Что скрывает Array#sort: реверс-инжиниринг подручными средствами
Как вам, возможно, известно, спецификация языка JavaScript не предписывает какой-то определённой реализации метода sort у массивов. Алгоритм, находящийся «под капотом», может отличаться (и отличается) в различных браузерах. Теоретически, можно представить себе ситуацию, когда от того, как именно реализована сортировка массивов в конкретном движке, зависит производительность вашего веб-приложения.
Очень сильно сомневаюсь, что так может случиться на практике, но как человек, написавший в своё время определённое количество курсовых и дипломных работ, я просто не смог обойтись без секции «применение в народном хозяйстве».
Если речь идёт о браузере с открытым исходным кодом, то можно просто открыть этот код и посмотреть, какой там использован алгоритм. Однако существуют браузеры с закрытым исходным кодом (не будем показывать пальцем). Что делать в таком случае?
Поскольку мы на Хабре, я готов предположить, что некоторые читатели уже потянулись к своим любимым дизассемблерам, в то время как некоторые другие готовятся звонить своим друзьям из одной небольшой и нетвёрдой компании. Однако сегодня мы не будем копаться в машинном коде или использовать инсайдерскую информацию. Мы будем смотреть весёлые картинки.
Существует возможность узнать кое-что о реализации метода sort прямо внутри скрипта. Она состоит в том, что этот метод принимает в качестве аргумента компаратор — функцию двух переменных, возвращающую числовое значение, на основании которого алгоритм сортировки делает вывод, какой из аргументов больше. Это позволяет сортировать массивы произвольных объектов, а не только чисел или строк. Также, что важно в нашем случае, это позволяет узнать, какие именно элементы массива и в каком порядке метод sort сравнивает между собой. Например, так:
function compare(a, b){
console.log(a, b);
return a - b;
}
Однако мало получить данные, нужно ещё придумать, как их интерпретировать. Когда я в последний раз заходил в книжный магазин, там не было книги под названием «Классификация алгоритмов сортировки на основании того, какие элементы они сравнивают между собой, для чайников». Возможно, с тех пор она там и появилась, но я решил обойтись без неё и положиться на способность человека распознавать визуальные паттерны.
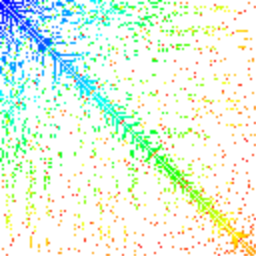
Будем делать так: возьмём некий массив, затем отсортируем его с помощью специально обученного компаратора, который сохраняет данные о каждом сравнении. Затем возьмём эти данные и построим на их основании следующую диаграмму: для каждого сравнения, в котором участвовали элементы с индексами a и b (имеются в виду индексы этих элементов в уже отсортированном массиве), мы отметим точку с координатами (a, b). Заодно отметим точку с координатами (b, a), чтобы было красиво и чтобы вид диаграммы не зависел от мелких деталей реализации. Причём точка будет не простая, а цветная: её цвет будет символизировать то, когда произошло это сравнение. Сравнения, случившиеся в самом начале сортировки, отметим красным, те, что ближе к концу — синим, а между ними будут прочие цвета радуги.
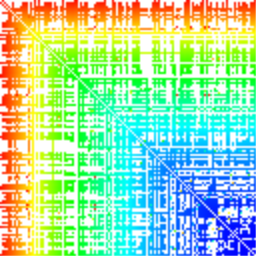
Как ни странно, этот план оказался не таким уж дурацким. Я реализовал несколько наиболее распространённых алгоритмов, и они действительно давали чётко различимые паттерны. Вот, например, сортировка выбором (selection sort):
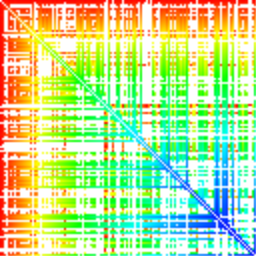
А так выглядит пузырьковая сортировка (bubble sort). Отличие хорошо различимо, и, в принципе, нетрудно понять, откуда оно берётся.
И тот, и другой — неэффективные алгоритмы сортировки (средняя временная сложность — О (n2)). Более продвинутые алгоритмы используют меньшее количество сравнений, потому диаграмма получается менее закрашенной. В начале статьи приведена диаграмма для пирамидальной сортировки (heap sort), на ней куда больше белых пикселей.
Каждая сортировка обладает своим узнаваемым паттерном. Плавный градиент у сортировки выбором, градиент с небольшими поперечными полосами у пузырьковой сортировки, полосы разного цвета у сортировки вставками (insertion sort). Быстрая сортировка (quicksort) всё расчерчивает крестиками, сортировка бинарным деревом (tree sort) — похожими крестиками, но не монотонными, а пёстрыми. У сортировки слиянием (merge sort) характерные короткие синие полосы ближе к диагонали. Диаграмма пирамидальной сортировки напоминает сортировку слиянием, но имеет выраженный цветовой градиент.
«Однако что там насчёт браузеров?» — спросит меня пытливый читатель, не забывший ещё, с чего начиналась статья. Специально для таких читателей я сделал страничку, где можно посмотреть диаграмму Array#sort в своём текущем браузере и сравнить её с диаграммами некоторых известных алгоритмов.
Если вкратце:
- Свежий Firefox использует сортировку слиянием (merge sort), но на достаточно малых массивах переключается на нечто, напоминающее сортировку вставками (insertion sort). Можете проверить это самостоятельно, добавив к URL странички »? size=4» (без кавычек, естественно).
- Свежий десктопный Chrome использует быструю сортировку (quicksort). Однако на iOS он же использует сортировку слиянием.
- Safari на MacOS и iOS также использует сортировку слиянием
- Яндекс.Браузер использует сортировку слиянием
- И старая Opera также использует сортировку слиянием
«Однако что там насчёт Internet Explorer?» — спросит меня пытливый читатель. Что ж, я знал, что до этого вопроса когда-нибудь дойдёт… С IE вышел конфуз. Полученные в IE11 и Edge диаграммы не совпадают ни с одним из реализованных алгоритмов. Выглядят они как-то так:
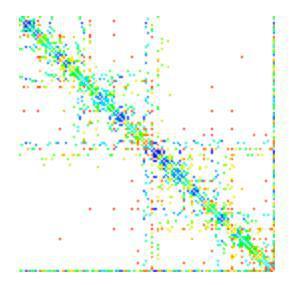
Но я не теряю надежды и продолжаю впиливать в свою страничку новые алгоритмы. А если у вас чешутся руки мне помочь, я охотно приму ваши пулл реквесты.
На текущий момент это всё, что я имею сказать. Надеюсь, вам было интересно.
