Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов… Вы делаете заказ, а система сохраняет ваши данные в базе.

В этой статье я на простых примерах расскажу, что такое база данных, как она выглядит, и чем она лучше хранения информации в простых текстовых файликах.
Содержание
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.

Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!

Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги…

Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
Тоже самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
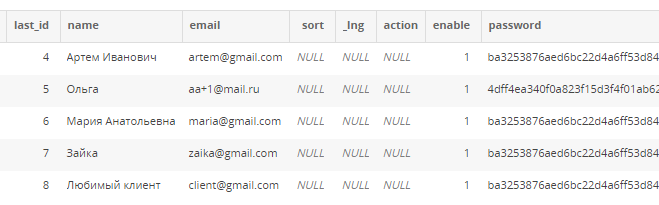
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
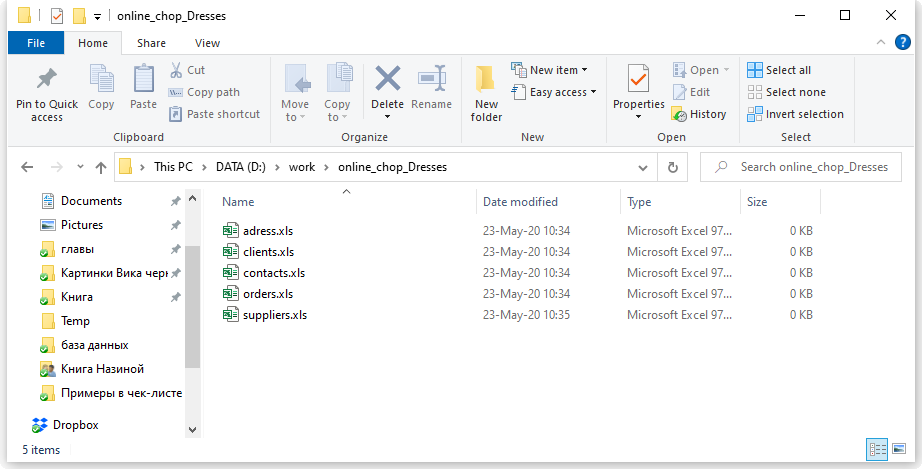
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
 Пример базы Oracle
Пример базы Oracle Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
заходишь в папку в винде → видишь файлики только из этой папки
заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
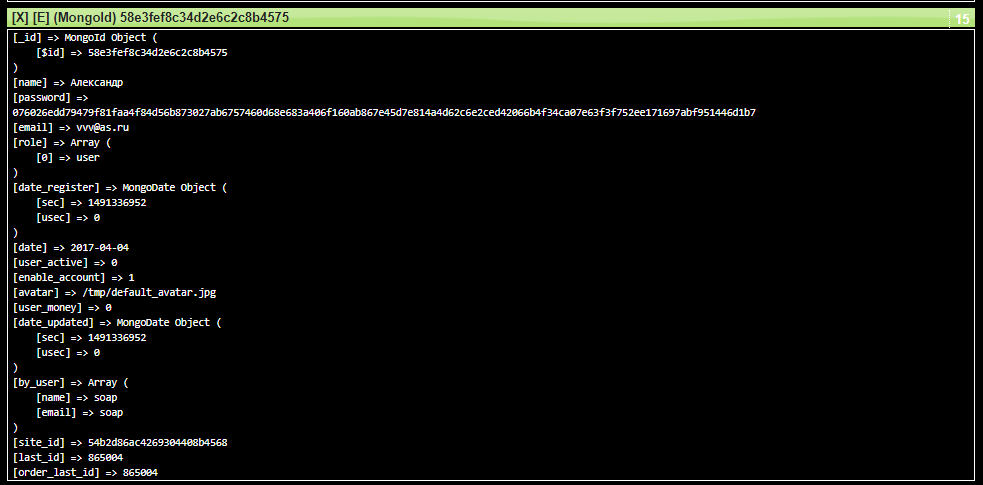
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки…
from — из такой-то таблицы базы…
where — такую-то информацию…
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»Переделываю в SQL:
select * from clients where name = 'Назина Ольга';
В дословном переводе:
select -- выбери мне
* -- все колонки (можно выбирать конкретные, а можно сразу все)
from clients -- из таблицы clients
where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. Тоже самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1–2–3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order | order (таблица order) | fio (таблица client) | phone (таблица contacts) |
1 | Пицца «Маргарита» | Иванова Мария | +7 (926) 555–33–44 |
2 | Комбо набор 1 | Петров Павел | +7 (926) 555–22–33 |
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name | first_name | birthdate | VIP |
Иванов | Иван | 01.02.1977 | true |
Петрова | Мария | 02.04.1989 | false |
Сидоров | Павел | 03.02.1991 | false |
Иванов | Вася | 04.04.1987 | false |
Ромашкина | Алина | 16.11.2000 | true |
В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order | addr | date | time |
Пицца «Маргарита» | ул Ленина, д5 | 05.05.2020 | 06:00 |
Роллы «Филадельфия» и «Канада» | Студеный пр-д, д 10 | 15.08.2020 | 10:15 |
Пицца 35 см, роллы комбо 1 | Заревый, д10 | 08.09.2020 | 07:13 |
Пицца с сосиками по краям | Турчанинов, 6 | 08.09.2020 | 08:00 |
Комбо набор 3, обед №4 | Яблочная ул, 20 | 08.09.2020 | 08:30 |
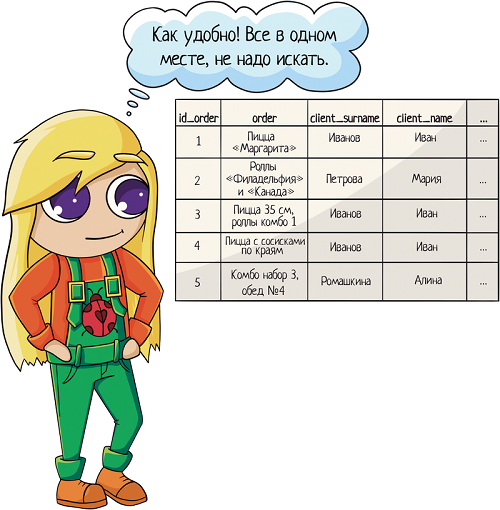
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам… В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Но есть минусы:
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Клиенты отдельно
Заказы отдельно
Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
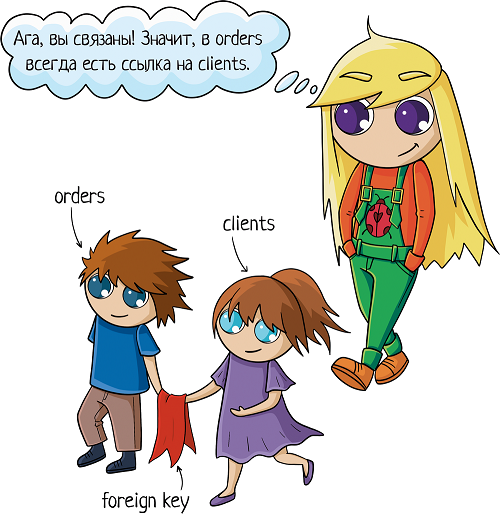
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы. Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку… А если у нас два клиента Ивана? Или три Маши? Десять Саш… Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.

А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
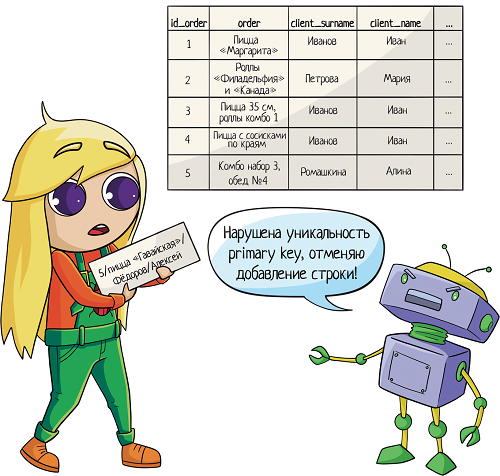 Здесь ключ — «id_order»
Здесь ключ — «id_order»Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
Тут привозят еще одного Барсика. Добавляем его в таблицу:
— Имя Барсик, 5 лет! (мы не указываем ID)
Система добавляет:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
3 | Барсик | 5 |

ID сгенерился автоматически. Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!
Теперь, если в другой таблице надо будет сослаться на котика, мы будем делать это именно через уникальный идентификатор. Например, у нас есть таблица комнат для постояльцев, куда мы заносим информацию о том, кто там живет:
id_room | square | id_cat (ссылка на id в таблице котиков) |
1 | 5 | 11 |
2 | 10 | 2 |
3 | 10 |
Мы видим, что в первой комнате живет котик с id = 1, а во второй — с id = 2. В третьей комнате пока никто не живет. Так, благодаря связке таблиц, мы всегда можем понять, что именно за котофей там проживает.
Итак, теперь мы знаем, что идентификатор лучше делать первичным ключом, дабы обеспечить его уникальность. Можно сделать поле автоикрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:

И в таблице заказов!»id_order» пусть генерится сам и всегда будет уникален. А еще в таблицу заказов мы добавим колонку «id_client» и повесим на нее foreign key, ссылку на «id_client» в таблице клиентов.
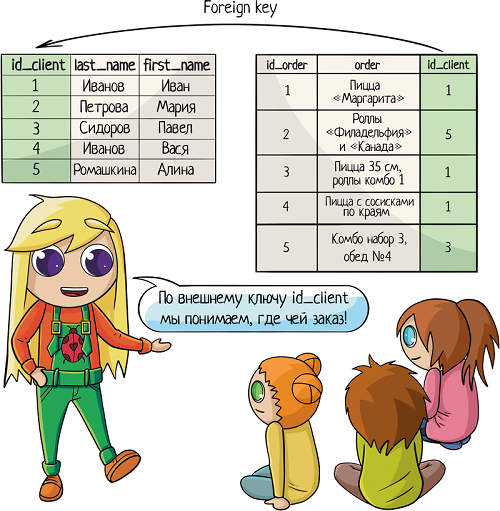
Ключей может быть несколько. Одна таблица может ссылаться на несколько других. Скажем, в заказе мы ссылаемся на клиента и поставщика.
И наоборот, несколько таблиц могут ссылаться на одну и ту же колонку текущей таблицы. ID клиента мы можем указывать в таблице адресов, телефонов, email адресов, документов, заказов… Ограничений на это нет.
Как ускорить запрос
Давайте представим, что у нас есть табличка excel. Если она небольшая (пара строк, пара колонок), то найти нужную ячейку не составит труда:
Открыли файлик — открывается моментально (если нет проблем с жестким диском)
Нажали «Ctrl + F», ввели запрос — тут же нашли результат.

Но что, если у нас сотни колонок и миллионы строк в файлике? Тогда начинаются тормоза. Файл открывается долго, в поиск значение ввели и система подвисла, обрабатывая результат…
Всё то же самое и в базе данных. Если табличка маленькая, любой запрос к ней отработает моментально. Если же таблица будет большая и с кучей данных, то результата запроса можно ждать минут по 15. А иногда и пару часов!

Что делать, чтобы запросы были быстрее? Тут есть несколько путей:
На этапе создания таблицы — добавить индексы
На этапе написания запроса к большой таблице — использовать хинты
Пересобрать статистику базы
Есть и другие, но мы остановимся на этих трех.
Индексы в таблице
Если вы заранее знаете, что данных в базе будет много, нужно продумать основные сценарии поиска. И на колонки, по которым будете искать, нужно повесить индексы.
Индекс — это как алфавитный указатель в библиотеке. Вот представьте, заходите вы в библиотеку и хотите найти «Преступление и наказание» Достоевского. А все книги стоят «от балды», никакого порядка. Чтобы найти нужную, надо обойти все стелажи и просмотреть все полки!

Совсем другое дело, если книги отсортированы по авторам. А внутри автора — по названию. Тогда найти нужную книгу будет легко!

Индекс играет ту же роль для базы данных. Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
Хинты
Хинт — это код, вставляемый в SQL-запрос, который позволяет изменить план выполнения запроса. Выглядит это примерно так:
SELECT /*+ NO_UNNEST( @SEL$4 ) */
*
FROM v;Хинт идет внутри блока /* */.
А что еще за план выполнения запроса? Смотрите, когда вы выполняете любой запрос, что делает система:
Строит план выполнения запроса (как ей кажется, оптимальный)
Выполняет его
Посмотреть план можно через ключевые слова EXPLAIN PLAN (в Oracle):
EXPLAIN PLAN FOR -- построй мне план для...
SELECT last_name FROM employees; -- вот такого запроса!А если вы работаете через sql developer (графический интерфейс для обращения к базе Oracle), то можно просто выделить запрос и нажать F10:
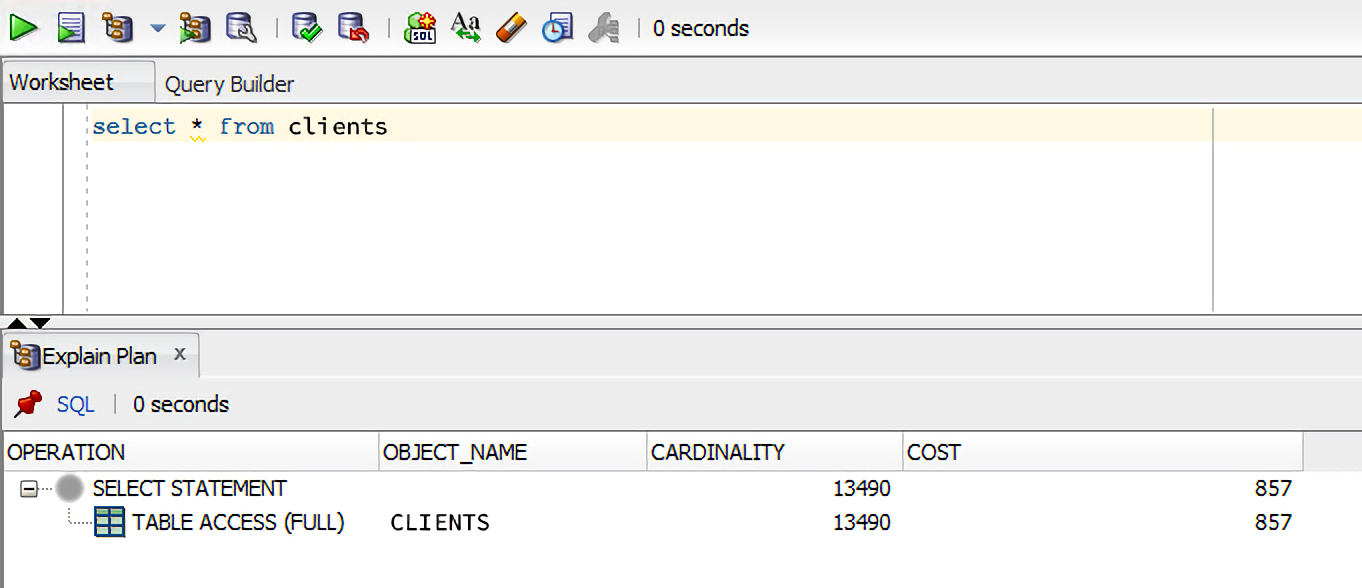
Что мы видим на этой картинке? Запрос говорит: «достань мне всю информацию из таблицы клиентов». Так как нет никаких условий where, то мы просто проходим фулл-сканом »Table Access (full)» по этом таблице. План показывает стоимость (cost) этого запроса — 857 ms.
А теперь изменим запрос, сделав выборку по одному конкретному человеку по колонке с индексом:

Оп, цена запроса уже 5 ms. Это, на минуточку, в 170 раз быстрее!
И это простейший запрос на тестовой базе. В реальной базе данных будет сильно больше, поэтому проход таблицы по индексированной колонке существенно сократит время выполнения запроса.
Вот пример плана чуть более сложного запроса, когда мы делаем выборку из двух таблиц:

Вы не обязаны понимать, «что тут вообще происходит», но вам нужно уметь получать этот план. Пригодится.
Допустим, поступает жалоба от заказчика — клиент открывает карточку в вебе, а она открывается минуту. Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Тормозит на уровне БД — тут или сам запрос долго отрабатывает, или статистику давно не пересобирали, или диски подыхают.
Тормозит на уровне приложения — тогда надо копаться внутри кода функции «открыть карточку», что она там делает, получив ответ от Базы (и снова есть вариант «подыхают диски, на которых установлено ПО»).
Тормозит на уровне сети — сервер приложения и сервер БД обычно размещают на разных машинах. Значит, есть общение между ними по интернету. А интернет может тупить.
Если есть подозрение, что тормозит сам select, разработчик попросит прислать план его выполнения на реальной базе. Конечно, если «с той стороны» грамотные админы, они это сделают сами. Но иногда это нужно уметь вам. Например, если вас отправили в банк разбираться на месте, что пошло не так. Вы проверяете разные гипотезы и собираете информацию для разработчика.

Собираете план, сохраняете в файлик и прикладываете в задачу в джире. Или отправляете по почте.
У меня бывало, что именно так находился баг — на тестовой базе запрос идет по правильному пути, а на боевой — нет. И на боевой идет не по индексам, что сильно его тормозит. Тут уже дальше разработчик думает, почему так получилось и как именно это исправить. Добавить индекс, хинт, или как-то иначе.
См также
17 Optimizer Hints в Oracle — хинты в базе Oracle
Статистика
Именно статистика позволяет базе данных выбрать оптимальный план выполнения запроса. Почему вообще возникают проблемы вида «на тестовой базе один план, на боевой другой»?
Да потому, что один и тот же запрос можно выполнить несколькими способами. Например, у нас есть таблица клиентов и таблица телефонов, и мы пишем такой запрос:
Найди мне всех клиентов, созданных в этом году,
У которых оператор связи в телефоне — Мегафон
Как можно выполнить запрос? Можно сначала обойти таблицу клиентов и поискать тех, кто создан в этом году. А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
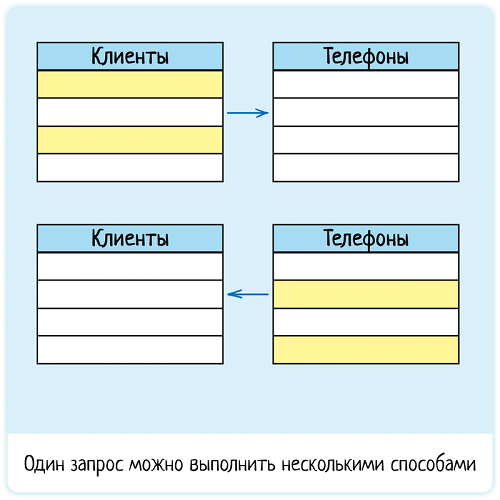
Какой вариант будет лучше? Никто не скажет без данных по таблицам. Может, у нас мало клиентов, но кучи телефонов (база перекупщиков), тогда быстрее будет начать с клиентов. А может, у нас куча миллионы клиентов, но всего пара сотен телефонов, тогда мы начнем с них.
Так вот, в статистике по БД хранится в том числе информация о распределении данных и характеристики хранения таблиц и индексов. И когда вы запускаете запрос, база (а точнее, оптимизатор внутри нее) строит возможные планы выполнения. Для каждого плана рассчитывает примерное время выполнения, а потом выбирает лучшее.
Время же он рассчитывает, ориентируясь на статистику:
Сколько данных находится в таблице?
Есть ли индекс по колонке, по которой я буду искать?

Именно поэтому просто пересбор статистики иногда убирает проблему «у нас тут тормозит». Прилетело в таблицу много данных, а статистика об этом не знает, и чешет по таблице через фуллскан, считая, что информации там мало.
См также:
Ручной и автоматический сбор статистики оптимизатора в базе данных Oracle
Преимущества базы данных
Почему используют базу, а не сохраняют данные в файликах? Потому что:
Базы поддерживают требования ACID (по крайней мере транзакционные БД)
Это единый синтаксис SQL, который используется повсеместно
Требования ACID
ACID — это аббревиатура из требований, которые обеспечивают сохранность ваших данных:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надёжность
Если база данных не поддерживает их, то могут быть печальные последствия из серии «Деньги с одного счета ушли, на другой не пришли? Ну сорян, бывает».
См также:
Требования ACID на простом языке — подробнее об этих требованиях
Единый синтаксис SQL
Я спросила знакомого разработчика:
— Ну и что, что единый синтаксис? В чем его плюшка то?
Ответ прекрасен, так что делюсь с вами:
— Почему в школе все преподают на русском? Почему не каждый свой язык? Одна школа — один, другая — другой. А ещё лучше не школа, а для каждого человека. Почему вавилонскую башню недостроили?

Как разработчик пишет код? Написал, проверил на коленке. Если не работает — думает, почему. Если непонятно, идет гуглить похожие ошибки. А что проще нагуглить? Ошибку распространенной БД, или сделанный на коленке костыль для работы с файлами? Вот то-то и оно…
Что знать для собеседования
Для начала я хочу уточнить, что я сама тестировщик. И мои статьи в первую очередь для тестировщиков))
Так вот, тестировщика на собеседовании не будут спрашивать про базы данных. Разработчика ещё могут спросить, а вас то зачем? Вполне достаточно понимания, что это вообще такое. И про ключи могут спросить — что такое primary или foreign key, зачем они вообще нужны.
Зато тестировщика спрашивают про SQL. Вот вам обсуждение из чатика выпускников, пригодится для повторения материала:
— В вакансии написано: уметь составлять простые SQL запросы. А простые это какие в народном понимании?
— (inner, outer) join, select, insert, update, create, последнее время популярны индексы, group by, having, distinct.
SQL выходит за рамки данной статьи, здесь я лишь пояснила, что это вообще такое. А дальше читайте статьи / книги из следующего раздела, или гуглите каждое слово из цитаты выше.
Статьи и книги по теме
База данных
Википедия
Какие бывают базы данных
Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных.
SQL
Книги:
Изучаем SQL. Линн Бейли — Обожаю эту линейку книг, серию Head First O`Reilly. И всем рекомендую)) Просто и доступно даже о сложном пишут.
Статьи:
Как изучить основы SQL за 2 дня
Полезные запросы
Тренажеры:
http://www.sql-ex.ru/ — Бесплатный тренажер для практики
Ресурсы и инструменты для практики с базами данных | SQL
Задачка по SQL. Найти объединенные данные
Резюме
База данных — это место для хранения данных. Они бывают самых разных видов, даже файловые! Но самые распространенные — реляционные базы данных, где данные хранятся в виде таблиц.
Если посмотреть на информацию о таблице в БД, мы можем увидеть ее ключи и индексы. Что это такое:
1. PK — primary key, первичный ключ. Гарантирует уникальность данных, часто используется для колонки с ID. Если ключ наложен на одну колонку — каждое значение в ячейках этой колонки уникальное. Если на несколько — комбинации строк по колонкам уникальны.
2. FK — foreign key, внешний ключ. Нужен для связки двух таблиц в разных соотношениях (1:1, 1: N, N: N). Этот ключ указываем в «дочерней» таблице, то есть в той, которая ссылается на родительскую (в таблице с данными по лицевому счету отсылка на client_id из таблицы клиентов).
3. Индекс. Нужен для ускорения выборки из таблицы.
Транзакционные базы данных выполняют требования ACID:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надежность
См также:
Что такое транзакция
И за это их выбирают разработчики. Мы получаем не просто хранилище данных. Наши данные защищены от неприятностей типа отключения электричества на середине бизнес-операции (с одного счета деньги списать, на другой записать). А еще по ним можно быстро искать, ведь разработчики баз данных оптимизируют свои приложения для этого.
Поэтому логика приложения — отдельно, база — отдельно. Так и получается клиент-серверная архитектура =)
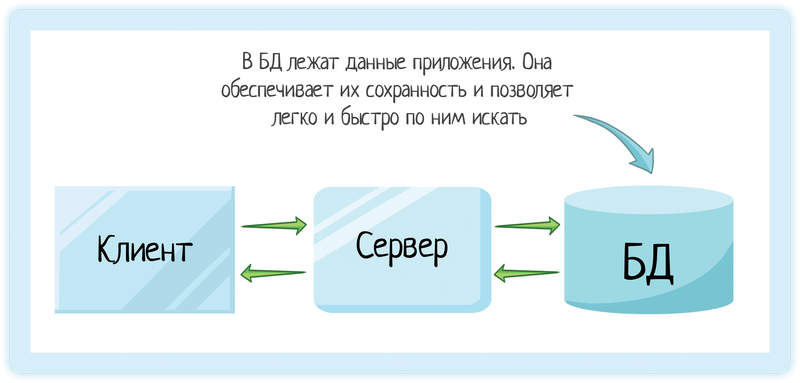
См также:
Клиент-серверная архитектура в картинках
Чтобы достать данные из базы, надо написать запрос к ней на языке SQL (Structured Query Language). Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Поиска по базе — правильно ли данные сохранились? В нужные таблицы легли? Это select-запросы.
Подготовки тестовых данных —, а что, если это значение будет пустое? А что, если у меня будет 2 лицевых счета на одной карточке? Можно готовить данные через графический интерфейс, но намного быстрее отправить несколько запросов в базу. Когда есть к ней доступ и вы знаете SQL =)
План-минимум для изучения: select, join, insert, update, create, delete, group by, having, distinct.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
