторинга я узнала много нового и упорядочила текущие знания.
- Задача мониторинга — давать актуальную информацию о состоянии системы на всех уровнях;
- Выбрать грамотные метрики и триггеры — 90% успеха;
- В платёжных сервисах конверсия бьёт ставку;
- Нужно следить за техникой и помнить о бизнес-метриках;
- Нужен системный взгляд на процессы и умение анализировать взаимосвязи;
И еще — будьте благодарны. Ребята из мониторинга, спасибо!
На этом всё. Задавайте вопросы, подписывайтесь на наш блог и приходите в гости.
