Архитектура in-memory СУБД: 10 лет опыта в одной статье
База данных в оперативной памяти — понятие не новое. Но оно слишком плотно ассоциируется со словами «кэш» и «не персистентный». Сегодня я расскажу, почему это не обязательно так. Решения в памяти имеют гораздо более широкое поле применения и гораздо более высокий уровень надежности, чем кажется на первый взгляд.
В статье я рассуждаю об архитектурных принципах решений в оперативной памяти. Как можно взять лучшее от in-memory мира — производительность невероятного уровня — и не жертвовать достоинствами дисковых реляционных систем. В первую очередь, надежность — как можно быть уверенным в сохранности данных.
Этот рассказ сжимает 10 лет опыта работы с in-memory решениями в один текст. Порог входа максимально низкий. Чтобы получить пользу от прочтения, вам не нужно иметь столько же лет опыта, достаточно базового понимания IT.
Введение
Меня зовут Владимир Перепелица, но я более известен как Mons Anderson. Я архитектор и продакт-менеджер Tarantool. Я уже много лет использую его в продакшене, например при создании объектного хранилища, совместимого с протоколом S3 [1]. Поэтому я его достаточно хорошо знаю его внутри и снаружи.
Для того чтобы понять технологию, полезно окунуться в историю. Мы узнаем, каким Tarantool был, через что он прошел, чем он является сегодня, сравним его с другими решениями, рассмотрим его функциональность, как он может работать по сети, что есть в экосистеме вокруг.
Этот пример позволит нам понять, какие преимущества вы можете получить от in-memory решений. Вы узнаете, как при этом не жертвовать надежностью, масштабом и удобством работы.
PS: это расшифровка открытого урока, адаптированная под статью. Если вам больше нравится слушать YouTube на 2х, ссылка на видео ждет вас в конце статьи [2].
История развития
Tarantool был создан внутренней командой разработки Mail.ru Group в 2008 году, изначально безо всякого прицела под опенсорс. Однако спустя два года эксплуатации внутри компании мы поняли, что продукт достаточно созрел для того, чтобы поделиться им в паблик. Так началась опенсорс история Tarantool.
commit 9b8dd7032d05e53ffcbde78d68ed3bd47f1d8081
Author: Yuriy Vostrikov
Date: Thu Aug 12 11:39:14 2010 +0400
Но для чего он был создан?
Первоначально Tarantool разрабатывался для социальной сети Мой Мир. Уже на тот момент мы были достаточно крупной компанией. Кластер из MySQL, который хранил профили, сессии и пользователей, стоил довольно много. Настолько много, что помимо производительности мы думали про деньги. Отсюда родилась история «Как сэкономить миллион долларов на базе данных» [3].
То есть Tarantool делался, чтобы сэкономить на огромных кластерах MySQL. Он проходил постепенную эволюцию: был просто кэшем, потом персистентным кэшем, а потом полноценной базой данных.
Заработав внутреннюю репутацию в одном проекте, он начал распространяться на другие: почта, рекламные баннеры, облако. В результате широкого применения внутри компании, новые проекты стали довольно часто по дефолту запускать именно на Tarantool.
Если проследить историю развития Tarantool, можно наблюдать следующую картину. Изначально Tarantool был in-memory кэшем. В свой момент зарождения почти ничем не отличался от memcached.
Чтобы решить проблемы холодного кэша, Tarantool стал персистентным. Дальше к нему добавили репликацию. Когда у нас есть персистентный кэш с репликацией, это уже key-value база данных. К этой key-value базе данных добавили индексы, то есть мы смогли использовать Tarantool почти как реляционную базу.
И дальше добавили Lua функции. Изначально это были хранимые процедуры для работы с данными. Затем Lua функции развились до кооперативного runtime и до сервера приложений.
Постепенно это все обрастало различными дополнительными фишками, возможностями, другими движками хранения. К сегодняшнему дню это уже мультипарадигменная база данных. Об этом подробнее.
Tarantool сегодня
Сегодня Tarantool — это платформа in-memory вычислений с гибкой схемой данных.
Tarantool можно и нужно использовать для создания высоконагруженных приложений. То есть реализовывать комплексные решения по хранению и обработке данных, а не только делать кэши. При этом он является не просто базой данных, а платформой, на которой можно что-то создавать.
Tarantool выпускается в двух версиях. Доступная большинству, самая понятная и известная — это опенсорсная версия. Tarantool разрабатывается под Simplified BSD лицензией, хостится целиком на GitHub в организации Tarantool.
Там у нас расположен сам Tarantool, его ядро, коннекторы к внешним системам, топологии, такие как шардинг или очереди; модули, библиотеки, как от команды разработчиков, так и от сообщества. Модули от сообщества вполне могут размещаться у нас.
Помимо опенсорсной версии в Tarantool есть еще энтерпрайз ветка. В первую очередь это поддержка, энтерпрайз-продукты, обучение, заказная разработка и консалтинг. Сегодня мы будем говорить об основной функциональности, которая есть во всех версиях продукта.
Tarantool сегодня — базовый компонент для database-centric приложений.
Как устроено ядро?
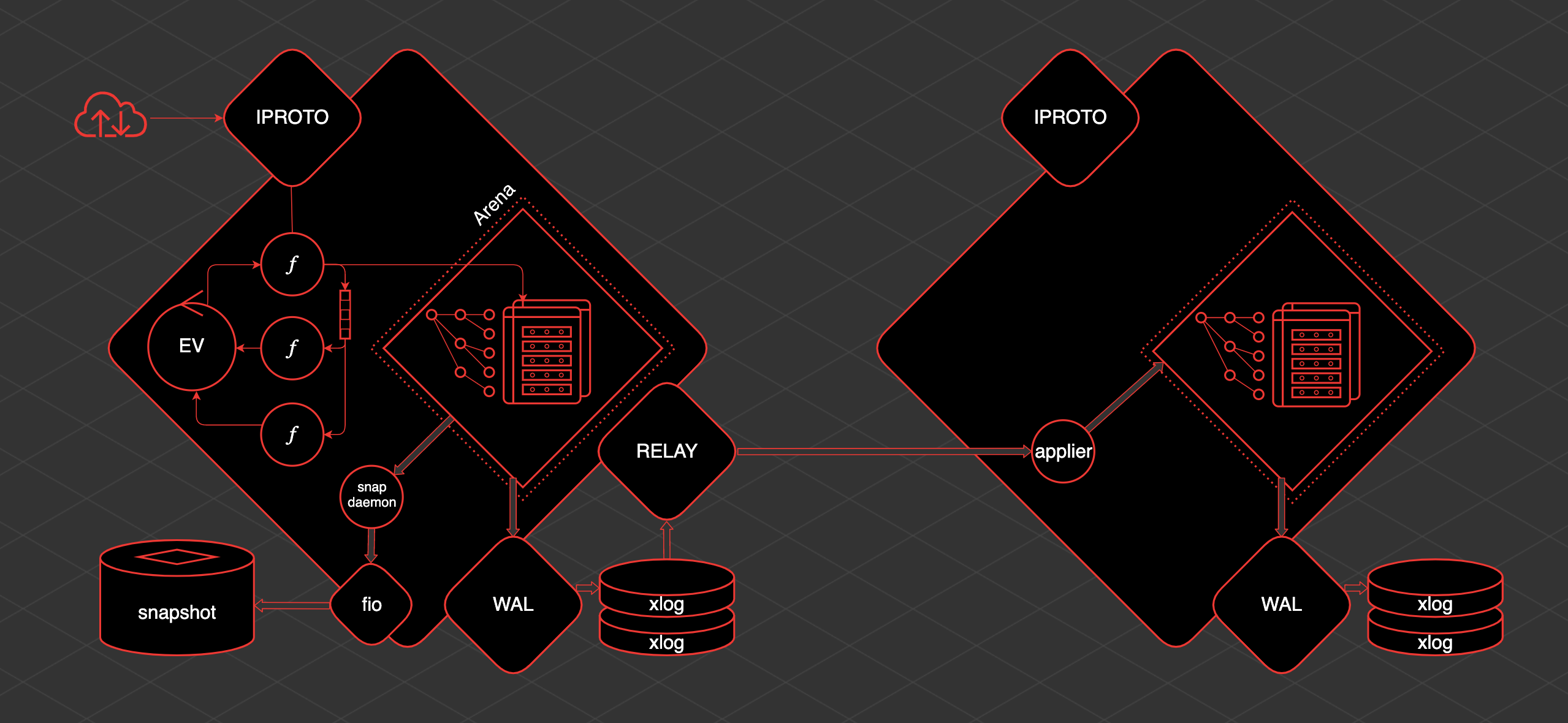
Основная идея, вокруг которой зарождался и развивался Tarantool — данные находятся в памяти. Доступ к этим данным всегда осуществляется из одного треда. Изменения, которые мы производим, линейно пишутся во Write Ahead Log.
К данным в памяти построены индексы. То есть доступ к данным у нас индексированный и предсказуемый. Периодически сохраняется snapshot этих данных. То, что пишется на диск, может быть реплицировано.
У Tarantool есть один основной транзакционный тред. Мы называем его TX тред. В рамках этого треда есть Arena. Это область памяти, выделяемая Tarantool для хранения данных. Данные хранятся в Tarantool в спейсах.
Спейс — это набор, коллекция единиц хранения — таплов. Тапл — это как строка в таблице. К этим данным построены индексы. За хранение и упорядочивание этого всего отвечает Arena и специализированные аллокаторы, которые в рамках Arena и работают.
- Тапл = строка
- Спейс = таблица
Также внутри TX треда работает событийный цикл, event loop. В рамках событийного цикла работают fiber«ы. Это кооперативные примитивы, из которых мы можем осуществлять коммуникацию со спейсами. Мы оттуда можем читать данные, можем создавать данные. Также fiber«ы могут взаимодействовать с событийным циклом и между собой напрямую или при помощи специальных примитивов — каналов.

Для того чтобы работать с пользователем извне, существует отдельный тред — iproto. iproto принимает запросы из сети, обрабатывает протокол Tarantool, передаёт запрос в TX и запускает пользовательский запрос в отдельном fiber«е.
Когда происходит какое-либо изменение данных, то отдельный тред, который называется WAL (от write ahead log), пишет файлы, которые называются xlog.
Когда Tarantool накапливает большое количество xlog, ему может быть сложно запуститься быстро. Поэтому для ускорения запуска существует периодическое сохранение snapshot. Для сохранения snapshot существует fiber, который называется snapshot daemon. Он читает консистентное содержимое всей Arena и пишет его на диск в файл snapshot.
Писать напрямую в диск из Tarantool нельзя, поскольку кооперативная многозадачность. Нельзя блокироваться, а диск — это блокирующая операция. Поэтому работа с диском ведется через отдельный пул тредов из библиотеки fio.

В Tarantool есть репликация и она организована довольно просто. Если есть еще одна реплика, то чтобы доставить данные до нее, поднимается еще один тред — relay. В его задачу входит читать xlog и отправлять их на реплики. На реплике запускается fiber applier, который получает изменения с удаленного узла и применяет их к Arena.
И эти изменения точно так же, как если бы они были сделаны локально, через WAL записываются в xlog. Зная, как это все устроено, вы можете понимать и предсказывать поведение того или иного участка Tarantool и понимать, что с этим делать.
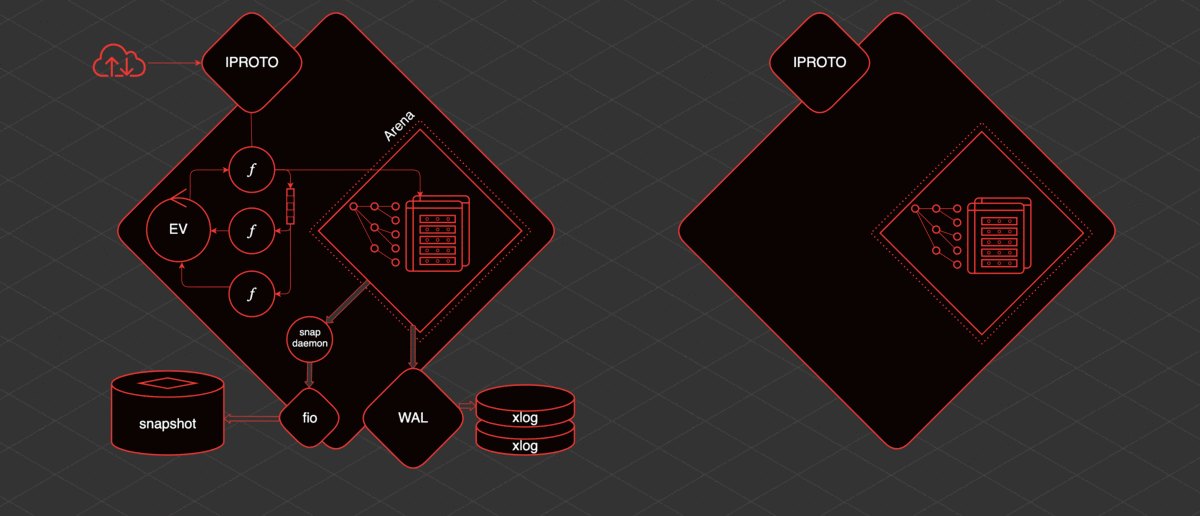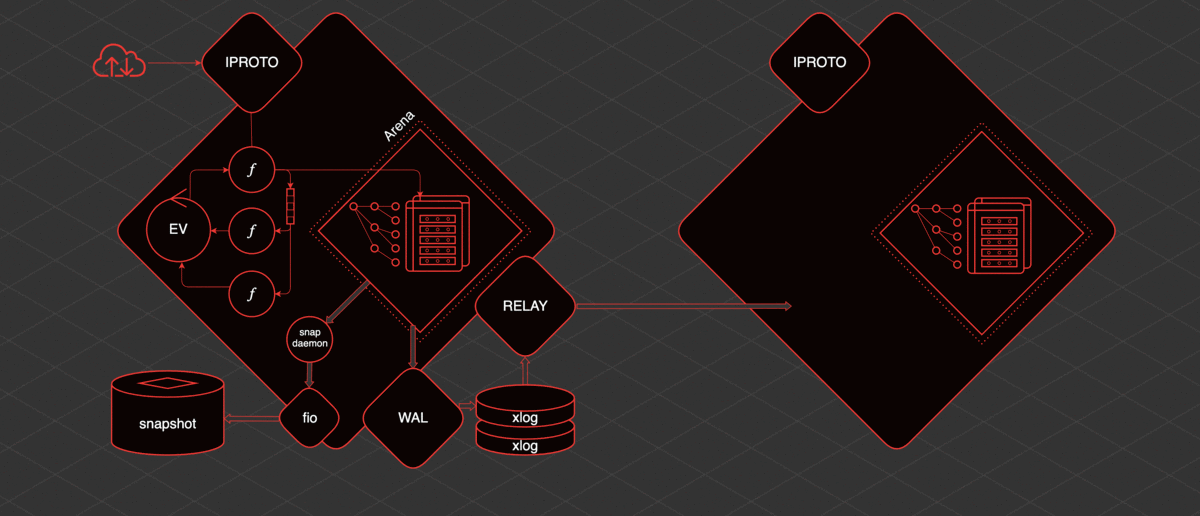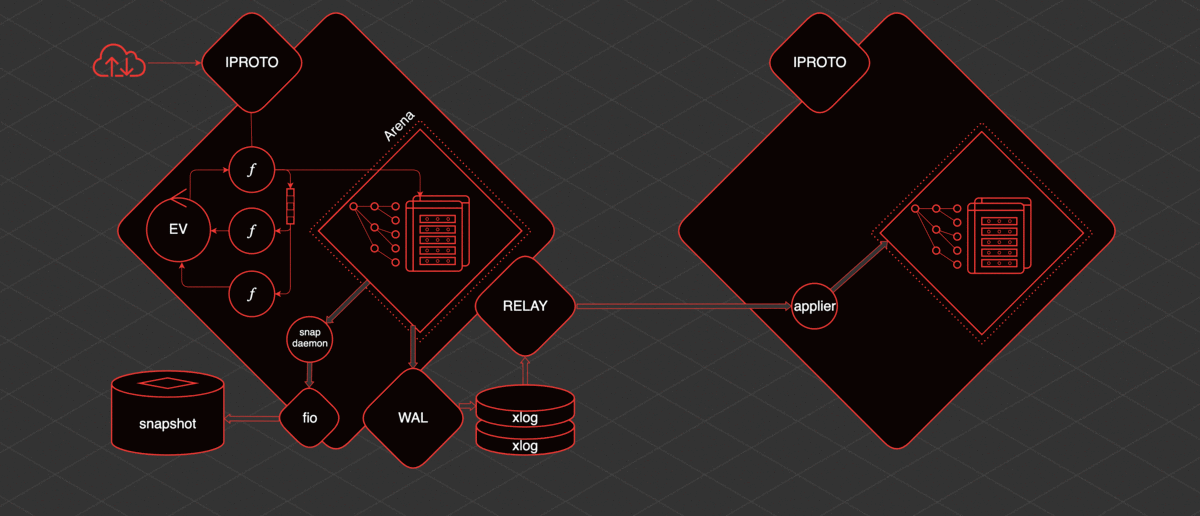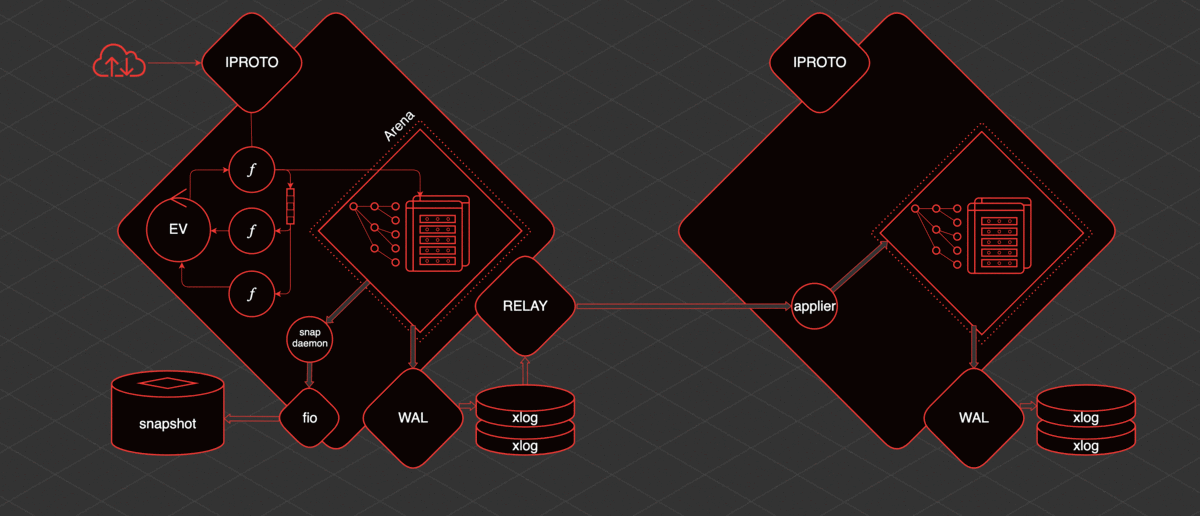
Что происходит при перезапуске? Представим, что Tarantool какое-то время работал, есть snapshot, есть xlog. Если его перезапустить:
- Tarantool находит последний snapshot и начинает его читать.
- Прочитывает и смотрит, какие есть xlog после этого snapshot. Читает их.
- По завершению чтения snapshot и xlog имеем снимок данных, который был на момент рестарта.
- Дальше Tarantool достраивает индексы. В момент чтения snapshot строятся только primary индексы.
- Когда все данные подняты в память, мы можем построить вторичные индексы.
- Tarantool запускает приложение.
Устройство ядра в шесть строк:
- Данные находятся в памяти
- Доступ к данным из одного треда
- Изменения пишутся во Write Ahead Log
- К данным построены индексы
- Периодически сохранятся Snapshot
- WAL реплицируется.
Lua
Приложения в рамках Tarantool реализованы на LuaJIT. Здесь можно остановиться и поговорить о том, почему LuaJIT.
Во-первых, Lua — это доступный скриптовый язык, который изначально создавался не для программистов, а для инженеров. То есть для людей, которые технически образованы, но не очень глубоко погружены в особенности программирования.
Lua был сделан максимально простым. Поэтому оказалось возможным создать JIT компилятор, который позволяет довести производительность скриптового языка почти до производительности языка С. Можно найти примеры, когда небольшая программа на Lua, скомпилированная на LuaJIT, практически догоняет по производительности аналогичную С программу [4].
Lua позволяет писать эффективные вещи довольно просто. И в целом, вокруг Tarantool была идея — работать рядом с данными. Запуская программу в том же неймспейсе и процессе, в котором находятся данные, мы можем не тратить время на поход по сети.
Мы обращаемся напрямую к памяти, поэтому чтение имеет практически нулевую и предсказуемую задержку. Этого всего можно было достигнуть и просто с Lua функциями, но внутри Tarantool есть событийный цикл плюс fiber«ы. Lua интегрирован с ними.
Итого:
- Lua: простой скриптовый язык для инженеров
- Высокоэффективная JIT-компиляция
- Работа рядом с данными
- Не процедуры, а кооперативный рантайм
Файберы и кооперативная многозадачность
Fiber — это нить исполнения. Она похожа на тред, но более легковесная и реализует примитив кооперативной многозадачности. Это налагает на нас следующие свойства.
- В один момент времени не исполняется более одной задачи.
- В системе отсутствует планировщик. Любой fiber должен отдавать управление добровольно.
Отсутствие планировщика и параллельно исполняющихся задач снижает потребление паразитных расходов и повышает производительность. Все это вместе дает возможность построить сервер приложений. Вы можете из Tarantool выйти во внешний мир.
В Tarantool есть библиотеки для работы как с сетью, так и с данными. Вы можете им пользоваться как привычным языком программирования, аналогично Python, Perl, JavaScript, и решать задачи, вообще не связанные с базой данных.
Внутри Tarantool есть функции, внутри самого сервера приложения для работы с базой данных. Поверх этого сервера приложений за время развития Tarantool развилась платформа. В термин платформа мы вкладываем следующее.
Платформа — это в основном in-memory база данных и встроенный сервер приложений. Или наоборот, сервер приложений плюс база данных. Но также к Tarantool прилагаются инструменты для репликации, для шардирования; инструменты для кластеризации и управления этим кластером, и коннекторы ко внешним системам.
Итого:
- Файбер — легковесная нить исполнения, реализует кооперативную многозадачность
- Следующая задача выполняется после того, как текущая объявит о передаче управления
- Сервер приложений
- Событийный цикл с файберами
- Неблокирующая работа с сокетами
- Коллекция библиотек для работы с сетью и данными
- Функции для работы с БД
- Платформа Tarantool
- In-memory база данных
- Встроенный сервер приложений
- Инструменты для кластеризации
- Коннекторы к внешним системам
Функциональность базы данных
Для хранения данных у нас используются таплы. Они же кортежи. Это массив с данными, которые не типизированы. Кортежи или таплы объединяются в спейсы. Спейс — это по сути просто коллекция таплов. Аналог из мира SQL — таблица.
В Tarantool есть два движка хранения. Можно разные спейсы определить на хранение в памяти или на диске. Для работы с данным обязательно нужен первичный индекс. Если создаем только первичный индекс, Tarantool будет выглядеть как key-value.
Но у нас индексов может быть много. Индексы могут быть композитные. Они могут состоять из нескольких полей. Мы можем выбирать по частичному совпадению с индексом. У нас возможна работа по индексам, то есть последовательный обход по итератору.
Индексы бывают разных типов. По умолчанию в Tarantool используется В+*дерево. А еще есть hash, bitmap, rtree, функциональные индексы и индексы по JSON путям. Все это многообразие позволяет нам вполне успешно использовать Tarantool там, где подходят реляционные базы.
Также в Tarantool есть механизм ACID транзакций. Устройство однопоточности доступа к данным дает нам возможность достичь уровня изоляции serializable. Когда мы обращаемся к арене, мы можем из неё читать или можем в неё писать, т.е. производить модификацию данных. Все, что происходит, выполняется последовательно и эксклюзивно в одном потоке.
Два fiber«а не могут исполняться параллельно. Но если мы говорим про интерактивные транзакции, то есть отдельный MVCC движок. Он позволяет выполнять в режиме serializable уже интерактивные транзакции, но придётся дополнительно обрабатывать потенциальные конфликты транзакций.
Помимо движка доступа Lua, в Tarantool есть SQL. Мы часто использовали Tarantool как реляционное хранилище. Сделали вывод, что мы дизайним хранилище по реляционным принципам.
Там, где в SQL использовались таблицы, у нас спейсы. То есть каждая строка представлена таплом. Мы определяли нашим спейсам схему. Стало понятно, что можно взять любой движок SQL и просто смаппить примитивы и исполнять SQL поверх Tarantool.
В Tarantool мы можем из Lua вызывать SQL. Можем пользоваться напрямую SQL, либо из SQL мы можем вызывать то, что определено в Lua.
SQL является дополняющим механизмом, им можно пользоваться, можно не пользоваться, но это довольно хорошее дополнение, расширяющее возможности применения Tarantool.
Итого:
Примитивы хранения данных
- тапл (кортеж, строка)
- спейс (таблица) — коллекция таплов
- engine:
- memtx — весь объём данных вмещается в память и надёжная копия на диске
- vynil — хранится на диске, объём данных может превышать объём памяти
- primary index
Индексы
- может быть много
- композитные
- типы индексов
- tree (B⁺*)
- hash
- bitmap
- rtree
- functional
- json path
Транзакции
- ACID
- Serializable (No-yield)
- Интерактивные (MVCC)
SQL & Lua
- TABLE: space
- ROW: tuple
- Schema: space format
- Lua → SQL: box.execute
Сравнение с другими системами
Чтобы хорошо понять место Tarantool в мире СУБД, мы проведем сравнение с другими системами. Сравнивать можно много с кем, но меня интересуют четыре основные группы:
- In-memory платформы
- Реляционные СУБД
- Key-value решения
- Документ-ориентированные системы
In-memory платформы
GridGain, GigaSpaces, Redis Enterprise, Hazelcast, Tarantool.
Чем они похожи? In-memory движком, in-memory базой данных, плюс некоторым application runtime. Они позволяют гибко строить кластерные системы под разные объемы данных.
В частности это использование в роли Data Grid. Эти платформы нацелены на решение бизнес-задач. Каждый грид, каждая in-memory платформа построена по своей собственной архитектуре, при этом они относятся к одному классу. Также в разные платформы входит разный набор инструментов, потому что каждая из них нацелена на свой сегмент.
Tarantool является платформой общего назначения без привязки к сегменту. Это дает более широкие возможности и спектр решаемых бизнес-сценариев.
Реляционные базы данных
Теперь сравним in-memory движок базы данных Tarantool с MySQL и PostgreSQL. Это позволяет позиционировать сам движок, в отрыве от сервера приложений и тем более платформы.
Tarantool похож на реляционные базы данных, потому что он хранит данные в табличной форме (в таплах и спейсах). К данным построены индексы, так же как в реляционных базах. В Tarantool можно определить схему, даже есть SQL, при помощи которого можно с данными работать.
Но именно SQL схема отличает Tarantool от классических реляционных БД. Потому что хоть SQL и есть, им можно не пользоваться. Он не является основным инструментом взаимодействия с базой данных.
Схема Tarantool не строгая. Вы можете её определить только для какого-то подмножества ваших данных.
В обычных реляционных базах таблица в памяти — это не персистентное хранилище, используемое для каких-то быстрых операций. В Tarantool весь объём данных влезает в память, обслуживается из памяти и при этом является надёжным и персистентным.
Это настолько важно, что я напишу еще раз — Tarantool хранит весь дата-сет в памяти и при этом данные надёжно сохраняются на диск.
Key-value БД
Следующий класс, с которым стоит сравнить, это key-value — memcached, Redis, Aerospike. Чем Tarantool похож на них? Он может работать в режиме key-value, можно использовать строго один индекс. В этом случае Tarantool ведет себя как классическое key-value хранилище.
Например, Tarantool можно использовать в качестве drop-in замены для memcached. Есть модуль, который реализует соответствующий протокол и в этом случае мы полностью имитируем memcached.
Tarantool похож по своей in-memory архитектуре на Redis, просто у него другой стиль описания данных. Там, где по архитектурным сценариям применим Redis можно брать и Tarantool. Битва этих ёкодзун описана в статье по ссылке [5].
Отличия Tarantool от key-value баз — это как раз наличие вторичных индексов, транзакций, итераторов и прочих вещей, свойственных реляционным базам.
Документ-ориентированные БД
В качестве четвертой категории я хотел бы привести документо-ориентированные базы. Здесь самый яркий пример это MongoDB. В Tarantool тоже можно хранить документы. Поэтому можно сказать, что Tarantool по-своему, в том числе документо-ориентированная база.
Сам внутренний формат хранения Tarantool — это msgpack. Это такой бинарный JSON. Он практически эквивалентен тому формату, который используется в Mongo. Это BSON. Он имеет такую же компактность. Он отражает те же самые типы данных. При этом вы можете индексировать содержимое этих документов. Подробнее про msgpack читайте в недавней статье [6].
Также вместе с Tarantool поставляется библиотека Avro Schema. Она позволяет документы регулярной структуры разобрать в строки и эти строки уже хранить непосредственно в базе.
Но Tarantool изначально не задумывался как документо-ориентированная база. Это бонус для него и возможность хранить какую-то часть данных как документ. Поэтому у него несколько слабее механизмы индексации в сравнении с той же Mongo.
Bonus round: колоночные базы
Такие вопросы иногда возникают. Здесь ответ простой — Tarantool не колоночная база данных (кто бы мог подумать). Те сценарии, которые хороши для колоночных баз, к Tarantool не подходят. Можно отметить, что они крайне хорошо дополняют друг друга.
Думаю, что многим из вас известен Click House. Это отличное аналитическое решение. Это колоночная база. Причем, ClickHouse не любит микротранзакции. Если в него присылать много мелких транзакций, он не достигнет своей максимальной пропускной способности. В него нужно слать данные батчами.
При этом в Tarantool можно и нужно слать микротранзакции. Он способен их накапливать. Поскольку он обладает различными коннекторами, он может накапливать эти транзакции и отправлять их в хранилище типа ClickHouse уже батчом. Инь и янь.
Итого:
Сценарии использования
Когда не использовать
Начнем мы с примеров того, когда Tarantool использовать не стоит. Основной сценарий — это аналитика, она же OLAP, в том числе с использованием SQL.
Причины тому довольно простые. Tarantool по своей основной идее однотредовое приложение. У него нет блокировок при доступе к данным. Но если один тред исполняет длинный SQL, во время его работы никто другой работать не сможет.
Поэтому аналитические базы обычно используют многотредовый режим доступа к данным. Тогда в отдельных тредах можно что-то обсчитывать. В случае Tarantool один тред работает быстрее, чем многие другие решения. Но он один, и нет возможности работать с данными из нескольких тредов.
Но если вы хотите строить какую-нибудь заранее рассчитанную аналитику, например, вы знаете, что вам понадобятся вот такие кумулятивные данные. У вас идет поток данных, и вы можете сразу сказать, что вам нужны какие-то счетчики. Такая предпосчитанная аналитика на Tarantool строится хорошо.
Когда использовать
Основной сценарий происходит из его исторического наследия, из того, для чего он создавался. Много мелких транзакций.
Это могут быть сессии, профили пользователей и все то, что выросло из него за это время. Например, Tarantool часто используются в качестве хранилища векторов рядом с Machine Learning, поскольку в нем это удобно хранить. Он может использоваться в качестве высоконагруженных счетчиков, которые пропускают через себя весь трафик, антибрутфорс систем.
Итого:
Примеры плохого использования
- Аналитика (OLAP)
- В т.ч. с использованием SQL
Примеры хорошего использования
- Высокочастотные микротранзакции (OLTP)
- Профили пользователей
- Счётчики и признаки
- Кеш-прокси к данным
- Брокеры очередей
Заключение и выводы
Tarantool персистентный и имеет возможность ходить во многие другие системы. Поэтому он используется в качестве кэш-прокси к легаси системам. К тяжелым, сложным, причем как и в write true proxy, так и в write behind proxy.
Также архитектура Tarantool, наличие в нем fiber«ов и возможности писать сложные приложения делает его хорошим инструментом для написания очередей. Мне известно 6 реализаций очередей, часть из них на GitHub, часть из них в закрытых репозиториях или где-то в проектах.
Основная причина этого — это гарантированно низкое latency на доступ. Когда мы находимся внутри Tarantool и приходим за какими-то данными, мы отдаем их из памяти. Мы имеем быстрый конкурентный доступ к данным. Тогда можно строить гибридные приложения, которые работают непосредственно рядом с данными.
Попробуйте Tarantool на нашем сайте и приходите с вопросами в Telegram-чат.
Ссылки
- Архитектура S3: 3 года эволюции Mail.ru Cloud Storage
- Видео — Tarantool как основа для высоконагруженных приложений
- Tarantool: как сэкономить миллион долларов на базе данных на высоконагруженном проекте
- https://github.com/luafun/luafun
- Tarantool vs Redis: что умеют in-memory технологии
- Расширенные возможности MessagePack
