Делаем плавный скролл в нагруженных таблицах
Предисловие
Как часто вы обращали внимание на плавный скролл в мобильных приложениях?
Кажется, что это очень не важный элемент при их разработке. Но в действительности это не так. Для многих пользователей важен перфоманс — плавность прокрутки и производительность отрисовки, — потому что это обеспечивает комфортное использование приложения.
Получается, реализация плавного скролла является одной из наших приоритетных задач, решить которую очень непросто.
В этой статье я предлагаю рассмотреть технические аспекты работы со сложными таблицами. Кстати говоря, работа с коллекциями будет аналогична.
Демо-проект
Для начала создадим демо-проект — новостное приложение, которое получает данные — статьи — через определенное API и отображает их содержимое в таблице. В ее ячейках большое количество элементов: картинка статьи, заголовок и дата публикации, а также сложная отрисовка в виде градиента, скруглений и теней.
Взглянем на состояние приложения.
Заметим, что есть фризы. Создается ощущение «замедленной» прокрутки. Но, чтобы точно убедиться, что действительно существует проблема отрисовки ленты, необходимо провести тестирование и получить результаты скорости прокрутки ячеек таблицы. Ниже приведены результаты, полученные при помощи инструмента CPU Profiler.
Таблица 1. Результаты производительности стартового проекта
Interval | Frames Per Second | GPU Hardware Utilization |
00:06.082.337 | 38 | 12.0% |
00:07.093.210 | 41 | 16.0% |
00:08.100.924 | 50 | 16.0% |
00:09.110.918 | 48 | 16.0% |
00:10.123.107 | 43 | 16.0% |
00:11.133.694 | 47 | 16.0% |
00:12.147.856 | 44 | 16.0% |
00:13.158.400 | 37 | 9.0% |
По результатам скорости прокрутки видно, что производительность необходимо увеличивать.
Механизмы увеличения производительности
Первая и самая очевидная оптимизация заключается в переиспользовании всего лишь нескольких экземпляров ячеек/хедеров/футеров в таблице.
Создание объекта ячейки для iOS является достаточно дорогостоящей операцией. Поэтому, если создавать новую ячейку каждый раз, как пользователь будет прокручивать список вверх и вниз, будет страдать общая производительность.
Стандартный способ исправить этот недостаток заключается в том, чтобы повторно использовать ячейку после того, как она выйдет за границы экрана.
 Рис. 1. Реализация переиспользования ячеек в коде.
Рис. 1. Реализация переиспользования ячеек в коде.
Проведем промежуточное тестирование и посмотрим, поменялись ли значения скорости прокрутки.
Таблица 2. Результаты производительности после реализации переиспользования ячеек.
Interval | Frames Per Second | GPU Hardware Utilization |
00:04.041.060 | 47 | 10.0% |
00:05.060.765 | 53 | 14.0% |
00:06.073.439 | 55 | 15.0% |
00:07.086.636 | 50 | 15.0% |
00:08.095.308 | 52 | 15.0% |
00:09.110.044 | 54 | 15.0% |
00:10.122.400 | 46 | 12.0% |
По результатам реализации переиспользования ячеек в таблице можно заметить, что производительность выросла. Однако все еще оставляет желать лучшего.
Далее в рамках оптимизации можно рассмотреть вычисление высот ячеек максимально быстрым способом. Она абсолютно бессмысленна в случае использования ячеек с одинаковой высотой во всей таблице, но крайне существенно может сказаться на производительности и плавности прокрутки при неправильном использовании в случае с динамической высотой ячеек.
Следует отметить, что, начиная с iOS 8, нам доступен автоматический способ, который, используя механизм Auto Layout, выставляет значение высоты каждой конкретной ячейке таблицы.
Auto Layout — это такой подход от Apple, имеющий API в виде системы ограничений (констрейнтов), под капотом которого система линейных уравнений Cassowary. И чем больше элементов лежит в вашей ячейке, тем больше уравнений приходится решать для расчета их высот. В оригинале для решений этой системы используется симплекс-метод, который имеет экспоненциальную сложность. Однако, по заверениям Apple, он имеет линейную сложность на простых отображениях. Решениями системы уравнений являются итоговые фреймы.
Из недостатков механизма Auto Layout можно выделить следующее:
Работает только в Main-потоке. Скорее всего, это сделано для синхронизации решений системы уравнений и свойством frame-представлений. Очевидно, что если бы решения системы вычислялись в отдельной очереди, то затем пришлось бы синхронизировать полученные решения — рассчитанные размеры и положения — с UI-потоком для их выставления представлениям;
На сложных представлениях работает медленно. То есть чем больше представлений добавлено в ваши ячейки как subview, тем больше будет расчетов и, соответственно, медленнее прокрутка;
Кеширование решений может занимать большой объем памяти.
Помимо механизма Auto Layout, существует другой способ расчета layout. Это ручной подсчет размеров и положений. Он считается самым производительным.
Его достоинство — возможность использования в Background-очереди. При этом если не использовать какие-то сложные вычисления, то он будет работать очень быстро. Все-таки сложить/вычесть/умножить/поделить несколько чисел проще, а значит, быстрее, чем решать системы линейных уравнений.
Однако проблемой же является то, что приходится реализовывать все вычисления самим.
Когда использовать ручной подсчет? Ответ прост. Когда достигли ограничения производительности Auto Layout — например, на отображении сложных элементов.
Как использовать ручной расчет? Кажется, что с размерами картинок, кнопок и других UI-компонентов, таких как свитчер или степпер, проблем быть не должно. Их размер можно задать однозначно согласно макетам, и он не будет меняться в зависимости от размеров устройства. А что с текстом? Его размер динамичен: высота, очевидно, должна меняться в соответствии с шириной самого текста и шрифта. Чтобы рассчитать размер текста в элементе, существует несколько подходов:
Стандартные методы UIKit. Это метод sizeThatFits и св-во intrinsicContentSize. Они возвращают актуальный размер для соответствующих представлений.
 Рис. 2. intrinsicContentSize
Рис. 2. intrinsicContentSize
Представления обычно содержат контент. Установка свойства intrinsicContentSize позволяет ему определять, какой размер он хотел бы иметь на основе своего содержимого. По умолчанию некоторые дочерние компоненты UIView имеют intrinsicContentSize — например, UILabel. Базовый UIView не имеет этого свойства, и если попытаться его распечатать, то результат будет {-1, -1}. Ширина и высота intrinsicContentSizeопределяют константы ограничений, которые система неявно добавляет на наше представление. Этот механизм очень удобен, он позволяет уменьшать количество явных ограничений, что упрощает использование Auto Layout.
Как видно на картинке ниже, при подсчете размеров с помощью Auto Layout система применяет эти методы. Их не следует использовать в Background-очереди. Достаточно вызывать методы при отображении элементов, не содержащих скролл.

Метод NSAttributedString/NSString boundingRect фреймворка CoreFoundation, который получает набор аргументов, такие как размер, в который нужно вписать текст, атрибуты — например, шрифт, и в результате возвращает размер соответствующего текста. То есть можно заранее, не подсчитывая размер UILabel, рассчитывать размер строки, зная ширину, в которую она вписывается. Этот метод можно использовать в Background-очереди, к тому же быстро работает.
TextKit, который лежит в основе стандартных элементов, таких как UILabel, UITextView, UITextField. TextKit — это система классов NSLayoutManager, NSTextStorage и NSTextContainer. Можно использовать, когда какой-то сложный Layout текста или для обтекания элемента текстом. Также может использоваться в Background-очереди.
Таким образом, реализуем вычисление высот ячеек максимально быстрым по времени способом.
 Рис. 4. Реализация layout.
Рис. 4. Реализация layout.
Для оптимизации расчета высот ячеек был выбран следующий подход: заранее, на этапе получения моделей, в Background-очереди вычисляются значения высоты каждой ячейки и сохраняются в DataSource.
Необходимость сохранения высоты строк обусловлена тем, что представление таблицы запрашивает эту информацию всякий раз, когда надо создать новую ячейку. Если высота ячейки фиксированная, беспокоиться не о чем. Однако, если она варьируется, вычисление ее должно выполняться достаточно быстро.
Логика работы по вычислению размеров ячеек выглядит следующим образом:
Таблица 3. Получение данных и их отображение.
Background-queue |
Получение данных и их парсинг |
Расчет фрейма (положение и размеры отображения) |
Описание иерархии отображения и составление DataSource для отображения полученных данных в таблице |
Main-queue |
Заполнение ячеек таблицы на основе ранее созданного DataSource и их отрисовка |
Обработка UI events |
Взглянем теперь на производительность.
Таблица 4. Результаты производительности после решения вычислять высоту ячеек таблицы вручную на Background-очереди.
Interval | Frames Per Second | GPU Hardware Utilization |
00:07.068.100 | 56 | 10.0% |
00:08.088.675 | 56 | 13.0% |
00:09.096.093 | 58 | 13.0% |
00:10.107.336 | 57 | 13.0% |
00:11.116.214 | 58 | 13.0% |
00:12.125.404 | 57 | 13.0% |
00:13.140.198 | 57 | 13.0% |
00:14.156.079 | 55 | 9.0% |
По результатам производительности видно, что скорость отображения в кадрах в секунду теперь в пределах 55–58. Однако еще не совсем близка к 60. Желательно, чтобы значения были в пределах 57–60. Почему все равно лагает? Получается, необходимо постараться еще как-то разгрузить СPU, так как, очевидно, еще остались дорогие для него операции, выполняемые на Render Server.
И вот мы переходим к третьему способу оптимизации — использованию фреймворка CoreAnimation.
Итак, давайте разберемся, как работает построение отображения в системе.
Для отображения в iOS используется ранее упомянутый фреймворк. И все наше отображение — это иерархия слоев CALayer. Эти слои образуют дерево. А для изменения текущего дерева слоев используется CATransaction. То есть любое изменение фрейма или других параметров слоя CALayer, а соответственно, и представления в целом, оборачивается в транзакцию.
Транзакция CATransaction — это группа изменений.
Таблица 5. Стек вызовов.
0 CustomTableView layoutSubviews () |
1 @objc CustomTableView.layoutSubviews () |
2 -[UIView (CALayerDelegate) layoutSublayersOfLayer:] |
3 -[CALayer layoutSublayers] |
4 CA: Layer: layout_if_needed (CA: Transaction*) |
5 CA: Context: commit_transaction (CA: Transaction*) |
6 CA: Transaction: commit () |
… |
11 _CFRunLoopRun |
12 CFRunLoopRunSpecific |
13 UIApplicationMain |
14 main |
15 start_sim |
16 start |
Выше представлен стек вызовов при скролле таблицы. Обратим внимание, что, перед тем, как вызывается метод layoutSubview, срабатывает CATransaction.commit. Но все начинается с RunLoop.
 Рис. 5. RunLoop.
Рис. 5. RunLoop.
RunLoop на главном потоке — бесконечный цикл обработки событий, никак не синхронизированный с частотой обновления экрана или еще чем-то. На нем обрабатываются различные источники данных для нашего приложения. Это события ввода — жесты пользователя. Здесь же обрабатываются таймеры и другие источники.
Так вот, большинство транзакций создаются на каждой итерации RunLoop, если у нас есть какое-то изменение слоя, а затем коммитятся.
CATransaction.commit — это метод для фиксации всех изменений, внесенных в ходе текущей транзакции. Здесь выполняется расчет layout всех представлений, помеченных как setNeedsLayout. В данном случае таким помеченным представлением является таблица CustomTableView, у которой вызывается layoutSubviews. В ней происходит переиспользование ячеек, вызов методов делегата и т. д. Также в коммите происходит Offscreen drawing — вызывается метод drawRect у всех представлений, помеченных как setNeedsDisplay. Стоит сказать, что все это происходит на главном потоке.
Таким образом, при скролле таблицы сам скролл обрабатывается RunLoop. Он помечает таблицу как setNeedsLayout. На следующей итерации RunLoop создает новую транзакцию и передает помеченную на предыдущей итерации таблицу в эту самую транзакцию, чтобы изменить offset таблицы, а далее коммитит эти изменения. Следом на главном процессоре происходит перерасчет layout для таблицы, и у нее вызывается layoutSubviews, который запускает методы делегата и dataSource. Тот, в свою очередь, вызывает heightForRowAt, и если этот метод не переопределен, то в работу вступает Auto Layout: он на основе контента ячейки создает систему уравнений и решает ее, возвращая высоту ячейки. Это увеличивает выполнение коммита транзакции, нагрузку на процессор и производительность соответственно.
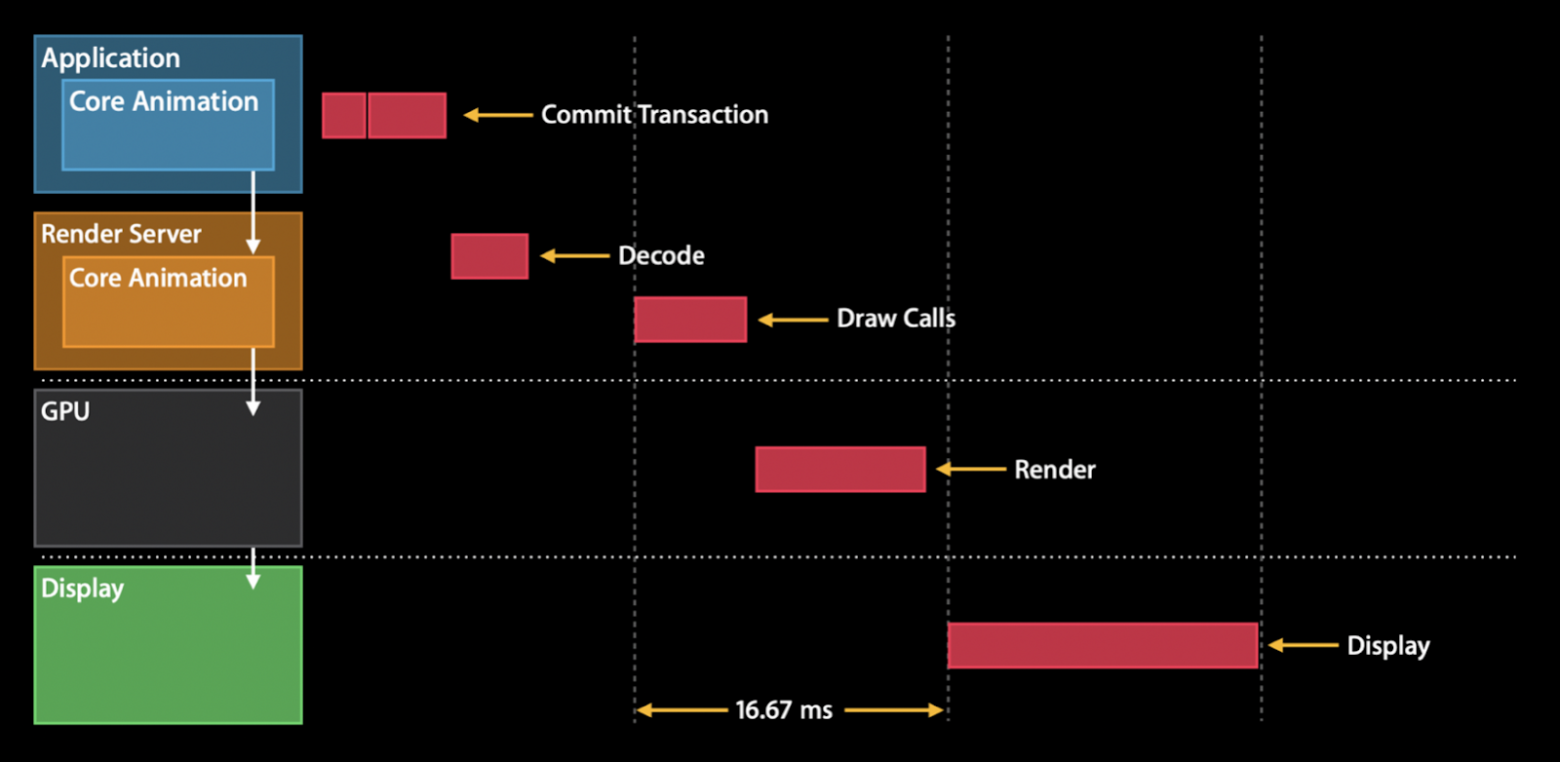 Рис. 6. Rendering Pipeline.
Рис. 6. Rendering Pipeline.
То есть процесс формирования кадра системой выглядит следующим образом: приложение обрабатывает событие — например, скролл таблицы, далее создается транзакция, описывающая изменение отображения, коммитится и передается в Render Server. На этом работа по формированию кадра в приложении заканчивается.
Render Server — отдельный системный процесс, в котором так же, как и в процессе приложения, работает Core Animation. Render Server декодирует полученную транзакцию, формирует вызовы для видеочипа, вызывает эти команды на видеочипе с использованием OpenGL или Metal. До этого момента все вычисления происходили в CPU, но дальше работа переходит в руки GPU. Видеочип рендерит новый кадр и размещает его на экране. Получается, чем дольше CATransaction.commit, тем хуже производительность.
Долгим он может быть из-за следующих проблем:
Во-первых, из-за дорогих операций в layoutSubviews или сложной иерархии отображаемых представлений. Решение проблемы — максимально упростить этот метод, то есть вынести все расчеты в фоновый поток.
Также дорого, если много работы в drawRect. Решение — использовать стандартные компоненты более низкоуровневого фреймворка, чем UIKit, — Core Animation. Таковыми являются CALayer, CAGradientLayer, CAShapeLayer и др. Также для решения данной проблемы у слоя есть свойство drawsAsynchronously — значение, указывающее, откладываются ли команды отрисовки и обрабатываются ли они асинхронно в фоновом потоке. Когда данное значение — истина, то объект CGContext передается в метод drawInContext, который может поставить в очередь переданные ему команды отрисовки, так что они будут выполняться позже (т. е. асинхронно с выполнением метода drawInContext).
Третьей проблемой является blending. Если используются полупрозрачные представления, то видеочипу нужно совершить тяжелую работу, чтобы вычислить сквозь все прозрачные/полупрозрачные слои итоговый цвет. Чтобы повысить производительность, надо либо избавиться от таких слоев, либо заранее отрисовать изображение в Background-очереди.
Еще одной проблемой является Offscreen rendering. Это такие явления, как скругления, тени и т. п. Во время прорисовки слоя GPU останавливает процесс рендеринга и передает управление CPU. В свою очередь, CPU выполняет все необходимые операции — например, cоздает тень и возвращает управление GPU с уже прорисованным слоем. GPU визуализирует его и процесс прорисовки продолжается. Кроме того, offscreen rendering требует выделения дополнительной памяти для так называемого резервного хранилища. Чтобы решить данную проблему, можно отрисовать эти явления заранее.
Применим вышесказанное в коде.

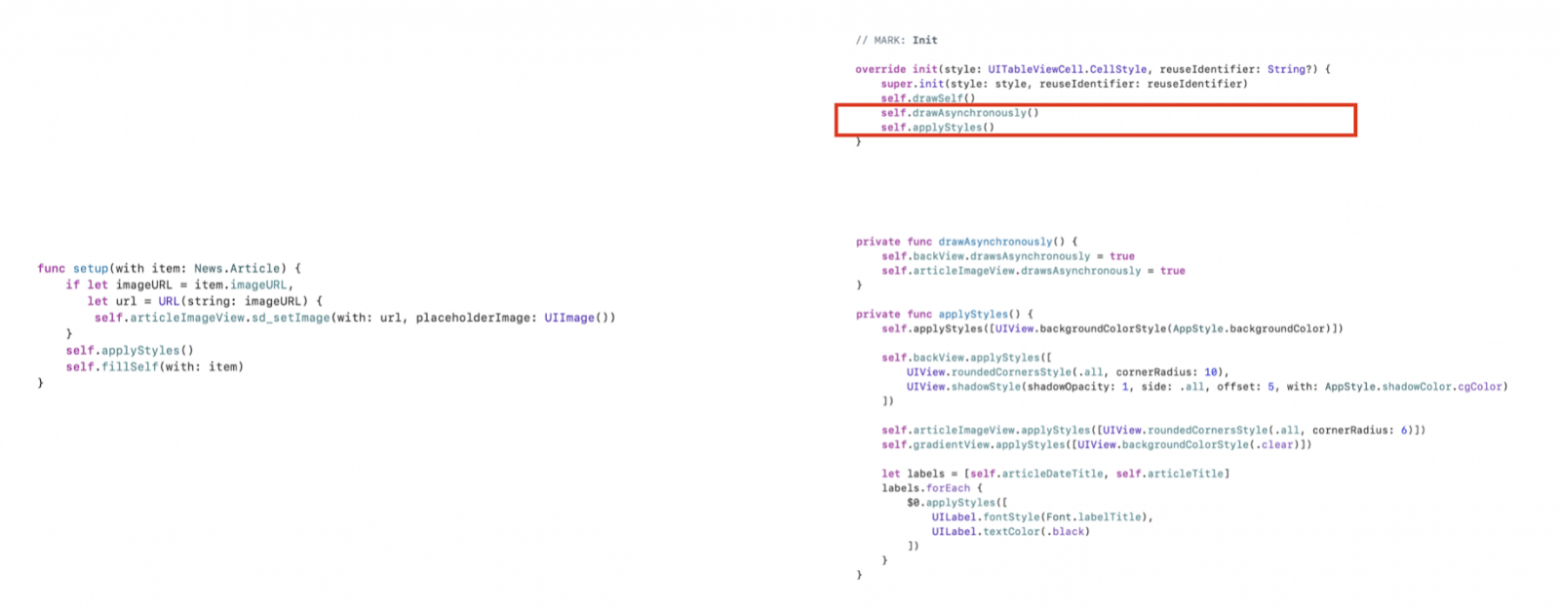 Рис. 7. Разгрузка CPU и GPU.
Рис. 7. Разгрузка CPU и GPU.
Сначала избавимся от переопределения функции drawRect в GradientView. Будем использовать стандартный элемент CAGradientLayer. Далее определим свойство drawsAsynchronously в true в тех местах, где применяются изменения к слою (в кастомных представлениях, ячейках). Также вынесем скругление представления, добавление теней на нее, заливку и применение стилей к UILabel из метода setup ячейки в ее конструктор, поскольку метод cellForRowAt вызывается для каждой ячейки и должен работать как можно быстрее. И зададим свойства shouldRasterize и rasterizationScale у слоя представления, к которому применяем тени, поскольку, если оставить их по умолчанию, из-за этого будет проседать FPS.
Взглянем на приложение после всех оптимизаций и снимем показатели производительности.
Таблица 6. Результаты производительности после всех оптимизаций.
Interval | Frames Per Second | GPU Hardware Utilization |
00:05.010.100 | 57 | 9.0% |
00:06.086.567 | 58 | 11.0% |
00:07.105.606 | 58 | 11.0% |
00:08.121.715 | 59 | 11.0% |
00:09.133.421 | 59 | 11.0% |
00:10.143.054 | 59 | 11.0% |
00:11.163.998 | 59 | 11.0% |
00:12.185.049 | 58 | 10.0% |
Прокрутка плавная, никаких фризов не наблюдается. Из результатов видно, что значения скорости отображения в кадрах в секунду находятся в пределах 58–59, то есть практически равны 60, а время подготовки ячеек незначительно. Достигнув таких показателей, производительность прокрутки высокая, а сама она плавная.
Возникает лишь один вопрос: почему не достигается 60? Во-первых, немного влияет пагинация. Во-вторых, Auto Layout в ячейках таблицы. Если проверить работу оптимизации на более сильном устройстве — например, на iPhone 13 Pro (разумеется, ограничив частоту кадров до 60 возможных), то значения по производительности как раз достигнут 60.
Вывод
Рассмотренный пример показывает, насколько эффективно может быть применение инструментов оценки производительности для понимания сути проблемы и насколько она повышается после каждого шага оптимизации.
Повторное использование ячеек/хедеров и футеров — первый и важный шаг оптимизации;
Уменьшить общее время загрузки и вычислений, их перевод в Background-очереди — значит упростить объем подсчетов;
Использование стандартных компонентов Core Animation для отрисовки ячеек позволит существенно ускорить процесс отображения и повысить производительность;
Кеширование данных для ячеек;
Нет ничего плохого в комбинации Auto Layout и ручного подсчета. Там, где не хватает производительности — использовать ручной подсчет.
