Dashboard as a code, или как мы создание дашбордов автоматизировали
Привет! Мы в QIWI довольно давно применяем микросервисную архитектуру, но ее понимание не всегда было одинаковым: оно менялось со временем и эволюционировало. Наши первые микросервисы были достаточно большие по объему, но сейчас мы создаем сервисы гораздо меньшего размера с более узкой и ограниченной зоной ответственности.
Часто такой сервис отвечает за конкретную небольшую фичу в нашем продукте (или вообще за часть фичи), или же за часть какого-то большого процесса. Нам такой подход нравится, поскольку микросервисы имеют независимые жизненные и релизные циклы, мы можем релизить фичи независимо друг от друга. Кроме того, различные команды могут работать в рамках одного продукта параллельно над разными фичами, не мешая друг другу и не сталкиваясь лбами. Это даёт нам возможность независимо масштабировать микросервисы и гораздо быстрее проверять гипотезы. В общем, плюсов много.

Сейчас будет «Но», правда?
Но в системе, которая состоит из большого количества маленьких взаимодействующих компонентов, становится критически важным такое качество, как наблюдаемость. Нам нужны как некие высокоуровневые метрики, показатели, чтобы видеть, как система живет в целом, так и для каждого компонента, для каждого нашего микросервиса —нужно видеть его текущие рабочие показатели и получать уведомления, если эти показатели выходят за пределы нормы. Поскольку новые фичи мы делаем часто, то и новые микросервисы мы разрабатываем часто, получилось так, что настройка дашбордов и конфигурация алертов превратились в такую рутину, которая отнимает существенную часть времени. Так что всё это хотелось бы автоматизировать.
Давайте посмотрим еще с другой стороны на дашборды и алерты.
Итак, для нас наблюдаемость — критически важное качество продукта, над которым мы работаем. В нашем Кошельке настройка дашбордов и алертов является частью Definition of Done нашего продукта: любая команда в компании, которая захочет внести изменения в Кошелёк, должна будет эту работу сделать. Её нужно будет настроить или актуализировать дашборды, сконфигурировать новые или исправить пороги существующих алертов.
И вот так мы пришли к пониманию того, что для нас алерты и дашборды — это неотъемлемая часть разрабатываемого нами продукта. Поэтому стало логичным эти отношения узаконить и размещать описания дашбордов и алертов на некоем языке совместно с исходным кодом того микросервиса, для которого они настраиваются.
Подход «Все есть код» у нас в компании как философия живет достаточно давно: инфраструктура является кодом, вместе с исходным кодом микросервиса хранится описание его pipeline CI/CD на Kotlin DSL, описание требований к сетевым доступам — всё это хранится в формате описания совместно с исходным кодом. Мы считаем очень логичной ситуацию, когда конфигурация дашбордов и конфигурация алертов тоже хранились рядом с исходным кодом, проходили code review, хранились в системе контроля версий — чтобы была видна связь изменений в логике сервиса с изменениями алертов и дашбордов, которые для этого сервиса предназначены.
Так вот, про автоматизацию. Если у нас описание дашборда и описание алертов будут в виде некоего исходного кода, то код мы умеем генерить, то есть это позволит нам достичь наших целей по автоматизации путем автогенерации кода дашбордов.
Мы, как и многие из вас, используем Grafana для визуализации наших дашбордов, поэтому первая мысль была использовать JSON Model Grafana для загрузки и для описания дашбордов: ведь Grafana умеет работать с таким форматом, можно при помощи API Grafana создавать дашборды в таком формате, выгружать их оттуда и делать все, что угодно.
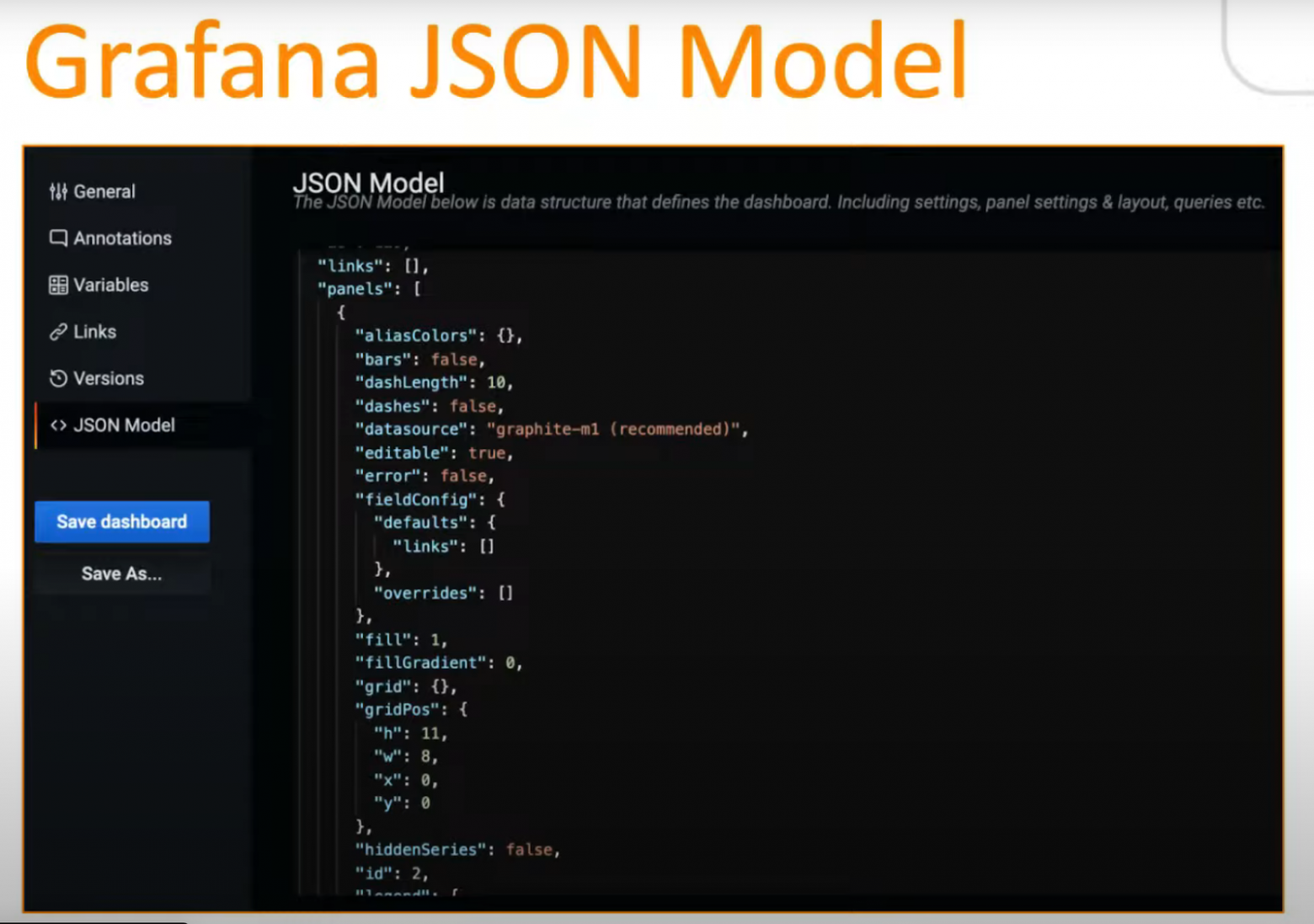
Но, к сожалению, такое описание очень трудное для восприятия человеком, оно на очень высоком уровне детализации и низком уровне абстракции. Понимать его вручную, визуально, вносить какие-то изменения в него вручную, фактически, невозможно.
К счастью, оказалось, что мы не единственные начали идти по этому извилистому пути, и для различных языков программирования уже существуют DSL, позволяющие более удобно описать дашборд. На более высоком уровне, более емко, более лаконично и более понятно. Есть и популярное решение для Python, но, поскольку у нас в компании развита JVM-экосистема, а в Кошельке Kotlin занимает сейчас доминирующее положение как язык разработки, наше внимание привлек open source проект от компании ЮMoney Grafana Dashboard DSL, который позволяет описать дашборд на Kotlin.
Вот пример того, как может выглядеть описание дашборда на Kotlin DSL.
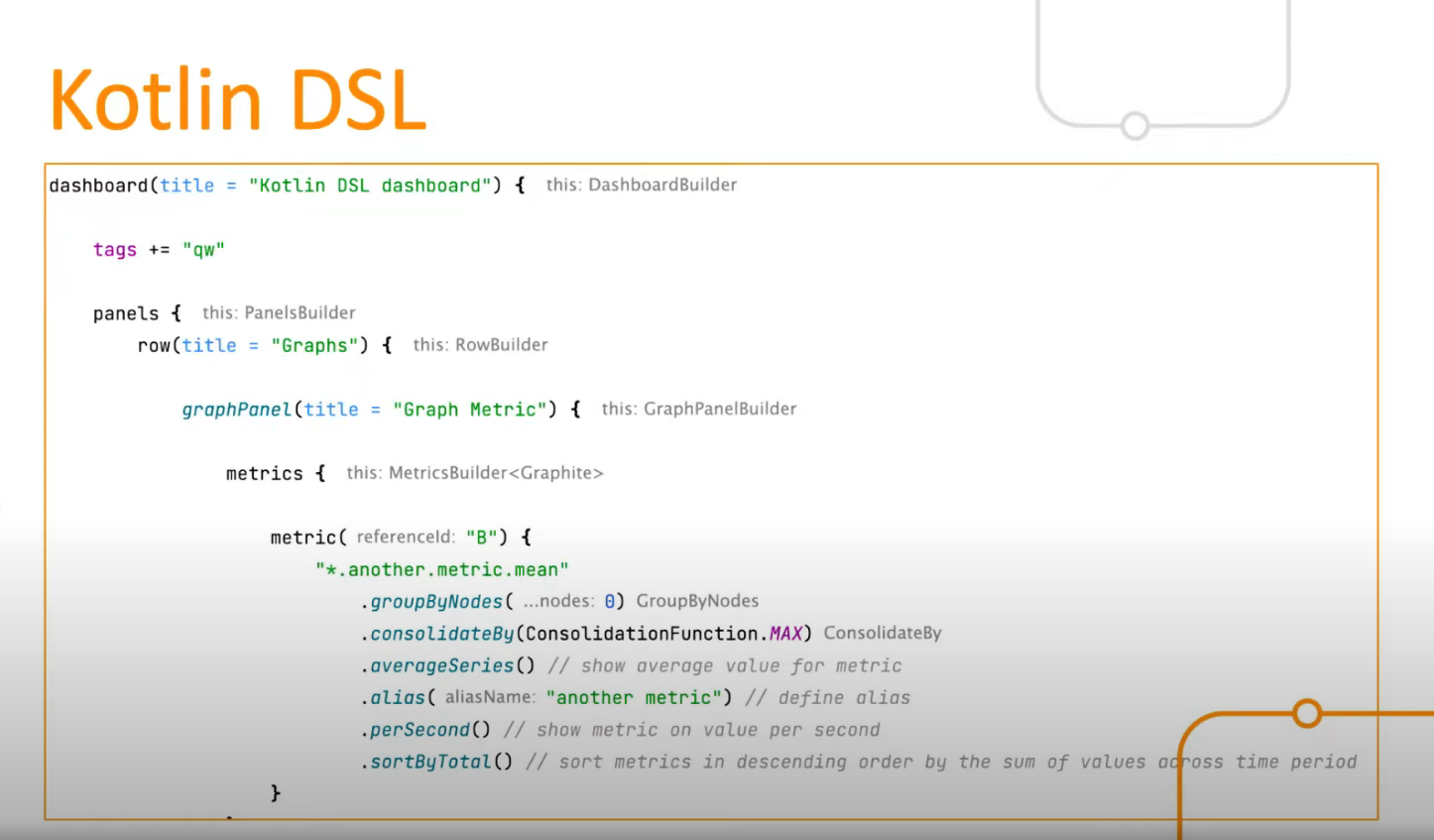
Объявляется дашборд, добавляются необходимые теги, создаются панели, объявляется метрика, указывается имя метрики, функции, которые к ней предъявляются, фактически, все возможности Grafana воплощены в этом Kotlin DSL.
Но мы захотели пойти чуть-чуть дальше, сделать описание дашбордов еще более лаконичным, понятным и коротким. Мы уже давно для продукта выработали договоренности по написанию дашбордов и созданию метрик. Договорились о том, какие используем имена, в каком формате пишем метрики, какой тип данных, для чего мы обязательно пишем метрики.
Это дало нам возможность использовать подход convention over configuration, то есть вместо детальной конфигурации каждой панели с указанием полного имени метрики, всех функций, единиц измерения и так далее, мы можем конструировать наш дашборд на более высоком уровне абстракции. К примеру, если у микросервиса есть rest API, то обязательно на его дашборде будет панель с частотой запросов к endpoint«ам этого микросервиса, со временем обработки запросов и так далее.

Поскольку все микросервисы пишут эти метрики схожим образом, (де-факто отличается только имя сервиса, имя контроллера, имя хоста, то есть какие-то конкретные понятные части общего имени, у которого есть определенно заданный формат), то нам не требуется полная многословная конфигурация каждой панели. Вместо этого мы можем просто сказать: «Отобрази на мне панель времени обработки запроса для такого-то сервиса или для такого-то endpoint«а определенного контроллера» и подобное.
Покажу вам еще один пример.
Поскольку все наши микросервисы пишут метрики по ошибкам в общем стандартном формате, для добавления панелей по ошибкам у нас также нет необходимости полностью и детально конфигурировать каждую панель. Это позволяет нам иметь более короткое, ёмкое и лаконичное описание.
Для всех наших типовых панелей и самых основных метрик мы сделали расширение для Kotlin DSL, которое позволяет нам описывать дашборды в таком формате. Но есть кое-что еще. Мы заметили, что большинство наших микросервисов имеет очень похожие дашборды, некоторые вообще как будто под копирку. И действительно, если у микросервиса есть rest API, то там будет панель со временем обработки запросов, с частотой запросов.
Если у микросервиса есть база данных, то там, само собой, будет панель со временем и количеством запросов к БД, панели по количеству соединений и так далее. То есть, зная, с чем интегрируется микросервис и как он устроен, что он использует, имея профиль этого микросервиса, можно фактически «автоматом» сгенерировать необходимые для нас дашборд и алерты.
Так мы и сделали автоматическую генерацию дашбордов. Оживает всё это при помощи Maven-плагина, который мы для себя написали. У него есть таска generate, сейчас я покажу, как она работает.

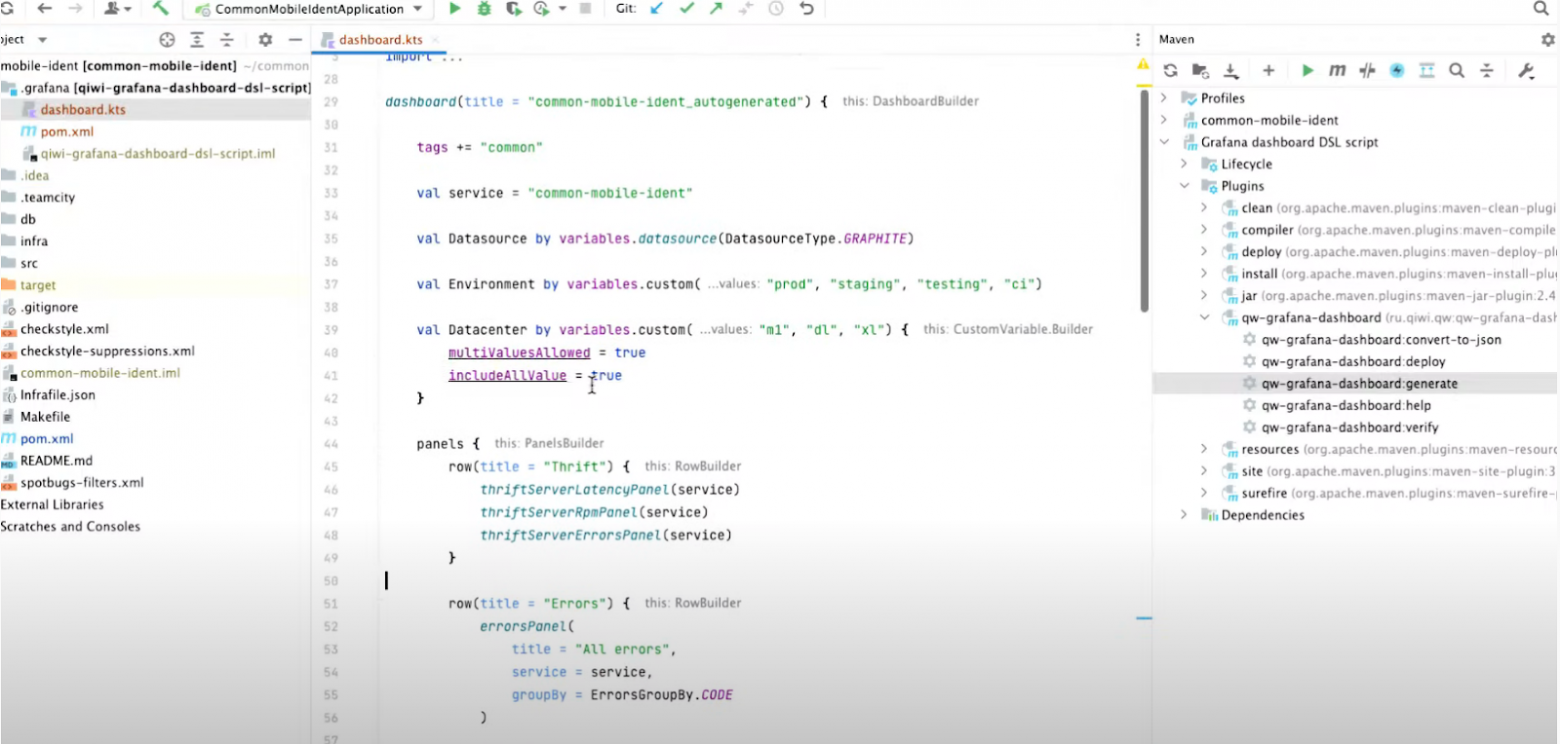
Открываем проект, запускаем автогенерацию. Все, дашборд сгенерирован.
Что здесь произошло? Мы проанализировали зависимости этого микросервиса и его исходный код, а затем построили профиль Metadata.
Мы выяснили, что rest API у микросервиса нет, но у него есть ThriftServer и ThriftClient. Мы в QIWI активно используем Thrift для межсервисного синхронного взаимодействия, и вот в этом сервисе есть API, которые он предоставляет другим сервисам и API, которые он потребляет как клиент.
Также генератор дашбордов выяснил, что у сервиса есть своя база данных и фоновые задачи. Этой информации хватило, чтобы построить дашборд. Он сгенерировался в виде Kotlin здесь, в каталоге Grafana, рядом есть каталог teamcity, в котором находится описание pipeline и CI/CD, тоже на Kotlin DSL.
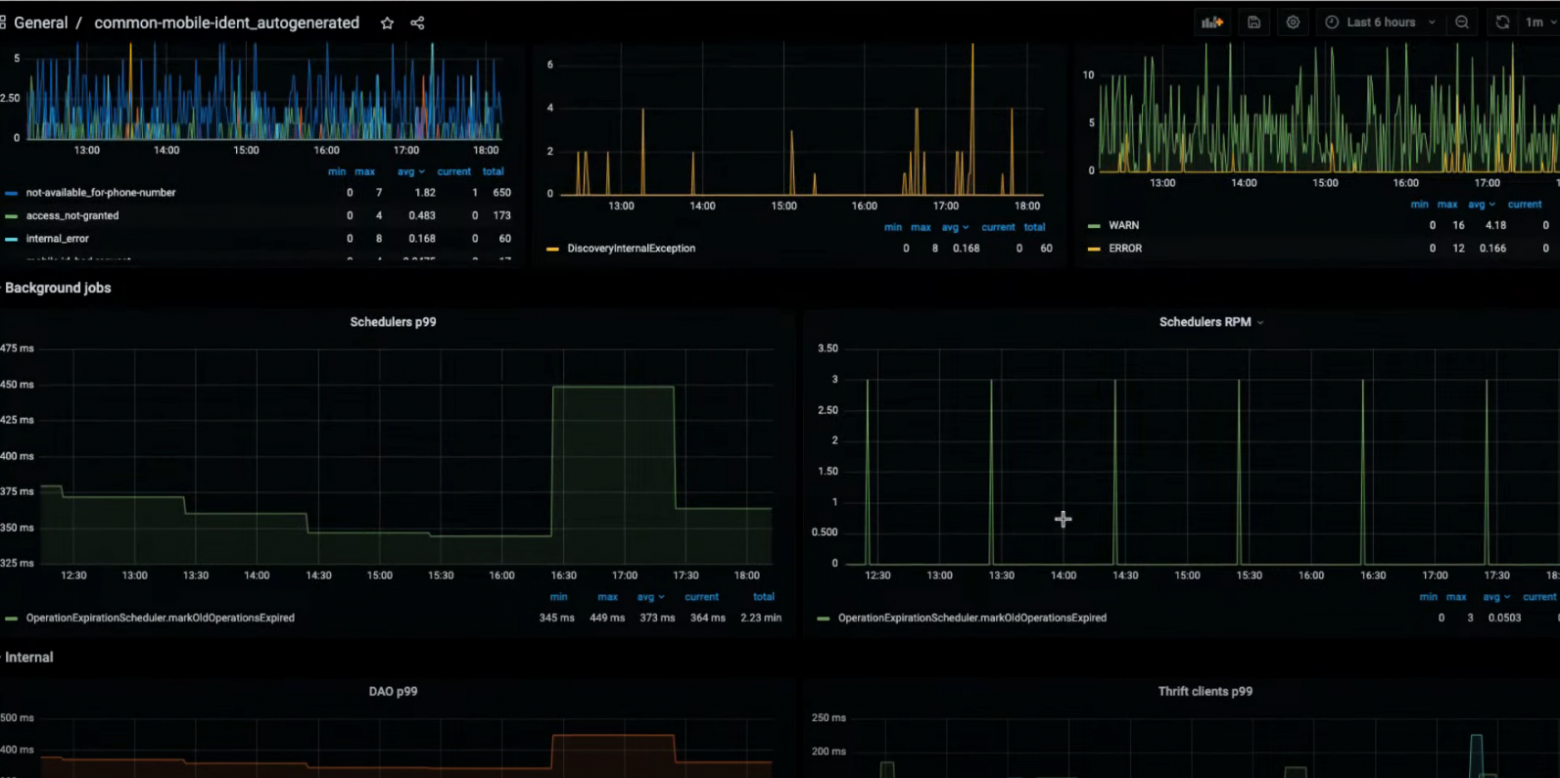
Вот наш свежесгенерированный дашборд.
Давайте посмотрим, как он оживает в Grafana.
Запустим таску deploy. Таска отработала, мы видим ссылку, по которой можем перейти и увидеть свежеиспеченный дашборд. Такой подход мы используем уже несколько месяцев.
Чем это нам помогло
Во-первых, мы стали быстрее настраивать дашборды и алерты, а ещё наши дашборды стали иметь стандартный, узнаваемый, типовой вид, понятный всем разработчикам.
Во-вторых, мы теперь не забываем настроить алерты для новых микросервисов, потому что они генерятся автоматически.
В-третьих, мы переиспользуем типовые панели, типовую конфигурацию, поэтому нам не приходится каждый раз накликивать в Grafana или кодировать в виде DSL подробное описание каждой панели, если она является типовой.
Какие я сделал лично для себя выводы из этой истории?
Прежде всего, очень важно договариваться в команде, в компании и в продукте о самых разных вещах, начиная от стиля кодирования до требований к внешнему, внутреннему API и до метрик. Помимо того, что это увеличивает общее владение кодом, это ещё и открывает возможности для автоматизации. Потому что стандартные, типовые вещи автоматизировать просто, а если каждый компонент, каждая часть кода делают что-то по-своему, по-разному, то автоматизировать связанные с этим вещи будет намного сложнее.
Не стоит забывать и о том, что в микросервисной архитектуре очень важно переиспользовать код. Помимо стандартной мотивации не изобретать очередной велосипед, здесь есть еще очень важный аспект — переиспользование поведения. Когда у вас много компонентов, и все они в похожих ситуациях ведут себя одинаково, это и упрощает понимание системы, ее поддержку, и также открывает возможности для автоматизации, которая иначе бы была невозможна.
Ещё важная штука: автоматизация даже простых вещей, которые происходят регулярно, часто, из спринта в спринт, тоже приносит очень ощутимый результат по экономии времени и усилий.
