DBA: в погоне за пролетающими блокировками
В прошлой статье, где я рассказывал о мониторинге БД PostgreSQL, была такая фраза:
Растут wait — приложение в кого-то «уперлось» на блокировках. Если это уже прошедшая разовая аномалия — повод разобраться в исходной причине.Такая ситуация — одна из самых неприятных для DBA:
- на первый взгляд, база работает
- никакие ресурсы сервера не исчерпаны
- … но часть запросов при этом «подтормаживает»

Шансов поймать блокировки «в моменте» крайне мало, да и длиться они могут всего по несколько секунд, но ухудшая при этом плановое время выполнения запроса в десятки раз. А хочется-то не сидеть и ловить происходящее в онлайн-режиме, а в спокойной обстановке разобраться постфактум, кого из разработчиков покарать в чем именно была проблема — кто, с кем и из-за какого ресурса базы вступил в конфликт.
Но как? Ведь, в отличие от запроса с его планом, который позволяет детально понять, на что пошли ресурсы, и сколько времени это заняло, подобных наглядных следов блокировка не оставляет после себя…
Разве что короткую запись в логе:
process ... still waiting for ...
А давайте попробуем зацепиться именно за нее!
Ловим блокировку в лог
Но даже чтобы хотя бы эта строка оказалась в логе, сервер надо правильно настроить:
log_lock_waits = 'on'… и установить минимальную границу для нашего анализа:
deadlock_timeout = '100ms'Когда включён параметр
log_lock_waits, данный параметр также определяет, спустя какое время в журнал сервера будут записываться сообщения об ожидании блокировки. Если вы пытаетесь исследовать задержки, вызванные блокировками, имеет смысл уменьшить его по сравнению с обычным значениемdeadlock_timeout.
Все deadlock, не успевшие «развязаться» за это время будут разорваны. А вот «обычные» блокировки — сброшены в лог несколькими записями:
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement
"SELECT pg_advisory_xact_lock( '"Документ"'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT:
DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '"Документ"'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
В этом примере видно, что у нас было всего 50мс от момента появления блокировки в логе до момента ее разрешения. Только в этом интервале мы можем получить хоть какую-то информацию о ней, и чем быстрее мы способны это делать — тем больше блокировок сможем проанализировать.
Тут самая важная для нас информация — это PID процесса, который ждет блокировку. Именно по нему мы можем сопоставить информацию между логом и состоянием базы. А заодно узнать, насколько проблемной была конкретная блокировка — то есть сколько времени она «висела».
Для этого нам достаточно всего пары RegExp на контент LOG-записи:
const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/; // ловим факт начала блокировки
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/; // ловим момент окончания
Докапываемся до лога
Собственно, осталось немного — взять лог, научиться его мониторить и соответствующим образом реагировать.
У нас-то для этого уже все есть — и онлайн-парсер лога, и заранее активированное соединение с БД, про которые я рассказывал в статье о нашей системе мониторинга PostgreSQL: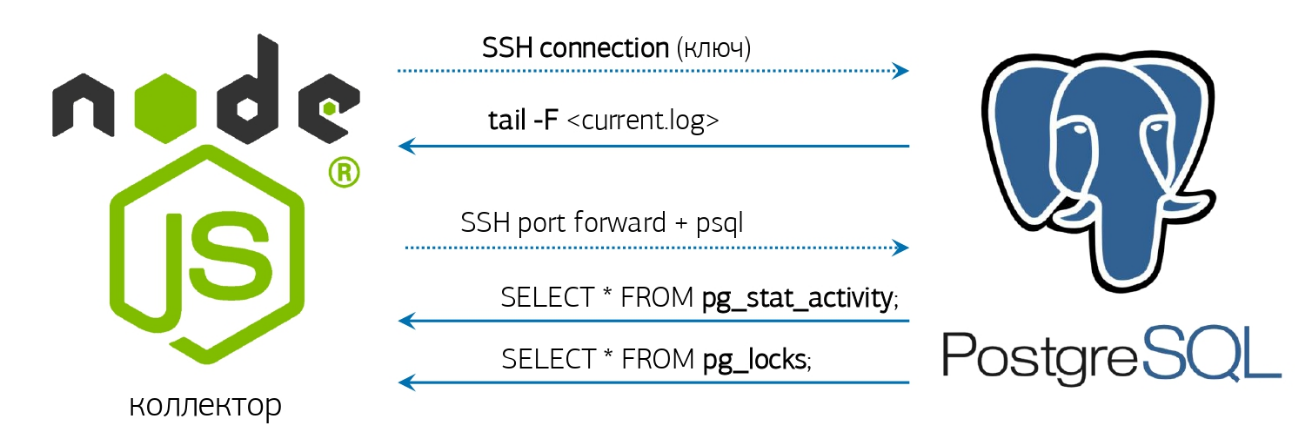
Но если у вас никакой аналогичной системы не развернуто — не беда, сделаем все «прямо с консоли»!
Если установленная версия PostgreSQL 10 и выше — повезло, поскольку там появилась функция pg_current_logfile(), которая в явном виде отдает имя текущего файла лога. Получить его из консоли будет достаточно легко:
psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
Если версия вдруг младше — все получится, но чуть сложнее:
ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
Получим полное имя файла, которое отдадим в tail -f и будем ловить там появление 'still waiting for'.
Ну а как только что-то возникло в этом потоке — вызываем…
Анализирующий запрос
Увы, объект блокировки в логе далеко не всегда является именно тем ресурсом, из-за которого возник конфликт. Например, если попытаться параллельно создать одноименный индекс, в логе будет только что-то вроде still waiting for ExclusiveLock on transaction 12345.
Поэтому нам придется снимать состояние всех блокировок с базы для интересующего нас процесса. Да и информации только о паре процессов (кто наложил блокировку / кто ее ожидает) — недостаточно, ведь нередко случается «цепочка» ожиданий разных ресурсов между транзакциями:
tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
Классика: «Дедка за репку, бабка за дедку, внучка за бабку, ...»
Поэтому напишем запрос, который нам точно скажет, кто же стал первопричиной бед по всей цепочке блокировок для конкретного PID:
WITH RECURSIVE lm AS (
-- lock modes
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
-- lock types
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
-- lock modes conflicts
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
-- locked targets/pids
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE) -- PID
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
Проблема #1 — медленный старт
Как видно в примере из лога, следом за строкой, сигнализирующей о возникновении блокировки (LOG), идет еще 3 строки (DETAIL, CONTEXT, STATEMENT), сообщающих расширенную информацию.
Сначала мы дожидались формирования полного «пакета» из всех 4 записей и только после этого обращались к базе. Но завершить формирование пакета мы можем только при приходе следующей (уже 5й!) записи, с реквизитами другого процесса, или по таймауту. Понятно, что и тот и другой варианты провоцируют лишнее ожидание.
Чтобы избавиться от этих задержек, мы перешли на потоковую обработку записей о блокировках. То есть теперь мы обращаемся к целевой базе сразу, как только разобрали первую же запись, и поняли, что там описана именно блокировка.
Проблема #2 — медленный запрос
Но все равно часть блокировок не успевала проанализироваться. Стали копать глубже — и выяснили, что на некоторых серверах наш анализирующий запрос выполняется по 15-20мс!
Причина оказалась банальной — общее количество активных блокировок на базе, доходящее до нескольких тысяч:
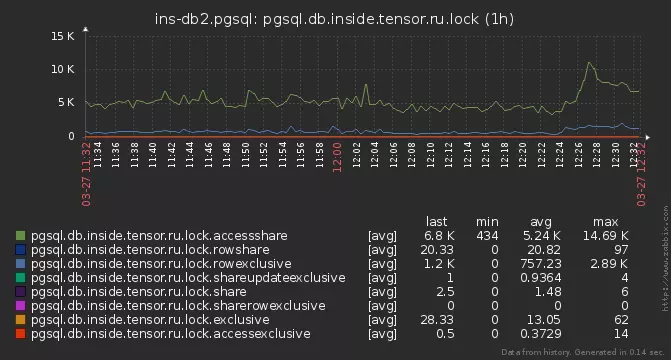
pg_locks
Тут надо заметить, что блокировки в PostgreSQL нигде не «хранятся», а представлены только в системном view pg_locks, которое является прямым отражением функции pg_lock_status. А мы в своем запросе читаем из нее трижды! А пока мы читаем эти тысячи экземпляров блокировок, и отбрасываем те, которые не имеют отношения к нашему PID, сама блокировка успевала «рассосаться»…
Решением стала «материализация» состояния pg_locks в CTE — после этого по ней можно бегать сколько угодно раз, она уже не меняется. Причем, посидев над алгоритмом, удалось все свести всего к двум ее сканированиям.
Избыточная «динамика»
А если еще чуть внимательнее посмотреть на запрос выше, то можно заметить, что CTE lm и lmx вообще никак не завязаны на данные, а просто вычисляют всегда одну и ту же «статичную» матрицу определения конфликтов между режимами блокировок. Так давайте просто и зададим ее в качестве VALUES.
Проблема #3 — соседи
Но часть блокировок все равно пропускались. Обычно это получалось по следующей схеме — кто-то заблокировал популярный ресурс, а в него или по цепочке дальше быстро-быстро уперлось сразу несколько процессов.
В результате, мы ловили первый PID, шли на целевую базу (а чтобы не перегружать ее, мы держим только одно соединение), делали анализ, возвращались с результатом, брали следующий PID… А на базе-то жизнь не стоит, и блокировка по PID#2 уже пропала!
Собственно, а зачем нам ходить на базу по каждому PID отдельно, если мы все равно в запросе отфильтровываем блокировки из общего списка? Давайте возьмем сразу весь список конфликтующих процессов прямо с БД и их блокировки распределим по всем попавшимся за время выполнения запроса в лог PID'ам:
WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
Теперь мы успеваем проанализировать даже блокировки, существующие всего 1-2 мс после попадания в лог.
Analyze This
Собственно, а ради чего мы так долго старались? Что нам это в результате дает-то?..
type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
В этой табличке нам пригодятся значения target с типом relation, ведь каждое такое значение — OID таблицы или индекса. Теперь остается совсем немного — научиться опрашивать базу на предмет еще неизвестных нам OID, чтобы перевести их в человекопонятный вид:
SELECT $1::oid::regclass;
Теперь, зная полную «матрицу» блокировок и все объекты, на которые они были наложены каждой из транзакций, мы можем сделать вывод «что вообще происходило», и какой ресурс вызвал конфликт, даже если заблокировавший запрос нам остался неизвестен. Это легко может произойти, например, когда время выполнения блокирующего запроса недостаточно велико для попадания в лог, но транзакция после его завершения была активна и создавала проблемы еще долго.
Но про это — уже в другой статье.
«Все само»
А пока соберем полный вариант «мониторилки», который будет автоматически снимать для нашего архива состояние блокировок, как только в логе появляется что-то подозрительное:
ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
А рядышком в detect-lock.sql кладем последний запрос. Запускаем — и получаем пачку файлов с искомым содержимым внутри:
# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
Ну а дальше — садимся и анализируем…
