Деплоим приложение на Django в Kubernetes с нуля

Расшифровка вебинара
Все исходники и манифесты можно найти в репозитории
Привет! Меня зовут Игорь, я управляющий партнер в KTS.
Нашей компании уже 6 лет, и 4 из них мы живем с Kubernetes. До этого мы испытали все варианты деплоя приложений на серверах: начиная от простого git pull до ci/cd на нескольких серверах.
Сегодня мы на практике разберем, что нужно делать, чтобы ваше приложение оказалось в Интернете. Какие-то моменты я опущу, чтобы не забираться слишком глубоко. В статье мы:
Пройдем путь от написания кода до запуска в Интернете
Рассмотрим необходимые для этого абстракции в Kubernetes
Задеплоим приложение в облаке и разберем, что для этого необходимо
Kubernetes — не самая простая вещь для быстрого понимания. Нужно постепенно входить в каждую абстракцию и элемент, чтобы понять, что с чем и как взаимосвязано.
Что будет в статье:
Подготовка к деплою в Kubernetes
Нам понадобятся:
Docker-файл для всех компонентов приложения
Собранный и запушенный в registry образ приложения
Манифесты, описывающие каждый компонент приложения. Их можно генерировать через инструменты шаблонизации, например, Helm
Выбранный на ваше усмотрение кластер. Можно взять облачный кластер у провайдера, можно сгенерировать самостоятельно. Но обратите внимание на необходимые компоненты:
Ingress Controller, например — nginx-ingress-contorller
для автоматического выписывания SSL-сертификатов — cert-manager
Сегодня мы задеплоим созданное через Django Create Project простое приложение на Django, соединенное с PostgreSQL. Все, что есть в приложении — url, который отдает HTML-страницу, просто чтобы проверить, что он работает:
def index(request):
return HttpResponse('''
KTS Webinar Demo
KTS Webinar Demo
It Works!
''')Уже сейчас оно работает с базой данных Postgres, как можно убедиться, посмотрев settings. У нас указана локальная база данных ktswebinar:
DATABASES = {
'default': env.db(default='postgresql://postgres:postgres@127.0.0.1:5432/ktswebinar'),
}Мы будем деплоить одновременно БД и приложение, поэтому сейчас для нас очень важно разделить эти два компонента, чтобы увидеть, как они будут взаимосвязаны.
Теперь давайте разберемся с requirements. У нас есть сама Django, пара библиотек для Postgers и переменных окружения и gunicorn в качестве веб-сервера, который будет загружать наше приложение в Docker.
Django==3.2.9
django-environ==0.8.1
psycopg2-binary==2.9.2
gunicorn==20.1.0Для начала посмотрим на этапы Docker-файла:
FROM python:3.9-slim as builder
ENV PYTHONUNBUFFERED=1
RUN pip install -U pip setuptools wheel
WORKDIR /wheels
COPY requirements.txt /requirements.txt
RUN pip wheel -r /requirements.txt
FROM python:3.9-slim
ENV PYTHONUNBUFFERED=1
COPY --from=builder /wheels /wheels
RUN pip install -U pip setuptools wheel \
&& pip install /wheels/* \
&& rm -rf /wheels \
&& rm -rf /root/.cache/pip/*
WORKDIR /code
COPY . .
EXPOSE 8000
ENV PYTHONPATH /code
RUN python manage.py collectstatic --noinput
CMD ["gunicorn", "-c", "docker/gunicorn.py", "ktswebinar.wsgi:application"]Устанавливаются зависимости:
WORKDIR /wheels
COPY requirements.txt /requirements.txt
RUN pip wheel -r /requirements.txtОни копируются и устанавливаются в конечный образ:
COPY --from=builder /wheels /wheels
RUN pip install -U pip setuptools wheel \
&& pip install /wheels/* \
&& rm -rf /wheels \
&& rm -rf /root/.cache/pip/*Вызывается команда Django manage.py collectstatic:
RUN python manage.py collectstatic --noinputОна собирает все статичные файлы — картинки, стили, js-файлы — и складывает их в одну папку. Нам это нужно, потому что потом мы еще будем смотреть на админку, и для упрощения вся статика собирается в этом же контейнере.
В качестве команды для запуска у нас будет использоваться gunicorn с настройками в папке docker/gunicorn.py и указанным wsgi-приложением, которое мы будем запускать — ktswebinar.wsgi:application:
CMD["gunicorn”, "-c”, "docker/gunicorn.py”, "ktswebinar.wsgi:application:”]В самом gunicorn.py нет ничего особенного:
import os
name = 'ktswebinar'
bind = '0.0.0.0:8000'
proc_name = 'ktswebinar'
daemon = False
user = 'root'
group = 'root'
workers = 1
errorlog = '-'
accesslog = '-'Единственное, на что нужно обратить внимание — bind. Здесь указан адрес, к которому будет выполнен bind приложения: 0.0.0.0:8000. В дальнейшем нам это пригодится.
Все логи будут писаться в stdout контейнера.
Давайте посмотрим, куда мы все это запушим. Чтобы образ где-то существовал, нужен какой-то Docker Registry. Можно использовать Docker Hub, хотя у него только один бесплатный приватный репозиторий. В целях демонстрации этого достаточно. Нужно просто ввести название, нажать Create, и у вас будет примерно такой репозиторий:

После этого все, что нужно — выполнить команду docker build, указав финальный тег образа и директорию, в которой нужно искать Docker-файл:
Ждем, когда все соберется:
После того, как все собралось, останется только выполнить docker push:
docker push igorcoding/ktswebinar:1.0.4 .В нашем случае push будет выполнен только для первых двух слоев, потому что у нас поменялись только исходники:
После push Docker-образа мы в любой момент можем выполнить для него docker run, пробросив порт 8000 на порт 9000:
docker run -p 9000:8000 igorcoding/ktswebinar:1.0.4
Сейчас мы прошли 2 этапа:
Написали Docker-файл. Эта часть у нас осталось за кадром, потому что я заранее его подготовил
Запушили этот Docker-образ в registry
Напоследок нужно сказать про приложение кое-что еще. Нужно помнить о том, что это Django. Это приложение, работающее с базами данных. А когда мы работаем с такими приложениями, у нас есть миграции: скрипты, которые приводят состояние схемы базы в нужную версию. Нам нужно будет как-то применять миграции при выкатке приложения в продакшн. Об этом мы поговорим позже.
Миграции в Django применяются с помощью команды manage.py migrate.
Чтобы посмотреть все миграции, выполните команду manage.py migrate showmigrations.
Архитектура Kubernetes
Kubernetes — оркестратор Docker-контейнеров. Это непростая сущность, и для его использования нужно понимание, из чего состоит его кластер.
Кластер состоит из двух видов узлов: мастер-узлы control plane и рабочие узлы worker. На worker обычно запускаются сами процессы, которые мы хотим задеплоить — веб-приложения, базы данных и т.д. На мастер-узлы редко деплоят рабочую нагрузку. Они выделены и там находятся управляющие сервисы, такие как API server, scheduler, Controller manager:
API server нужен для обработки запросов на добавление, изменение, апгрейд сущностей. Когда вы работаете с Kubernetes, всегда считайте, чтобы вы работаете с Kubernetes API server. Даже kubelet, которые запущены на Node, общаются через API server.
Из-за того, что Kubernetes непростой, включает много компонентов и подвижных частей, большие компании предоставляет его в качестве готового managed-решения. Нажатием пары кнопок интерфейса вы можете создать Kubernetes-кластер, к которому подключаетесь и начинаете деплоить приложение. Так вы не задумываетесь о развертывании кластера по нескольким нодам.
Для развертывания продакшн-кластера вам нужно как минимум 3 мастер-узла, 1 балансировщик перед ними, 1 worker, на который вы деплоите приложение, и 1 балансировщик, который смотрит на worker. Итого 6 серверов для поднятия относительно работоспособного продакшн-кластера.
Можно еще усложнить эту схему, вынеся отдельно базу данных, которую использует Kubernetes, etcd. Это еще 3 дополнительных сервера. К тому же с ростом количества worker-узлов будет увеличиваться количество необходимых мастер-узлов.
Kubernetes-кластер может быстро превратиться в десятки серверов. Поэтому облачные провайдеры предоставляют готовые Kubernetes-решения. В России это Selectel, VK Cloud Solutions и Яндекс Cloud.
Абстракции
Все конфиги и манифесты Kubernetes пишутся в виде yaml-файлов, и все они практически идентичны по структуре. У всех есть поля apiVersion и kind. Посмотрите на файл сущности Deployment:
Два параметра apiVersion и один kind вместе называются GVK — Group, Version, Kind. Они уникально идентифицируют тип ресурса. Но некоторые ресурсы не имеют группы, потому что они встроены в Kubernetes. Например, Pod.
Теперь перейдем к конкретным абстракциям.
Pod. Минимальная сущность, которой оперирует Kubernetes для деплоя.
Это обертка над контейнером. Между этими двумя терминами можно поставить условный знак равенства. Когда мы запускаем какой-то контейнер, мы в любом случае запускаем под. Единственное отличие между ними в том, что внутри пода может быть несколько контейнеров. В описании мы можем увидеть секцию containers, где описан контейнер:
Если вы работали раньше с Docker compose, вы увидите похожую ситуацию и здесь. Мы описываем контейнеры, которые нужно запустить:
name— названиеimage, imagePullPolicy— образ, из которого надо запустить контейнерports— порты, которые использует контейнер для expose
Контейнер. Мы упаковываем наше приложение в образ, который доставляем на сервер, и там из этого образа запускается контейнер. Нужно помнить, что контейнер — это не виртуальная машина, у него нет почти никакого оверхеда на запуск и работоспособность.
Дополнительная абстракция подов понадобилась именно потому, что для распределения любой нагрузки Kubenetes использует именно поды. Если в поде у вас несколько контейнеров, то все они пачкой будут задеплоены на сервер.
Есть две возможности, про которые нужно помнить:
контейнеры внутри пода имеют одно сетевое пространство и могут обращаться друг к другу по localhost. Им не нужно ходить по сети или на другие узлы.
между ними может быть организован общий диск: например, один контейнер может писать какие-то файлы, а другой — читать их. Так можно организовать какой-нибудь upload-сервер. Например, Python-приложение сохраняет запросы на upload и сохраняет их в общую папку между контейнерами. Из этой папки их раздает nginx.
kubectl. Эта утилита используется для того, чтобы применить что-то в Kubernetes. Если выполнить команду kubectl apply -f pod.yaml, где -f означает «передать файл», можно увидеть, что этот под будет запущен.
Deployment. Наиболее практически ориентированная сущность.
Возможности удобно запустить несколько копий одного и того же пода нет: нужно руками менять name. Это может понадобиться, например, для распределения нагрузки: когда вы понимаете, что под не справляется с нагрузкой, и хотите запустить еще один такой же. Тогда придется создать еще один такой манифест, так же его задеплоить и самому следить за состоянием каждого пода.
Поэтому придумали такие более общие манифесты, как ReplicaSet или DaemonSet. Одним из них является Deployment.
Внутри манифеста есть секция template, которая на самом деле представляет собой под: там точно так же есть containers и остальные параметры, которые мы уже разобрали. Задача Deployment в том, чтобы запустить количество подов, указанное в параметре replicas, из шаблона template.
Обратите внимание на поля Labels. Они не несут никакой физической нагрузки и нужны для логического связывания. Но здесь они обязательны и важны, потому что Deployment должен как-то понять, какие контейнеры ему принадлежат, чтобы определить, сколько подов уже запущено и сколько должно быть запущено.
Поэтому внутри секции template есть компонент лейблов, которые также указаны в секции selector в Deployment:
Как создать кластер
В качестве демо мы будем использовать кластер, созданный в VK Cloud Solutions. Коротко пройдемся по опциям, которые могут вас ждать.
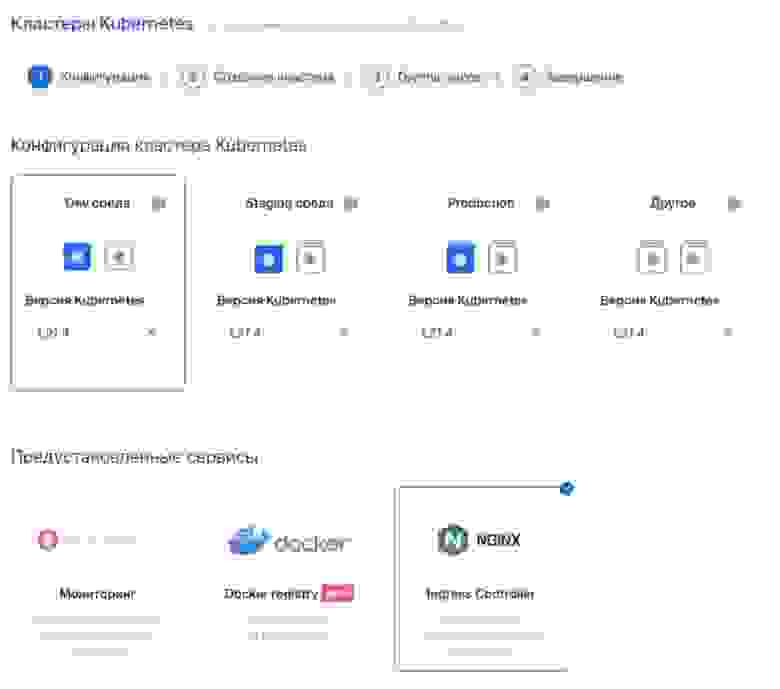
1-й этап
Конфигурация кластера Kubernetes. Мы выберем самый простой — «Dev среда».
Предустановленные сервисы. Нам не нужен Docker registry, но понадобится Ingress Controller, про который мы еще поговорим. Упрощенно говоря, это сущность, с помощью которой трафик привлекается из Интернета и попадает внутрь кластера.
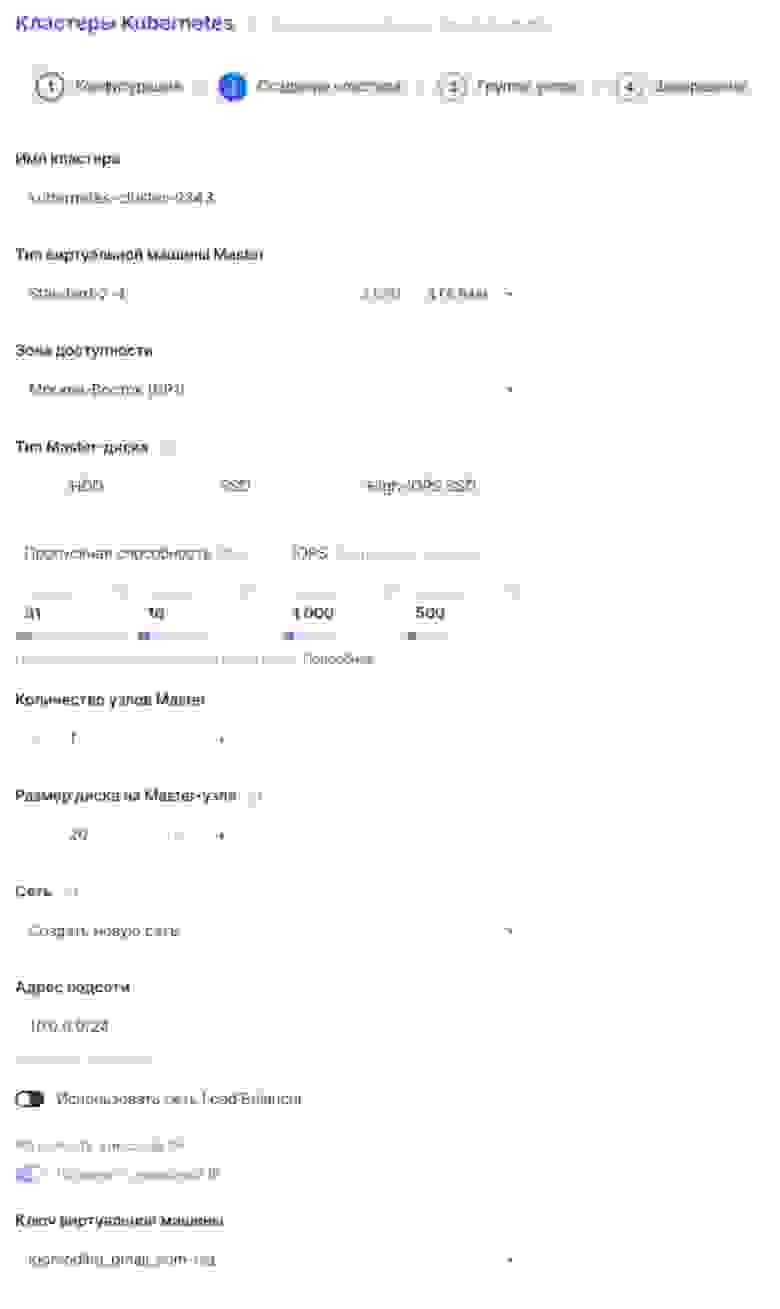
2-й этап
Здесь нет ничего интересного. Параметры тут можно отредактировать на свое усмотрение. Обратите внимание, что количество мастер-узлов всегда нечетное.

3-й этап
На этом этапе можно создать сразу одну или несколько групп узлов. Разберем параметры, которые будем менять.
Тип Node-узлов. Нам понадобится одна группа воркеров, и в этом поле вы должны выбрать их конфигурацию. После этого настраиваете по своим потребностям следующие поля:
Размер диска
Количество узлов Node
Автомасштабирование. Очень полезная функция, работающая на основе метрик, которые могут быть в самом кластере Kubernetes. Уникальное свойство оркестраторов в том, что при наступлении события по метрикам они могут купить дополнительные машины или еще один worker в кластер и задеплоить туда приложение. Нужно в случаях, когда, например, у вас не хватает CPU или памяти.
На этом настройка конфигурации закончена. После нажатия кнопки «Создать кластер» вы получите примерно такой результат:

Из этого кластера вам понадобится файл kubeconfig, который у меня уже был скачан. Его также можно скачать по ссылке см. п.2 на иллюстрации выше (список внизу под словом Подключение).
Для дальнейшей работы нам понадобится kubectl. Как его установить, можно прочесть на официальном сайте Kubernetes.
kubectl должен знать, в какой конфиг смотреть. Для этого выполните команду export KUBECONFIG, переменной окружения с указанием пути, где лежит kubeconfig:
$ export KUBECONFIG=~/Desktop/kubernetes-cluster-1658_kubeconfig.yamlПосле этого можно выполнить команду kubectl get nodes, которая вернет узлы кластера. В нашем случае — два узла, один мастер и один worker:
Видов ресурсов в Kubernetes очень много. Чтобы те ресурсы, которые вы деплоите, не пересекались друг с другом, существуют выделенные окружения, которые изолируют ресурсы. Они называются namespace.
Чтобы посмотреть все поды во всех namespace, выполните команду kubectl get pods -A:
Сейчас у нас уже запущено какое-то количество подов, в основном в namespace kube-system.
Чтобы посмотреть изолированные ресурсы конкретного namespace, используется флаг -n: kubectl -n ingress-nginx get pods
Выполнив команду, вы увидите все поды в namespace ingress-nginx.
Также можно смотреть другие ресурсы:
kubectl -n ingress-nginx get servicekubectl -n ingress-nginx get ingresskubectl -n ingress-nginx get deploy
Пишем первый манифест — deployment
Первый манифест, с которым мы познакомимся — сам deployment:
name: Создаем deployment с именем ktswebinar.
labels: Лейблы, которые вы видите — стандартные. Всего их 6 штук. и желательно, чтобы вы пользовались ими: app.kubernetes.io/name: app.kubernetes.io/component:
replicas: Говорим, что хотим запустить одну реплику.
containers: Параметры контейнера, который мы используем в качестве пода.
Теперь создадим новый namespace, чтобы ни с чем не конфликтовать: kubectl create ns ktswebinar
Посмотрим содержимое: kubectl -n ktswebinar get pods
Пока тут ничего нет. Мы сделаем первые операции, но всегда будем выполнять команды с -f .kube/, чтобы применить их ко всей директории: kubectl -n ktswebinar apply -f .kube/
У нас создался deployment. Мы можем применить команду kubectl -n ktswebinar get pods и увидеть, что он находится в состоянии ContainerCreating:
Итак, у нас есть deploymennt, который называется ktswebinar и состоит из одного пода:
Сами поды можно посмотреть с помощью команды kubectl get pods:
Название пода начинается с названия deployment, а после него идет хеш.
Чтобы узнать, работает ли вообще наша система, выполним команду kubectl -n ktswebinar port-forward. Она пробросит порт из конкретного пода на наш компьютер. Для этого нужно написать название контейнера и порт:
Трафик из порта 127.0.0.1:9000 пробрасывается в порт 8000 контейнера. Если мы перейдем на localhost:9000, то увидим, что у нас все отработало и идет handling соединения на порт 9000:
Теперь посмотрим логи контейнера с помощью команды kubectl logs и убедимся, что все отработало успешно:
Связь с базой данных — манифест pg-deploy
Возьмем deployment для Postgres и разберем его:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pg
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: pg
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: pg
template:
metadata:
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: pg
spec:
containers:
- name: pg
image: postgres:14
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5432
name: pg
env:
- name: POSTGRES_PASSWORD
value: gYwOKJZaR0do8TUUgPS9В общем и целом, тут все то же самое. Первое отличие в образе, в котором будет формироваться контейнер: image: postgres:14
Второе отличие — в секции ports. Мы ставим другой порт — 5432 и ставим ему другое имя — pg.
Третье отличие — в переменной окружения:
env:
- name: POSTGRES_PASSWORD
value: gYwOKJZaR0do8TUUgPS9Какие переменные окружения принимает контейнер, можно посмотреть на DockerHub.
Сразу задеплоим все командной kubectl -n ktswebinar apply -f .kube/
Посмотрев deployment, убедимся, что у нас все запустилось:
Также увидим, что у нас запущено два пода:
Теперь нам нужно связать приложение с контейнером БД. Для этого в settings.py мы прописали, что с помощью переменной окружения у нас есть возможность переопределить url для postgres:
DATABASES = {
'default': env.db(default='postgresql://postgres:postgres@127.0.0.1:5432/ktswebinar'),Сервис. Манифест pg-service
Сейчас нам нужно немного остановиться и разобрать такое понятие, как сервис. Посмотрим на наши deployment в режиме wide, который показывает IP-адреса подов:
Каждый раз, когда поднимается очередной под, ему присваивается IP-адрес в локальной сети кластеров. Проблема в том, что если понадобится удалить под и создать его заново, его адрес изменится. Из-за этого мы никак не можем ориентироваться на IP-адреса подов. Нам нужно что-то более статичное.
Под может удалиться по множеству причин. Во-первых, его случайно можно удалить руками. Возможно, ему не хватает ресурсов, и Kubernetes считает, что его нужно перенести на другую машину. Он может просто упасть — по любой причине.
Такая ненадежность IP-адресов подов — одна из причин, по которой придумана сущность service:
apiVersion: v1
kind: Service
metadata:
name: pg
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: pg
spec:
type: ClusterIP
ports:
- port: 5432
targetPort: pg
protocol: TCP
name: pg
selector:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: pgservice объединяет несколько подов в один сетевой объект.
Я хотел бы особо обратить ваше внимание на секцию selector. Она похоже на стандартную секцию deployment, и выполняет точно такую же задачу: находит список подов с совпадающим списком лейблов и считает, что они принадлежат этому сервису.
Также в service есть порты. Один из портов будет тот же, что в deployment для Postgres — 5432.
Обратите внимание на targetPort, для которого указано значение pg. Каждый раз, когда вы будете обращаться к service, вы будете обращаться к targetPort какого-то из подов, которые объединены в этот сервис.
Выполним kubectl -n ktswebinar apply -f .kube/ и увидим, что service создан:
Посмотреть подробнее можно, выполнив команду kubectl -n ktswebinar get service:
У нас создался service с именем pg. Он получил какой-то IP-адрес, который теперь стабилен: каждый раз, когда мы будем обращаться к этому IP-адресу, мы будем попадать в какой-то из подов этого сервиса.
Но если вы удалите сам service, его адрес тоже изменится. Поэтому общий совет таков: не пользуйтесь IP-адресами. В Kubernetes есть отличная возможность использовать имена сервисов для их идентификации.
Для этого мы допишем 3 строчки в наш app.deployment:
env:
- name: DATABASE_URL
value: postgresql://postgres:gYwOKJZaR0do8TUUgPS9@pg:5432/postgresВ этом дополнении:
username = postgres
пароль — тот же, что мы создали в pg.deplpoyment
host, к которому мы будем подключаться — имя сервиса
порт, на который подключаемся
БД
Примерно так же все происходит в Docker Compose.
Вы можете использовать просто имя сервиса, если он находится в вашем же namespasce. Вы также можете подключиться к сервису в другом namespace, но для этого понадобится немного другой синтаксис.
Сейчас мы создали service и прописали в нашем deployment переменную окружения DATABASE_URL. Теперь мы подключаемся к существующей базе данных.
Выполним kubectl -n ktswebinar apply -f .kube/ и увидим, что deployment.apps/ktswebinar изменился:
В любой момент вы можете посмотреть на задеплоенный манифест следующей командой: kubectl -n ktswebinar get deploy
После этого вам нужно указать имя манифеста и дописать -o yaml: kubectl -n ktswebinar get deploy ktswebinar -o yaml
У вас будет полностью выведен манифест с дополнительными полями.
Сейчас самое время еще раз посмотреть на наши поды и проверить состояние системы через port-forward:
Все работает, но мы не применили миграции. Поэтому сущности DjangoSession пока не существует:
Как применять миграции. Манифест app-migrations
Один из вариантов — применять их на старте контейнера. Это не лучший выбор, потому что если у вас несколько реплик, они начнут применять миграции все одновременно, и все это закончится конфликтом.
Поэтому нужен отдельный процесс, который будет применять миграции. Создадим этот процесс и введем еще одну новую сущность — job.
Фактически это тот же самый под. Но идея пода в том, что если он завершается — неважно, успешно или нет — Kubernetes попытается его перезапустить. Но сейчас нам нужен процесс, который нужно перезапускать только при неуспешном завершении, а при успешном — не нужно.
Назовем джоб-файл app-migrations.yaml и посмотрим на его спецификацию:
apiVersion: batch/v1
kind: Job
metadata:
name: migrations
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: migrations
spec:
activeDeadlineSeconds: 120
template:
metadata:
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: migrations
spec:
restartPolicy: Never
containers:
- name: migrations
image: igorcoding/ktswebinar:1.0.4
imagePullPolicy: IfNotPresent
command:
- python
- manage.py
- migrate
env:
- name: DATABASE_URL
value: postgresql://postgres:gYwOKJZaR0do8TUUgPS9@pg:5432/postgresОтличия от deployment в другой API-версии и в том, что параметр kind равен Job. Все остальное очень похоже на deployment: имя, лейблы, spec.
template описывает, какой под нам нужен, и все, что стоит ниже этой строки — снова спецификация пода.
Поэтому ничего нового тут нет, и единственное, что меняется — это поведение.
Контейнер мы назвали migrations и написали новую версию 1.0.4. Но мы будем запускать другую команду. По умолчанию при запуске контейнера запускается команда, которая записана в конце Docker-файла. А нам нужна другая:
command:
- python
- manage.py
- migrateЕще нам снова нужно прописать в переменной окружения, где находится наша БД. Если этого не сделать, мы будем подключаться в адрес по стандартным настройкам 127.0.0.1.
Выполним kubectl -n ktswebinar apply -f .kube/ и увидим, что создалась миграция:
Смотрим, что происходило с подами:
У нас запущен новый под migrations, в котором не запущено ни одного контейнера. Кроме этого, он имеет статус Completed. Такой статус могут иметь только job и cronjob.
Посмотрим на логи этого пода, чтобы понять, что в итоге нам дал его запуск. Миграции успешно применились:
Единственным минусом job является то, что сами по себе они не уничтожаются, и создать еще одну такую же с таким же именем нельзя.
В базе данных у нас нет еще ни одного пользователя. Самое время его создать.
Для этого можно зайти прямо внутрь запущенного контейнера и выполнить любое действие. Нам понадобится такая же команда, как в Docker — exec:
Нужно указать контейнер, под, в который мы хотим перейти, и команду, которую мы выполним в этом контейнере. В нашем случае это bash.
Мы оказались внутри контейнера:
Теперь выполним команду ./manage.py createsuperuser, введем почту и пароль:
Выйдем из контейнера командой exit и запустим port-forward. Зайдем в админку и введем наши данные:
Наша база данных и приложение успешно работают.
Ingress Controller. Манифест app-service
Мы почти все подготовили. У нас есть:
приложение
job, которая стартует миграции для приведения схем БД в нужное состояние
сама БД, в которой мы будем хранить данные
Нам остается опубликовать этот сервис, чтобы мы могли обратиться к нему хотя бы по какому-то IP-адресу и DNS-имени. Для этого существует несколько способов.
Первый из них — NodePort. Его суть в том, что каждый узел кластера открывает какой-то случайный порт и перенаправляет трафик в данный сервис.
Но нас интересует простой ClusterIP — такой же, как мы создавали для Postgres.
Скопируем service.
apiVersion: v1
kind: Service
metadata:
name: ktswebinar
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: web
spec:
type: ClusterIP
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
selector:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: webМы создаем новый сетевой объект, который просит выделить стабильный IP-адрес для сервиса с именем ktswebinar. При обращении на порт 80 мы будем проксировать трафик на порт с названием http в подах. Как вы помните, это порт 8000. Так происходит небольшая схема портов.
Выполним kubectl -n ktswebinar apply -f .kube/ и посмотрим, что получится:
Чтобы пробросить трафик в кластер, нужно будет разобрать еще пару сущностей — Ingress Controller и Ingress.
Помимо того, что у нас создался кластер, создался также Ingress Controller. В нашем случае это nginx.
Ingress Controller будет балансировать трафик между разными сервисами. Его задача — принять запрос для конкретного домена на конкретный url и направить его в нужный сервис. Это некая мета-сущность, из которой будет формироваться настройка nginx.
VK Cloud Solutions при создании кластера создали также балансировщик. Если зайти в Виртуальные сети → Балансировщик нагрузки, мы увидим выделенный балансировщик и его IP-адрес:
Если мы придем на этот адрес, мы придем прямо в наш кластер и попадаем на default backend. Все запросы, которые не совпадают ни с одним доменом, попадают сюда:
Чтобы посмотреть на эти запросы, сначала нужно вернуться в консоль и выполнить команду kubectl -n ingress-nginx get pod:
Здесь есть под, который называется controller. Если мы заглянем в его логи, мы увидим именно эти запросы, который ушли на default backend.
В итоге у нас есть какой-то внешний балансировщик, физически поднятый где-то в датацентре VK Cloud Solutions. Он принимает на себя весь трафик и потом направляет в наш кластер в Ingress Controller.
Если мы посмотрим на сервисы ingress-nginx, мы увидим один сервис, который называется LoadBalancer:
Наш балансировщик появился именно из-за того, что у нас в кластере появился сервис с типом LoadBalancer. Когда создается сервис такого типа, облачный провайдер создает физический балансировщик и возвращает его IP-адрес в Kubernetes. Так, обращаясь на его внешний IP-адрес, мы попадем в сервис ingress-nginx-controller, и он дальше уже направит трафик в нужные поды.
Ingress. Манифест ingress
Создадим новый ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ktswebinar
labels:
app.kubernetes.io/name: ktswebinar
app.kubernetes.io/component: web
spec:
rules:
- host: ktswebinar.ktsdev.ru
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: ktswebinar
port:
name: httpУ нее снова другие GVK, но для нас это уже неважно.
В секции rules описаны правила, по которым нужно будет запроксировать трафик. Сейчас тут написано, что если запрос приходит по host: ktswebinar.ktsdev.ru, то его надо направить в сервис ktswebinar.
Это позволяет обслуживать несколько доменов одним Kubernetes-кластером.
Давайте посмотрим одновременно на ingress и на service:
По host:ktswebinar.ktsdev.ru мы попадем в service, который на порт 80 запроксирует трафик http дальше на deployment, который находится в порт 8000 соответствующего пода.
Суть Ingress такова, что мы создаем некоторую сущность, из которой сформируется конфиг nginx для Ingress Controller, который будет проксировать трафик.
Давайте применим все изменения через kubectl -n ktswebinar apply -f .kube/:
Обратимся к адресу ktswebinar.ktsdev.ru и увидим, что все работает:
Проверим также админку Django и убедимся, что здесь тоже все в порядке:
Заключение
Короткое резюме:
Мы разобрали, что такое Pod и Deployment
Обсудили сетевое взаимодействие сервисов в Kubernetes
Разложили приложение Django + PostrgreSQL в Kubernetes-кластере
Научились создавать Kubernetes-кластер в VK Cloud Solutions
Повторим основные шаги процесса.
У нас есть приложение, суть которого знать необязательно. Главное, чтобы оно было упаковано в Docker-образ, который можно запустить
В нашем случае образ был запушен на DockerHub
Мы создали сущность deployment, которая отвечает за то, чтобы запустить наш контейнер. Вы можете указать полный путь до образа
Создали и запустили контейнер с БД. Связали его с контейнером приложения
Создали сущности, которые являются сетевыми абстракциями под названиями service: чтобы открыть наше приложение наружу и для нашей БД, или для связи приложения с БД. Это нужно потому, что поды имеют непостоянные IP-адреса и имена
Поскольку наше приложение зависит от БД, нам нужно накатить миграции. Для этого мы создали job-сущность migrations, которая запустится и выполнит определенную команду в нашем образе. Также мы передаем ей url до БД
Последним шагом мы создали мета-конфиг nginx, наш ingress. Его заметил Ingress Contoller и создал из этого правило для балансировки.
Теперь рассмотрим, что можно улучшить в нашем деплое:
Мы два раза указывали образ — в миграциях и деплойменте. Чтобы не повторяться, нужен шаблонизатор: Helm, Kustomize, Jsonnet
Наши пароли в открытом виде в манифестах. Лучше выносить их в secret
Всю статику лучше собрать в отдельный контейнер и запустить его в виде контейнера nginx
Желательно, чтобы приложение было с https — выписывание сертификатов через cert-manager
Если под с Postgres вдруг перезапустится, то мы потеряем все наши данные. Поэтому нам нужны Volume для персистентности. Также неплохо было бы поднимать Postgres в кластерном режиме, если один нод откажет, трафик перенаправлялся в другой.
Где еще поучиться Kubernetes
13-го декабря мы в KTS запускаем курс «Деплой приложений в Kubernetes».
На курсе студенты окунутся в тонкости контейнеризации и оркестрации, поймут, почему Kubernetes стал де-факто стандартом в оркестрации. Вы познакомитесь со всеми нужными для деплоя абстракциями Kubernetes, а также дополнительными инструментами, облегчающими деплой, например, Helm.
Приходите!
