Data-mining и Твиттер
Среди социальных сетей Твиттер более других подходит для добычи текстовых данных в силу жесткого ограничения на длину сообщения, в которое пользователи вынуждены поместить все самое существенное.
Предлагаю угадать, какую технологию обрамляет это облако слов?
Используя Твиттер API можно извлекать и анализировать самую разнообразную информацию. Статья о том, как это осуществить с помощью языка программирования R.
Написание кода занимает не так уж много времени, сложности могут возникнуть из-за изменений и ужесточения Твиттер API, судя по всему компания всерьез озаботилась вопросами безопасности после выволочки в Конгрессе США по следам расследования влияния «русских хакеров» на выборы в США в 2016 г.
Зачем кому-то может понадобиться извлекать в промышленных масштабах данные из Твиттер? Ну например это помогает делать более точные прогнозы относительно исхода спортивных событий. Но я уверен, что есть и другие пользовательские сценарии.
Для начала понятно, что нужно иметь учетную запись Твиттер с указанием номера телефона. Это необходимо для создания приложения, именно этот шаг дает доступ к API.
Заходим на страницу разработчика и жмем на кнопку Create an app. Далее следует страничка на которой надо заполнить информацию о приложении. На данный момент страница состоит из следующих полей.
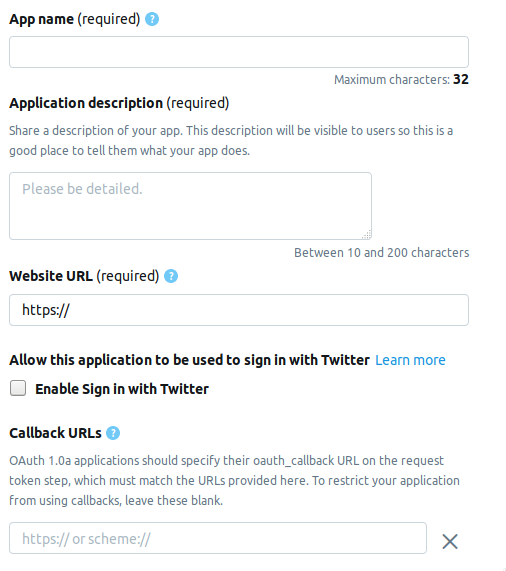
- AppName — имя приложения (обязательно).
- Application description — описание приложения (обязательно).
- Website URL — страница сайта приложения (обязательно), можно вписать все, что угодно похожее на URL.
- Enable Sign in with Twitter (check box) — Вход со страницы приложения на Твиттер, можно попустить.
- Callback URLs — Обратная вызов приложения при аутентификации (обязательно) и необходимо, можно оставить
http://127.0.0.1:1410.
Далее следуют необязательные к заполнению поля: адрес страницы условий предоставления услуг, имя организации и проч.
При создании учетной записи разработчика следует выбрать один из трех возможных вариантов.
- Standard — Базовый вариант, можно искать записи на глубину ≤ 7 дней, бесплатный.
- Premium — Более продвинутый вариант, можно искать записи на глубину ≤ 30 дней и с 2006 г. Бесплатный, но дают не сразу по рассмотрению заявки.
- Enterprise — Бизнес-класс, платный и надежный тариф.
Я выбрал Premium, ждать одобрения пришлось около недели. Не могу сказать всем-ли подряд дают его, но попытаться стоит в любом случае, а Standard никуда не денется.
После того, как вы создали приложение в закладке Keys and tokens появится набор содержащий следующие элементы. Ниже названия и соответствующие переменные R.
Consumer API keys
- API key —
api_key - API secret key —
api_secret
Access token & access token secret
- Access token —
access_token - Access token secret —
access_token_secret
Устанавливаем необходимые пакеты.
install.packages("rtweet")
install.packages("tm")
install.packages("wordcloud")
Эта часть кода будет выглядеть следующим образом.
library("rtweet")
api_key <- ""
api_secret <- ""
access_token <- ""
access_token_secret <- ""
appname=""
setup_twitter_oauth (
api_key,
api_secret,
access_token,
access_token_secret)
После аутентификации R предложит сохранить коды OAuth на диске, для последующего использования.
[1] "Using direct authentication"
Use a local file to cache OAuth access credentials between R sessions?
1: Yes
2: No
Оба варианта приемлемы, я выбрал 1-й.
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
Ключ include_rts позволяет контролировать включение в поиск, или исключение из него ретвитов. На выходе получаем таблицу с множеством полей, в которых есть подробности и детали каждой записи. Вот первые 20.
> head(names(tweets), n=20)
[1] "user_id" "status_id" "created_at"
[4] "screen_name" "text" "source"
[7] "display_text_width" "reply_to_status_id" "reply_to_user_id"
[10] "reply_to_screen_name" "is_quote" "is_retweet"
[13] "favorite_count" "retweet_count" "hashtags"
[16] "symbols" "urls_url" "urls_t.co"
[19] "urls_expanded_url" "media_url"
Можно составить более сложную строку поиска.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+")
search_tweets(search_string, include_rts=FALSE, n=100)
Результаты поиска можно сохранить в текстовом файле.
write.table(tweets$text, file="datamine.txt")
Сливаем в корпус текстов, производим фильтрацию от служебных слов, знаков пунктуации и переводим все в нижний регистр.
Существует еще одна функция поиска — searchTwitter, для которой требуется библиотека twitteR. В чем-то она удобнее search_tweets, а в чем-то ей уступает.
Плюс — наличие фильтра по времени.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500)
text = sapply(tweets, function(x) x$getText())
Минус — вывод не таблица, а объект типа status. Для того, чтобы его использовать в нашем примере нужно из вывода вычленить текстовое поле. Это и делает sapply во второй строке.
corpus <- Corpus(VectorSource(tweets$text))
clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte"))
tdm <- TermDocumentMatrix(clearCorpus, control =
list(removePunctuation = TRUE,
stopwords = c("com", "https", "hadoop", stopwords("english")),
removeNumbers = TRUE,
tolower = TRUE))
Во второй строке функция tm_map нужна для того, чтобы перевести всякие эмоджи символы в строчные, иначе конвертация в нижний регистр с помощью tolower завершится с ошибкой.
Облака слов впервые появились на фото-хостинге Фликр, насколько мне известно и с тех пор обрели популярность. Для этой задачи нам понадобится библиотека wordcloud.
m <- as.matrix(tdm)
word_freqs <- sort(rowSums(m), decreasing=TRUE)
dm <- data.frame(word=names(word_freqs), freq=word_freqs)
wordcloud(dm$word, dm$freq, scale=c(3, .5),
random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Функция search_string позволяет задать в качестве параметра язык.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
Однако ввиду того, что NLP пакет для R плохо русифицирован, в частности нет списка служебных, или стоп-слов, построение облака слов с поиском на русском у меня не получилось. Буду рад, если в комментариях найдут лучшее решение.
Ну, и собственно…
library("rtweet")
library("tm")
library("wordcloud")
api_key <- ""
api_secret <- ""
access_token <- ""
access_token_secret <- ""
appname=""
setup_twitter_oauth (
api_key,
api_secret,
access_token,
access_token_secret)
oauth_callback <- "http://127.0.0.1:1410"
setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret)
appname="my_app"
twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret)
tweets <- search_tweets("devops", include_rts=FALSE, n=600)
corpus <- Corpus(VectorSource(tweets$text))
clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte"))
tdm <- TermDocumentMatrix(clearCorpus, control =
list(removePunctuation = TRUE,
stopwords = c("com", "https", "drupal", stopwords("english")),
removeNumbers = TRUE,
tolower = TRUE))
m <- as.matrix(tdm)
word_freqs <- sort(rowSums(m), decreasing=TRUE)
dm <- data.frame(word=names(word_freqs), freq=word_freqs)
wordcloud(dm$word, dm$freq, scale=c(3, .5),
random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Использованные материалы.
Краткие ссылки:
Оригинальные ссылки:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
P.S. Подсказка, ключевое слово облака на КДПВ не используется в программе, оно связано с моей предыдущей статьей.
