Что эффективнее — усложнять модель или увеличивать количество данных?
Привет, Хабр! Меня зовут Ольга, я кандидат физ-мат наук в области астрофизики. Однако недавно я увлеклась IT и окунулась в область Data Science. Чтобы изучить эту тему, прошла ряд курсов (как платных, так и бесплатных), и в основном там процесс разработки модели машинного обучения подаётся как «так, берём данные, удаляем выбросы, стандартизируем и идём подбирать гиперпараметры моделей». Однако в рабочей практике оказалось, что это только часть задачи, и в первую очередь нужно всё‑таки собрать эти самые данные. Которых зачастую бывает недостаточно. К чему это приводит?
Статья «Необоснованная эффективность данных», написанная сотрудниками Google в 2009 году, говорит нам:
Простые модели с множеством данных превосходят сложные модели с меньшим количеством данных.
Этот принцип заложен в основу подхода, ориентированного на данные (Data-driven) — приоритет отдаётся информации, содержащейся в данных, в то время как модель выступает в роли инструмента. Важную ценность несут именно сами данные, которые позволяют извлекать информацию для принятия точных и эффективных решений. Если данных недостаточно, в них отсутствуют чёткие закономерности или они недостаточно разнообразны, то потенциал машинного обучения ограничивается. Но как определить, что объём данных достаточен? Где лежат границы между большим и маленьким объёмом данных? Этот вопрос мы сейчас попробуем поисследовать.
Как можно оценить качество предсказаний исходя из сложности модели или объёма данных? Для этого я предлагаю взять обширный датасет, обучить модель на полной выборке и на её части, и затем провести сравнительный анализ результатов. Важным шагом будет настройка гиперпараметров модели на основе лишь фрагмента данных. Оценка усложнённой модели будет проводиться как на этой части, так и на полном наборе данных. И лишь после всех этапов можно будет сделать выводы.
В качестве объекта исследования был выбран набор данных Sloan Digital Sky Survey — DR18. Этот набор содержит информацию о небесных объектах, которую можно использовать для обучения модели классификации. Данные состоят из 100 000 наблюдений 18-го выпуска астрономического проекта Sloan Digital Sky Survey (SDSS). Обширный объём датасета предоставляет отличную возможность изучить, как точность модели зависит от количества данных. Особенно приятно бывшему астрофизику иметь дело с астрономическими объектами. Датасет предоставляет задачу классификации, в рамках которой необходимо распределить наблюдения по категориям вида объекта: звезда (STAR), галактика (GALAXY) и Квазар или Квазизвездный объект (Quasi-Stellar Object, QSO).
Описание параметров наблюдений
Признаки классифицируются на:
Общая информация:
Objid, Specobjid — идентификаторы объектов,
ra — прямое восхождение J2000,
dec — склонение J2000,
redshift — красное смещение,
u, g, r, i и z — измерения светимости в разных фотометрических полосах, охватывающих ультрафиолетовую, зелёную, красную, инфракрасную и ближнюю инфракрасную области спектра.
Идентификация наблюдений:
run — номер прохода, во время которого проводилось наблюдение за определённой областью неба,
rerun — номер повторной обработки, связанной с анализом полученных данных,
camcol — номер столбца камеры, отвечающей за изображение данного наблюдения,
field — номер поля, представляющего конкретную часть неба, снятую в одной экспозиции телескопа,
plate — номер пластины,
fiberID — идентификатор оптического волокна,
mjd — модифицированная юлианская дата, представляющая количество дней с полуночи 17 ноября 1858 года. Используется для отслеживания времени каждого наблюдения.
Свойства объектов:
petroRad_u, petroRad_g, … — радиусы объектов в пяти фотометрических полосах,
petroFlux_u, petroFlux_g, … — потоки в пяти фотометрических полосах,
petroR50_u, petroR50_g, … — радиусы, на которых половина интенсивности излучаемого света содержится в апертуре объекта,
psfMag_u, psfMag_g, … — замеры объектов на основе функции распределения точек (PSF) в пяти фотометрических полосах. Они предоставляют информацию о яркости и цвете астрономических объектов,
expAB_u, expAB_g, … — отношения осей экспоненциальной аппроксимации к профилю света астрономических объектов в пяти фотометрических полосах. Эти показатели помогают характеризовать форму объектов.
Для начала загрузим датасет и разделим его на обучающую и тестовую выборки. Обратите внимание, что идентификаторы объектов в данной задаче не предоставляют полезную информацию, поэтому мы исключаем их из признаков. Координаты также скорее всего не окажут существенного влияния на классификацию объектов. Хотя проведение исследовательского анализа и предварительной обработки данных могло бы улучшить конечные результаты, в данной работе мы ограничимся исследованием зависимости качества модели от объёма данных.
Код:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import accuracy_score
import random
df = pd.read_csv('SDSS_DR18.csv')
X = df.drop(columns = {'objid','specobjid','class'}, axis=1)
y = df['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)Для начального этапа исследования был использован полный объём данных. В качестве модели я применяю бустинг от LightGBM, предоставляющую быстрое обучение и настройку за счёт обширного набора гиперпараметров. Запускаем процесс обучения модели на полном объёме данных и получаем предварительную оценку.
Код:
model = lgb.LGBMClassifier(verbose = 0, force_col_wise = True)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
print('Score: ', score)Отличный результат! Оценка accuracy в 0.99364 для «голой» (без подбора гиперпараметров) модели LGBMClassifier на полном наборе данных говорит о хорошей способности модели обобщать и классифицировать объекты.
Продолжая исследование, проанализируем, как будет меняться оценка в зависимости от сокращения объёма данных. Мы будем использовать метод cross_val_score для оценки модели на кросс-валидации. Для этого мы будем сокращать объём данных с шагом в 1000 объектов. Такой анализ позволит лучше понять, как количество данных влияет на стабильность и качество модели.
Исходя из этого, мы начинаем итерации, каждый раз обучая модель на сокращённых данных и оценивая её качество через кросс-валидацию. По завершении всех итераций мы получим набор оценок, которые помогут прояснить, каким образом уменьшение объёма данных влияет на результаты моделирования.
Код:
%%time
count_list = []
mean_score = []
max_score = []
min_score = []
std_score = []
for i in range(1000, X_train.shape[0] + 1, 1000):
count_list.append(i)
score_list = cross_val_score(model, X_train[:i], y_train.values[:i], cv=4)
mean_score.append(score_list.mean())
max_score.append(score_list.max())
min_score.append(score_list.min())
std_score.append(score_list.std())
plt.figure(figsize = (15,5))
plt.plot(count_list, mean_score, color = 'black')
plt.errorbar(count_list, mean_score, std_score)
plt.fill_between(count_list,min_score,max_score,alpha=.2)
plt.xlabel('Количество данных в обучающей выборке')
plt.ylabel('Accuracy')Для наглядной визуализации изменений в оценках модели в зависимости от объёма данных положим результаты на график. Тут будут отображены средние оценки для каждой из итераций, а также разброс между минимальным и максимальным значениями на кросс-валидации четырех моделей. Для наглядности добавим бары ошибок, которые представляют собой среднеквадратичное отклонение.
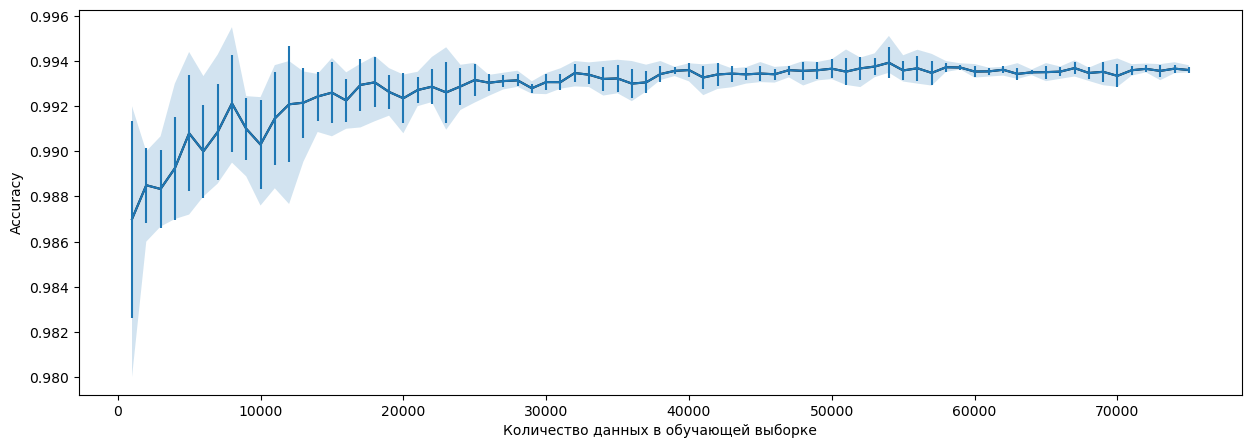
Зависимость accuracy модели от количества данных в обучающей выборке
Заметно, что с увеличением объёма данных оценки становятся более стабильными: разброс и стандартное отклонение снижаются, а средняя оценка повышается. Следует отметить, что эти оценки основаны на «дефолтных» моделях, то есть моделях, которые обучены без дополнительной настройки гиперпараметров.
Теперь мы сосредоточимся на оценке модели на наборе данных, который составляет около 20 000 наблюдений — примерно в 4–5 раз меньше, чем исходный объём выборки (с учетом разделения на test/train). Мы повторно оценим модель с помощью cross_val_score, а также проведем оценку на тестовых данных. Затем, для улучшения производительности модели именно на этом наборе данных, мы воспользуемся методом BayesSearchCV. Этот инструмент оптимизирует гиперпараметры алгоритма с использованием байесовской оптимизации.
Планируется подбор оптимальных значений для различных гиперпараметров, включая тип бустинга (boosting_type), количество листьев в деревьях (num_leaves), максимальную глубину дерева (max_depth), скорость обучения (learning_rate), количество итераций (num_iterations), регуляризацию весов (reg_alpha), частоту выполнения бэггинга (bagging_freq) и долю случайно выбранных данных при построении каждого дерева (bagging_fraction). Ожидается, что оптимизация этих гиперпараметров сделает модель более обобщающей. На данный момент, «дефолтная» модель, обученная на 20 000 данных, дает оценку accuracy на тесте равную 0.99292.
Код:
from skopt import BayesSearchCV
from skopt.space import Integer, Real, Categorical
import scipy.stats as stats
param_grid = {
'boosting_type': ['gbdt', 'dart', 'rf'], # default = gbdt
'num_leaves': Integer(10, 200), # default = 31
'max_depth': Integer(2, 12), # default = -1
'learning_rate': Real(0.0001, 0.3), # default = 0.1
'num_iterations': Integer(50,3000), # default = 100
'reg_alpha': Real(0.0001, 0.1), #default = 0.0
'bagging_freq': Integer(1, 5), # default = 0
'bagging_fraction': Real(0.1, 0.9) # default = 1.0
}
# Создание модели и настройка с использованием байесовской оптимизации
model = lgb.LGBMClassifier(verbose = -1, force_col_wise = True)
bayes_search = BayesSearchCV(model, param_grid, n_iter=500, cv=3)
bayes_search.fit(X_train[:20000], y_train[:20000])
# Вывод наилучших гиперпараметров и оценки
print("Best Hyperparameters:", bayes_search.best_params_)
print("Best Cross-Validation Score:", bayes_search.best_score_)Вывод:
Best Hyperparameters: OrderedDict ([('bagging_fraction', 0.9), ('bagging_freq', 3), ('boosting_type', 'gbdt'), ('learning_rate', 0.24792510780742116), ('max_depth', 10), ('num_iterations', 2140), ('num_leaves', 41), ('reg_alpha', 0.06929527881184443)])
Best Cross-Validation Score: 0.9931499974656233
Модель с подобранными гиперпараметрами имеет больший num_leaves и num_iterations — это должно улучшить качество. Увеличенный reg_alpha и bagging_fraction < 1 помогут избежать переобучения, при этом learning_rate выше дефолтного значения. Так же лучшие оценки по BayesSearchCV показывает тип бустинга 'dart' (Dropouts meet Multiple Additive Regression Trees) - его используют для увеличения точности, поскольку этот метод случайным образом отключают (зануляют) некоторые признаки при обучении новых деревьев в ансамбле. Это помогает снизить корреляцию между деревьями, более устойчиво обрабатывать выбросы и шум и улучшить обобщающую способность модели.
При этом оценка даже ниже, чем на default-модели — 0.99272. Возможно, увеличение сложности модели привело к переобучению, особенно при ограниченном количестве данных. Это может быть вызвано тем, что увеличенные гиперпараметры не позволяют модели обобщать на новых данных, что ведет к понижению обобщающей способности.
Ну чтож, подбор гиперпараметров не дал особого результата. Может, он просто не работает? Попробуем обучить модель с этими гиперпараметрами на полном наборе данных:
Код:
model = lgb.LGBMClassifier(verbose = 1, force_col_wise = True,
bagging_fraction = 0.9, bagging_freq = 3,
boosting_type = 'gbdt', learning_rate = 0.24792510780742116,
max_depth = 10, num_iterations = 2140, num_leaves = 41, reg_alpha = 0.06929527881184443)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
print('Score: ', score)Вывод:
Score: 0.99416
Итого, оценки accuracy, полученные на разных по объёмам данных и сложности моделях:
Default-модель, 76000 строк | Default-модель, 20000 строк | Оптимальная модель, 20000 строк | Оптимальная модель, 76000 строк |
0.99364 | 0.99292 | 0.99272 | 0.99416 |
В рамках данной статьи мы наблюдаем, что accuracy «дефолтной» модели на сокращенных данных оказалась выше, чем оценка лучшей модели, полученной в результате оптимизации гиперпараметров с помощью BayesSearchCV. Это важный вывод, который подчеркивает, что иногда более сложная модель не обязательно будет лучше справляться с задачей, особенно при ограниченных объёмах данных.
Учитывая это наблюдение, следует обратить внимание на баланс между сложностью модели и доступными данными. Важно уделять внимание обобщающей способности модели, чтобы она успешно работала не только на обучающих данных, но и на новых, ранее не виданных примерах.
