Что делать, если поймал HardFault?
Что делать, если поймал HardFault? Как понять, каким событием он был вызван? Как определить строчку кода, которая привела к этому? Давайте разбираться.
Всем привет! Сложно найти программиста микроконтроллеров, который ни разу не сталкивался с тяжелым отказом. Очень часто он никак не обрабатывается, а просто остаётся висеть в бесконечном цикле обработчика, предусмотренном в startup файле производителя. В то же время программист пытается интуитивно найти причину отказа. На мой взгляд это не самый оптимальный путь решения проблемы.
В данной статье я хочу описать методику анализа тяжелых отказов популярных микроконтроллеров с ядром Cortex M3/M4. Хотя, пожалуй, «методика» — слишком громкое слово. Скорее, я просто разберу на примере то, как я анализирую возникновение тяжелых отказов, и покажу, что можно сделать в подобной ситуации. Я буду использовать программное обеспечение от IAR и отладочную плату STM32F4DISCOVERY, так как эти инструменты есть у многих начинающих программистов. Однако это совершенно не принципиально, данный пример можно адаптировать под любой процессор семейства и любую среду разработки.

Падение в HardFault
Перед тем, как пытаться анализировать HatdFault, нужно в него попасть. Есть много способов это сделать. Мне сразу же пришло на ум попытаться переключить процессор из состояния Thumb в состояние ARM, путем задания адреса инструкции безусловного перехода четным числом.
Небольшое отступление. Как известно, микроконтроллеры семейства Cortex M3/M4 используют набор ассемблерных инструкций Thumb-2 и всегда работают в режиме Thumb. Режим ARM не поддерживается. Если попытаться задать значение адреса безусловного перехода (BX reg) со сброшенным младшим битом, то произойдет исключение UsageFault, так как процессор будет пытаться переключить своё состояние в ARM. Подробнее об этом можно почитать в [1](пункты 2.8 THE INSTRUCTION SET; 4.3.4 Assembler Language: Call and Unconditional Branch).
Для начала, я предлагаю смоделировать безусловный переход по четному адресу на языке C/C++. Для этого я создам функцию func_hard_fault, затем попытаюсь вызвать ее по указателю, предварительно уменьшив адрес указателя на единицу. Сделать это можно следующим образом:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //Объявляем указатель на функцию отказа
ptr_hard_fault_func = reinterpret_cast(reinterpret_cast(func_hard_fault) - 1); //Присваиваем ему значение со сброшенным младшим битом
ptr_hard_fault_func(); //Вызов функции отказа
while(1) continue;
}
void func_hard_fault(void) //Функция, вызов которой приведет к отказу
{
while(1) continue;
}
Посмотрим с отладчиком, что же у меня получилось.

Красным я выделил текущую инструкцию перехода по адресу в РОН R1, который содержит чётный адрес перехода. Как результат:

Еще проще данную операцию можно выполнить с помощью ассемблерных вставок:
void main(void)
{
//Переходим на свой же адрес
asm("LDR R1, =0x0800029A"); //Псевдо-инструкция для записи значения переходf
asm("BX r1"); //Переход по адресу R1
while(1) continue;
}
Ура, мы попали в HardFault, миссия выполнена!
Анализ HardFault
Откуда мы попали в HardFault?
На мой взгляд, самое важное — узнать то, откуда мы попали в HardFault. Сделать это не сложно. Для начала напишем свой обработчик ситуации HardFault.
extern "C"
{
void HardFault_Handler(void)
{
}
}Теперь поговорим о том, как выяснить, как мы здесь оказались. В процессорном ядре Cortex M3/M4 есть такая замечательная вещь, как сохранение контекста [1](пункт 9.1.1 Stacking). Если говорить простым языком, при возникновении любого исключения, содержимое регистров R0-R3, R12, LR, PC, PSR сохраняется в стеке.

Здесь для нас самым важным будет регистр PC, который содержит информацию о текущей выполняемой инструкции. Так как значение регистра было сохранено в стек во время возникновения исключительной ситуации, то там будет содержаться адрес последней выполняемой инструкции. Остальные регистры менее важны для анализа, но нечто полезное можно выцепить и из них. LR — адрес возврата последнего перехода, R0-R3, R12 — значения, которые могут подсказать в каком направлении двигаться, PSR — просто общий регистр состояния программы.
Предлагаю выяснить значения регистров в обработчике. Для этого был написал такой код (подобный код я встречал в одном из файлов производителя):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; //Указатель на текущее значение стека(SP)
asm(
"TST lr, #4 \n" //Тестируем 3ий бит указателя стека(побитовое И)
"ITE EQ \n" //Значение указателя стека имеет бит 3?
"MRSEQ %[ptr], MSP \n" //Да, сохраняем основной указатель стека
"MRSNE %[ptr], PSP \n" //Нет, сохраняем указатель стека процесса
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
Как результат, имеем значения всех сохраняемых регистров:
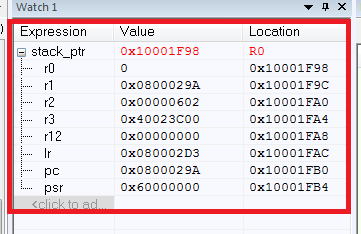
Что же здесь произошло? Сначала мы завели указатель стека stack_ptr, тут все понятно. Сложности возникают с ассемблерной вставкой (если есть потребность в понимании ассемблерных инструкций для Cortex, то рекомендую [2]).
Почему мы просто не сохранили стек через MRS stack_ptr, MSP? Дело в том, что ядра Cortex M3/M4 имеют два указателя стека [1](пункт 3.1.3 Stack Pointer R13) — основной указатель стека MSP и указатель стека процесса PSP. Они используются для разных режимов работы процессора. Не буду подробно углубляться в то, для чего это сделано и как это работает, однако дам небольшое пояснение.
Для выяснения режима работы процессора (используется в данный MSP или PSP), нужно проверить третий бит регистра связи. Этот бит определяет то, какой указатель стека используется для возвращения из исключения. Если этот бит установлен, то это MSP, если нет, то PSP. В целом, большинство приложений, написанных на C/C++ используют только MSP, и эту проверку можно и не делать.
Так что же по итогу? Имея список сохраняемых регистров, мы можем без труда определить то, откуда программа упала в HardFault по регистру PC. PC указывает на адрес 0×0800029A, который и является адресом нашей «ломающей» инструкции. Не стоит также забывать о важности значений остальных регистров.
Причина возникновения HardFault
На самом деле, мы можем также выяснить причину возникновения HardFault. В этом нам помогут два регистра. Hard fault status register (HFSR) и Configurable fault status register (CFSR; UFSR+BFSR+MMFSR). Регистр CFSR состоит из трёх регистров: Usage fault status register (UFSR), Bus fault status register (BFSR), Memory management fault address register (MMFSR). Почитать про них можно, например, в [1] и [3].
Предлагаю посмотреть, что эти регистры выдают в моём случае:

Во-первых, установлен бит HFSR FORCED. Значит произошёл отказ, который не может быть обработан. Для дальнейшей диагностики следует изучить остальные регистры статуса отказов.
Во-вторых, выставлен бит CFSR INVSTATE. Это значит, что произошёл UsageFault, так как процессор попытался выполнить инструкцию, которая незаконно использует EPSR.
Что такое EPSR? EPSR — Execution program status register. Это внутренний регистр PSR — специального регистра состояния программы (который, как мы помним, сохраняется в стеке). Двадцать четвертый бит этого регистра указывает на текущее состояние процессора (Thumb или ARM). Это как раз может определять нашу причину возникновения отказа. Давайте попробуем его считать:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
В результате выполнения получаем значение EPSR = 0.

Получается, что регистр показывает состояние ARM и мы нашли причину возникновения отказа? На самом деле нет. Ведь согласно [3](стр. 23), считывание этого регистра с помощью специальной команды MSR всегда возвращает нуль. Мне не очень понятно почему это работает именно так, ведь этот регистр и так только для чтения, а тут его полностью и считать нельзя (можно только некоторые биты через xPSR). Возможно это некие ограничения архитектуры.
По итогу, к сожалению, вся эта информация практически ничего не дает рядовому программисту МК. Именно поэтому я рассматриваю все данные регистры только как дополнение к анализу сохраненного контекста.
Однако, например, если отказ был вызван делением на нуль (данный отказ разрешается установкой бита DIV_0_TRP регистра CCR), то в регистре CFSR будет выставлен бит DIVBYZERO, что укажет нам на причину возникновения этого самого отказа.
Что дальше?
Что же можно сделать после того, как мы проанализировали причину возникновения отказа? Мне кажется хорошим вариантом такой порядок действий:
1) Вывести в отладочную консоль (printf) значения всех анализируемых регистров. Это можно сделать только при наличии отладчика JTAG.
2) Сохранить информацию об отказе во внутреннюю или внешнюю (если имеется) flash. Также можно вывести значение регистра PC на экран устройства (если имеется).
3) Перезагрузить процессор NVIC_SystemReset ().

Источники
1) Joseph Yiu. The definitive guide to the ARM Cortex-M3.
2) Cortex-M3 Devices Generic User Guide.
3) STM32 Cortex-M4 MCUs and MPUs programming manual.
