Что же такое GitOps? Его свойства и недостатки

Полтора года назад мы переводили пару статей о том, что такое GitOps. С тех пор этот термин (и сам подход) набрал ещё большую популярность в среде DevOps-инженеров, особенно эксплуатирующих Kubernetes. В то же время у меня появилось свое видение того, какие у него проблемы и каким он должен быть. Поделиться этими мыслями я решил в получасовом видео — смотрите его либо читайте основную выжимку, если предпочитаете текст:
Далее представлен текстовый пересказ видео.
Предисловие о терминологии
До публикации этого материала мы уже выпустили английскую версию видео и получили обратную связь, на основании которой я понял, что для полноты восприятия надо сделать важное уточнение.
В сообществе бытуют два понимания GitOps:
- Обобщенное — как паттерна, при котором Git является единым источником правды и в котором через действия в Git мы управляем действительностью. Из самого названия «GitOps» — любому, кто много работал с Git и IaC (Infrastructure as Code), — интуитивно понятен этот паттерн. Именно такое обобщенное понимание мы и используем в нашем проекте werf.
- Более конкретное понимание GitOps, в частности, определяющееся pull-моделью и обязательным промежуточным Git-репозиторием. Именно такую конкретную реализацию достаточно активно продвигают некоторые компании (включая авторов самого термина). Информацией именно об этой модели заполнен интернет.
В данном видео (и статье) под «GitOps» я подразумеваю именно второе, «конкретное›, понимание и пытаюсь разобрать, какие к нему есть вопросы.
Что такое GitOps
Какая картина возникает у вас в голове, когда вы слышите «GitOps»?
Все начинается с Git-репозитория. В нем есть YAML-файлы, описывающие желаемое состояние Kubernetes. Например:
- два Deployment’а,
- StatefulSet,
- Ingress.
Вместе они формируют некоторое простое приложение, которое располагается в кластере Kubernetes.
Единственная недостающая часть — это GitOps-оператор. Он отвечает за синхронизацию состояния из Git в Kubernetes. Для этого он периодически (или по событию, которое может быть запущено, например, через webhook):
- считывает состояние из Git,
- считывает состояние из Kubernetes,
- сравнивает их,
- меняет состояние Kubernetes (если это необходимо).
Вот и все. Проще не бывает: репозиторий Git с (обычно «предварительно скомпилированными») манифестами, кластер Kubernetes и штука, которая поддерживает синхронизацию между ними (GitOps-оператор).
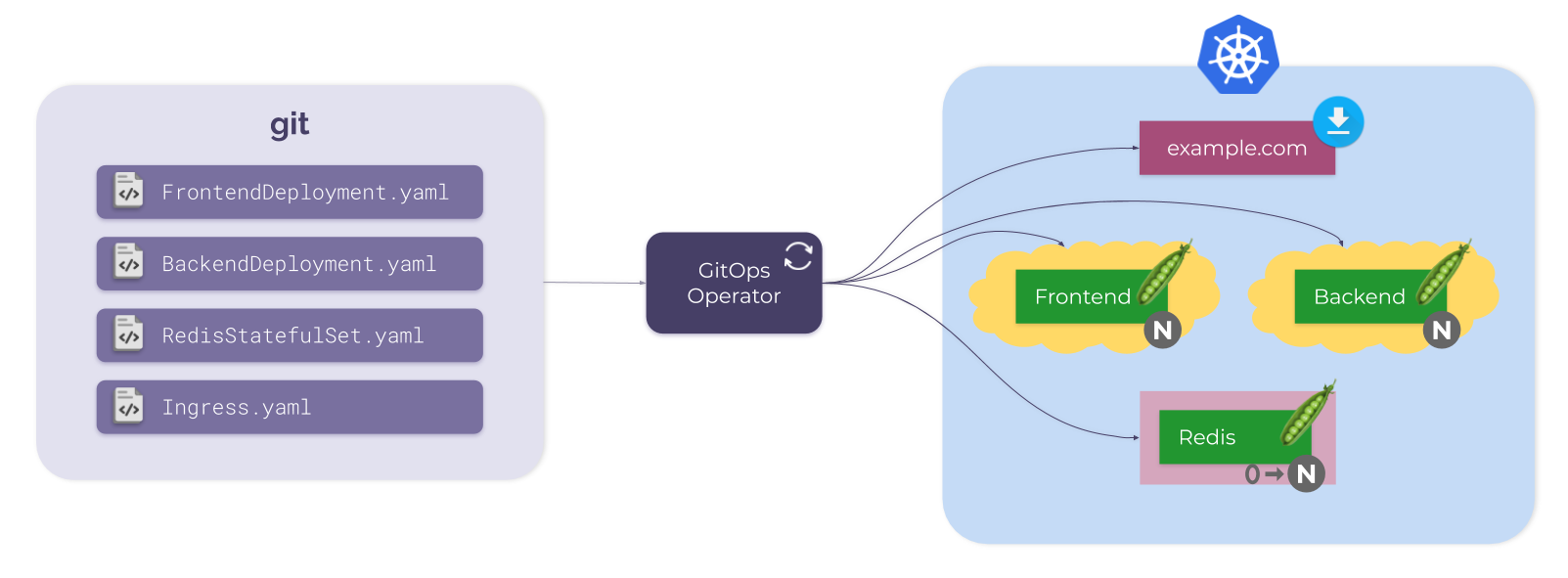
Обычная схема GitOps в действии
NB. Хотя GitOps-оператор и может работать снаружи, почти всегда он находится внутри кластера Kubernetes. Но для упрощения мы изображаем его снаружи.
Само использование этого подхода уже предостерегает нас от некоторых вещей. Если по какой бы то ни было причине некоторый пользователь напрямую изменит что-то в Kubernetes, GitOps-оператор обнаружит изменение и вернет K8s в состояние, определенное в Git. Это создает своего рода »забор», который мотивирует пользователей (вместо прямого внесения изменений в K8s) делать правки в единственном источнике правды, которым выступает Git.
Вместо небольшого забора можно построить и серьезную стену (полностью забрав у пользователя прямой доступ к K8s), и «прозрачную» стену (с доступом только для чтения). Но главное не в этом, а в том, что Git — единственная точка входа.
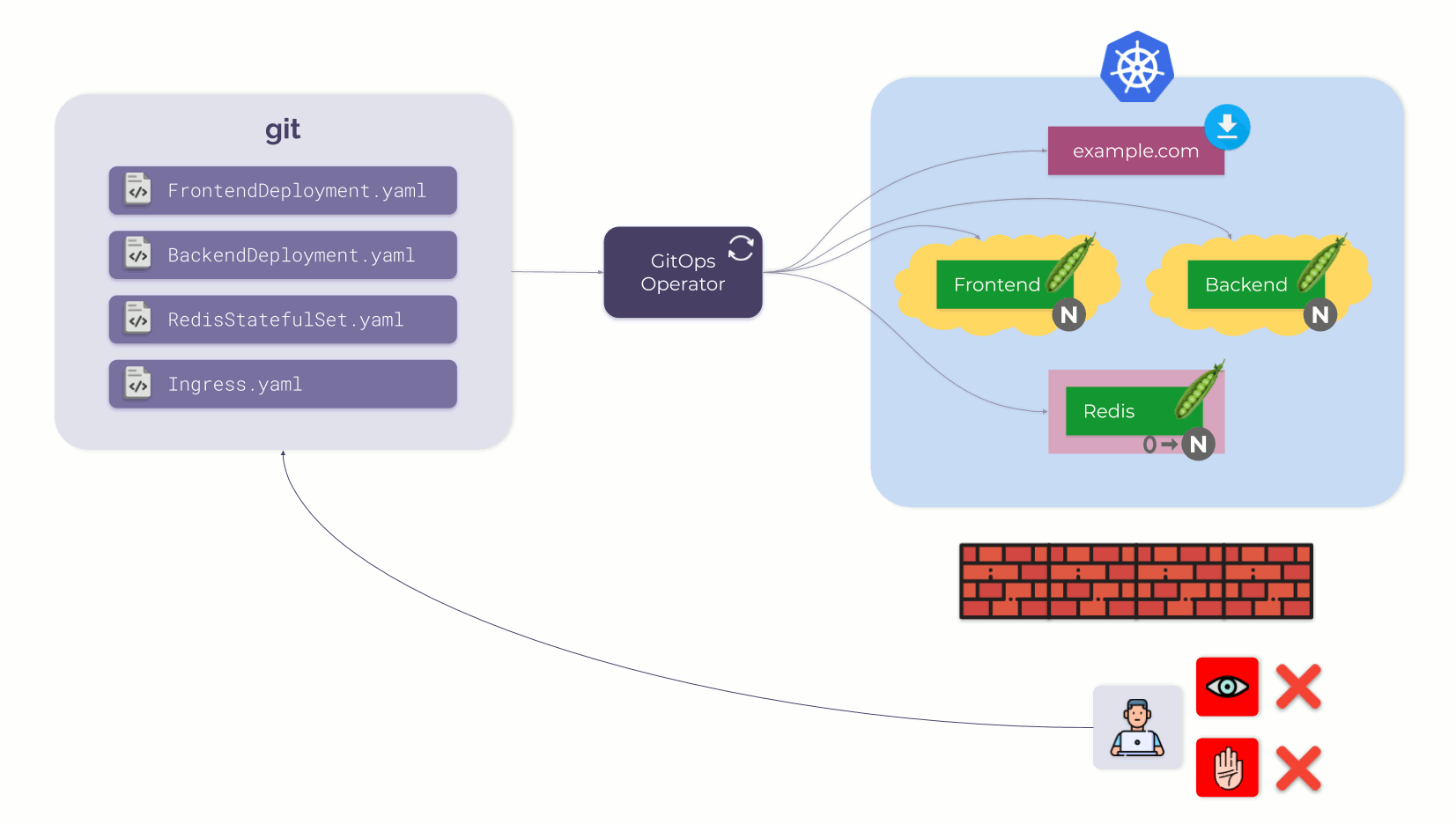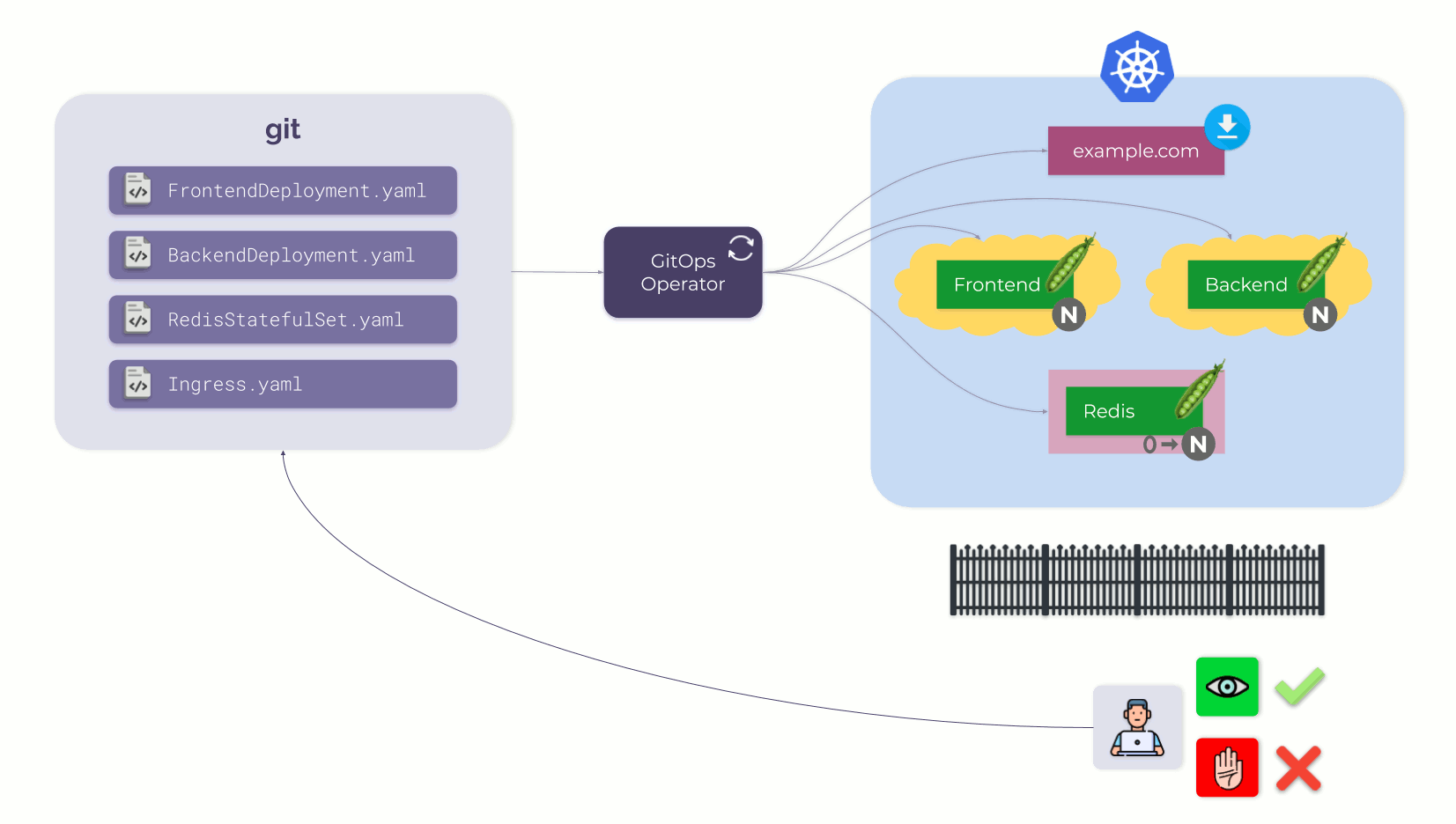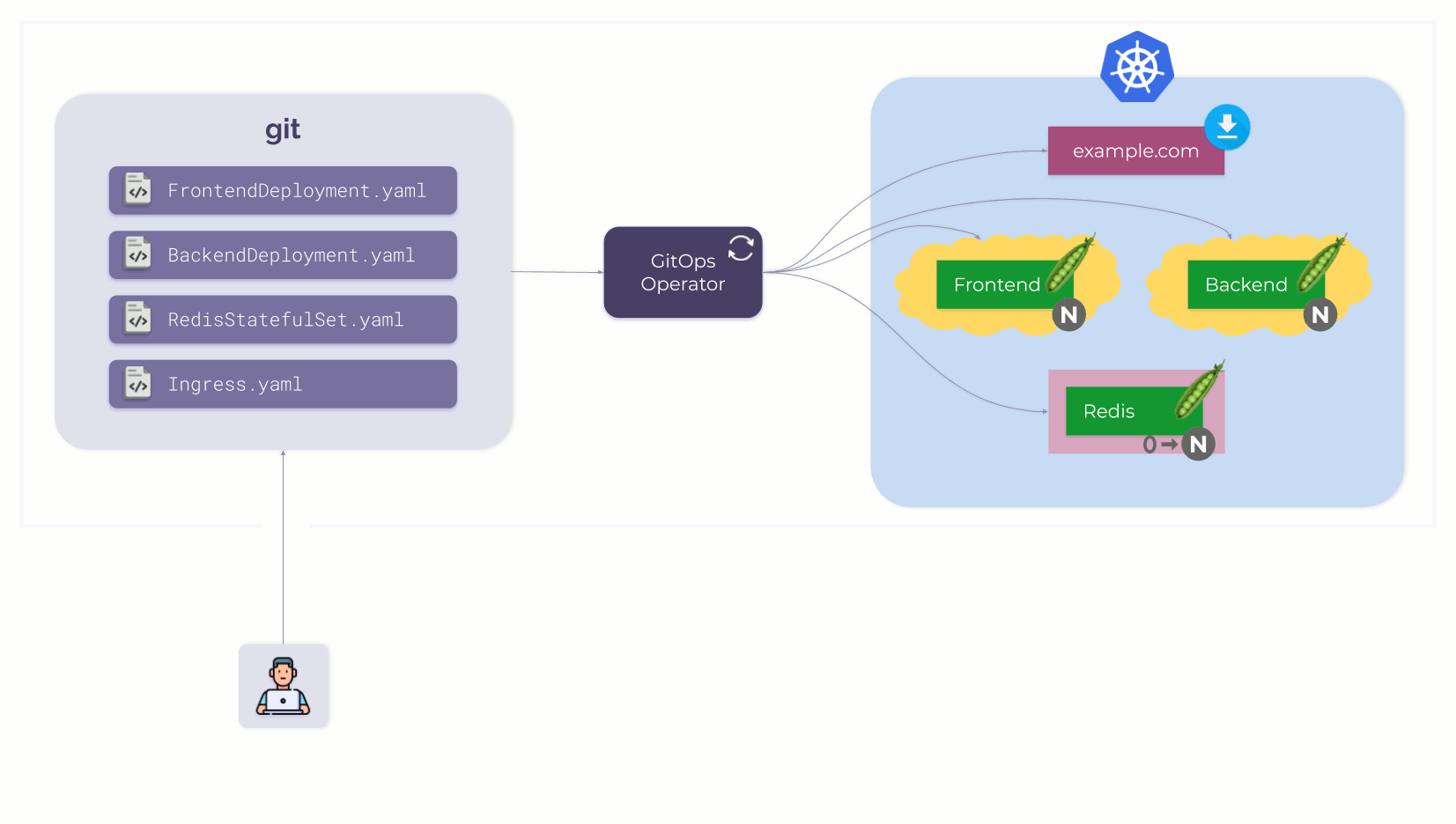
Стена, предотвращающая прямой доступ пользователей к Kubernetes
Всё ли здесь учтено?
В представленной схеме не хватает одной важной части — container registry. Если новый Docker-образ попадает в реестр, GitOps-оператор через некоторое время обнаружит изменение и распространит его в Kubernetes (новый образ будет доставлен в K8s).

Становится очевидно, что состояние Kubernetes на самом деле не полностью определено в Git. Состояние Kubernetes определяется Git’ом и container registry.
Преимущества и недостатки GitOps
Когда мы читаем о GitOps, нам обещают множество полезных свойств. Проанализируем их критическим взглядом:
- Автоматизация ✓ Мы не производим вручную ни какие-либо правки в Kubernetes, ни синхронизацию состояния из Git. Для последнего есть GitOps-оператор, который отвечает за синхронизацию, выполняя ее полностью автоматически.
- Конвергентность ✓ Система стремится прийти в желаемое состояние и, даже если время от времени происходит рассинхронизация, сама возвращается обратно в требуемое, синхронизированное состояние. Почему может произойти рассинхронизация? Две основные причины: а) что-то изменилось в Kubernetes (ручные или несанкционированные действия и подобное), б) изменения внесены в Git, но еще не доставлены в Kubernetes. В обоих случаях за восстановление синхронизации системы отвечает GitOps-оператор.
- Идемпотентность ✓ Если мы повторим синхронизацию несколько раз, результат первой синхронизации не повлияет на результат второй, они оба не повлияют на третью, и так далее. Впрочем, если у нас имеются уже скомпилированные манифесты, коммитнутые в Git, эта идемпотентность обеспечивается в основном самим Kubernetes и его API, так что в этом смысле заслуги GitOps тут нет.
- Детерминизм ✗ Состояние в Kubernetes целиком и полностью определяется тем, что написано в Git. Как я уже говорил, это неправда, потому что состояние зависит ещё от container registry. Если кто-то изменит состояние реестра, изменит образ в реестре… развалится практически всё. Подробности будут ниже.
- Наблюдаемость ✗ В любой момент времени мы хотим знать, синхронизирована ли наша система. Хотим иметь возможность получать алерт, если это не так. С одной стороны — да, наблюдаемость присутствует: ведь мы знаем, соответствует ли текущий Kubernetes манифесту в Git. Однако мы в то же время не знаем, находится ли наша система в желаемом состоянии. Ведь что такое желаемое состояние? Это комбинация из манифестов (в репозитории Git) и образов контейнеров (в реестре). Вывод: только половина состояния определяется Git, и только половину состояния можно наблюдать.
- Аудит ✗ Необходимо надежно и удобно просматривать все изменения, внесенные в Kubernetes, причем в одном месте. И это место — Git. Но это неправда, потому что мы также должны полагаться на функции аудита используемого container registry. Сопоставление данных аудита из двух систем совсем не назовешь надежным или удобным.
- Безопасность ✗ Речь про запрет прямого доступа CI-системы к кластеру Kubernetes. На первый взгляд, наличие оператора, который находится внутри кластера и pull’ит изменения (без прямого доступа к кластеру извне), кажется более безопасным. Однако CI-система (или пользователь) по-прежнему должны иметь возможность отправлять образы в container registry и обновлять манифесты в Git’е. А это означает, что CI-система (или пользователь) уже имеют весь возможный доступ к кластеру. Изменение доступа с прямого на опосредованный не улучшает безопасность, а создает неправильное ощущение безопасности, что делает всю среду только менее защищенной. Вы должны обеспечить безопасность своего CI, других способов тут нет.
С чем мы вообще сравниваем GitOps?
Как обычно осуществляется доставка в Kubernetes? Самый очевидный и наиболее часто используемый способ — это просто деплой из CI-системы. Этот подход иногда называют CIOps.
Как работает CIOps
Всё тоже начинается с Git-репозитория, но на этот раз — не просто репозитория с манифестами Kubernetes. Это репозиторий приложения, который содержит:
- исходный код;
- Dockerfile (s);
- Kubernetes-манифесты, но теперь они представлены Helm-чартом;
- и скорее всего здесь же располагаются некоторые тесты.
К этому репозиторию подключена CI-система. Это может быть что угодно: Jenkins, GitLab CI/CD, GitHub Actions и т.д. У этой CI-системы есть следующие задания (или jobs, tasks, actions, stages… как бы они ни назывались):
- Build — для сборки образа;
- Unit test — для запуска тестов на образе;
- Publish — для публикации образа (или скорее даже образов) в реестре;
- Deploy to stage…
На первый взгляд, это задание просто выполняет helm, которому передается чарт из Git. Но одного чарта недостаточно. Обычно вам также необходимо передать в Helm информацию о только что созданных образах: новые теги этих образов. На основе таких тегов Helm рендерит манифесты и отправляет их в Kubernetes API. А K8s в свою очередь уже приводит себя к заданному состоянию и вытягивает новые образы.
NB. Кстати, вы можете заменить Helm на любой другой инструмент: разницы не будет. В любом случае у вас есть какие-то шаблоны и теги Docker-образов. И теги будут использоваться для рендеринга (компиляции) этих шаблонов.
Вернемся к нашим заданиям, осталась еще парочка:
- E2e test — для запуска end-to-end-тестов на развернутом приложении;
- Deploy to production делает то же самое, что и Deploy to stage, но для production-окружения.
Вот как обычно выглядит деплой в Kubernetes из CI-системы.
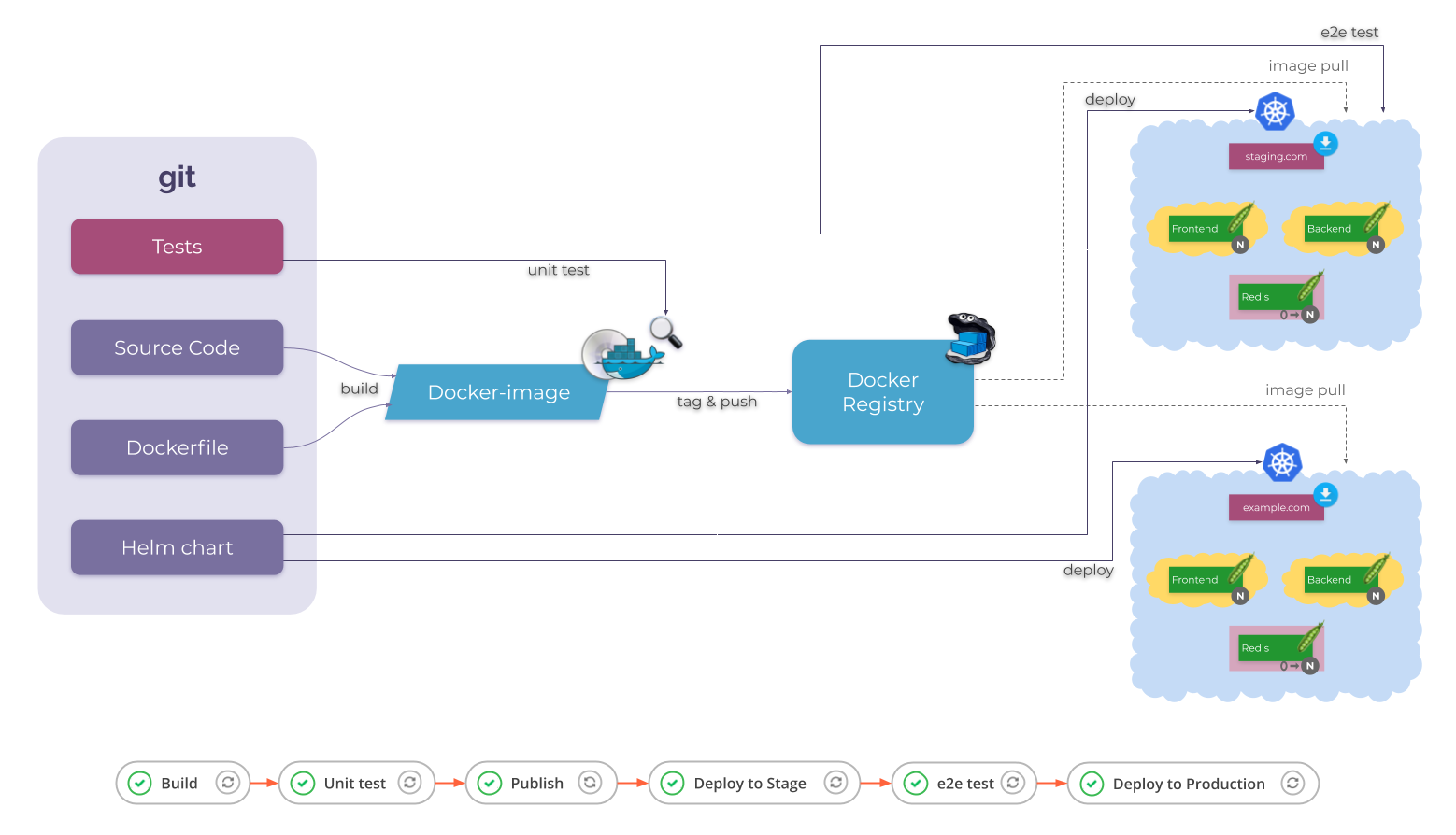
Обычная схема CIOps
Преимущества и недостатки CIOps
Давайте быстро оценим, как работает эта схема, по тем же критериям, что мы использовали для GitOps.
Прежде всего, что с детерминизмом? Бывает по-разному, но обычно всё плохо:
- Во многих реализациях этого подхода я видел проблему в области сборки Docker-образов. Даже имея исходный код и Dockerfile в одном репозитории, а также действительно стараясь «заморозить» все внешние зависимости в нём же, мы всё равно в конечном итоге не получаем гарантии воспроизводимости наших сборок. Если по какой-либо причине мы соберем образ дважды (из одного и того же коммита), можно получить не только небольшие бинарные различия (потому что это два разных образа), но и два действительно разных образа (образы с разными содержимым).
В Kubernetes нет проблем с детерминизмом процесса применения манифестов, однако сложность в том, чтобы сделать манифесты непротиворечивыми, повторимыми, воспроизводимыми — одними и теми же каждый раз. Поскольку повторимость отрендеренных результатов во многом зависит от повторимости этапов сборки (и публикации), от детерминированности этапов сборки и публикации, конечный результат не получается консистивным и воспроизводимым, поэтому весь workflow получается недетерминированным.
- Другая проблема заключается в стратегии тегирования. Найти способ воспроизводимого тегирования далеко не так просто. Наиболее естественной реализацией видится использование ID коммитов из Git’а. Можно сделать проверку наличия образа (в реестре) и, если образ с таким коммитом уже есть, пропустить сборку и публикацию, а если образа нет — собирать образ и публиковать его. При таком подходе, если вы вызовете сборку несколько раз, второй и последующие вызовы ничего не поменяют.
Однако я никогда не видел, чтобы в реальной жизни это делали правильно. Либо тег используется повторно, поэтому при повторном выполнении существующий образ заменяется в реестре (что обычно дает непредсказуемые результаты), либо стратегия тегирования основана на некоторых данных из CI-системы (идентификаторы заданий или что-то подобное).
Это означает, что нет и идемпотентности. Кстати, если некоторые шаги полагаются на данные из CI-системы, то состояние Kubernetes будет определять не только Git и container registry, но еще и CI-система…
NB. Повторюсь, что в процессе применения манифеста нет проблем с идемпотентностью: проблема заключается в воспроизводимости — в консистентности данных, которые мы передаем в Helm (которые передаются процессу рендеринга).
Таким образом, несмотря на то, что Helm-чарт находится в Git, несмотря на то, что Helm сам по себе идемпотентен (вы можете заменить Helm на kubectl или другой аналогичный инструмент), несмотря на то, что Dockerfile и исходный код также находятся в том же Git, весь workflow не является детерминированным и идемпотентным. Нет гарантии восстановления кластера до состояния конкретного коммита в Git.
Как вы уже знаете, идемпотентность и детерминизм составляют основу всего процесса. А когда их нет, все остальное разваливается:
- Больше нет конвергентности и наблюдаемости, потому что нет согласованного и повторяемого способа получить желаемое, целевое состояние (а как его тогда наблюдать?).
- Git не полностью определяет состояние, поэтому нет и аудита. История Git может что-то сказать, но это далеко не окончательный или единственный источник истины.
- Нужно ли говорить о безопасности? Замена прямого доступа на опосредованный ничего не меняет.
Зато всё хорошо с автоматизацией. Ведь CI-системы — они про автоматизацию. Так что здесь вопросов нет: да, мы доставляем наши изменения автоматически. Просто эти изменения нам неизвестны…
NB. Говоря об автоматизации, важно упомянуть еще одну вещь: обратную связь. Чтобы автоматизация работала правильно, необходимо предоставить пользователю четкую обратную связь. Когда мы разворачиваем приложения в Kubernetes, довольно часто попадаем в ситуацию, когда Helm (или kubectl apply) сообщает: «Успешно применено». Однако это вовсе не означает, что наши изменения развернуты. Это лишь говорит о том, что запрос на развертывание приложений был успешно получен. Если вы попадали в подобную ситуацию, вам могут пригодиться werf или kubedog.
Подводя итог по CIOps: если все сделать правильно, такая схема может работать. Необходимо уделить достаточно внимания этапу сборки и тегированию, сделав их идемпотентными и детерминированными. Тогда в большинстве случаев вы мгновенно получаете все остальное ✓ (более или менее). Особенно, если вы не забываете об обеспечении понятной обратной связи.
Вот с чем мы должны сравнивать GitOps.
Но сделаю еще один шаг. Будьте честны с собой: как часто вам нужно повторно разворачивать приложение? Или развернуть его в каком-нибудь историческом состоянии? Если наступят плохие времена (авария в кластере или неизвестное изменение в кластере), мы будем глубоко опечалены… Но если накатываем только новые изменения и если делаем это только последовательно, то ведь вполне себе можно жить с недетерминированным и неидемпотентным подходом.
Я не пытаюсь убедить вас в правильности такого подхода — как раз наоборот: я категорически за детерминизм и за идемпотентность. Однако пытаюсь сказать, что в реальных ситуациях все может быть нормально даже с недетерминированным и неидемпотентным рабочим процессом. Поэтому, возможно, вы не захотите вкладывать много дополнительных усилий для достижения этой «полной безопасности». Здесь вопрос скорее в том, сколько вы готовы «заплатить»?
GitOps или CIOps
Итак, «на бумаге» GitOps почти идеален, а CIOps очень плох. Однако совершенство GitOps (само по себе) вызывает сомнения. А CIOps, если все сделано правильно, может сработать или даже вполне хорошо работать. Но это всё ещё не полная картина.
Дело в том, что CiOps описывает весь процесс: от изменений, внесенных в Git приложения, до их развертывания в production-кластере Kubernetes, а GitOps охватывает только некоторую часть этого процесса. Давайте же посмотрим на всю картину.
GitOps на более полной схеме
Вернемся к схеме с GitOps. На самом деле, в Git-репозитории есть нескольких веток и, вероятно, есть несколько кластеров, например, для staging и production.

GitOps с разными ветками и кластерами
Но по-настоящему важно то, что основной Git-репозиторий, содержащий весь исходный код нашего приложения и все сопутствующие вещи, отсутствовал. Это тот самый репозиторий, который мы видели в CIOps. В дальнейшем будем называть их как репозиторий приложения (Application repo) и кластерный репозиторий (Cluster repo).
Затем весь процесс практически полностью повторяет CIOps. Задания в CI-системе:
- Build,
- Unit test,
- Publish,
- Deploy: начинаем с тех же шагов, забирая информацию об образах из задания Publish и передавая ее в Helm, но затем вместо того, чтобы вносить изменения напрямую в Kubernetes, мы делаем коммит в кластерный репозиторий.
В то же время работает GitOps-оператор. И он либо замечает новые образы в container registry, либо новые манифесты в кластерном Git-репозитории. И выполняет свою работу: приводит Kubernetes к целевому состоянию.
Еще несколько вещей, на которые стоит обратить внимание:
- У нас нет обратной связи в CI-системе: задание Deploy говорит, что все хорошо, потому что успешно коммитнуло новые манифесты в кластерный репозиторий. Однако это не означает, что изменения были успешно применены в кластере. Поэтому нужно заглянуть в какую-то другую систему… И мы вынуждены делать это даже для того, чтобы проверить совсем простые вещи — например, чтобы убедиться, валидны ли новые манифесты.
- Система стала асинхронной. Например, GitOps-оператор может заметить новый образ в container registry до того, как новые манифесты будут коммитнуты (и увидены им). Таким образом, GitOps-оператор может применить старые манифесты с новыми образами, а вдруг они не подойдут друг другу?
Наконец, происходит деплой в production. В GitOps, чтобы сделать выкат в production, нужно выполнить merge из ветки staging в ветку production. (Возможно, вам также потребуется сделать promote образам из stage в production в реестре, хотя этого можно избежать, используя правильные стратегии тегирования.)

Вот полная картина, на которой можно увидеть, что в реальной жизни GitOps не такой аккуратный, как это обычно показывают.
Даже если GitOps-часть делает все то, что о ней написано (а это не совсем так), общий workflow наследует все проблемы от CIOps и добавляет дополнительный уровень сложности.

При оценке GitOps важно учитывать весь CI-пайплайн
GitOps — это антипаттерн?
Я считаю, что GitOps, реализованный описанным или подобным способом, на самом деле является антипаттерном. Вся культура DevOps говорит о плавности и непрерывности потока — потока изменений от идеи/Git’а к production — и о совместной работе. Однако такая реализация GitOps обманывает нас, обещая прозрачность и удобство, а на самом деле — препятствует потоку ненужным промежуточным репозиторием, ненужной стеной между разработкой и эксплуатацией.
Но это мое мнение. Что неопровержимо, так это то, что нельзя сравнивать GitOps и CIOps. Правильным будет сравнение всего процесса, построенного вокруг GitOps, с CIOps. То есть GitOps плюс «конвейеры» против CIOps.
И что мы получим в таком случае?
- CIOps может быть неидемпотентным и недетерминированным и, будучи таковым, может вредить.
- Используя GitOps, мы получаем идемпотентность и детерминизм. Но…
- Детерминизм в GitOps — посредственный, потому что половина правды лежит не в Git, а в container registry.
- Другие минусы — отустствие обратной связи там, где нам это нужно (в CI-системе, где разработчики всё делают), и повышенная сложность из-за новых элементов и введенной асинхронности.
Надеюсь, теперь, имея все факты, вы сможете выбрать рабочий процесс, который действительно подходит для вашего случая.
Готов поспорить, что «стандартная» реализация GitOps будет заменена чем-то, что даст вам идемпотентность и детерминизм, но более практичным и удобным способом. Способом, совместимым с существующими подходами CI. Способом, не создающим стену. Будет ли этот подход называться GitOps 2.0?…
Эпилог про werf
Последние несколько лет мы в компании «Флант» работали над Open Source-инструментом werf. Как мне кажется, у нас получилось решить главный вызов всей этой истории (как я его вижу): мы смогли превратить основной Git-репозиторий (репозиторий приложения) в единственный источник истины. Для этого werf реализован таким образом, чтобы гарантировать идемпотентность и детерминизм этапов сборки, тегирования и деплоя. А все остальное построено на этом.

Интересно? Попробуйте! А для разработчиков, только начинающих знакомиться с утилитой, мы подготовили онлайн-самоучитель.
P.S.
Читайте также в нашем блоге:
