DeepMind: обучения с подкреплением достаточно для достижения «настоящего» ИИ
Ученые из британской лаборатории искусственного интеллекта DeepMind в своей статье в Artificial Intelligence утверждают, что настоящий искусственный интеллект можно развить не в результате формулирования и решения сложных проблем, а в результате соблюдения принципа вознаграждения.
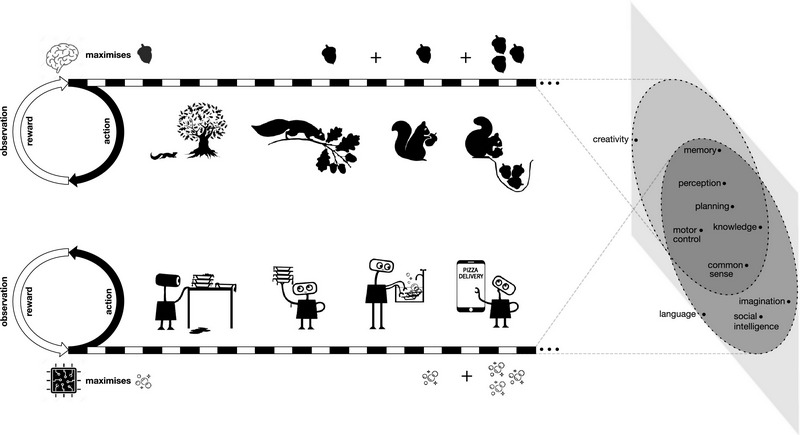 Иллюстрация потребности в минимизации голода / www.sciencedirect.com
Иллюстрация потребности в минимизации голода / www.sciencedirect.comРабота под названием «Награды — этого достаточно», которая все еще находится в стадии предварительной проверки, посвящена эволюции естественного интеллекта, а также анализу уроков из недавних достижений в области ИИ. Авторы предполагают, что максимизации вознаграждения и опыта проб и ошибок достаточно, чтобы развить «интеллектуальное поведение» машин. Из этого они делают вывод, что обучение с подкреплением, основанное на максимизации вознаграждения, может привести к развитию реального искусственного интеллекта.
Ранее человеческое понимание системы зрения млекопитающих привело к появлению систем искусственного интеллекта, которые могут классифицировать изображения, определять местонахождение объектов на фотографиях, границы между объектами и другое. Человеческое понимание языка помогло в разработке различных систем обработки естественного языка, таких как ответы на вопросы, генерация текста и машинный перевод.
Однако все эти системы разработаны для выполнения определенных задач и не демонстрируют общие способности. Некоторые ученые отрасли считают, что объединение нескольких специализированных модулей ИИ приведет к созданию интеллектуальных систем. Недавно исследователи из Пекинской академии искусственного интеллекта представили генеративную модель глубокого обучения Wu Dao со 1,75 трлн параметров. Она может выполнять задачи по обработке естественного языка, генерации текста, распознаванию и созданию изображений, генерировать альтернативный текст на основе статического изображения и почти фотореалистичные изображения на основе описаний на естественном языке. Wu Dao также продемонстрировала свою способность предсказывать трехмерные структуры белков.
Другой подход к созданию ИИ, предложенный исследователями DeepMind, заключается в создании «цели максимизации вознаграждения, чтобы управлять поведением». Они отмечают, что этот механизм привел к эволюции живых существ со сложными способностями.
По словам авторов работы, способности, связанные с интеллектом, возникают как решение единственной цели максимизации вознаграждения, и это обеспечивает более глубокое понимание самой потребности. При этом, когда каждая способность предназначена для достижения специализированной цели, то вопрос «почему» уходит на второй план.
Исследователи утверждают, что «самый масштабируемый» способ максимизировать вознаграждение — использовать агентов, которые учатся через взаимодействие с окружающей средой.
В своей статье они приводят несколько примеров того, как «интеллект и связанные с ним способности будут неявно возникать на службе максимизации одного из множества возможных сигналов вознаграждения».
Например, сенсорные навыки помогают выжить в сложных условиях. Распознавание объектов позволяет животным обнаруживать пищу, добычу, стаю и угрозы или находить тропы, укрытия и насесты. Сегментация изображений дает им возможность различать разные объекты и избегать фатальных ошибок, таких как падение со скалы или с ветки. Между тем, слух помогает обнаруживать угрозы. Обоняние, осязание и вкус также дают животному преимущество в выживании. Награды и окружающая среда формируют врожденные и усвоенные знания. Например, жвачные животные учатся укрываться от атак хищников.
Исследователи также обсуждают основанные на вознаграждении основы языка, социального интеллекта, имитации и, наконец, общего интеллекта, который они описывают как «максимизацию единственного вознаграждения в единой сложной среде».
Здесь они проводят аналогию между естественным интеллектом и ОИИ: «Поток опыта животного достаточно богат и разнообразен, поэтому может потребоваться гибкая способность для достижения огромного количества подцелей (таких как добывание пищи, борьба или бегство). Точно так же, если поток опыта искусственного агента достаточно богат, то многие цели (такие как время автономной работы или выживание) могут неявно требовать способности достичь столь же широкого разнообразия подцелей».
Обучение с подкреплением включает среды, агентов и вознаграждения. Выполняя действия, агент изменяет свое состояние и состояние среды. В зависимости от того, насколько эти действия влияют на цель, которую должен достичь агент, его награждают или наказывают. Во многих задачах обучения с подкреплением агент не имеет начальных знаний об окружающей среде и начинает свою работу с выполнения случайных действий. На основе фидбэка он учится настраивать разрабатывать политики, которые увеличат вознаграждение.
Исследователи уверены, что в процессе максимизации награды хороший агент обучения с подкреплением может в конечном итоге получить восприятие, язык и даже социальный интеллект.
В статье они приводят несколько примеров, показывающих, как агенты обучения с подкреплением смогли освоить общие навыки в играх и роботизированных средах.
Однако исследователи подчеркивают, что некоторые фундаментальные проблемы остаются нерешенными. Они говорят: «Мы не предлагаем никаких теоретических гарантий эффективности выборки агентов обучения с подкреплением». Известно, что обучение с подкреплением требует огромных объемов данных. Например, агенту могут потребоваться столетия игрового процесса, чтобы овладеть компьютерной игрой. И исследователи до сих пор не придумали, как создать системы обучения с подкреплением, которые могли бы обобщить знания в нескольких областях. Поэтому небольшие изменения в окружающей среде часто требуют полного переобучения модели.
Патрисия Черчленд, нейробиолог, философ и профессор Калифорнийского университета в Сан-Диего, описала идеи в статье как «очень тщательно разработанные». Однако она указала на возможные недостатки. По словам нейробиолога, исследователи DeepMind сосредотачиваются на личных выгодах в социальных взаимодействиях. Сама Черчленд недавно написала книгу о биологических истоках моральной интуиции и утверждает, что привязанность является мощным фактором в принятии социальных решений млекопитающими и птицами, поэтому животные подвергают себя большой опасности, защищая детей. Она говорит, что склонна рассматривать связь, а следовательно, и заботу о других, как расширение сферы действия того, что считается собой — «я и мое». «В таком случае, я думаю, небольшая модификация гипотезы статьи, позволяющая максимизировать вознаграждение для «я и мое», сработает очень хорошо», — говорит она.
Специалист по анализу данных Герберт Ройтблат оспорил позицию статьи о том, что простых механизмов обучения и опыта проб и ошибок достаточно для развития способностей, связанных с интеллектом. Он утверждает, что теории, представленные в статье, сталкиваются с рядом проблем, когда дело доходит до их реализации в реальной жизни: «Если нет ограничений по времени, тогда может быть достаточно обучения методом проб и ошибок, но в противном случае мы столкнемся с проблемой бесконечного числа обезьян, печатающих бесконечное количество времени».
Ройтблат — автор книги «Алгоритмов недостаточно», в которой он объясняет, почему все современные алгоритмы ИИ, включая обучение с подкреплением, требуют тщательной формулировки проблемы и представлений, созданных людьми. Он заметил, что в статье нет предложений по поводу того, как определять вознаграждение, действия и другие элементы обучения с подкреплением. «Обучение с подкреплением предполагает, что агент имеет конечный набор потенциальных действий. Указаны сигнал вознаграждения и функция ценности. Другими словами, проблема общего интеллекта состоит как раз в том, чтобы вносить вклад в те вещи, которые необходимы для обучения с подкреплением в качестве предварительного условия», — сказал Ройтблат.
