ClickHouse: Путь джедая искавшего дом для своих данных
 * Юристы попросили нас написать, что картинка шуточная, и мы уважаем всех гордых любителей разных систем хранения данных.
* Юристы попросили нас написать, что картинка шуточная, и мы уважаем всех гордых любителей разных систем хранения данных.
В разные эпохи развития нашего проекта в качестве основного хранилища которое было как источник данных для аналитики у нас были хранилища MySQL, ElasitcSearch, Exasol и ClickHouse. Последний нам очень нравится и вообще вызывает дикий восторг как инструмент для работы с большими массивами данных, но если посчитать итоговую стоимость владения с учётом внедрения кластера, обучения и поддержки — лучше подумайте два раза, прежде чем тащить его в ваше стек. На наших объёмах данных вложенные усилия окупаются, но если бы мы были чуть меньше, то, наверное, экономика не сошлась бы.
Главная проблема ClickHouse — это практическое отсутствие удобных и стабильно работающих инструментов для эксплуатации и большое кол-во решение рядом в погоне добиться того же пользовательского опыта как при работе с классическим RDBMS (MySQL или PostgreSQL). Вам придется приложить не мало усилий чтобы понять как эффективно применить clickhouse для ваших задач анализировать придется много: начиная от вопросов развертывания до выбора оптимальных моделей данных под профиль вашей нагрузки, в общем доступе не так много рекомендаций по выбору конфигураций под разные типы задач.
С другой стороны, его киллер-фича — это возможность работать с огромными массивами данных невероятно быстро для решений в этой области, то что раньше нам приходилось делать в Spark или через другие реализации map reduce, теперь мы можем делать внутри clickhouse. И бесплатно, потому что такими же плюсами обладают многие MPP решения вроде Vertica или Exasol. Но ClickHouse открытый, и за это мы платим налог на использование не прогнозируемым объемом поддержки или развития системы. Не всем это подходит: например, есть опыт компаний, которые сначала было влезли в это дело, потом поняли, что это не то — и взяли платные продукты с платной поддержкой с экспертизой в решении архитектурных задач именно их продуктами. В платных продуктах есть готовые инструменты, которые понятно, как применять.
В общем, давайте расскажу про наш опыт.
Что такое ClickHouse и чем он стал для нас
Это решение созданное под задачи хранения данных проекта Яндекс.Метрики, которая была заточена под сохранение данных о действиях пользователей и последующей аналитикой в интерфейсе и построения отчетов. Вот подробный пост. Он потенциально очень хорошо масштабируется (о топологии нашего кластера, мы расскажем в отдельной статье), очень быстро работает и хранит сырые данные с простым доступом через SQL — что очень удобно для аналитики. У clickhouse нет эффективного подхода обновления данных, атомарных операций и транзакций, но для обновления есть возможность все же реализовать обновление через построение особой модели данных и движки таблиц Replacing*.
Документация по clickhouse есть, но написана она часто излишне детализировано, а часто в духе «осталось нарисовать остальную сову», примеры нарисованных «сов» можно найти на некоторых конференциях в решении узких задач. Главная проблема для нас была в том, что то же масштабирование в кластере можно сделать несколькими разными способами, но на практике только один из 3 будет рабочим. И вы не узнаете, какой, пока не попробуете все, во всяком случае такой путь был у нас. В том же Exasol в такой же ситуации метод будет только один одобренный вендором, и по-другому сделать просто не выйдет. Зато он точено будет прост, понятен и будет гарантированно работать.
Отсутствие инструментов к нему обходится дорого, но посчитать насколько — сложно. Если бы мы могли сформулировать заранее требования к хранению данных и их использованию точно — то наверняка взяли бы Vertica или продолжили бы использовать Exasol. Но проблема в том, что развивающиеся продукты часто не знают, что именно им понадобиться на горизонте 1–3 лет, поэтому приходится хранить всё. Плюс есть неопределённость в продукте, а при развитии новых фич часто нужны исторические данные. В случае платных решений нужные объёмы хранения были банально дороги.
Коммерческие стоят от 2 тысяч долларов в месяц. Два года назад у нас было 7,5 Тб, и мы понимали, что к 2021 году, если не случится, ну, знаете, чего-нибудь особенного для индустрии путешествий, будет 20 Тб. При этом мы не могли посчитать профит от хранения 1 Тб данных, потому что платить надо сразу, а пригодиться данные могут через полгода. Каждый раз, когда мы начинаем что-то складывать в хранилище, это делается по экспертной оценке от владельца продукта: «Кажется, у этих данных есть потенциал для бизнеса».
Так же нам хотелось создать инфраструктуру и дать такой инструмент для аналитиков чтобы они использовали минимальное кол-во источников и имели инструмент с маленьким порогом входа, это накладывало дополнительные ограничения на возможные сложные инструменты которые могли бы быть применены.
В итоге мы попробовали ClickHouse. Если бы была экспертиза в PostgreSQL, взяли бы GreenPlum. Vertica мы тоже не умели и не понимали. В итоге попробовали домик, и он очень понравился аналитикам SQL-интерфейсом, скоростью работы и богатым набором функций необходимых для их повседневной работы. Напомню, в elasticsearch, который мы использовали для хранения части наших данных — SQL нет и это сильно осложняло пользовательский опыт аналитиков, не говорят о эффективности использования ресурсов.
Как пришли к elasticsearch в 2016 году и что за задача вообще была
Тогда нам надо было сделать систему, которая позволила бы собирать данные о действиях пользователей со всех наших проектов. Причём с вечным хранением данных. Это нужно, чтобы сравнивать метрики, которые были в прошлых годах в аналогичном месяце, потому как в туристической сфере очень значительно отражается сезонность. Мы хотели проводить детальный анализ результатов АБ-тестов по сырым данным с точностью до каждого пользователя. Решения для классической web-аналитики Я.Метрика и Google Analytics бесплатные и имеют низкий порог входа. Но они довольно ограниченные и не позволяют гибко работать с сырыми данным, для нас блокирующим фактором стали ограничения на получения сырых данных и потери данных в ~10% по нашим исследованиям. Эти потери выглядели при аналитике как потеря некоторых событий в цепочке действий пользователей. На этих инструментах также нельзя строить что-то серьёзное в привязке к деньгам и не сливать финансовые данные. Мы замечали, что данные в этих системах иногда по-разному доходят до хранилищ, в результате чего и та, и другая система врут относительно реальных данных по тем же заказам, причём в разные стороны. Возможно, там есть какая-то логика, из-за которой мы не можем получить все данные.
Есть простые решения, например, писать данные в логи, хранить какие-то агрегаты, полученные из логов в реляционных базах данных. И есть самое гибкое решение — построить свою дата-платформу. У этого решения нету всех недостатков предыдущих, но при этом есть дороговизна внедрения и необходимость поднятия под это инфраструктуры. Ну и нужен штат дата-инженеров. А ещё такая дата-платформа требует простоты работы с данными. В наших имеющихся системах, когда аналитики работали над продуктовой задачей, они тратили больше времени на подготовку данных, нежели на сам анализ. Ещё не хватало контроля качества и документации данных, которые мы собираем в нашу систему и какого-то контроля потерь. Мы как минимум хотели бы сообщать аналитикам, насколько можно верить собранным данным. Плюс в требованиях было хранить целые сессии пользователей, а не какие-то агрегаты.
Мы начали собирать информацию, учится, ходить на конференции, там общаться с людьми, кто строил уже подобные платформы. Мы не понимали какой стек нам вообще нужен для решения конкретно этой задачи. Были истории успеха у netflix, у linkedin и других новаторов в этой области, которые строили крутые дата платформы, но непонятно было, пойдут ли нам эти решения. Если б мы просто начали бы тестировать, подходит ли нам конкретно вот этот стек для решения наших задач, то мы могли бы уйти в исследование достаточно на долгое время. В 2016 году вообще было мало практик по созданию подобных систем и мало компетентных специалистов готовы построить систему с нуля.
К тому моменту наше хранилище для аналитиков состояло только из нескольких огромных реплик на MariaDb куда стекались данные из всех 100+ серверов и наш опыт и опыт большинства компаний говорил о том что это не то решение которое будет готово переварить хранение всех кликов пользователей.
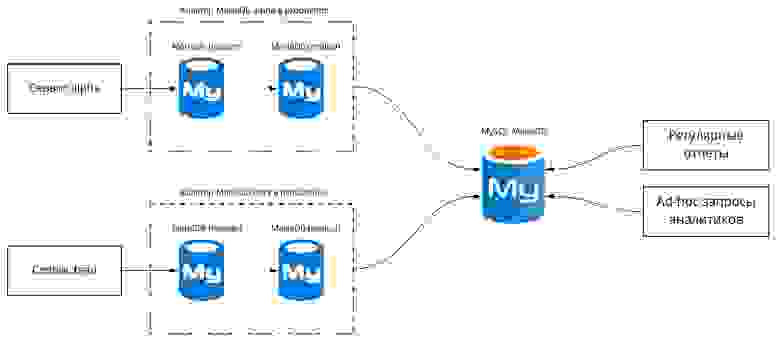
Поскольку основное в архитектуре с нашей точки зрения было хранилище, начали мы именно с него. У нас уже на тот момент были реляционные базы, такие как MySQL, на которых было сложно получить реалтайм и правильно сегментировать данные — получалось, что они часто нужны нам в сыром виде. Clickhouse тогда еще был недоступен публично, поэтому мы выбирали из Greenplum и ElasticSearch. В итоге мы пришли к решению, что мы будем внедрять ElasticSearch, потому что ElasticSearch решал несколько задач в нашей компании например такие как хранение логов приложений для задач эксплуатации инфраструктуры запуска наших приложений.
ElasticSearch — это документо-ориентированное хранилище с near-real-time доступом к данным. Данные в ElasticSearch не сразу становятся доступными для поиска. Чем меньше этот лаг, тем выше нагрузка на хранилище. Мы могли смириться с лагом в несколько минуту, что снимало эту проблему. Ещё это распределенное решение для полнотекстового поиска, который имеет гибкие возможности масштабирования и достаточно богатые возможности для построения агрегации по данным. ElasticSearch позволяет гибко нарезать данные временных рядов, ну и организовывать работу с ними уже встроенными возможностями, без каких-то дополнительных действий. У них большая экосистема. Есть в стеке kibana, которая позволяет, доступаться к нашим данным, строить визуализации и дашборды. Всё бесплатной версии лицензии.
Но у этого хранилища были минусы которые не были значительными на том этапе нашего развития:
Отсутствие SQL подобного языка запросов;
Нет join«ов в классическом понимании, но есть альтернатива;
Нет контроля консистентности и транзакций;
Еще один источник данных для аналитиков который придется осваивать.
Не смотря на все ограничения хранилище успешно решало бизнес-задачи и имело вот такую структуру:

Год назад в хранилище было 12 Тб данных, и это без сессий ботов. 12 миллиардов документов. В среднем писалось по 20 тысяч записей в минуту. Бывали пики до 40 тысяч. 9 нод elasticsearch.
Работало с базой 5 продуктовых команд, 11 аналитиков и 2 дата инженера на поддержке и развитии текущей системы.
«Вы распиливаете монолит, а мы собираем его обратно»
Мы росли, наша архитектура проекта развивалась, новые проекты делались на микросервисной архитектуре, старые монолиты постепенно разделялись на мелкие проекты, начало появляться множество серверов баз данных для изоляции между группами сервисов c которыми работал production код. Итак, мы выросли из старой архитектуры из-за:
потребностей в удобстве доступа к данным;
скорости работы с данными;
необходимости подключать удобные BI инструменты;
сложности поддерживания старой системы реплик и нескольких хранилищ;
поменялись требования по порогу входа аналитиков, их функциям и ожиданиям по скорости проверки гипотез в единицу времени.
В качестве альтернативы clickhouse мы рассматривали ещё некоторые системы аналитики которые поставляются как SaaS (в сравнении с ними собственное внедрение open source окупалось за считанные недели, как нам казалось, посчитав потом могу сказать — месяцы), были BigQuery, RedShift, и решения в AWS. Но у нас не было экспертизы, как готовить такое, чтобы было экономически сообразно. Из того, что мы посчитали, всё было дороже и менее предсказуемым чем MVP на базе clickhouse. Плюс почти во всех облачных решениях нужно аналитиков контролировать и выстраивать процесс, чтобы они не сделали запрос, который обойдётся дорого, потому что оплата шла по факту за чтение/кол-во запросов и сложность этих запросов. Например, пропустил join по всей базе — и упс, прилетает счёт на пару тысяч долларов. В clickhouse порог входа в аналитики куда проще: если они вдруг уложат хранилище, оно быстро упадёт и быстро поднимется. Но, скорее, пережуёт запрос. Переделывать принципы работы аналитиков мы не хотели, поэтому решили сразу, что плата за сложность запроса — плохая идея которая бы потребовала бы внедрение новых процессов и обучение.
В clickhouse хранение данных очень эффективное, то, что у нас занимало около 15 Тб в elasticsearch, заняло в итоге 4 Тб в clickhouse. В основном мы храним действия в сессии пользователя и состав выдач железнодорожных и авиабилетов ему. Есть и заказы, и билинг, и документы и всё остальное, но в сравнении с этими категориями это просто капля в море по объёму. Сейчас мы на пути сбора данных со всех сервисов компании (монолит и около 1000 микросервисов) и собираем их в один data lake на базе clickhouse. Такую задачу также можно решить поднятием кластера Spark или Hadoop, делающего распределённые join, но решения по сложности сопровождения и сложности архитектур сильно проигрывают clickhouse.
На текущий момент удалось созданием внутренней базы знаний понизить порог входа в clickhouse для разработчиков в командах которые не имеют экспертов в хранилищах для использования clickhouse как миниму для доставки данных от production кода до data lake на базе clickhouse с минимальным оказанием консалтинга экспертов в clickhouse для разработчиков, что позволило не делать «узким горлышком» одну команду и перенести зону ответсвенности на команды которые являются источниками данных, с более сложными системами вроде Hadoop это сделать было бы сложнее.
В итоге схема к которой мы пришли ниже, где clickhouse играет важную роль:
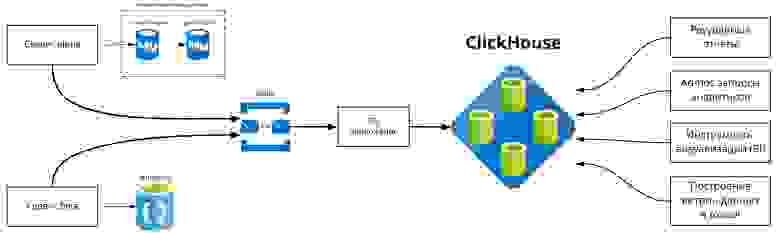
За пару лет эксплуатации clickhouse мы натыкались на ломающиеся достаточно важные части функционала, например такие как clickhouse-copier (инструмент для миграции данных между кластерами), мы не доверяем новым удобным фичам вроде чтения из kafka или из других источников потому как в случае проблем исследовать проблемы и делать drill down практически не возможно и достаточно регулярно в них встречались баги или недокументированные особенности которые приводили к потерям данных в краевых случаях, по этому мы используем clickhouse как решение для хранения и доступа к данным, а инструменты доставки используем во вне.
Мы считаем что пока в начале пути и ещё много надо сделать. В планах:
На текущий момент витрины данных для быстрого доступа у нас хранятся в Exasol, но мы хотим рассмотреть для этой задачи clickhouse на основе materialized view и встроить в наш процесс создания витрин;
Повысить скорость работы с данными которые требуют меньших задержек чем получаем сейчас, хотим сократить скорость ответа для частых сложных запросов с десятков минут до 2–3 минут;
Научиться быстро локализовывать возникающие проблемы производительности новых запросов и ловить не оптимальные запросы на ранних этапах;
Интеграция со всеми сервисами данные которых необходимы для какой либо аналитики внутри компании;
Полностью заменить этим хранилищем те функции которые которые выполняла большая реплика MariaDb которую упоминали ранее;
Наладить регулярное обновление до свежих версий clickhouse, потому как часто появляются новые полезные для аналитиков фичи и ломаются старые;
Начать декомпозицию потоков данных по доменным областям и двигаться в сторону data mesh.
Про инструменты доставки данных, особенности интеграции с шиной данных и как пришли к текущей архитектуре в которой clickhouse решает только одну задачу и о том какая конфигурация нашего кластера clickhouse мы расскажем в следующих статьях.
