Датасеты для automotive
1. A2D2 dataset от Audi

Наш набор данных включает в себя более 40 000 кадров с семантической сегментацией изображений и метками облака точек, из которых более 12 000 кадров также имеют аннотации для 3D-боксов. Кроме того, мы предоставляем немаркированные данные датчиков (прибл. 390 000 кадров) для последовательностей с несколькими циклами, записанных в трех городах.
Сегментация данных
Набор данных содержит 41 280 кадров с семантической сегментацией по 38 категориям. Каждому пикселю изображения присваивается метка, описывающая тип объекта, который он представляет, например пешехода, автомобиль, растительность и т. д.
Облако точек
Сегментация облака точек производится путем слияния семантической пиксельной информации и лидарных облаков точек. Таким образом, каждой 3D-точке присваивается метка типа объекта. Это зависит от точной регистрации камеры-лидара.
Рамки
3D-боксы предусмотрены для 12 499 кадров. Лидарные точки в поле зрения фронтальной камеры помечены 3D-рамками. Мы аннотируем 14 классов, имеющих отношение к вождению, например автомобили, пешеходы, автобусы и т. д.
2. Ford Autonomous Vehicle Dataset
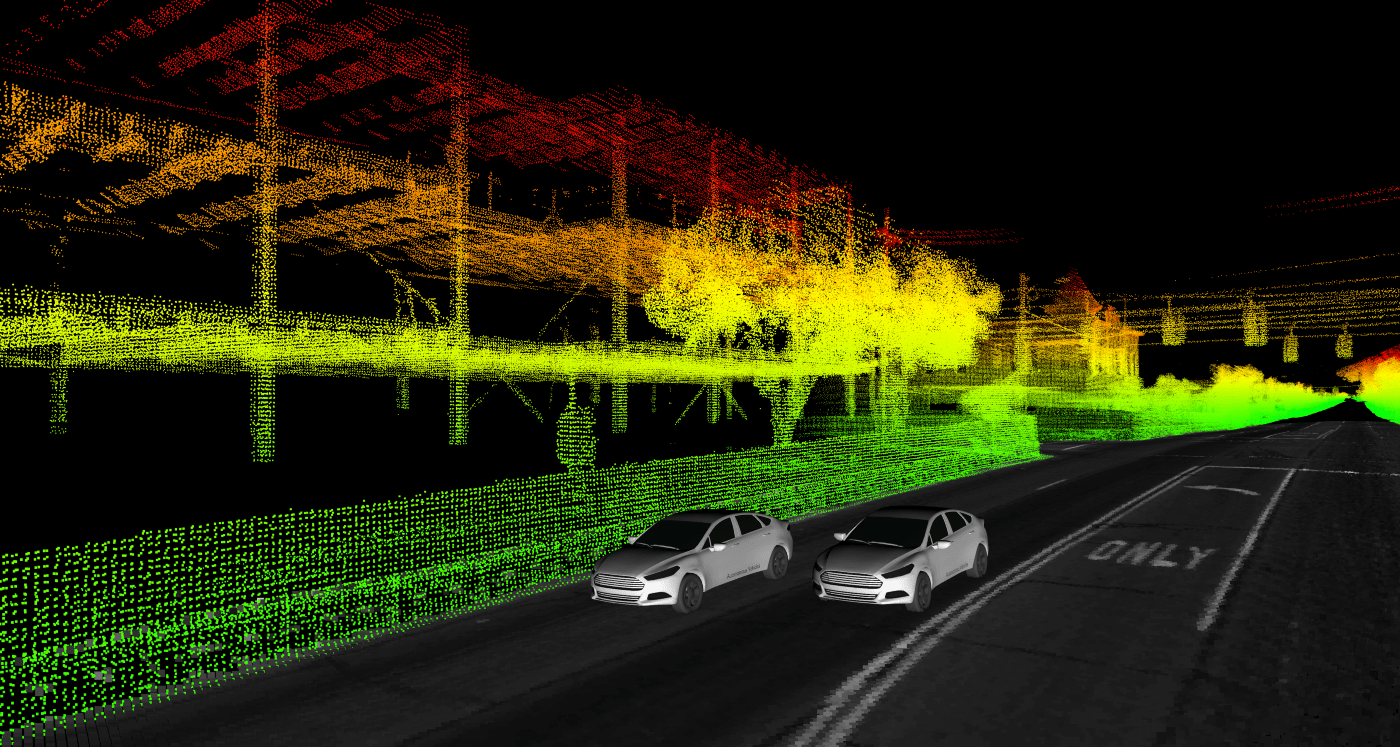
Мы представляем сложный мультиагентный сезонный датасет, собранный парком автономных транспортных средств Ford в разные дни и время в течение 2017–18 годов. Автомобили управлялись вручную по маршруту в Мичигане, который включал в себя сочетание сценариев вождения, включая поездку в аэропорт Детройта, автострады, городские центры, университетский городок и пригородный район.
Мы представляем сезонные изменения погодных условий, освещения, строительства и дорожного движения, наблюдаемые в динамичных городских условиях. Этот датасет может помочь в разработке надежных алгоритмов для автономных транспортных средств и мультиагентных систем. Каждый лог в наборе данных помечен временем и содержит необработанные данные со всех датчиков, калибровочные значения, pose trajectory, ground truth pose и 3D-карты. Все данные доступны в формате Rosbag, который может быть визуализирован, изменен и применен с помощью операционной системы робота с открытым исходным кодом (ROS).
Датасетх содержит данные с отметкой времени полного разрешения от следующих датчиков:
- Четыре HDL-32E Velodyne 3D-лидара
- 6 градаций серого 1.3 MP камеры
- 1 градация серого 5 MP Dash камера
- Applanix POS-LV IMU
Датасет также включает в себя:
- 3D Ground Reflectivity Maps
- 3D Point Cloud Maps
- 6 DoF Ground-truth Pose
- 3 DoF Localized Pose
- Преобразование и калибровка датчиков
3. Waymo Open Dataset

Waymo Open Dataset в настоящее время содержит 1 950 сегментов. Мы планируем увеличить этот набор данных в будущем. Вот что в настоящее время включено:
1950 сегментов по 20 секунд каждый, собранных на частоте 10 Гц (200 000 кадров) в различных географических условиях и условиях
Данные сенсоров
- 1 лидар среднего радиуса действия
- 4 лидар ближнего действия
- 5 камер (передняя и боковые)
- Синхронизированные данные лидара и камеры
- Лидар к проекциям камеры
- Калибровка датчиков и позиции транспортных средств
Размеченные данные
- Маркировки для 4 классов объектов — транспортные средства, пешеходы, велосипедисты, знаки
- Высококачественные маркировки для лидарных данных в 1200 сегментах
- 12.6M 3D-боксы с маркировкой с отслеживающими идентификаторами на лидарных данных
- Высококачественные маркировки для данных камеры в 1000 сегментах
- 11.8M 2D-боксы с маркировкой с идентификаторами отслеживания на данных камеры
Исходники
github.com/waymo-research/waymo-open-dataset
4. nuTonomy

Датасет nuScenes — это крупномасштабный автономный набор данных для вождения. Он имеет следующие особенности:
- Полный набор датчиков (1X лидар, 5X радар, 6X камера, IMU, GPS)
- 1000 сцен по 20 секунд каждая
- 1 400 000 изображений камеры
- 390 000 лидарных проходов
- Два разных города: Бостон и Сингапур
- Левостороннее и правостороннее движение
- Подробная информация о карте
- Ручные аннотации для 23 классов объектов
- 1.4M 3D-боксы аннотированные на частоте 2 Гц
- Атрибуты, такие как видимость, активность и поза
5. Dataset | Lyft Level 5
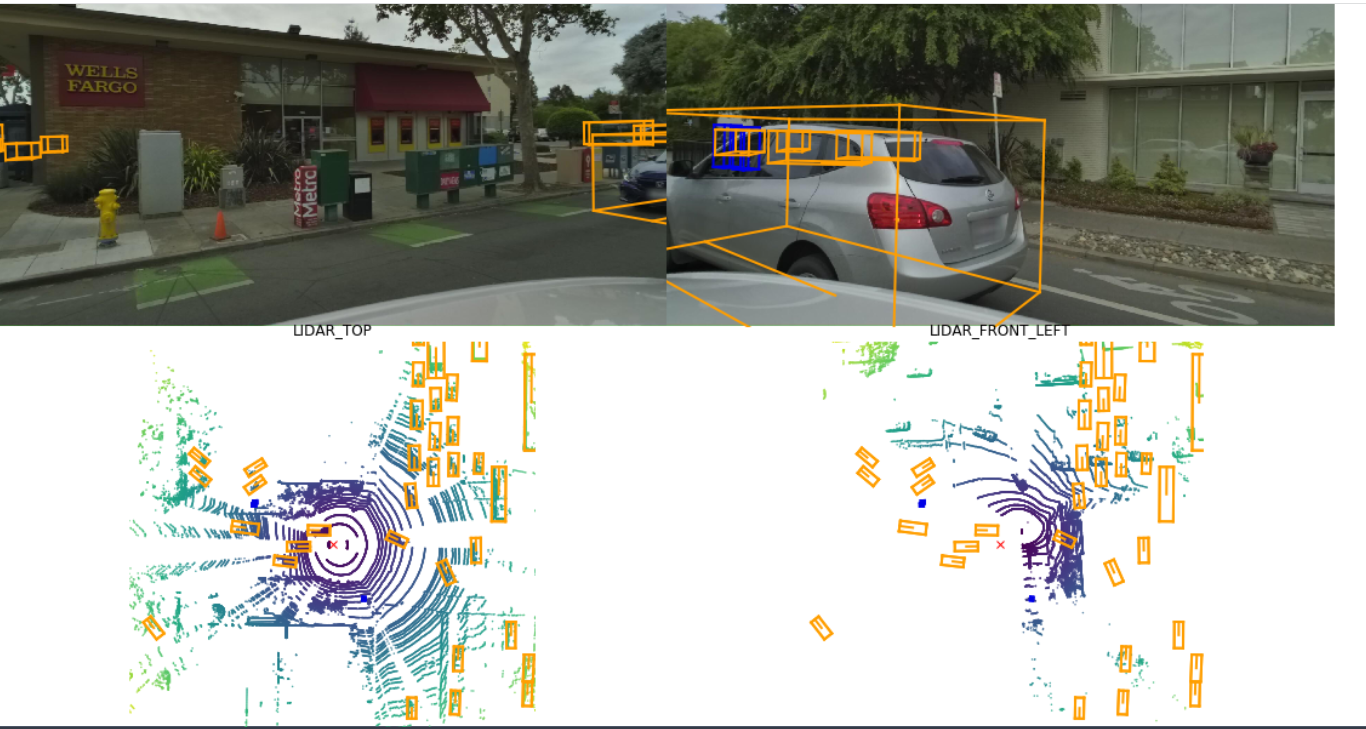
Все данные собираются автопарком автомобилей Ford Fusion. У нас есть две версии транспортных средств. Они указаны в их калибровочных данных как BETA_V0 и BETA_PLUS_PLUS. Каждый автомобиль оснащен следующими датчиками в зависимости от версии автомобиля:

BETA_V0 LiDARS:
- Один 40-лучевой лидар на крыше и два 40-лучевых лидара на бампере.
- Каждый лидар имеет разрешение по азимуту 0,2 градуса.
- Все три лидара совместно производят ~216 000 точек при частоте 10 Гц.
- Направления зондирования всех лидаров синхронизированы, чтобы быть одинаковыми в любой момент времени.
BETA_V0 Cameras:
- Шесть камер с широким полем зрения (WFOV) равномерно охватывают поле зрения на 360 градусов (FOV). Каждая камера имеет разрешение 1224×1024 и FOV 70°x60°.
- Одна камера с большим фокусным расстоянием установлена немного вверх, главным образом для обнаружения светофоров. Камера имеет разрешение 2048×864 и FOV 35°x15°.
- Каждая камера синхронизирована с лидаром таким образом, что Луч лидара находится в центре поля зрения камеры, когда камера захватывает изображение.

BETA_PLUS_PLUS LiDARS:
Единственное различие в лидарах между Beta-V0 и Beta++ это лидар на крыше, который является 64-лучевым для Beta++.
Синхронизация лидаров такая же, как и у Beta-V0.
BETA_PLUS_PLUS Cameras:
- Шесть камер с широким полем зрения (FOV) с высоким динамическим диапазоном равномерно охватывают 360-градусное поле зрения (FOV). Каждая камера имеет разрешение 1920×1080 и FOV 82°x52°.
- Одна камера с большим фокусным расстоянием установлена немного вверх, главным образом для обнаружения светофоров. Камера имеет разрешение 1920×1080 и FOV 27°x17°.
- Каждая камера синхронизирована с лидаром таким образом, что Луч лидара находится в центре поля зрения камеры, когда камера захватывает изображение.
Этот датасет включает в себя высококачественную семантическую карту. Семантическая карта предоставляет контекст для принятия решений о присутствии и движении агентов в сценах. Предоставленная карта содержит более 4000 сегментов полос движения (2000 дорожных сегментов и около 2000 перекрестков), 197 пешеходных переходов, 60 стоп-знаков, 54 парковочных зоны, 8 лежачих полицейских, 11 лежачих полицейских.
Все элементы карты регистрируются в базовой геометрической карте. Это одна и та же система отсчета для всех сцен в наборе данных.
6. UC Berkeley open-sources self-driving dataset

Video Data
Исследуйте 100 000 HD-видеопоследовательностей более чем 1100-часового опыта вождения в разное время суток, погодных условий и сценариев вождения. Наши видеопоследовательности также включают в себя местоположение GPS, данные IMU и временные метки.
Road Object Detection
2D-боксы аннотированы на 100 000 изображениях для автобуса, светофора, дорожного знака, человека, велосипеда, грузовика, мотора, автомобиля, поезда и всадника.
Instance Segmentation
Исследуйте более 10 000 разнообразных изображений с аннотациями на уровне пикселей и rich instance-level.
Driveable Area
Изучите сложное решение по управлению автомобилем из 100 000 изображений.
Lane Markings
Multiple types of lane marking annotations on 100,000 images for driving guidance.
Многотипное аннотирование разметки полосы движения на 100 000 изображениях для навигации.
7. The Cityscapes Dataset от Daimler

The Cityscapes Dataset focuses on semantic understanding of urban street scenes. In the following, we give an overview on the design choices that were made to target the dataset«s focus.
Cityscapes Dataset фокусируется на семантическом понимании городских уличных сцен. Ниже мы дадим обзор вариантов дизайна, которые были сделаны для того, чтобы достичь целей датасета.
Полигональные аннотации
- Плотная семантическая сегментация
- Сегментация экземпляров для транспортных средств и людей
Сложность
Разнообразие
- 50 городов
- Несколько месяцев (весна, лето, осень)
- Дневное время
- Хорошие / средние погодные условия
- Выбранные вручную кадры
- Большое количество динамических объектов
- Различные сцены макет
- Изменение фона
Размер
- 5 000 аннотированных изображений с прекрасными аннотациями (примеры)
- 20 000 аннотированных изображений с грубыми аннотациями (примеры)
Метаданные
- Предшествующие и конечные видеокадры. Каждое аннотированное изображение является 20-м изображением из 30-кадровых фрагментов видео (1,8 с)
- Соответствующие правые стерео виды
- координаты GPS
- Данные эго-движения из одометрии транспортного средства
- Наружная температура от датчика автомобиля
Расширения, сделанные другими исследователями
- Ограничивающая коробка аннотации людей
- Изображения дополненные туманом и дождем
Benchmark suite и оценочный сервер
- Семантическая маркировка пиксельного уровня
- Семантическая маркировка на уровне экземпляра
- Паноптическая семантическая маркировка
8. The KITTI Vision Benchmark Suite

Наша записывающая платформа оснащена четырьмя видео высокого разрешения камеры, лазерный сканер Velodyne и современная система локализации. Наши бенчмарки составляют 389 пар стерео и оптических потоков, стереовизуальные одометрические последовательности длиной 39,2 км и более 200 тысяч 3D-аннотаций объектов, снятых в захламленных сценариях (до 15 автомобилей и 30 пешеходов на изображении).

Мы, пожалуй, самый сильный в России центр компетенций по разработке автомобильной электроники. Сейчас активно растем и открыли много вакансий (порядка 30, в том числе в регионах), таких как инженер-программист, инженер-конструктор, ведущий инженер-разработчик (DSP-программист) и др.
У нас много интересных задач от автопроизводителей и концернов, двигающих индустрию. Если хотите расти, как специалист, и учиться у лучших, будем рады видеть вас в нашей команде. Также мы готовы делиться экспертизой, самым важным что происходит в automotive. Задавайте нам любые вопросы, ответим, пообсуждаем.
Читать еще полезные статьи:
