Автоматическая генерация CI/CD пайплайна для развёртывания инфраструктуры
Подход «Инфраструктура как код» означает, что инфраструктура создаётся, развёртывается и управляется при помощи кода. Это позволяет автоматизировать процессы, делать их более гибкими и масштабируемыми. Код для инфраструктуры фиксирует конфигурацию, обеспечивает воспроизводимость и упрощает управление настройками. Также благодаря этому подходу возрастает эффективность работы команды, поскольку он позволяет вести совместное развитие инфраструктуры и обеспечивает удобство отслеживания изменений.
Именно этот подход мы используем при нашей работе. Однако в процессе его использования мы столкнулись с проблемой написания пайплайнов для инфраструктуры.
Мы были вынуждены сделать процесс выкатки инфраструктуры максимально точечным из-за использования terragrunt. Каждый его модуль должен выкатываться отдельно, иначе будут получены десятки планов, и понять, что делает каждый из них, будет невозможно. Это означает, что каждому модулю terragrunt нужна отдельная джоба в пайплайне на plan и apply, но для каждого модуля они во многом повторяют друг друга. Подобное постоянное написание одинаковых частей CI/CD пайплайна при добавлении новых баз и бакетов навевало тоску.
Меня зовут Татьяна Мигулаева, я DevOps-инженер в «Магните». Поделюсь тем, как мы создали генератор джоб в GitLab CI/CD и навсегда забыли о ручном написании пайплайнов для развёртывания элементов инфраструктуры.
Что мы имеем
Инфраструктура на базе Yandex Cloud, описанная в terragrunt-файлах, код которых хранится в GitLab.
Периодически приходится создавать новые файлы или изменять существующие — например, чтобы поправить название пользователя в managed базе или создать новый топик в Кафке. После внесения этих изменений их необходимо выкатить в облако, предварительно проверив, что при выкатке ничего не сломается. Для этого используются CI/CD пайплайны со следующим флоу:
При создании merge request должен запускаться terragrunt plan, который проверяет допустимость вносимых в коде изменений и показывает, что произойдёт, если их применить. При мерже этих изменений в main должен повторно запускаться terragrunt plan, а после него — terragrunt apply, который применит эти изменения на инфраструктуре.
Есть два примерных варианта, как это реализовать:
1. Большой статичный пайплайн, который включает в себя все сервисы сразу.
Плюсы: не надо ничего менять, для выкатки достаточно изменений в terragrunt-файле. Удобно, когда инфраструктура небольшая и не меняется слишком часто.
Минусы: Такой пайплайн может выполняться довольно долго. При этом результатом его работы будут сотни планов и отчетов в гитлабе. По ним будет очень тяжело понять, какие изменения были внесены в код и как они отразятся на инфраструктуре. Также такой пайплайн будет не полностью управляем: не получится нажать кнопку деплоя отдельно для того элемента инфраструктуры, в который были внесены изменения.
2. Для каждого элемента — отдельный шаг в пайплайне. Автоматически запускаются только те шаги, в которые были внесены изменения. terragrunt apply применяется отдельно для каждого элемента инфраструктуры и запускается только вручную.
Плюсы: Это удобно, пайплайн выполняется относительно быстро. При этом нет риска случайно выкатить не то.
Минусы: Придётся постоянно дописывать новые шаги в CI/CD, высок риск ошибки. Учитывая, что наша инфраструктура динамична и много и часто меняется, делать такие изменения пришлось бы постоянно. И это просто скучно :)
Наше решение
В нашем решении объединены плюсы обоих вариантов. По сути мы изменяем только код инфраструктуры, а наш пайплайн автоматически подстраивается под это.
При создании merge request автоматически генерируется и запускается шаг пайплайна, который запускает terragrunt plan только для тех terragrunt-файлов, в которые были внесены изменения.
Например, мы решили создать postgres-базу в облаке для сервиса my-lovely-service. Для этого создали в репозитории в нужной папке terragrunt-файл с конфигурацией бакета. Далее создали merge request с этими изменениями. При этом был автоматически создан и запущен следующий шаг пайплайна.

Есть возможности зайти в пайп и посмотреть вывод команды terragrunt plan. Стоит обратить внимание, что для остальных файлов в репозитории пайплайн не запускался, что значительно ускоряет работу.
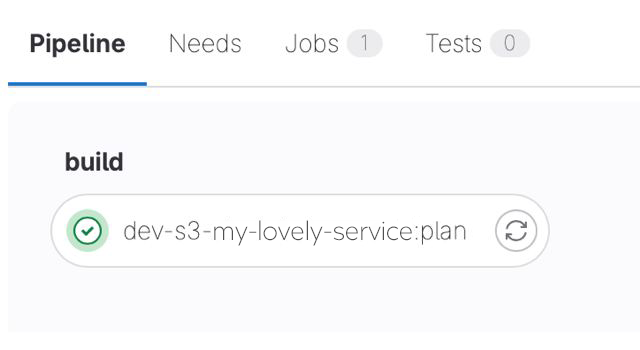
После слияния изменений в main запускается пайплайн целиком, но при этом триггерятся только те шаги terragrunt plan, которые запускались на merge request. У нас этот пайплайн выглядит немного страшно.
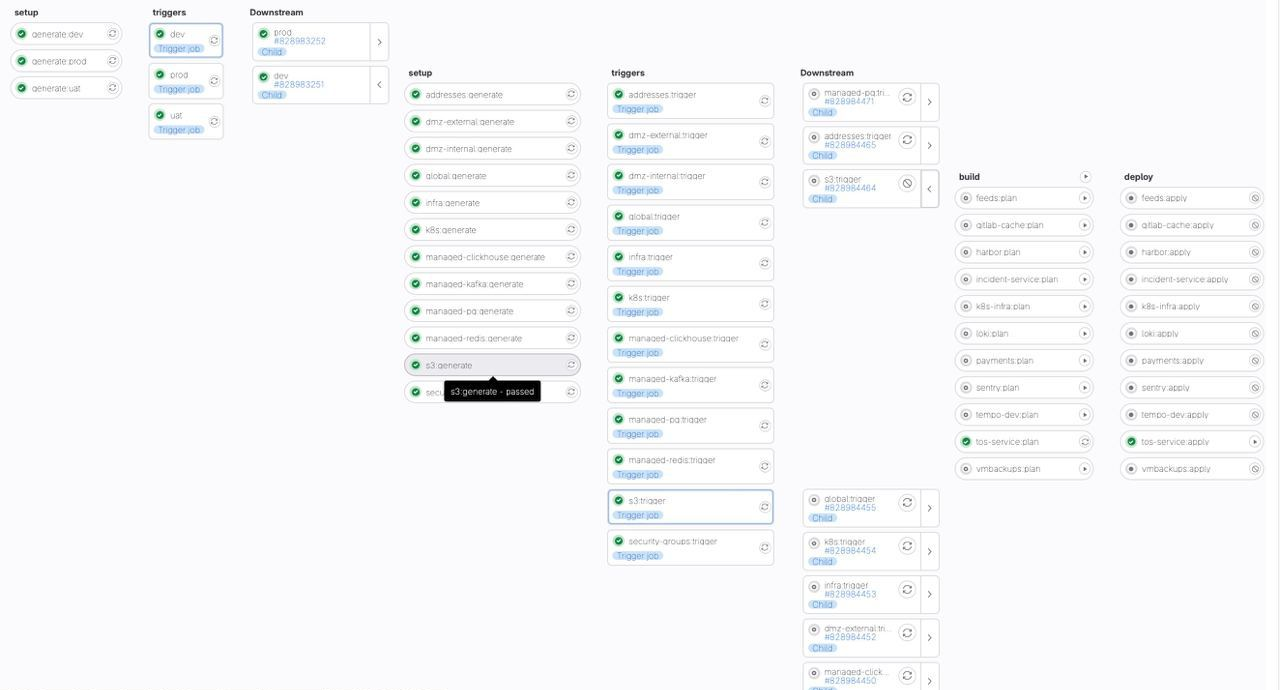
Но это зависит от количества сервисов и размера инфраструктуры.
Далее в нём можно вручную запустить terragrunt apply для тех элементов инфраструктуры, которые необходимо развернуть.
Реализация
Далее рассмотрим подробнее, как мы это реализовали. Для примера будет взято использование dev-окружения, при необходимости можно добавлять аналогичные шаги соответственно количеству окружений.
Здесь важно обратить внимание на то, как работает include в GitLab CI/CD. Если кратко — он объединяет имеющийся CI/CD файл и те, которые указаны в include. При этом шаги, которые называются одинаково в нескольких файлах, сливаются между собой. Подробнее можно изучить в документации Gitlab: https://docs.gitlab.com/ee/ci/yaml/#include
Предположим, нам надо создать s3 бакет для сервиса my-service в dev-окружении. Для этого в папке dev создаём папку my-service и создаём в ней terragrunt.hcl файл, из которого будет создаваться бакет.
Делаем коммит с этими изменениями в отдельную ветку. В этот момент pre-commit hook запускает следующий скрипт.
generate-mr-jobs.sh
#!/bin/sh
echo '' > .gitlab-ci-mr-jobs.yml
for env in "dev" "uat" "mm-dev" "mm-uat"
do
isMmProject=false
if [[ "$env" =~ ^mm-.*$ ]]
then
isMmProject=true
fi
for root in $(git ls-files -s |grep -oE "\s${env}/.*terragrunt.hcl$" | xargs dirname)
do
prefix=$(echo "$root" | tr / -)
cat >>.gitlab-ci-mr-jobs.yml <В данном скрипте сначала очищается имеющийся файл с джобами, после чего прописывается ci/cd шаг для каждого terragrunt файла в репозитории.
Таким образом, мы получаем файл .gitlab-ci-mr-jobs.yml со списком шагов следующего вида:
dev-s3-my-service:plan:
variables:
TF_ROOT: "dev/s3/my-service"
extends:
- .terragrunt:plan:dev
- .rules:mr:devПосле создания merge request с нашими изменениями запускается ci/cd пайплайн. Сам gitlab-ci.yml файл включает в себя три других:
include:
- '.gitlab-ci-terragrunt.yml'
- '.gitlab-ci-templates.yml'
- '.gitlab-ci-mr-jobs.yml'А также следующие шаги:
stages:
- build
- deploy
- setup
- triggersФайл gitlab-ci-mr-jobs.yml был рассмотрен ранее.
В gitlab-ci-templates.yml задаются такие элементы, как теги раннеров, правила создания шагов и так далее. Выглядит он следующим образом.
gitlab-ci-templates.yml
.runners:dev:
tags:
- devops
- dev
.rules:mr:dev:
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
changes:
- terragrunt.hcl
- provider.tmpl
- dev/env.hcl
- ${TF_ROOT}/*
- ${TF_ROOT}/**/*
.rules:default:dev:
rules:
- if: $CI_COMMIT_REF_PROTECTED == "true"
changes:
- terragrunt.hcl
- provider.tmpl
- dev/env.hcl
- ${TF_ROOT}/*
- ${TF_ROOT}/**/*
- when: manual
.terragrunt:plan:dev:
extends:
- .terragrunt:plan
- .runners:dev
variables:
TF_TARGET_ENV: "dev"
.terragrunt:apply:dev:
extends:
- .terragrunt:apply
- .runners:dev
variables:
TF_TARGET_ENV: "dev"
В gitlab-ci-terragrunt.yml описаны шаги подключения к облаку и работы с ним. В нашем случае это Yandex Cloud, но может быть и любое другое. В качестве хранилища секретов используется Hashicorp Vault.
gitlab-ci-terragrunt.yml
variables:
TF_PLAN_CACHE: plan.cache
.terragrunt:common:
image:
name: my_name
resource_group: ${TF_ROOT}
id_tokens:
VAULT_ID_TOKEN:
aud: ${VAULT_ADDR}
variables:
VAULT_AUTH_PATH: "id_jwt"
YC_KEY: /tmp/yc_key.json
before_script:
- export VAULT_TOKEN="$(vault write -field=token auth/${VAULT_AUTH_PATH}/login role=${VAULT_AUTH_ROLE} jwt=${VAULT_ID_TOKEN})"
- vault kv get -field=${TF_TARGET_ENV} infra/${TF_SECRET_PATH}/terraform > ${YC_KEY}
- yc config profile create my-robot-profile
- yc config set service-account-key ${YC_KEY}
- export YC_TOKEN=$(yc iam create-token)
- git config --global url."https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.com/".insteadOf ssh://git@gitlab.com/
- export TF_HTTP_PASSWORD=${CI_JOB_TOKEN}
- cd ${TF_ROOT}
.terragrunt:validate:
extends:
- .terragrunt:common
stage: validate
script:
- terragrunt validate
.terragrunt:plan:
variables:
TF_PLAN_JSON: plan.json
JQ_PLAN: |
(
[.resource_changes[]?.change.actions?] | flatten
) | {
"create":(map(select(.=="create")) | length),
"update":(map(select(.=="update")) | length),
"delete":(map(select(.=="delete")) | length)
}
extends:
- .terragrunt:common
stage: build
script:
- terragrunt plan -input=false -out="$(pwd)/${TF_PLAN_CACHE}"
- terragrunt show -json "$(pwd)/${TF_PLAN_CACHE}" |
jq -r "${JQ_PLAN}" > "${TF_PLAN_JSON}"
artifacts:
expire_in: 1 week
paths:
- ${TF_ROOT}/${TF_PLAN_CACHE}
reports:
terraform: ${TF_ROOT}/${TF_PLAN_JSON}
.terragrunt:apply:
extends:
- .terragrunt:common
stage: deploy
script:
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add -
- terragrunt apply -input=false "$(pwd)/${TF_PLAN_CACHE}"
when: manualВернёмся к нашему бакету для my-service. После создания merge request из всех описанных ранее файлов будут объединены следующие шаги.
.rules:mr:dev:
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
changes:
- terragrunt.hcl
- provider.tmpl
- dev/env.hcl
- ${TF_ROOT}/*
- ${TF_ROOT}/**/*
.terragrunt:plan:dev:
extends:
- .terragrunt:plan
- .runners:dev
variables:
TF_TARGET_ENV: "dev"
.runners:dev:
tags:
- devops
- dev
- .terragrunt:plan - настройка terragrunt с Yandex CloudТаким образом, этот шаг будет запускаться только на те ресурсы, в которых произошло изменение, то есть на созданный terragrunt файл s3 бакета сервиса my-service. Далее на раннеры ставятся нужные теги, а terragrunt настраивается на использование нужного нам dev окружения в облаке.
Далее, когда всё это прошло успешно, merge request вливается в main ветку. В этот момент запускается скрипт generate-default-jobs.sh
generate-default-jobs.sh
#!/bin/sh
# directory is in the first argument
directory=$1
# Environment is in the second argument
env=$2
# Prefix is the directory name with slashes replaced by dashes
parent_prefix=$(echo "$directory" | tr / -)
cat >.gitlab-ci-${parent_prefix}.yml <>.gitlab-ci-${parent_prefix}.yml <>.gitlab-ci-${parent_prefix}.yml < Суть этого скрипта, что он генерирует gitlab-ci файл аналогично предыдущему, с той разницей, что появится шаг развёртывания файлов terraform apply. Результат выглядит следующим образом:

Первые шаги пайплайна

Шаг деплоя S3-бакетов
Таким образом, мы создали механизм автоматической генерации пайплайнов, который значительно упрощает работу инженера. При его использовании достаточно писать вручную исключительно terragrunt-файлы, а пайплайны в репозитории будут появляться и запускаться автоматически.
