DDIA book (книга с кабанчиком) — сделай level up в понимании баз данных
Несколько месяцев назад на одной из ретроспектив мы решили попробовать совместное чтение.
Наш формат:
1. Выбираем книгу.
2. Определяем часть, которую необходимо прочитать за неделю. Выбираем небольшой объем.
3. В пятницу обсуждаем прочитанное.
4. Читаем в нерабочее время, обсуждаем в рабочее.
5. После окончания книги совместно выбираем следующую.
Что дает:
1. Мотивация на чтение и дочитывание.
2. Развитие скиллов (в том числе на будущее).
3. Выравнивание майндсета и терминологии в команде.
4. Рост доверия.
5. Лишний повод пообщаться.
Одна из недавних книг, которую мы читали — Designing Data-Intensive Applications. Да-да, та самая книга с кабанчиком. И эта книга настолько всем понравилась, что я решил сделать здесь обзор, чтобы большее количество людей ее прочитали.
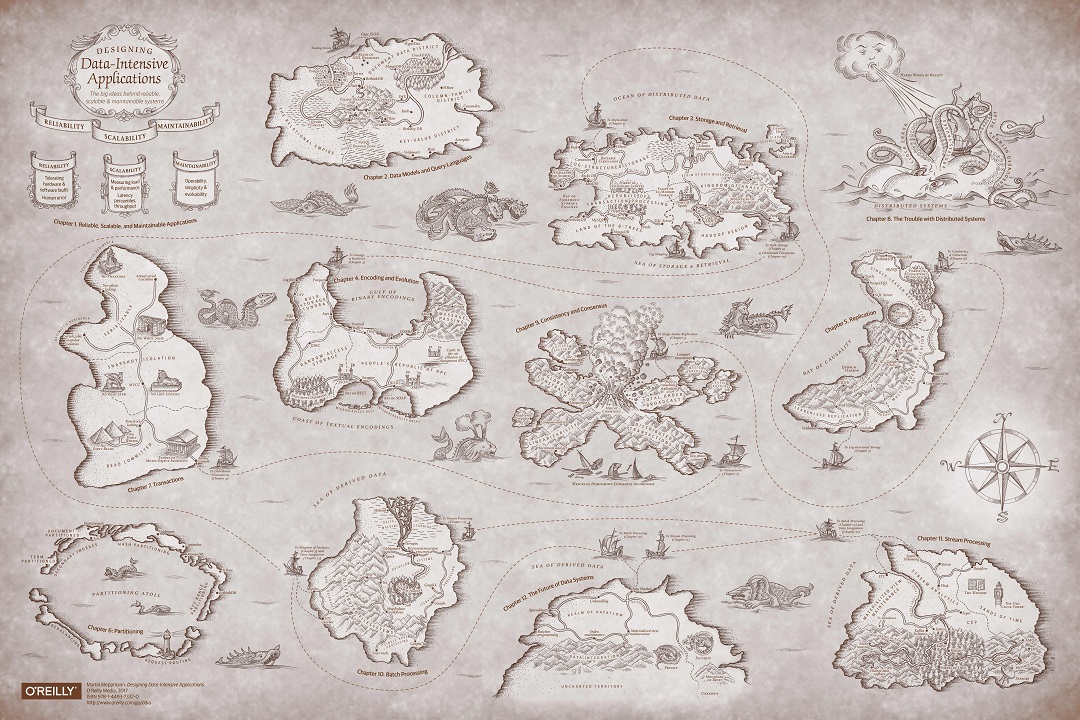
Карта в исходном качестве
Есть перевод этой книги на русский от Издательства Питер. Но мы читали в оригинале, поэтому не обещаю, что переводы терминов совпадут. Более того часть терминов мы осознанно не переводили.
Начальная часть книги посвящена основам систем обработки данных.
В первой главе указывается, что важными свойствами таких систем являются надежность, масштабируемость и удобство сопровождения.
Вторая глава описывает различные модели данных. Описаны привычные реляционные и документоориентированные СУБД, так и менее известные графовые и колоночные базы данных.
Первые главы вводят в курс дела, устанавливают рамки книги. Во многих местах дальше автор ссылается на первые главы. Справедливости ради, можно сказать, что книга полна перекрестными ссылками.
Что удивляет с первых же глав, так это количество источников (библиография есть после каждой главы). Ссылки на десятки статей (как блоги, так и научные) и книг скрупулезно расставлены по всем главам. Количество источников к некоторым главам превышает сотню.
Третья глава начинается с исходника простейшего key-value хранилища:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
Это будет даже работать, очень хорошо на запись, но, конечно же, не без проблем при чтении.
И сразу же предлагаются варианты улучшения производительности. Описываются хэш-индексы, SSTable, b-tree и LSM-tree. Все это объясняется на пальцах, но при этом показано, как та или иная структура используется в привычных нам базах данных.
Нацеленность на практику — еще одна отличительная черта книги. Большинство примеров и рецептов настолько практичны, что почти со всем релевантным я так или иначе сталкивался.
В четвертой главе описан encoding: от обычных JSON и XML до Protobuf и AVRO. Мы не всегда выбираем формат осознанно, обычно он навязан той или иной технологией в целом. Но круто понимать как устроено внутри, какие сильные-слабые стороны формата.
Автор специально не стал использовать термин сериализация, так как этот термин в базах данных имеет еще одно значение.
Содержание глав намного богаче моего краткого представления. В первой части также описаны отличия между OLTP и OLAP, как устроены полнотекстовый поиск и поиск в колоночных БД, REST и брокеры сообщений.
Вторая часть книги рассказывает о распределенных системах обработки данных. Почти все современные мало-мальски нагруженные системы имеют несколько реплик или подсистем (микросервисы).
Когда мы только начали практиковать совместное чтение, мы просто обсуждали свои заметки, интересные места и мысли. В какой-то момент мы поняли, что нам не хватает просто разговоров, после обсуждения все быстро забывается. Тогда мы решили усилить нашу практику и добавили заполнение mind map. Нововведение пришлось как раз на эту книгу. Начиная со второй части, мы начали вести mind map для каждой главы. Поэтому дальше каждая глава будет с нашим mind map. Мы использовали coggle.it
В пятой главе описывается репликация.
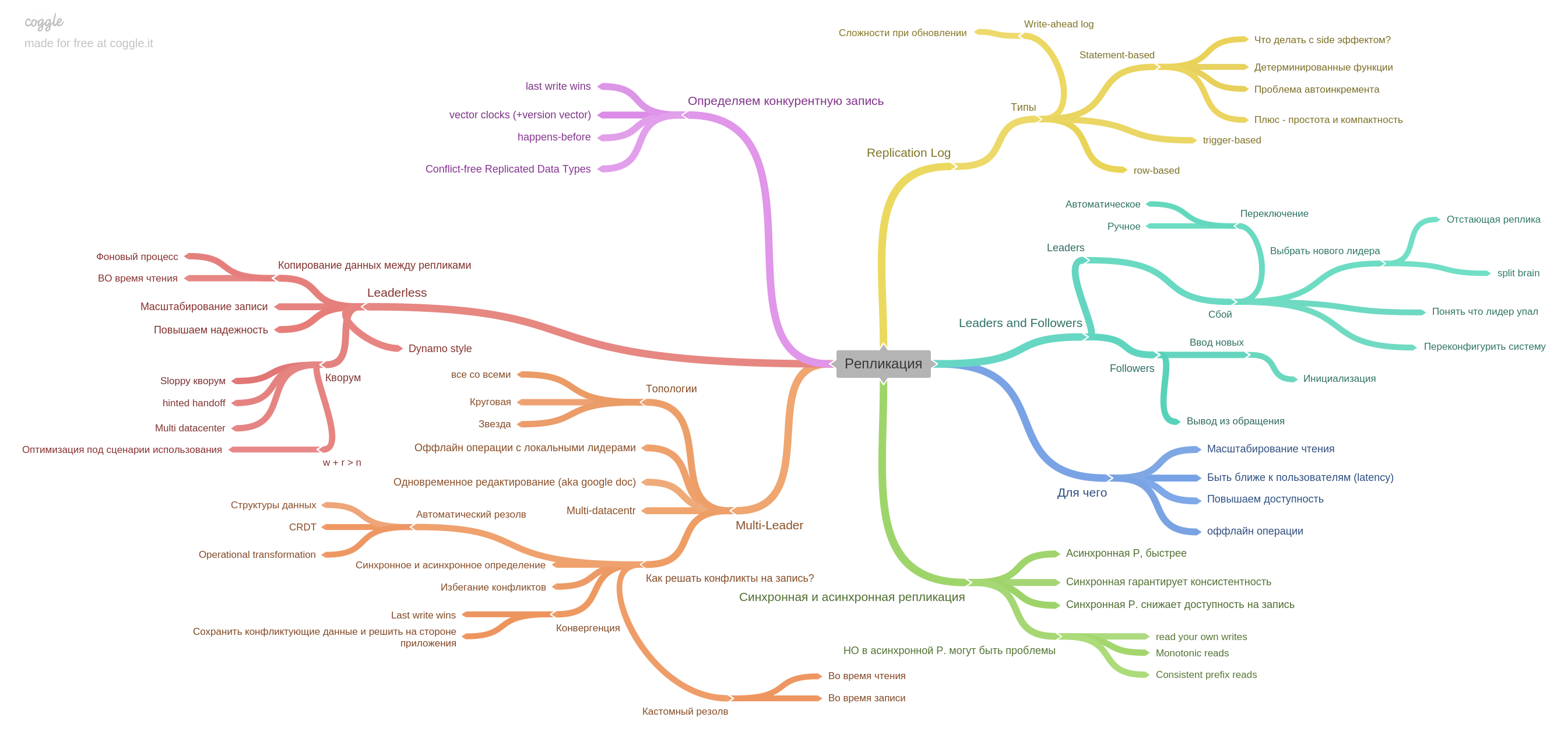
Здесь собраны вся базовая информация о репликах: single-мастер, мультимастер, replication log и как жить с конкурентной записью в leaderless-системах.
В шестой главе описано партицирование (aka шардинг и пачка других терминов).
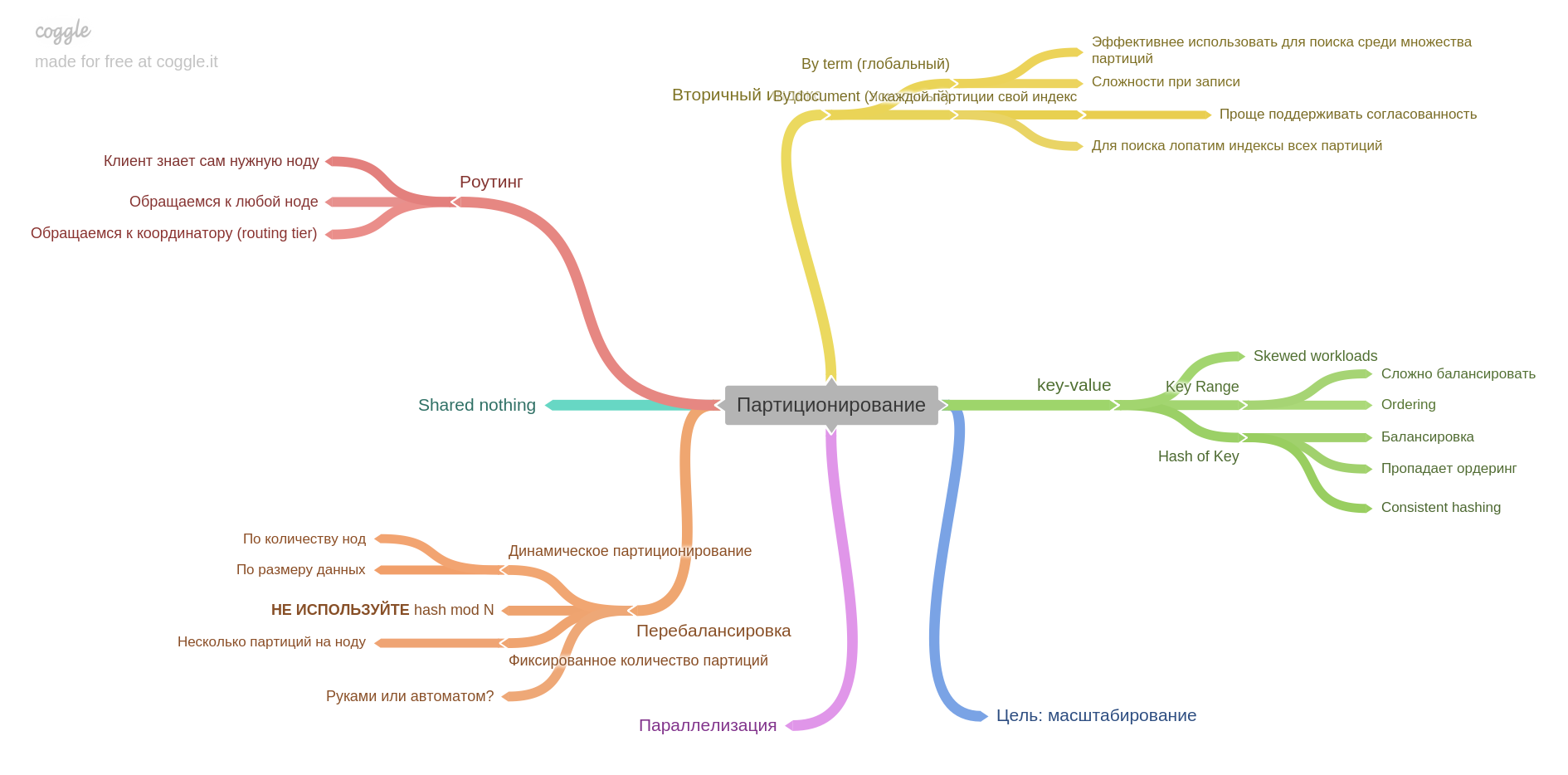 Вы узнаете, как разбивать данные на шарды, какие проблемы можно решить, а какие получить, как строить индексы и балансировать данные.
Вы узнаете, как разбивать данные на шарды, какие проблемы можно решить, а какие получить, как строить индексы и балансировать данные.
Седьмая глава: транзакции.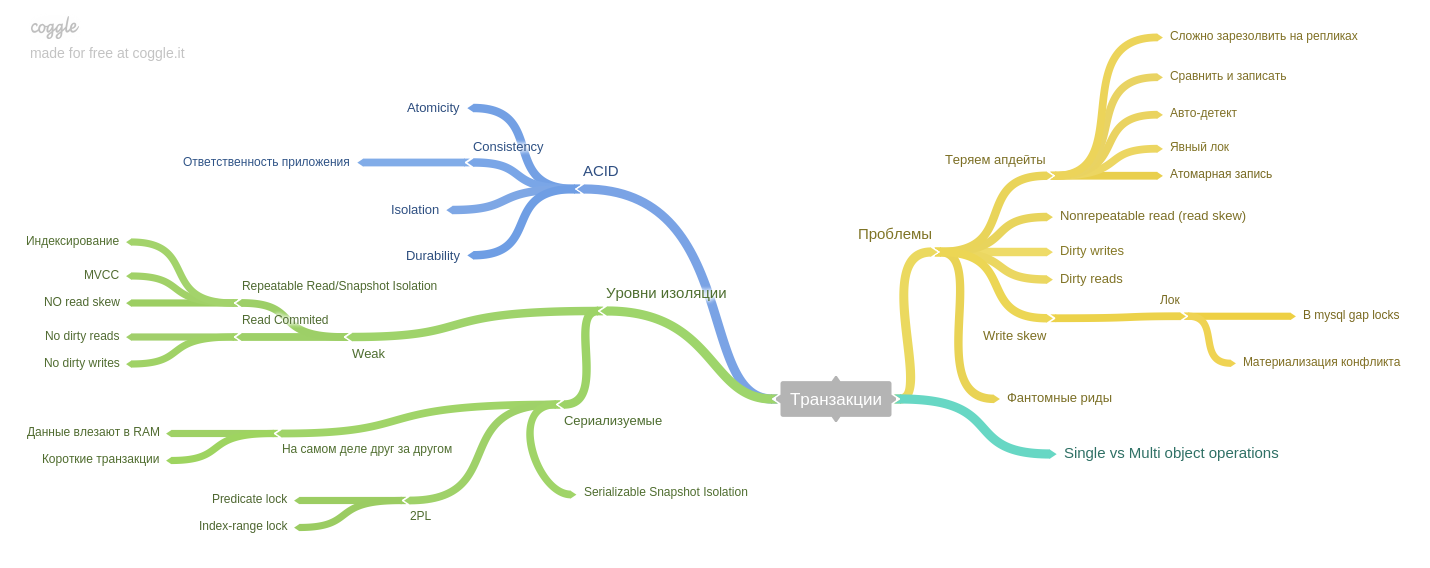
Описаны феномены (read skew, write skew, phantom reads, etc) и каким именно образом уровни изоляции ACID-style баз данных помогают избежать проблем.
Восьмая глава: о проблемах специфичных для распределенных систем.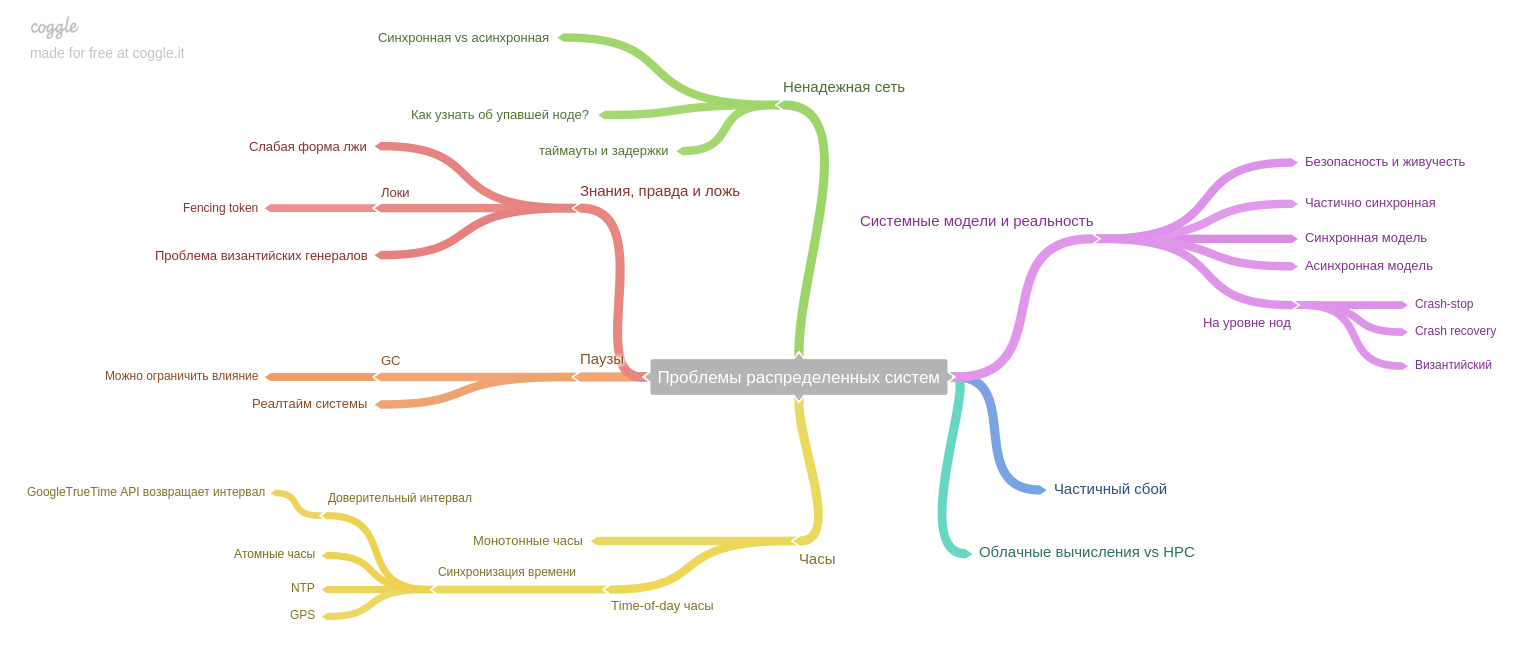
Автор выделяет важную мысль: если раньше система работала на одной машине, и в случае отказа вся система переставала работать (и принимать любые новые данные). Таким образом, данные после отказов оставались в консистентном состоянии, но сегодня, в эпоху реплик и микросервисов прекращает свою работу только часть системы. Таким образом, перед нами встает новая проблема: обеспечение согласованности данных в условиях частичного отказа, постоянных проблем с ненадежной сетью и т.п.
В девятой главе описывается согласованность и консенсус и вводится важной понятие: линеаризуемость. Помню, что глава тяжело заходила и укладывалась в голове)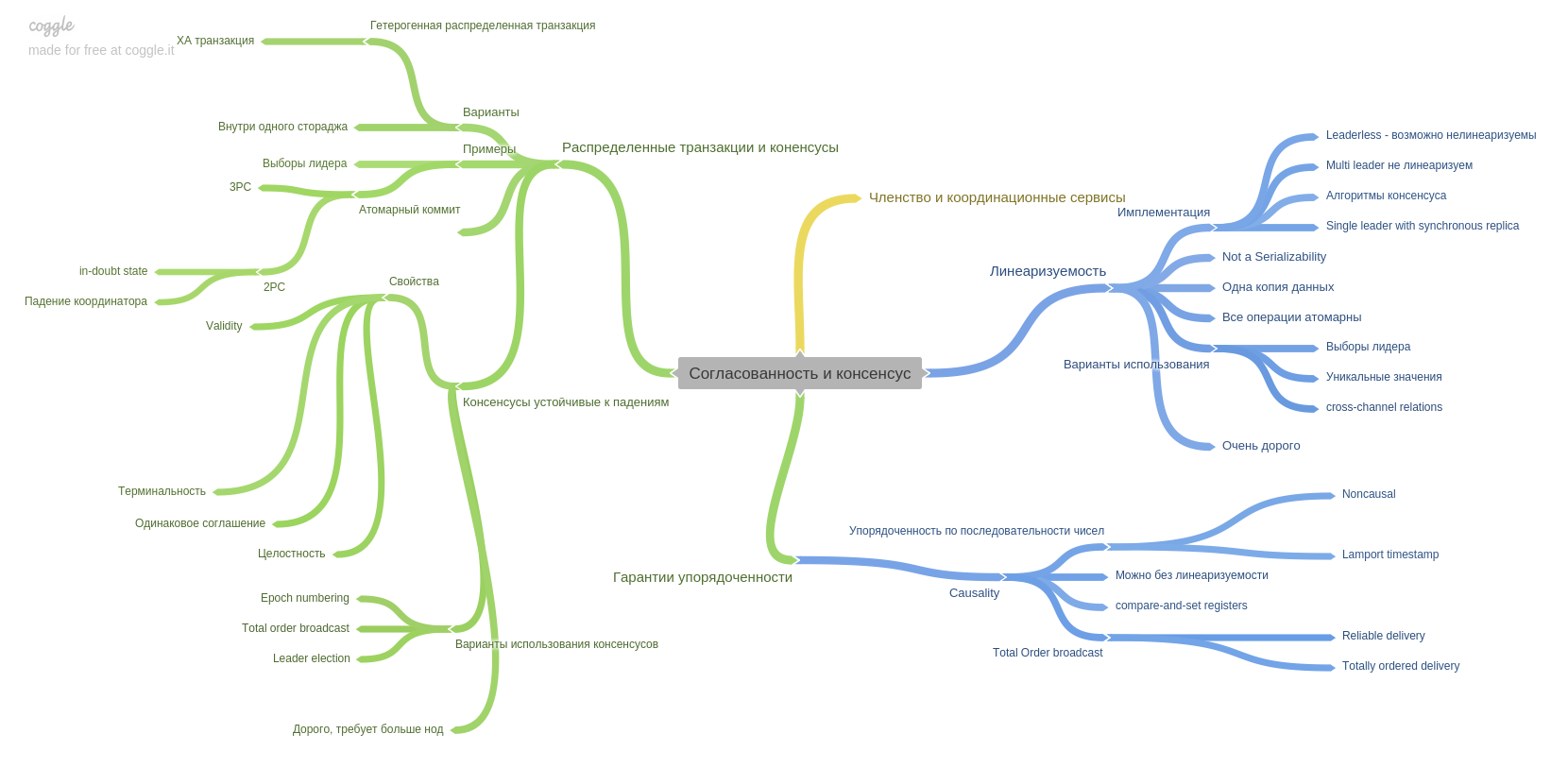
В этой главе также описывается техника двухфазного коммита и его слабые места. Также в этой главе вы прочитает про гарантии упорядоченности. Как и что современные системы могут вам обеспечить.
Третья часть книги посвящена derived data (нет устоявшегося перевода). В итоге, автор озвучивает мысль, что все индексы, таблицы, материализованные вьюшки — это просто кэш над логом. Только лог содержит самые актуальные данные, все остальное запаздывает и используется для удобства.
Десятая глава.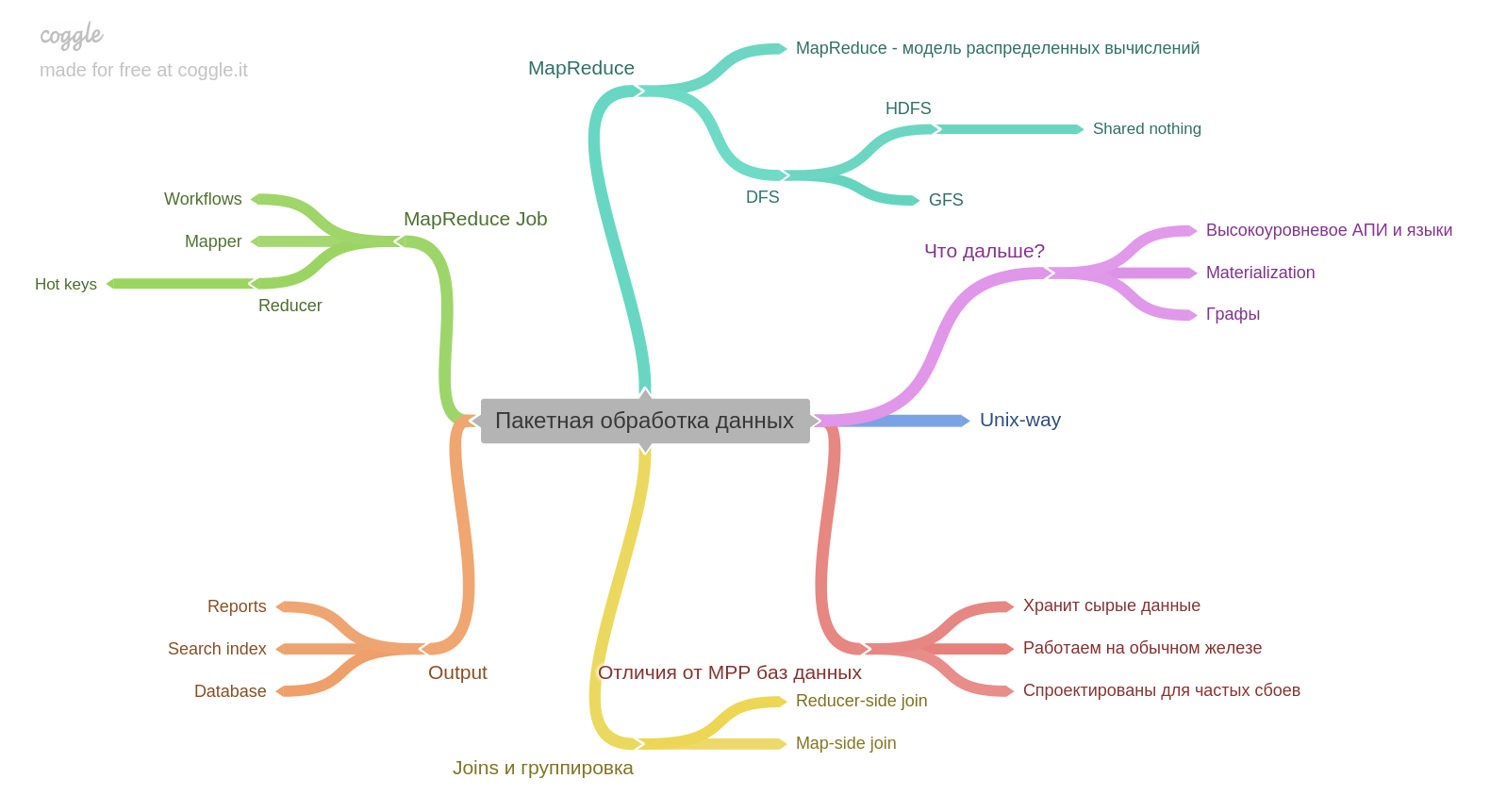
Если есть опыт с Hadoop или MapReduce, возможно, вы мало нового узнаете. Но я не работал и было очень интересно. Важный момент для меня — результат пакетной обработки сам по себе может стать основой для другой БД.
Глава 11. Потоковая обработка данных.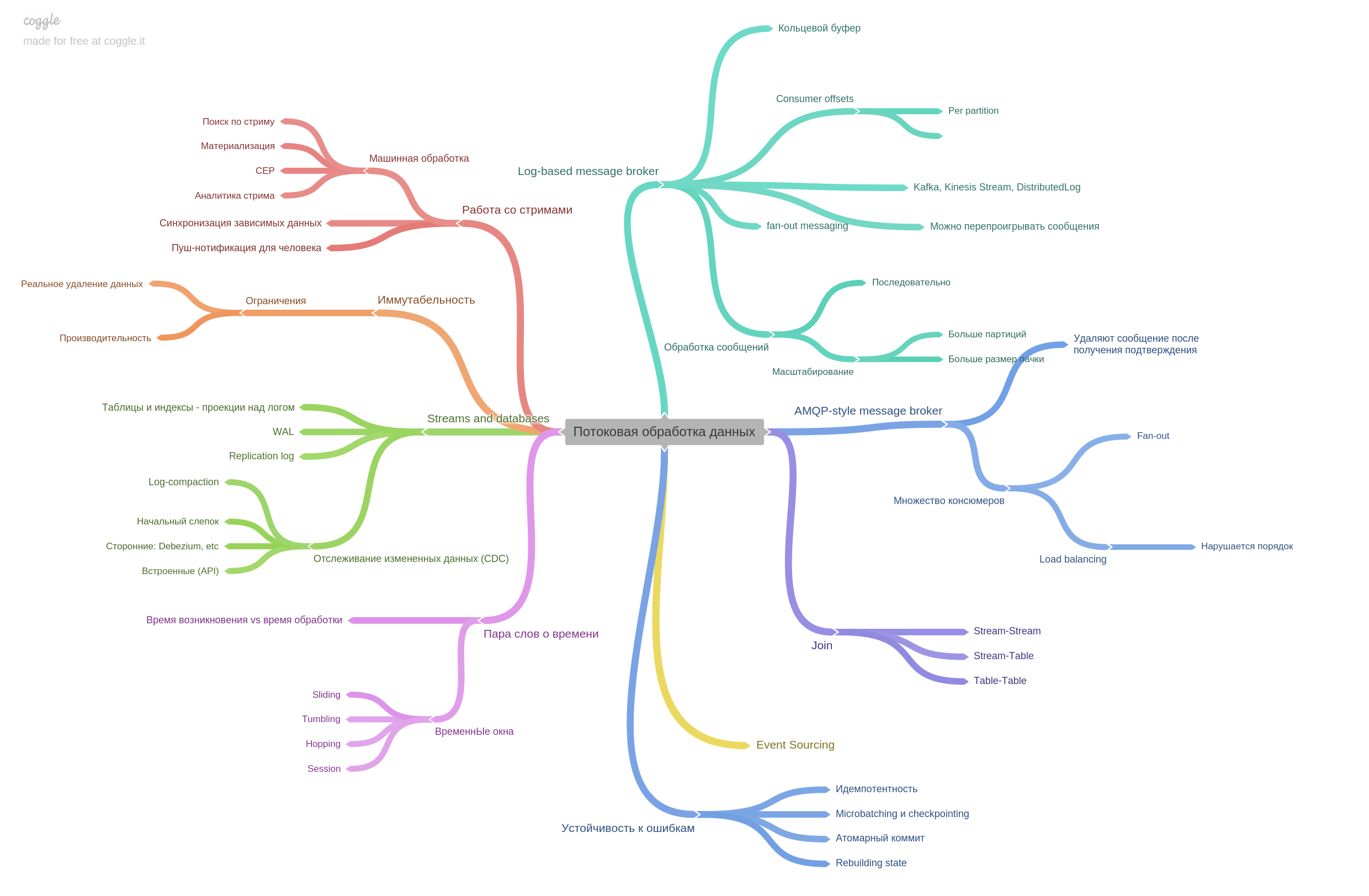
Описываются брокеры сообщений и чем AMPQ-style отличается от log-based. На самом деле глава содержит много другой информации. Было очень интересно читать.
Последняя глава про будущее. Чего ждать, чем уже заняты мысли исследователей и инженеров.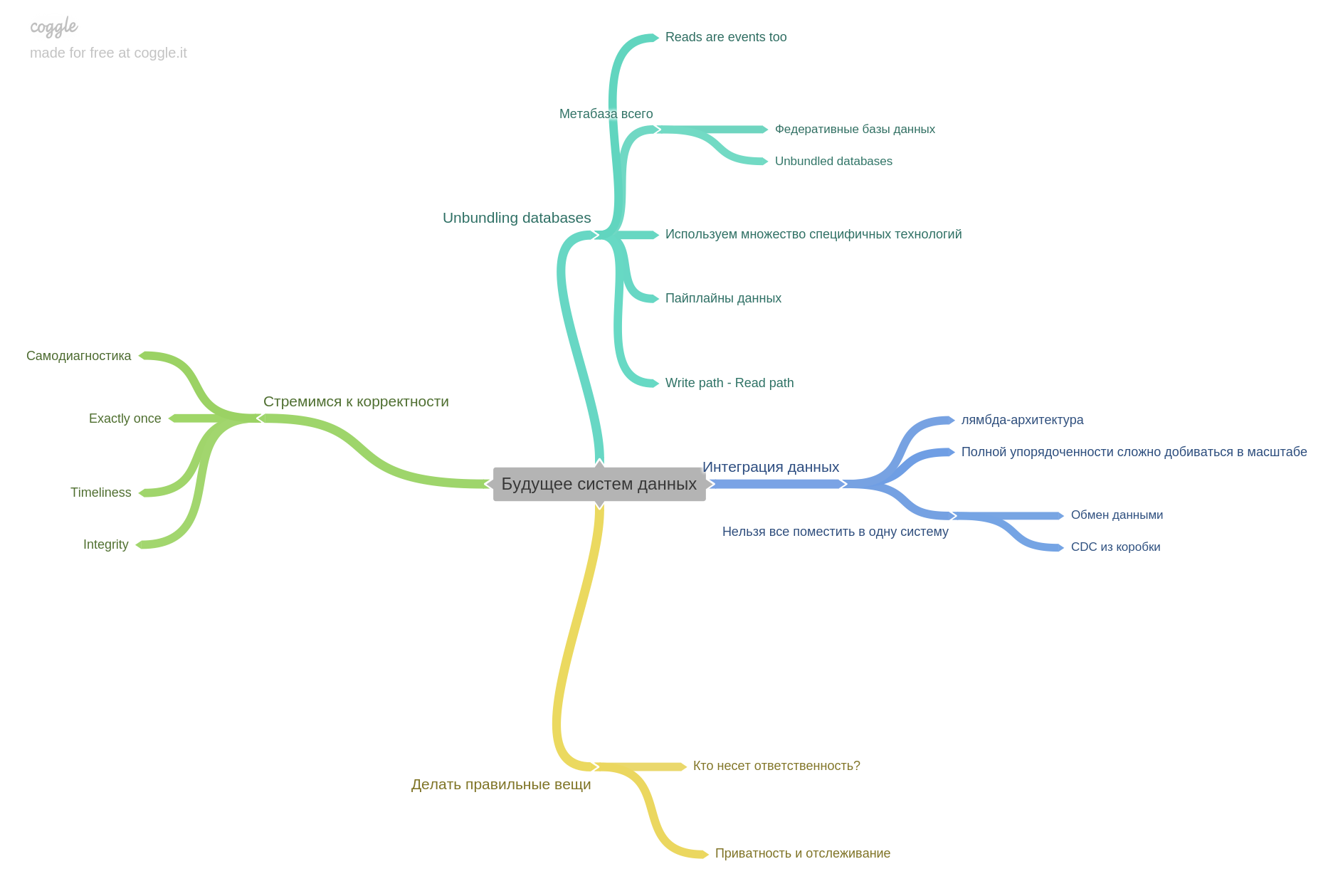
На этом я заканчиваю свой обзор. Важно понимать, что я вынес только часть тезисов по каждой главе. У книги столь плотное содержание, что нет возможности кратко, но полноценно пересказать.
Лично я считаю эту книгу лучшей технической за последние несколько лет. Очень рекомендую ее прочитать. И не просто прочитать, но усердно проработать. Походить по ссылкам из библиографии, поиграться с реальными СУБД.
Прочитав эту книгу, вы легко ответите на многие вопросы в техническом интервью по базам данных. Но это не главное. Вы станете круче как разработчик, будете знать внутреннее устройство, сильные и слабые стороны различных БД и задумаетесь о проблемах распределенных систем.
Готов в комментариях обсудить как саму книгу, так и нашу практику совместного чтения.
Читайте книги!
