Дата-инжиниринг в превосходных условиях
Привет, Хабр!
Меня зовут Артемий Козырь, я занимаюсь дата-инжинирингом в команде аналитики Wheely. А конкретнее — построением аналитических решений, начиная с основ и до конечного результата: подключение источников, очистка и трансформация данных, организация хранилища и детального слоя, формирование витрин и дашбордов.

В этом посте я сделал верхнеуровневый обзор решений, подходов и фреймворков, которые мы используем для развития Wheely: оптимизации операционной деятельности, планирования, построения отчетности и проверки гипотез. И еще немного похвастаться (куда без этого), потому что инструменты, которые мы используем в Wheely, сегодня набирают огромную популярность на Западе, но в России пока далеко не каждая компания готова их адаптировать.
Источники данных
Первый кубик в этой системе — это источники данных. Я разделяю их на несколько групп, у каждой из которых свои особенности.
Источники данных Wheely
Первая группа источников — нереляционные базы данных класса NoSQL. С самого основания компании в Wheely используется популярная документ-ориентированная БД MongoDB.
MongoDB обеспечивает работу мобильных приложений (основная операционная деятельность) и значительной части микросервисов:
начисление бонусов водителям
служба поддержки и заботы о клиентах
синхронизация расписания авиарейсов
геосервисы
Основные особенности MongoDB:
гибкая модель данных (schemaless), вложенные иерархические структуры данных (nested data)
оптимальное хранение и поисковые структуры (индексы)
легко начать строить сервисы и перейти к продвинутой разработке
поддержка механизмов репликации и шардинга
С точки зрения бизнеса важнейшим преимуществом является тот факт, что MongoDB позволяет хранить данные в виде полуструктурированных документов. Если внезапно меняются требования, возникают новые идеи, например, мы вдруг захотим сохранять версию ОС и приложения клиента, причины отмены бронирования, время водителей на линии для последующей аналитики, — эти данные можно добавить буквально в считанные секунды, и нам не придется ничего менять. Время от идеи до внедрения (Time to Market, T2M) — одна из наиболее важных метрик. А требования бизнеса, как вы знаете, обычно очень динамичны и могут меняться буквально на ходу. Так что скорость и гибкость это не столько плюшка, сколько насущная необходимость в нормальной работе.
Эволюция схемы документа MongoDB (поездка)
MongoDB позволяет очень быстро и гибко поддерживать текущие операции: поиск водителей, оформление поручений и бронирований, одновременный просмотр приложения пользователями и ответы на их вопросы в режиме реального времени — где сейчас машина, сколько будет стоить поездка, и другие. Такой характер нагрузки на БД можно охарактеризовать как OLTP (Online transaction processing). И это именно поддержка операционной деятельности компании.
Но нам бы хотелось строить сводную отчетность, например, по динамике количества поездок, объема выручки, величины среднего чека, количества сеансов и конверсий клиентов. Плюс, мы постоянно внедряем новые продукты и сервисы, выпускаем новые версии приложений, проводим PR-кампании, выстраиваем коммуникацию с клиентами. В идеале задействовать все доступные источники событий и смотреть на таймлайне, как меняются ключевые бизнес-метрики. Такой характер нагрузки уже можно назвать OLAP (Online Analytical Processing).
Однако MongoDB едва ли предназначена для поддержки разнообразия аналитических решений, спрос на которые в Wheely только возрастает.Значит, данные следует переместить в такое хранилище, которое будет предназначено для аналитических нагрузок (спойлер: это Amazon Redshift).
Вторая группа источников — классические реляционные базы данных, имеющие поддержку транзакций и требований ACID. Чаще всего мы используем PostgreSQL (его облачную версию на Amazon RDS). Предназначены они, в основном, для поддержки работы финансовых сервисов. Например:
формирование и отправка фискальных чеков
подсчет бонусов для водителей
бухгалтерская отчетность
Третья группа источников — всевозможные внешние сервисы и системы:
Воронка взаимодействий с push-уведомлениями (Braze)
Все эти данные мы тоже тщательно собираем и агрегируем у себя в хранилище. Эти источники позволяют обогащать витрины, формировать сегменты пользователей (аудитории), и проводить эффективные рекламные кампании.
Четвертую группу источников можно назвать пользовательской — это Google Sheets. Сервис активно используют бизнес-юзеры, чтобы быстро подготовить какие-либо справочники, маппинги и регулярно актуализировать данные в них. Например, это может быть Partnership manager, который указывает UTM-метки, промокоды, комиссионные вознаграждения для партнерских программ. После внесения изменений, данные появляются у нас в течение короткого промежутка времени, и мы можем отразить изменения в своих отчетах.
Интеграция в Хранилище Данных
ОК, отлично, мы классифицировали источники данных. Теперь нужно понять, как извлечь оттуда данные и доставить в место, где мы будем их анализировать. В работе с каждым из источников есть тонкости и нюансы, к которым нужно быть готовым.
Во-первых, каждый источник имеет свой тип подключения: это может быть драйвер JDBC, запросы через REST API, утилиты командной строки. В общем, не то чтобы зоопарк, но различий хватает. И каждое нужно поддерживать в актуальном и рабочем состоянии, иначе мы можем потерять данные.
Второй важный челлендж — следить за нагрузкой на базу-источник. Если источник поддерживает высоконагруженный сервис, то наша задача — минимизировать дополнительную нагрузку и следы своего присутствия, чтобы случайно не положить базу. Идеальный случай — читать лог изменений с read-only реплики. Это Oplog для MongoDB и Write-ahead log (WAL) для PostgreSQL.
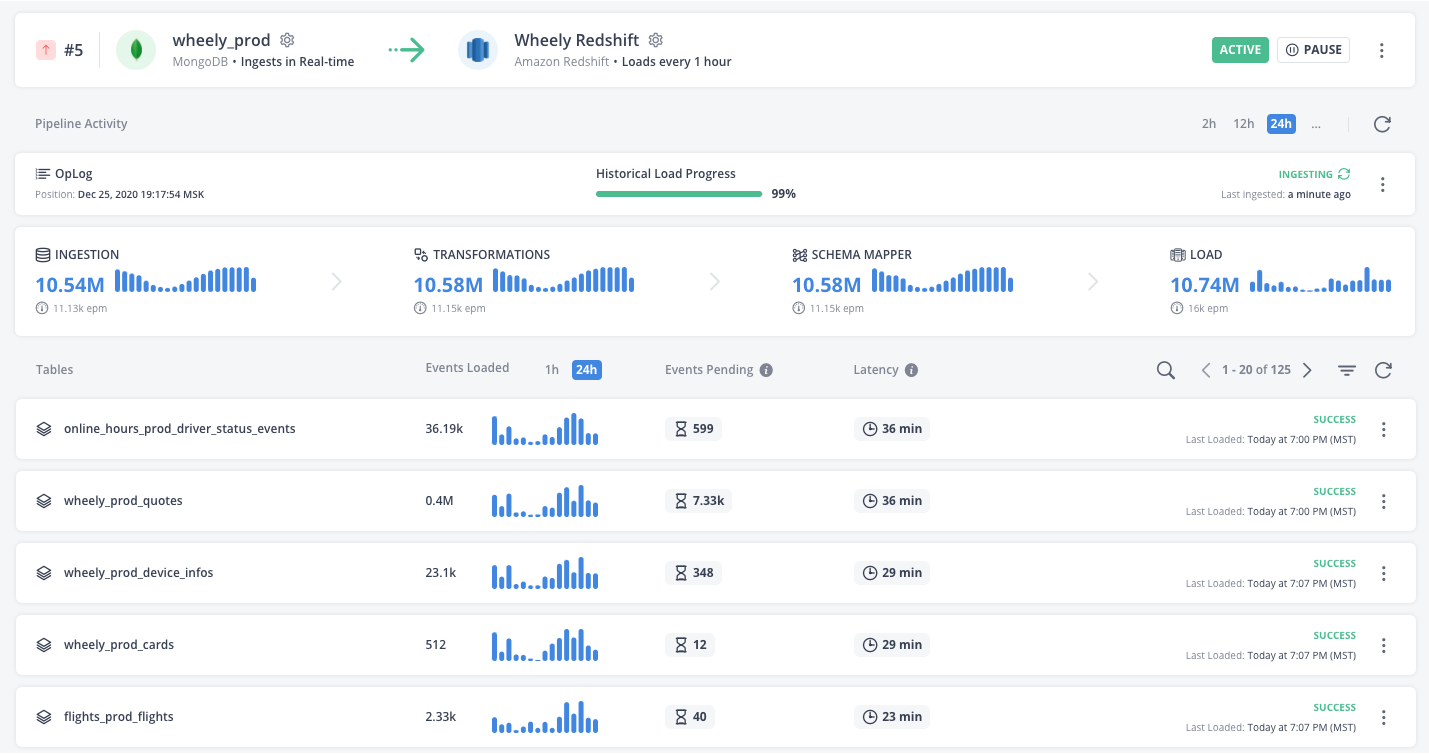 Статус выгрузки из MongoDB (бэкенд мобильных приложений)
Статус выгрузки из MongoDB (бэкенд мобильных приложений)
Третий нюанс: синхронизация самых важных источников в режиме реального времени. Технически говоря — это CDC (Change Data Capture). Очень хочется идти в ногу с источниками и иметь минимальные отставания. Для этого необходимо научиться получать дельту (инкремент, изменения данных) и уметь ее накатывать в Хранилище Данных.
Четвертый пункт касается обширной темы качества данных. Когда мы реплицируем источник, очень важно убедиться, что мы прочли все события (1), что все они достигли цели (2), причем пришли именно в единственном экземпляре (3) и ровно в том виде, как они есть в источнике (4). И конечно отразить эти события в Хранилище согласно последовательности, в которой эти события происходили (5). В случае необходимости желательно уметь перемотать назад и проиграть события еще раз начиная с какого-то момента времени (будто нажать rewind & play на магнитофоне).Для извлечения данных мы используем облачный ETL-сервис Hevo. По сути это частичный аутсорсинг всех вышеперечисленных аспектов в отдельную компанию, которая на них специализируется, работает по SLA и оказывает поддержку. Частичный — потому что существенная доля ответственности всё же остается на пользователе сервиса. Если вам интересно — напишите в комментах, и я сделаю отдельный пост про этот сервис, как мы выбирали провайдера, критерии, тесты. Сейчас скажу только, что альтернативами были Alooma, Fivetran и Stitch.
Схема потоков данных Wheely
Hevo поддерживает широкий набор коннекторов и удовлетворяет почти всем нашим техническим требованиям, плюс ко этому у него есть полезная фича — слой трансформации. Hevo оперирует событиями (event) — любая вставка, изменение, удаление есть событие, и его можно пропустить через слой трансформации. Иными словами — это обработка потоков событий (Event Stream Processing, ESP).
Так какие же трансформации мы применяем к потокам данных в Hevo?
Самое основное — удаление персональных данных: имя, фамилия, номер телефона, личные данные водителя, номер водительской лицензии, где он живет и как его зовут. Плюс информация об адресах мест начала и окончания поездок. Все эти данные просто не попадают в наше Хранилище.
Во-вторых, для целей сегментации и аналитики мы рассчитываем обезличенные хеш-суммы. Например, применяем к email-адресу хэш-функцию. В результате, мы обезличили электронный адрес, но сохранили некий идентификатор, по которому можно измерить результативность маркетинговых кампаний или построить связи с другими датасетами.
Трансформации позволят получить еще ряд очень полезных результатов:
Парсинг значений из вложенных иерархических структур (JSON)
Получение почтового домена (лидируют gmail.com, mail.ru, icloud.com)
Наименование страны по префиксу страны в телефонном номере (ОАЭ и Монако тоже есть)
Выглядеть это может следующим образом:
from io.hevo.api import Event
import json
import hashlib
from phoneiso3166.country import phonecountry, InvalidPhone
# prepare email string and calculate sha256
def emailhash(mes):
if mes:
try:
prep = mes.strip().lower()
return hashlib.sha256(prep).hexdigest()
except:
return None
# extract email domain from address
def emaildomain(mes):
if mes:
try:
prep = mes.split('@')[1]
return prep
except:
return None
# extract country code from phone number
def phonecountrycode(phonenumber):
try:
return phonecountry(phonenumber)
except:
return None
# main transformation handler
def transform(event):
# Get event name & its properties
eventName = event.getEventName()
properties = event.getProperties()
if eventName == 'users':
# calculate hash values
properties['emailsha256'] = emailhash(properties.get('email'))
properties['emaildomain'] = emaildomain(properties.get('email'))
properties['phonecountry'] = phonecountrycode(properties.get('phone'))
# drop pii for all events
pii = ['email', 'firstname', 'lastname', 'phone', 'pendingphone', 'hashedpassword', 'photo_url', 'keywords']
[properties.pop(p, None) for p in properties.keys() if p in pii]
return eventОркестрация вычислений и периодических задач
У нас есть ряд джобов, которые реализуют довольно сложную логику, затрагивают как минимум несколько сервисов, составляют последовательность действий. При этом их необходимо выполнять регулярно, по расписанию. Это набор заданных действий максимально близок к бизнес-целям. Для оркестрации таких вычислений мы используем Apache Airflow.
Airflow — это очень популярный и распространенный сегодня инструмент для оркестрации вычислений, при этом в нем очень гибко комбинировать задачи в цепочки, применять логику ветвления (if-else), вести лог выполненных действий, получать уведомления об ошибках. Это конструктор, в котором минимальными кубиками выступает запуск почти любых функций, команд, утилит. Из этих строительных блоков мы составляем цепочку, джобу целиком — DAG (Directed Acyclic Graph), дерево, которое выполняет «кубики» в заданной последовательности и с заданными условиями.
Последовательность задач для проверки качества данных
Одной из самых важных задач Airflow является формирование отчетов для Business Review — регулярных стратегических встреч. Вся компания использует Notion, популярный Wiki-Portal. Для нас он очень удобен: вся документация, странички, обсуждения будущих фичей, планы, KPI и квартальные цели, регулярные встречи ведутся именно в Notion.
Руководство и операционная команда получают готовую страничку с рядом отчетов, визуализацией, в разбивке по ключевым метрикам — demand, operations, marketplace, support и другим. Плюсом к этому идут верхнеуровневые общие метрики, визуальные графики, выполняются разбивки по регионам и странам. В такой разбивке формируется страница в Notion и наполняется отчетами.
 Стратегическое планирование в Notion (без blur никак)
Стратегическое планирование в Notion (без blur никак)
Все это запрограммировано с помощью Airflow. Под капотом мы запрашиваем по API из BI-инструмента Looker ряд отчетов с применением фильтров, формируем PDF-выгрузки и программно наполняем страницу содержимым. Получается красивый отчет с заголовками, содержанием, и каждый вторник к 9 утра страница готова. И когда люди приходят в офис, они начинают готовиться, оставляют комментарии, вопросы друг другу, имея четкую фактологию и метрики, что помогает проводить встречи более продуктивно.
Помимо интерактива большой плюс этих отчетов в том, что каждую неделю формируется отдельная страничка, и можно посмотреть историю: что было неделю, месяц назад, каков статус сегодня и как мы прогрессируем. Все отчеты сохраняются, и для нас это очень важно.
Во-вторых, в Airflow также запрограммирован pipeline для проверки качества данных. Есть несколько тасков. Один таск вычитывает данные из MongoDB, второй загружает их в Redshift, третий сравнивает две выборки. Дальше формируется сводная таблица, где видно разницу между источником и приемником: где записей больше, а где меньше, что в процессе потерялось, есть ли расхождения между этими записями. Для нас важно предоставлять максимально достоверную информацию — стоимость поездки, комиссия, время создания и окончания поездки, ее статус, рейтинг водителя и т.п. И колонки сравниваются на уровне каждой отдельной ячейки.
Дашборд статуса Data Quality
Еще один пример использования Airflow — формирование гексагонов для визуальной группировки геоданных. У нас визуально формируются карты-heatmaps, которые подсвечиваются разными цветами в зависимости от значения рассчитанной метрик, например, количество заказов или Estimated time of arrival, ETA (расчетное время прибытия)
Формирование гексагонов обеспечивает библиотека h3-py в Python. Airflow поддерживает процесс регулярной выгрузки координат начала и окончания поездок, например, за каждые 3 часа. Эти данные за интервал 3 часа группируются в несколько тысяч разноцветных многоугольников на карте, и возвращаются в Хранилище. Так мы очень быстро и наглядно видим, что в одной зоне у нас была, допустим, тысяча заявок, а в другой всего сто.
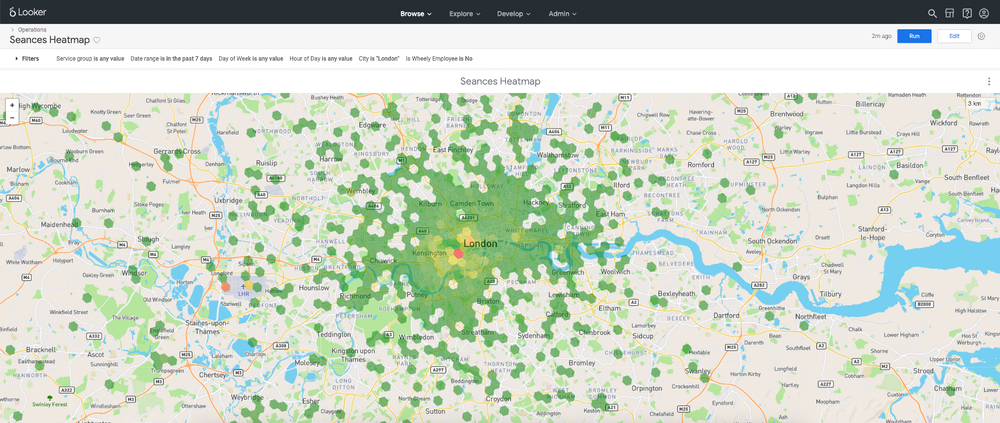 Визуализация метрик на карте (пользовательские сессии)
Визуализация метрик на карте (пользовательские сессии)
Резюмируя, главные преимущества Airflow для нас, это:
Максимальная гибкость в конфигурации задач
Легкость в расширении функционала. Уже пользуемся уведомлениями в Slack, попытками повторного запуска (retry), расширенным логированием.
Активное и динамичное развитие продукта и коммьюнити вокруг него.
Надежный фундамент как основа работы с данными
Несмотря на гетерогенный характер источников данных, скорость их изменений и рост объема данных, мы смогли построить гибкую, масштабируемую и, что самое главное, управляемую платформу — основу для работы с данными.
Прозрачные процессы, документирование, использование профессиональных сервисов, версионирование (version control), совместная работа (peer review) и полномасштабное тестирование данных и пайплайнов позволяет значительно улучшить надежность решений. Уведомления о любых падениях и ошибках мы незамедлительно получаем в Slack, и последнее время такие уведомления скорее редкость, нежели чем обычное явление.
Ну и, конечно, низкий порог входа для новых членов команды. Процесс Onboarding нового аналитика длится 1 неделю, в течение которой человеку предоставляется возможность настроить инструменты и подключения, посмотреть и потрогать весь data-stack, и полноценно погрузиться в процесс решения задач.
Впереди у нас вторая часть доклада:
Организация детального слоя и витрин (знакомьтесь с dbt — Data Build Tool)
Бизнес-аналитика (BI) и Демократизация доступа к данным (приветствуйте Looker)
Культура проведения исследований, проверки гипотез и презентации результатов (DS + Jupyter)
Пока можете приглядеться к Wheely, нашим ценностям и тому, куда мы идем.
Спасибо за внимание. Я с удовольствием отвечу на вопросы в комментариях.
