Что ещё можно сделать в поиске? Доклад Яндекса
В Яндексе есть служба разработки поисковых компонент, которая строит поисковую базу на MapReduce, обеспечивает выдачу данных вёрстке для рендеринга, формирует алгоритмы и структуры данных и решает ML-задачи роста качества. Алексей Шлюнкин, руководитель одной из групп внутри этой службы, объясняет, из чего состоит рантайм поиска и как мы им управляем.
Хочешь ковыряться в ML — ковыряйся. Хочешь только MapReduce — окей. Хочешь рантайм — рантайм.
— Что такое поиск сегодня? Яндекс начался с того, что сделал поиск, развивал его. Прошло 20 лет. У нас получилась поисковая база на сотни миллиардов документов.
Документом мы называем любую страничку в интернете, но, на самом деле, не только ее. Еще — ее содержимое, различные статистики о том, какие пользователи любят на нее ходить, сколько их. Плюс посчитанные нами данные.
Также это десятки тысяч инстансов, которые в ответ на каждый запрос обрабатывают данные, что-то ищут, обогащают ответ поиска. Какие-то инстансы ищут картинки, какие-то — обычные текстовые документы, какие-то — видео, и т. д. То есть на каждый ваш запрос активируются десятки тысяч машин. Они все стараются что-то найти и улучшить результат, который вам показывается. Соответственно, десятки тысяч машин обслуживают тысячи запросов в секунду. Эти десятки тысяч инстансов объединены в сотни сервисов, предназначенных для решения какой-то задачи.

Есть ядро поиска — сервис поиска по вебу. А есть сервис поиска по видео, и т. д. Соответственно, есть штука, которая объединяет ответы разных поисков и пытается выбрать, что и в каком порядке лучше показать пользователю. Если это какой-то запрос про музыку, то, наверное, лучше сначала показать Яндекс.Музыку, а потом, например, страничку про эту музыкальную группу. Это называется блендер. Таких сервисов уже тоже сотни, и они тоже на каждый запрос что-то делают и пытаются как-то пользователям помочь. И, конечно же, в этом всем используется машинное обучение просто всех сортов, от каких-то простейших статистик, линейных моделей, до градиентных бустингов, нейросетей и так далее.
Я сейчас буду рассказывать и про инфраструктуру, и про ML.
Моя группа называется группой разработки нового рантайма, она входит в службу разработки поисковых компонент. Чтобы вы имели представление, я чуть-чуть расскажу, чем наша служба занимается.

На самом деле — всем. Если вы представите поиск, то примерно во всё мы запустили свои руки, начиная от построения поисковой базы. То есть у нас есть MapReduce, мы там собираем все данные о документах, провариваем, строим всякие структуры данных, чтобы при запросе по ним что-то эффективно вычислять. Соответственно, мы работаем от самых низов, когда документ к нам только-только попадает, от первой стадии, когда эти документы что-то достают и ранжируют, и до самого верха, где верстка получает условный JSON и рисует его со всеми картинками и красивостями. Снизу доверху по всему стеку мы что-то разрабатываем.
Но мы не только пишем код и, соответственно, все это инфраструктурно делаем. Мы, на самом деле, обучаем нейросетки, CatBoost. И прочие ML-штуки, которые можно себе вообразить и которые жгут, мы тоже обучаем. Еще, так как у нас большие нагрузки, большие данные, мы, конечно, шарим в алгоритмах, структурах данных и никогда не сдерживаемся от их внедрения куда-то. Например, у нас в нескольких местах используются деревья отрезков. У нас есть собственное сжатие индексов, которые строят бор и по нему считают динамику, как лучше словари построить.
В целом, занимаясь такой большой махиной как поиск, мы насытились подобными простыми задачами. Поэтому мы, конечно же, обожаем что-то сложное, новое, то, что нам бросает вызов. И мы не просто пошли и написали, как обычно, десять строк кода. Надо подумать, провести какие-то эксперименты. В целом, те задачи, которые мы перед собой ставим, часто находятся на грани фантастики. Иногда вы думаете: наверное, это невозможно. Но потом вы, может, как-то поэкспериментировали — эксперименты могут занять целый год, —, но в итоге что-то получается. Тогда мы начинаем внедрять, что-то переделывать.
И помимо всяких проектов, скиллов, и так далее, в целом мы одна из самых амбициозных и быстро растущих команд в Яндексе. Например, я пришел два года назад, был девятым человеком у нас в службе. Сейчас у нас служба практически 60 человек. Это, на самом деле, со стажерами, но, в общем, в четыре раза мы за два года выросли точно. Это чтобы вы примерно имели представление, чем наша служба занимается.
Теперь я хочу чуть-чуть по верхам рассказать о наших задачах и том направлении, которое, как мне кажется, в ближайшее время у нас будет все более и более актуальным. Но для этого надо сначала вкратце рассказать, как работает самый базовый слой поиска.
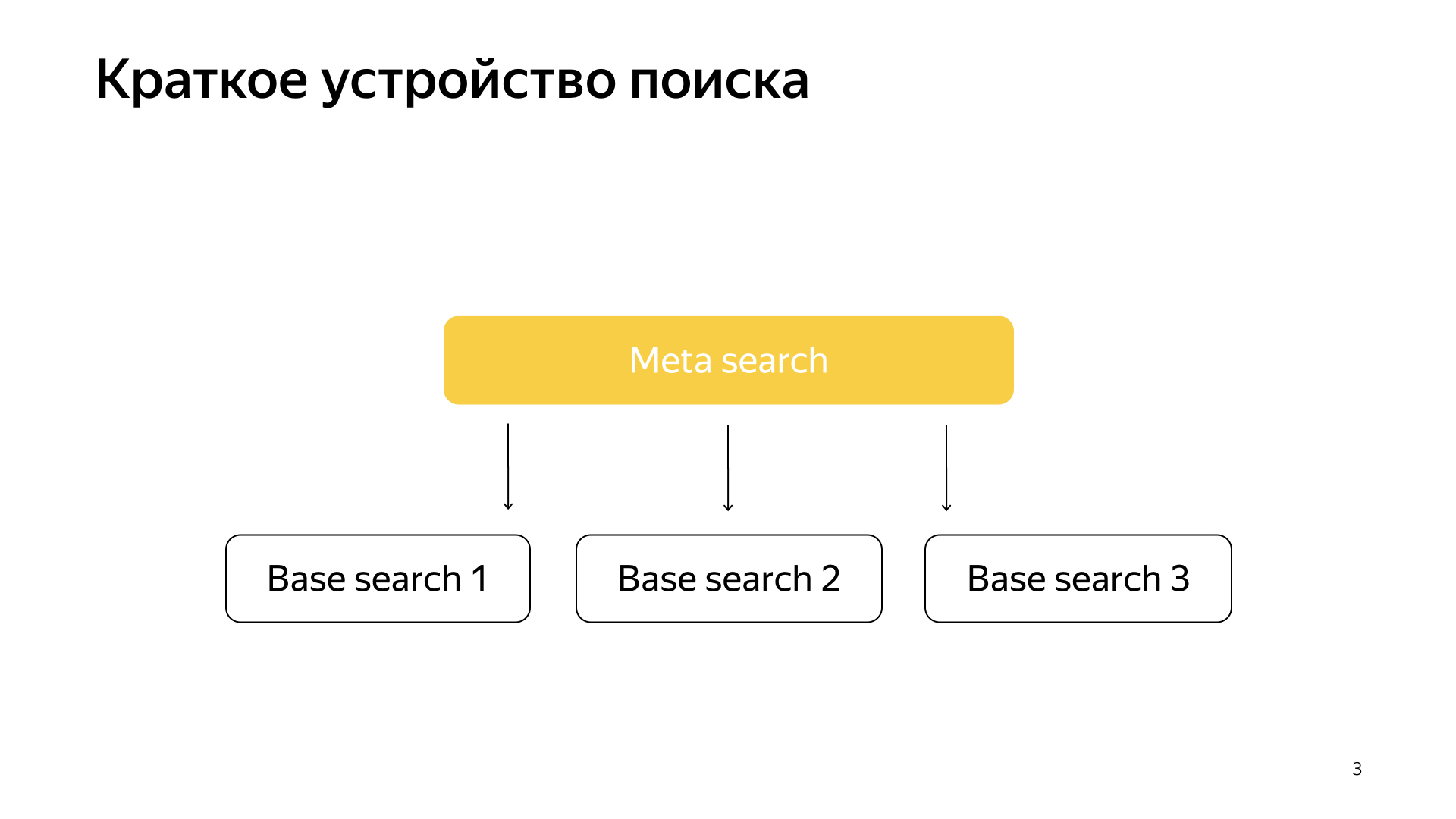
Если общо, все работает очень просто. У нас есть наша поисковая база, есть все документы, и мы все эти документы делим более-менее равномерно на N каких-то кусочков. Они называются шардами. И над шардом запускается программа, которая называется «Базовый поиск». У нее задача выполнять поиск, соответственно, по этому кусочку интернета. То есть она умеет по нему искать и больше про другой интернет ничего не знает. И таких у нас N шардов. Над ними запущены базовые поиски, и, соответственно, над этим есть мета-поиск. В него сваливается запрос пользователя и он, соответственно, просто ходит во все шарды, и каждый шард выполняет поиск, потом каждый возвращает результат, и он выполняет какое-то слияние и отдает ответ.
Примерно так был устроен поиск практически все 20 лет, и, в общем-то, долгое время думали, что это примерно так и останется, и лучше уже ничего сделать нельзя. Но все меняется, появляются новые технологии, и машинное обучение сейчас не только позволяет растить качество, но и позволяет решать какие-то инфраструктурные задачи. В последнее время у нас в поиске очень выстреливают проекты, как раз на стыке инфраструктуры и машинного обучения. Когда два таких мастодонта сливаются, получаются очень интересные результаты.

В последнее время появились нейросети. У нас есть текст запроса, есть текст документа. Мы хотим из запроса получить какой-то вектор чисел, из документа получить какой-то вектор чисел так, чтобы скалярное произведение предсказывало ту величину, которую мы хотим. Например, хотим обучить, чтобы скалярное произведение предсказывало вероятность клика пользователя по этому документу. Вполне понятная вещь.
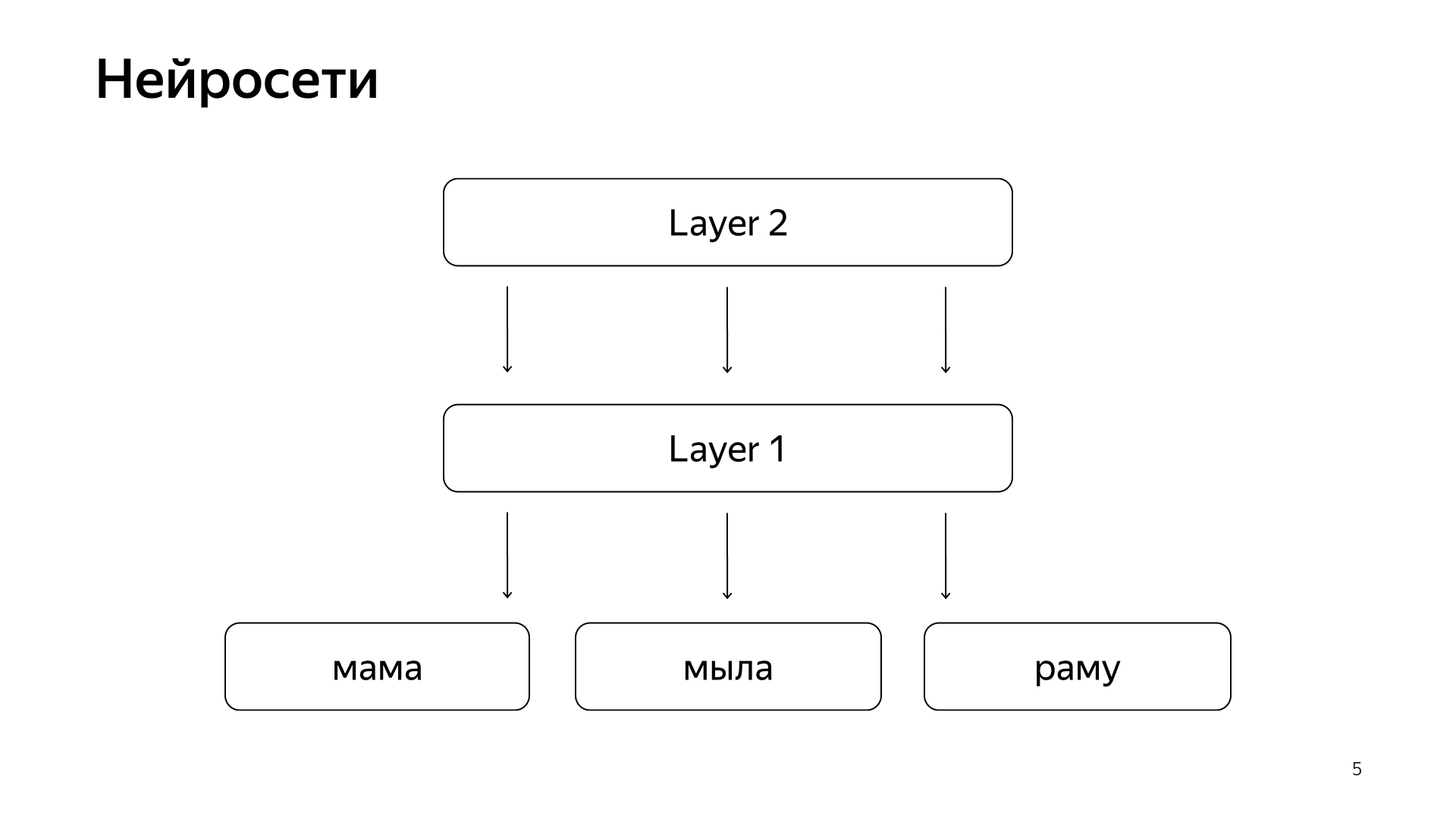
Устроено это примерно так. Если очень-очень грубо, то у нас на нижнем слое есть какие-то слова, и дальше есть несколько слоев сети. Каждый слой, на самом деле, берет на вход какой-то вектор. То есть нижний слой, это такой разреженный вектор, где каждое слово — запрос. Умножает его на матрицу, получает какой-то вектор, и дальше, соответственно, к каждому компоненту применяет какую-то нелинейность, и так несколько раз это делает. И последний слой, это называется как раз тот вектор, который мы как раз взяли запрос, применил такие слои, и вот последний слой — это тот самый вектор запроса.
Соответственно, эти нейросети у нас уже последние годы активно в поиск внедрялись, приносили очень много пользы для качества. Но у них есть одна проблема в том, что все величины, которые мы хотим предсказывать, они хорошие, но достаточно грубые, потому что, чтобы обучить такую нейросеть, нижний слой очень большой, — все слова из десятков миллионов слов, поэтому надо уметь подать ей на вход несколько миллиардов данных.
Мы, например, можем обучать на какие-то пользовательские клики, и так далее. Но тот основной сигнал, который у нас в поиске считается самым главным, это ручная разметка специальными людьми. Они берут запрос, берут документ, читают его, понимают, насколько он хорош и выставляют оценку, то есть, насколько этот документ подходит под этот запрос. Вот такую величину мы долгое время не могли предсказывать нейросетями, потому что оценок у нас все равно какие-то миллионы, потому что нанять всю планету, чтобы она постоянно это все размечала, — это очень дорого. Поэтому мы сделали некоторый хак.
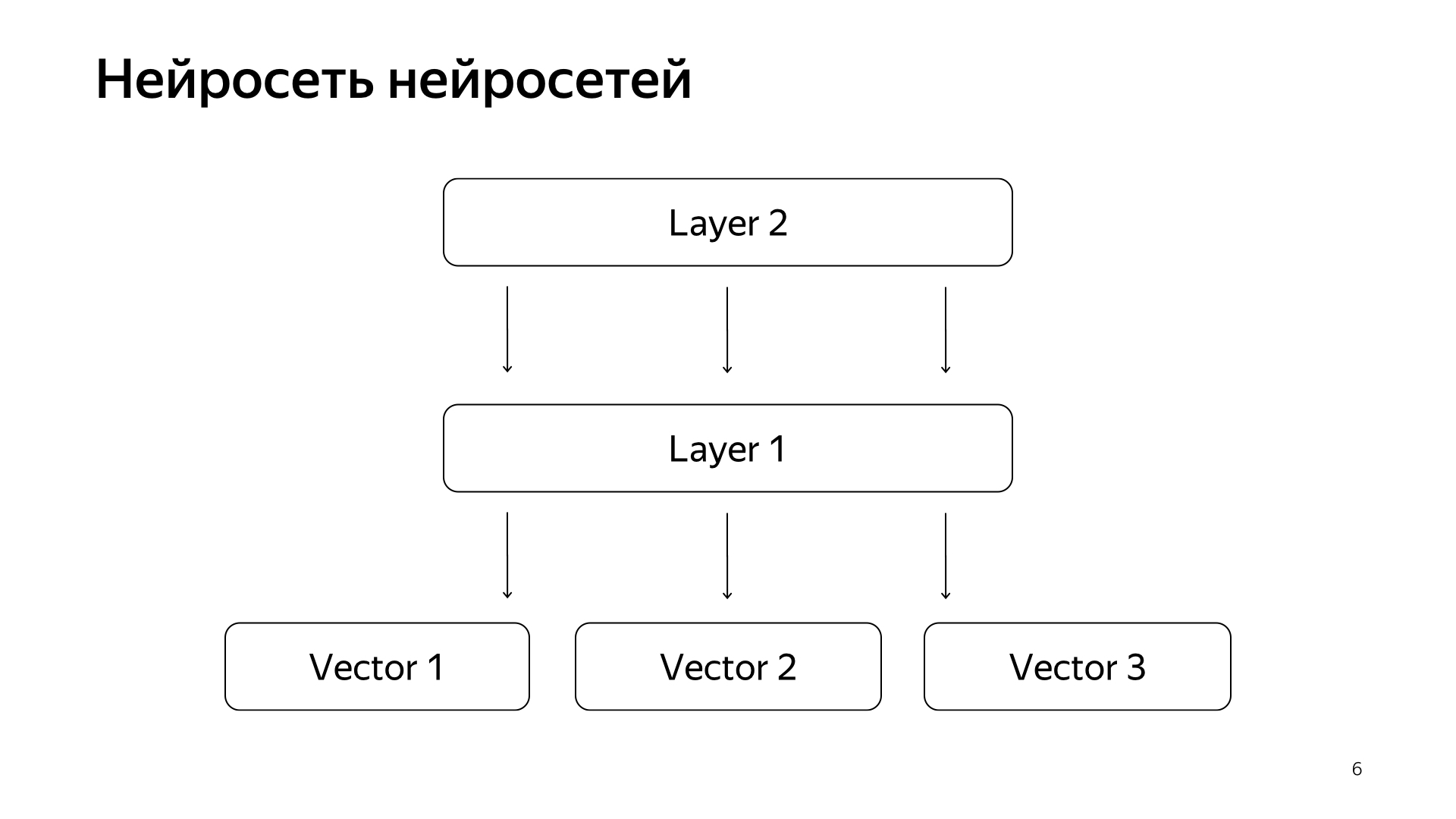
Нейросеть нейросетей. У нас скопилось за последние годы достаточно много каких-то нейросеток, которые предсказывают хорошие сигналы, но чуть более грубые, чем оценка специальных людей. Соответственно, мы решили, что на нижний слой мы подадим уже готовые вектора этих сетей, а дальше обучим нейросеть предсказывать уже как раз на меньшем data-сете нашу поисковую релевантность.
Получилась очень хорошая модель. Она и запросы документов приводит в вектор, и их скалярное произведение предсказывает прямо настоящую релевантность, которую мы давно хотели предсказывать.
Дальше у нас возникла идея, как можно поиск немножко переделать. Проект называется KNN-базой (англ. k-nearest neighbors, метод k-ближайших соседей).

Основная идея такая. У нас есть вектор запроса и вектор документа. Нам надо найти ближайший. У нас каждый документ представлен вектором. Давайте выделим N кластеров, те, которые характеризуют все пространство документов. Грубо говоря. Сильно меньше, чем количество документов, но например, они характеризуют темы. Если простым языком, есть кластер про котиков, кластер про тачки, кластер про программирование, и так далее.
Соответственно, будем документы раскидывать не как-то рандомно по шардам, как раньше, а будем документ класть в тот шард, то есть центроид которого ближе всего к документу. Соответственно, у нас в шарде будут такие сгруппированные по темам документы.
А дальше просто на запрос теперь мы можем ходить не во все шарды, а ходить только в какое-то маленькое подмножество тех, кто самый близкий к этому запросу.
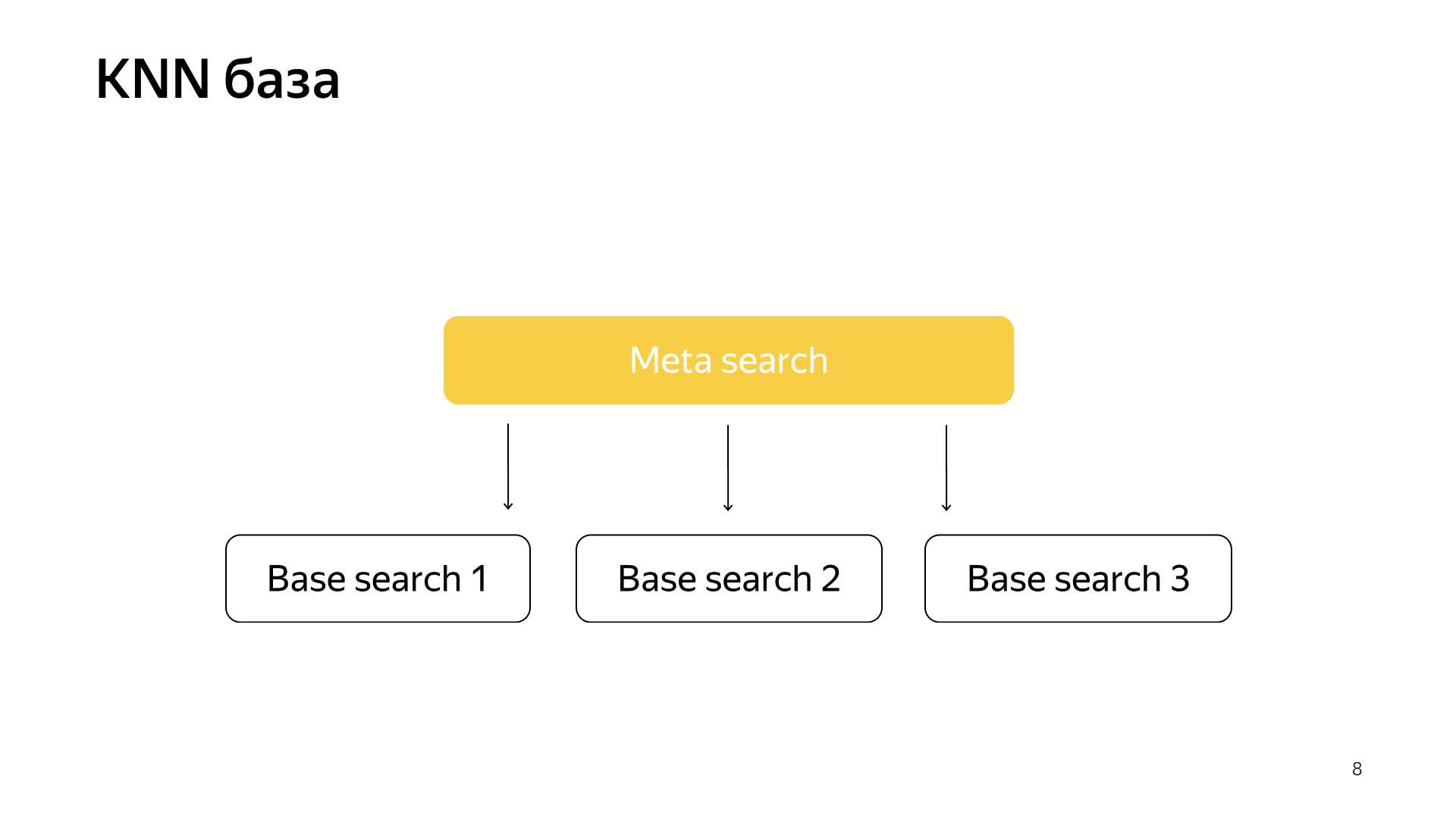
Соответственно, у нас была такая схема, мета-поиск входит во все шарды. А теперь ему надо ходить в сильно меньшее количество, и при этом мы все равно будем искать ближайшие документы.
Что мы, собственно, от такой конструкции получаем? Она значительно снижает потребление вычислительных ресурсов, просто потому что мы ходим в меньшее количество кластеров. Это, как я уже говорил, я считаю, одной из изюминок нашей службы, этот тот сплав инфраструктуры и машинного обучения, который дает такие результаты, о которых раньше никто не могу подумать.

И, в конце концов, это просто достаточно веселая штука, потому что ты тут модельки получил, а потом пошел, весь поиск переделал, петабайты данных поворочал, и у тебя поиск работает, жжет в десять раз меньше ресурсов. Ты сэкономил компании миллиард долларов, все счастливы.

Я рассказал про один из проектов, который возникает у нас в поиске и который внедряется и делается вместе со всеми экспериментами условно год. Другие наши типичные задачи — это вырастить поисковую базу еще в два раза, потому что интернет постоянно растет и мы хотим его догнать и искать по всем страничкам в интернете. И конечно, это ускорение базового слоя, в котором больше всего инстансов, больше всего железа. Для примера, ускорить базовый поиск на один процент означает сэкономить примерно миллион долларов.
Еще мы занимаемся поиском как инкубатором стартапов. Я поясню. Поиск делается 20 лет. В нем уже много всего сделано, много раз мы упирались в какой-то тупик и думали, что больше ничего сделать нельзя. Потом была долгая череда экспериментов. Мы опять этот тупик пробивали. И у нас за это время скопилось очень много экспертизы того, как делать большие и крутые вещи. Соответственно, сейчас большинство новых направлений в Яндексе делается в поиске, потому что люди в поиске уже умеют все это делать, и логично их попросить как минимум задизайнить какую-то новую систему. А как максимум — самим пойти и сделать.
Теперь, надеюсь, вы чуть-чуть представляете нашу работу. Я быстренько расскажу тематическую часть своего рассказа, про стажеров в нашей службе. Мы их очень любим. У нас их много, прошлым летом только в моей группе было 20 стажеров, и я считаю, что это хорошо. Когда берешь одного-трех стажеров, они чувствуют себя немного одиноко, иногда боятся спросить у старших товарищей. А когда их много, они друг с другом общаются как товарищи по несчастью. Если боятся спросить что-то у разработчиков — пойдут, пошушукаются в углу. Такая атмосфера помогает делать все эффективно.
У нас миллион задач, команда не очень большая, поэтому стажеры у нас загружены по полной. Мы не просим стажера сидеть все время грепать лог, писать тесты, рефакторить код, а сразу даем какую-то сложную продакшен-задачу: ускорить поиск, улучшить сжатие индекса. Конечно, помогаем. Мы знаем, что это все окупается, поэтому мы с удовольствием делимся своей экспертизой. Так как наша сфера деятельности достаточно обширная, то каждый у нас найдет себе задачу по вкусу. Хочешь ковыряться в ML — ковыряйся. Хочешь только MapReduce — окей. Хочешь рантайм — рантайм. Есть все что угодно.
Что надо, чтобы попасть к нам? Мы все делаем в основном на C++ и Python. Не обязательно знать и то и другое, можно знать что-то одно. Мы приветствуем знание алгоритмов. Оно формирует определенный стиль мышления, а он очень помогает. Но это тоже необязательно: опять же, мы всему готовы учить, готовы вкладывать свое время, поскольку знаем, что это окупается. Самое главное требование, которое мы предъявляем, наш девиз, — это ничего не бояться и много фигачить. Не бояться уронить продакшен, не бояться начать делать что-то сложное. Поэтому нам нужны такие люди, которые тоже ничего не боятся и тоже готовы сворачивать горы. Спасибо большое.
