Что подвесило систему: баг или вспышка на солнце?

Исходные данные: три системы БД Oracle, которые активно обмениваются между собой данными через механизм распределенных транзакций Oracle. В один прекрасный момент на всех серверах админы стали наблюдать возникновение очередей при попытке выполнить вставки/обновления данных приложением. Процессам, которые блокировали ожидающих пользователей, начали посылать сигналы для их немедленного завершения. После получаса разбирательств, было принято решение перезагрузить все три системы. Далее запустили процедуры по очистке зависших распределенных транзакций, которые находились в статусах COLLECTING и PREPEARED *. После того, как системы привели в работоспособное состояние, начался разбор полетов.
Главный вопрос — что стало причиной сбоя системы? Да, во время инцидента, была выявлена система (одна из трех), которая на этапе первичной диагностики работала с аномалиями (назовем ее система Х). Логин в ОС проходил, но подключиться к БД было невозможно. Причем данные системы оповещения health check фиксировали, что с системой полный порядок и во время зависания внимания на нее особо не обращали. Проблемы первоначально фиксировались на двух других системах (назовем их Y и Z), все внимание было на них.
Начали сбор диагностики. Что-то уже было сделано до, и во время зависания. Кстати, очень помогли в диагностике скриншоты профилей удаляемых процессов из системы мониторинга, как раз перед их удалением.
- На системах Y и Z из истории активных сессий выгрузили статистику удаленных в первую очередь процессов. Процессы до их удаления фигурировали в истории активных сессий, каждый процесс ожидал SQL*Net message from dblink из удаленной системы X. И тут появилась первая аномалия. После 12:32:08 строки истории активных сессий в статистиках потребленного CPU, DB time (TM_DELTA_CPU_TIME, TM_DELTA_DB_TIME) показывали пустые данные.
- Анализ трассировочных файлов БД и листенера системы X. В alert.log БД последняя временная метка до перезапуска системы — Time: 06-SEP-2017 12:27:18. В журнале listener — Wed Sep 06 12:27:18 2017. В директории с трассировочными файлами последнее изменение файла NMON было в 12:26.
- История активных сессий на системе X показывала, что последняя запись из диапазона 12:20 — 14:00 была сделана фоновыми процессами в 12.27.33. В данном случае, сервер Oracle не сохранил данные истории, начиная с 12:27:33.
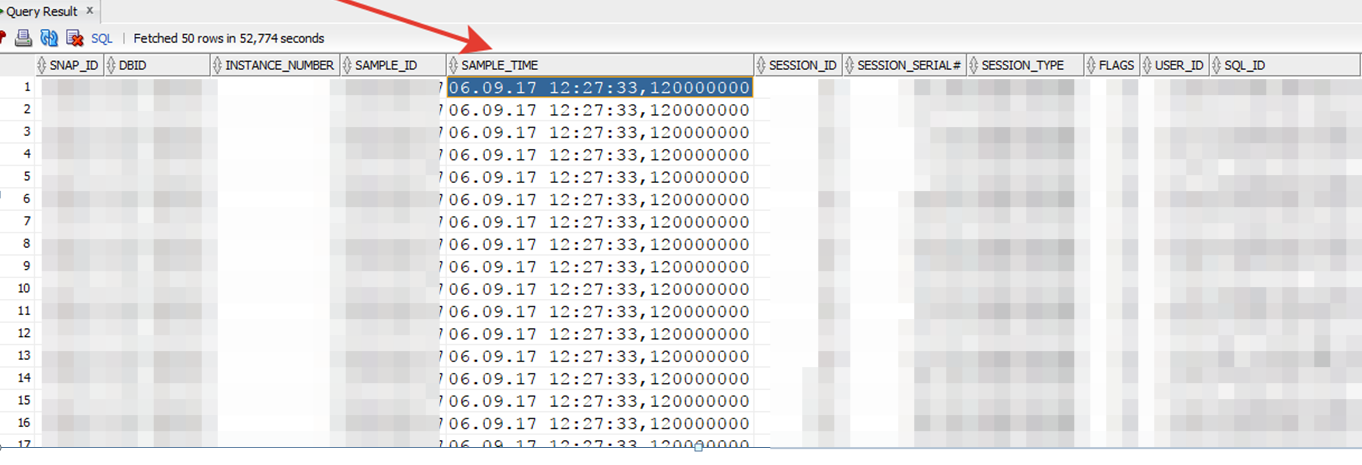
- Очевидно, что-то произошло с БД на системе X. Стали смотреть детально статистику со стороны ОС (CPU, ввод-вывод и т.п.) сервера.
 Наблюдаются значительные ожидания Wait % — когда пользовательские процессы ожидают, пока будет возможна запись/чтение данных с диска (также наблюдаем полное отсутствие kernel write/read system calls, сетевого ввода-вывода падение RunQueue). Время наступления событий ожиданий — также 12:28.
Наблюдаются значительные ожидания Wait % — когда пользовательские процессы ожидают, пока будет возможна запись/чтение данных с диска (также наблюдаем полное отсутствие kernel write/read system calls, сетевого ввода-вывода падение RunQueue). Время наступления событий ожиданий — также 12:28. - С БД и ОС разобрались. Смотрим на нижележащий уровень, файловую систему и СХД. На системе хранения ничего не обнаружили, а вот на Veritas вывод команды errpt показал такую картину (особое внимание на метки времени у последних 2-х строчек — 12:28):
BC3BE5A3 0906140317 P S SRC SOFTWARE PROGRAM ERROR
A6DF45AA 0906140317 I O RMCdaemon The daemon is started.
BC3BE5A3 0906140217 P S SRC SOFTWARE PROGRAM ERROR
D221BD55 0906140217 I O perftune RESTRICTED TUNABLES MODIFIED AT REBOOT
B258EF25 0906140117 T S VxDRV:vxdmp Messages reported by vxdmp driver
B258EF25 0906140117 T S VxDRV:vxdmp Messages reported by vxdmp driver
B258EF25 0906140117 T S VxDRV:vxdmp Messages reported by vxdmp driver
...удалено...
B258EF25 0906122817 T S VxDRV:vxdmp Messages reported by vxdmp driver
B258EF25 0906122817 T S VxDRV:vxdmp Messages reported by vxdmp driver
Промежуточный итог:
Основной причиной возникновения проблем, явился отказ в обслуживании системы X в районе 12:27(28) местного серверного времени. Прямо это видно из журналов БД, listener-a, трассировочных файлов, данных истории активных сессий и журналов файловой системы VxFS. Также подтверждается отсутствием активности после отметки 12:32 на системах Y и Z при сетевых ожиданиях процессов во время вставки данных и фиксации распределенных транзакций. Данные процессы блокировали другие сессии, что приводило к формированию больших очередей процессов на сервере Y. Блокирующие сессии впоследствии были завершены аварийно.
Различие временных меток останова обслуживания на Y, Z и X связано с отставанием сервера X на ~4 минуты от других систем. Если вычесть эту дельту из времени окончания активности процессов на Y, Z (см. выше п.1), получим 12:27(28) — цифры последней активности, которые показывают журналы БД, listener-a и история активных сессий на системе X.
Если восстановить последовательность событий, то цепочка такая: недоступность системы X→появление очередей на Y и Z –> потом — удаление администраторами блокирующих процессов и дальнейшее лавинообразное развитие ситуации с зависанием распределенных транзакций оставшихся компонентов системы.
Итак, похоже дело в файловой системе VxFS от Veritas, на которой располагались файлы базы данных, трассировочные файлы БД и listener-a. ФС впала в «заморозку» и остальные процессы ожидали, пока операция ввода-вывода будет завершена. Решили воспроизвести проблему с помощью команды fsfreeze на тестовых системах — очень похожая картина. Поиском на сайте вендора Veritas обнаружили описание бага с похожими симптомами: Doc Id: 3898129 с симптомами: File system hang can be observed sometimes due to IO’s hung in DRL.
На следующий день открываю новостную ленту –, а там сообщения о вспышках на солнце 6 сентября. За 7 сентября заголовки новостей были все в сообщениях, как эта аномалия на Солнце повлияла на системы связи, людей итд…
06.09.2017 14:05, rg.ru, «Ученые: Мощнейшая вспышка на Солнце окажет воздействие на Землю»
06.09.2017 14:44, rbc.ru, «Астрономы зарегистрировали самую мощную за 12 лет вспышку на Солнце»
06.09.2017 15:34, rg.ru, «Видео: Из-за мощной вспышки на Солнце Москва увидит полярное сияние»
06.09.2017 23:54, rg.ru, «Ученые рассказали о последствиях мощнейшей вспышки на Солнце»
07.09.2017 02:26, regnum.ru, «Мощнейшая вспышка на Солнце: Что ждет Землю?»
07.09.2017 03:39, interfax-russia.ru, «Мощнейшая геомагнитная буря не повлияла на системы боевого управления РВСН»
Некоторые считали, что необходимо наряду с багом в VxFS, как рабочую, рассматривать и эту версию. Тогда я не придал этому особого значения.
На днях решил все-таки плотно разобраться с этим вопросом. В Интернете вышел на сайт Лаборатории рентгеновской астрономии солнца (ФИАН), на котором публикуется статистика солнечной активности со спутника GOES-15. Открываю я страницу с данными за 6 сентября — и что же? На КДПВ всплеск активности по вспышке балла C2.7 как раз попадает на время начала проблем с работой сервера X, причем очень близко к максимуму вспышки — 12:34. Я проверил еще раз время — не UTC ли? Нет, время местное. Ну, не может такого быть. Совпадение?
Однако дополнительный поиск вывел на статью на Geektimes: Космическое излучение может влиять на системы. Оказывается, такое редко –, но бывает. Такие события называются «нарушением в результате единичного события» (single-event upset, SEU). Чаще всего происходят на большой высоте или околоземной орбите, но и случаются на земле. Цитата:
Хотя существуют довольно яркие примеры сбоев техники, SEU остаются исключительно редким феноменом. Но специалисты обращают внимание, что электронные микросхемы всё чаще используются в различных бытовых приборах. Плотность транзисторов на чипах возрастает, как и их количество. Из-за этого вероятность встречи с «космическим сбоем» растёт с каждым годом. Производители электротехники изучают проблему.
Похоже на то, что солнечная активность может быть фактором, влияющим на стабильность и устойчивость работы информационных систем. Что будет дальше при дальнейшей миниатюризации тех. процессов, более плотной упаковке чипов? Вопрос.
На этом все.
Берегите себя!
С наступающим Новым Годом!
* Подробности, что делать в этом случае — можно зачитать в документе: How To Resolve Stranded DBA_2PC_PENDING Entries [ID 401302.1].
