ClickHouse: очень быстро и очень удобно

Виктор Тарнавский показывает, что оно работает. Перед вами расшифровка доклада Highload++ 2016.
Здравствуйте. Меня зовут Виктор Тарнавский. Я работаю в «Яндексе». Расскажу про очень быструю, очень отказоустойчивую и супермасштабируемую базу данных ClickHouse для аналитических задач, которую мы разработали.
Пару слов обо мне. Меня зовут Виктор, я работаю в «Яндексе» и руковожу отделом, который занимается разработкой аналитических продуктов, таких как «Яндекс.Метрика» и «Яндекс.AppMetrica». Я думаю, многие из вас пользовались этими продуктами и знают их. Ну и в прошлом и по-прежнему пишу много кода, а раньше еще занимался разработкой железа.
Что сегодня вообще будет
Я расскажу немного истории: почему мы решили создать свою систему, как дошли до жизни такой, что в современном мире, в котором, казалось бы, существует решение для любой задачи, нам все равно понадобилось создать свою базу данных. Потом расскажу о том, какие фичи сейчас есть в ClickHouse, из чего он состоит, и какие в нём есть возможности, которые можно использовать. Потом хочется погрузиться немного вглубь и рассказать вам, какие решения мы принимали внутри ClickHouse, и из чего он состоит, и почему ClickHouse работает наcтолько быстро. И в конце хочу показать, как ClickHouse может помочь именно вам лично или компании, в которой вы работаете, для каких задач стоит его применять, какие кейсы можно построить вокруг ClickHouse.
Немного истории
Все начиналось в 2009 году. Тогда мы делали «Яндекс.Метрику» — веб-аналитический инструмент. То есть такой инструмент, который владельцы или разработчики сайтов ставят себе на сайт. Это кусочек JavaScript, он отсылает данные в «Яндекс.Метрику». Потом в «Метрике» можно видеть статистику: сколько на сайте было людей, что они делали, купили ли они холодильник и всякое такое.
И с точки зрения разработки веб-аналитической системы — это некоторый challenge. Когда вы разрабатываете один сервис или какой-то продукт, вы проектируете нагрузку так, чтобы выдерживать какие-то RPS и прочие параметры этого одного сервиса или продукта. А когда вы разрабатываете веб-аналитический инструмент, вам нужно выдерживать нагрузку всех сайтов, на которых стоит ваш веб-аналитический инструмент. И в случае «Метрики» — это очень большие масштабы: десятки миллиардов событий, которые мы принимаем каждый день.
«Метрика» стоит на миллионах веб-сайтов. Сотни тысяч аналитиков каждый день сидят и смотрят в интерфейс «Метрики», запрашивают какие-то отчёты, выбирают фильтры и пытаются понять, что происходит у них на сайте, купил ли этот человек этот холодильник, или что происходит. По внешним данным «Метрика» — это система, которая входит в тройку самых крупных игроков на этом рынке. То есть количество сайтов, которые у нас, и количество людей, которых видит «Метрика», — это продукт из топа, продуктов большего масштаба практически нет.
В 2009 году «Метрика» выглядела не так:
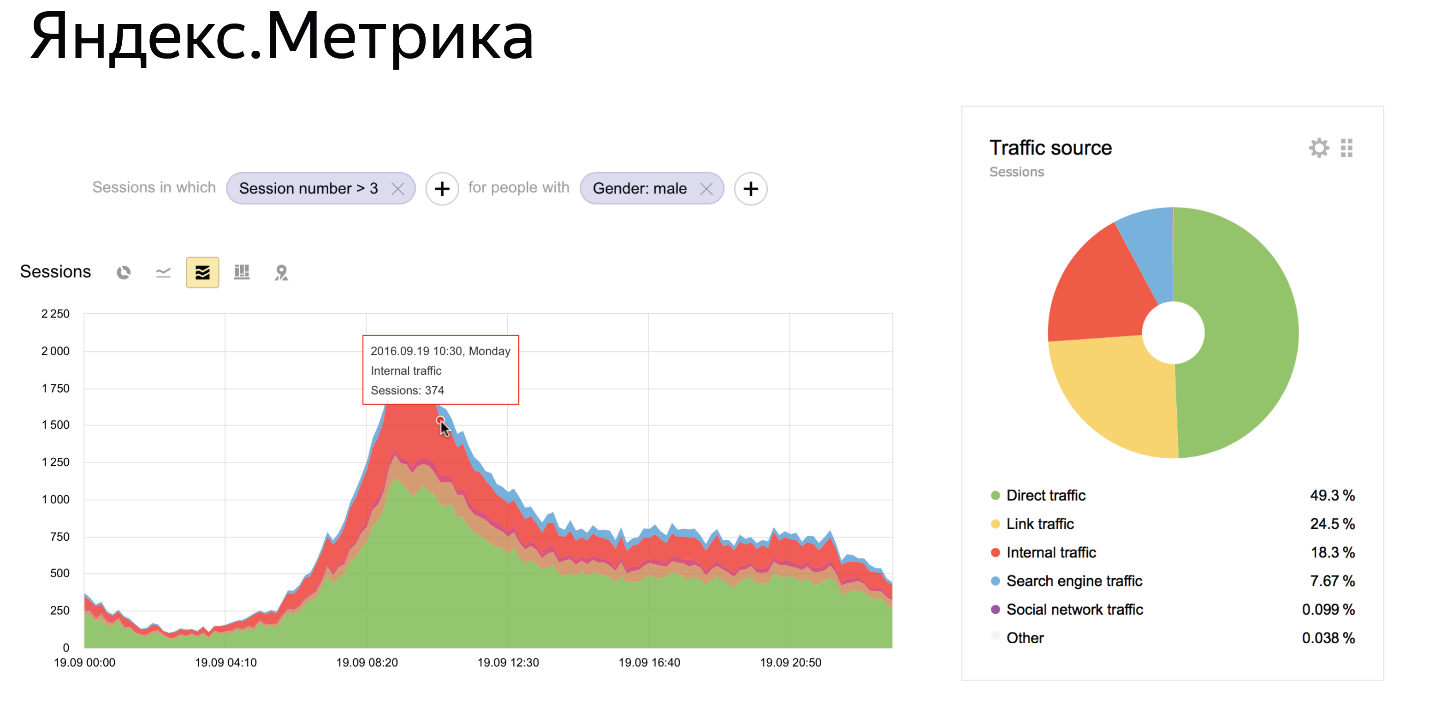
Это текущее её состояние. Видно, что в «Метрике» есть много чего. Есть Dashboards, на которых можно строить свои отчёты. Есть графики, которые позволяют что-то построить в режиме реального времени. Есть сложная система фильтров, с помощью которой можно посмотреть данные в любом срезе. Например, посмотреть данные только для девочек или только для людей, которые пришли с Зимбабве, — что-то такое.
Возникает вопрос — как нужно хранить данные, чтобы реализовать все эти возможности?
И в 2009 году мы жили, как мы это называем, в мире «классического» подхода агрегированных данных. Как это выглядит?
Допустим, вы хотите построить отчёт по полу. Как известно, полов в мире три: мужской, женский и «не определено», когда нам не удалось понять какой пол у человека. Вы берёте вашу любимую базу данных, делаете в ней колоночку с полом, делаете её enumerate какой-нибудь из трёх значений, делаете колоночку с датой, потому что нужно построить график, и делаете столбцы с метриками, которые вы считаете: количество людей, количество событий, например, заходов на сайт, количество купленных холодильников и так далее. Такую табличку, например, по Cron раз в день пересчитываете и записываете в MySQL новые строчки, и всё успешно работает.
В 2009 году мы жили в такой парадигме. Поэтому для каждого отчёта, который мы делали, мы создавали, по сути, новую такую таблицу. А в случае «Метрики» было больше 50 подобных разных таблиц с разным предагрегированным ключом. Наша система была существенно сложнее. Мы умели делать это в режиме реального времени. Мы умели выдерживать любые нагрузки, но тем не менее смысл оставался таким же.
Проблема этого подхода — в том, что вот такой интерфейс реализовать поверх этой структуры данных невозможно. Потому что если вы записали в вашу табличку, что мужской пол, дата такая-то, было куплено 4 холодильника, то вы не сможете уже эти данные отфильтровать, потому что там написана цифра 4 и неизвестно сколько из этих людей какого возраста, например. Поэтому со временем мы пришли к понятию неагрегированного подхода.
Это выглядит следующим образом. Мы сохраняем небольшое количество очень широких таблиц исходных событий. Например, в случае «Метрики» — это просмотры страниц. Одна строчка означает один просмотр страницы, у одного просмотра страницы очень много разных атрибутов: пол человека, возраст, куплен холодильник или нет, и еще какие-то колонки. В нашем случае в просмотрах мы записываем более 500 разных атрибутов для каждого просмотра.
Что такой подход позволяет делать? Он позволяет строить любые отчёты поверх такой модели данных. Данные можно как угодно фильтровать и группировать, потому что все параметры у вас есть, можно посчитать, что угодно. Получается небольшое количество таблиц, в случае «Метрики» их можно пересчитать на пальцах одной руки, но в них очень большое количество столбцов.
Проблема такого подхода
Нужна база данных, которая позволяет по такой широкой и длинной таблице — потому что очевидно, что она будет длиннее, чем агрегированные данные — быстро считать любые запросы.
Выбор СУБД
Это был основной вопрос, который у нас стоял в 2009 году. Тогда у нас уже были свои эксперименты. У нас была такая система, мы ее называли All Up. В неё уже были неагрегированные данные, и, если кто-то помнит старую «Метрику», в ней был конструктор отчетов, в котором можно было выбрать какие-то фильтры, измерения и построить произвольный отчёт. Он как раз был поверх этой системы All Up. Она была достаточно простой, у неё было много недостатков, она была недостаточно гибкой, недостаточно быстрой. Но она дала нам понимание того, что этот подход в принципе применим.
Мы начали выбирать базы, сформировали для себя какие-то требования. Мы поняли, что у нас примерно такой список требований.

Конечно, нам нужно максимально быстро выполнять запросы. Потому что наше основное продуктовое преимущество — максимально быстро выполнять запросы на больших объемах данных. Чем больше сайт, для которого мы можем быстро считать данные, тем лучше. Чтобы вы понимали паттерн: человек смотрит в интерфейс в «Метрике», меняет какие-то параметры, добавляет фильтры. Он хочет быстро получить результат, он не желает ждать до завтра или полчаса, пока ему это придёт. Нужно делать эти запросы за секунды.
Нужна обработка данных в реальном времени. Как на уровне вот этого запроса, когда человек сидит и хочет быстро увидеть результат, так и на уровне времени, которое проходит между покупкой холодильника на сайте и моментом, когда владелец сайта увидит, что человек купил этот холодильник. Это тоже очень важное преимущество, например, для новостных сайтов, которые выпускают какую-то новость и хотят быстро смотреть, насколько быстро она растёт. Нам нужна система, которая позволяет вставлять эти данные в реальном времени в базу и параллельно с этим забирать оттуда свежие результаты и агрегированные данные.
Нужна возможность хранить петабайты данных, потому что они у нас есть. «Метрика» очень большая — объём измеряется петабайтами. Далеко не каждая база может так масштабироваться. Для нас это очень важный параметр.
Отказоустойчивость в терминах датацентров. Ну что это означает?
Мы живем в России и много чего видели. Периодически приезжает трактор и выкапывает кабель, который ведёт к твоему датацентру, а потом совершенно неожиданно в тот же день приезжает экскаватор и выкапывает резервный кабель в твой другой датацентр, который находится через 100 километров. И ладно, если б я так шутил. Но оно и правда так было. Если, иногда, какая-нибудь кошка заползает в трансформатор, он взрывается. Иногда метеорит падает, рушит датацентр. В общем всякое происходит — датацентры выключаются.
В «Яндексе» мы проектируем все наши сервисы таким образом, чтобы они жили — не деградировали в своих продуктовых характеристиках, когда отключаются датацентры. Любой из датацентров может отключиться и сервисы должны выживать. На уровне базы данных для «Метрики» нам нужна такая база, которая может выживать при падании датацентра, что особенно это сложно с учетом предыдущих пунктов, про хранение петабайт данных и обработку в реальном времени.
Так же нужен гибкий язык запросов, потому что «Метрика» — сложный продукт и у нас много разных комбинаций, отчетов, фильтров и всего на свете. Если язык будет похож на какой-нибудь aggregation API MongoDB — если кто-то пытался пользоваться им, то вот такой нам не подходит. Нужен какой-то язык, которым удобно пользоваться, поэтому это было одним из ключевых критериев для нас.
Тогда было примерно как? На рынке не было ничего. Нам удалось найти базы, которые реализовывали, максимум, три из этих пяти параметров и то с какими-то там натяжками, а про пять даже речи не шло. У нас шло создание All Up системы и мы поняли, что мы, кажется, можем построить такую систему сами. Мы начали прототипировать. Начали создавать систему с нуля.
Основные идеи, которые мы преследовали, когда создавали новую систему и это изначально было понятно — что это должен быть SQL. Потому что его гибкости хватает для наших задач.
Понятно, что SQL это расширяемый язык, потому что в него можно свои какие-то функции добавлять, даже какие-то сверхнавороты делать. Это язык с низким порогом входа. Все аналитики и большая часть разработчиков с этим языком знакомы.
Линейная масштабируемость. Что означает «линейная»? Линейная означает, что если у вас есть какой-то кластер и вы в него добавляете сервера, то производительность должна расти, потому что количество серверов увеличилось. Но если взять какую-то более типичную систему, которая недостаточно хорошо масштабируется, то легко может выясниться, что вы добавляете сервера, а потом делаете запрос сразу на весь кластер и производительность не будет расти.
Вам повезёт, если она будет такой же, но в большинстве случаев она еще и падать будет со временем. Нам такое не подходит.
Изначально мы проектировали систему с фокусом на быстрое исполнение запросов, потому что, как я уже говорил, это наша основная фича. С точки зрения дизайна системы, с самого начала было понятно, что это должно быть Column-oriented — колоночное решение. Только поколоночное решение способно реализовать все, что нам нужно, закрывать все наши потребности.
И мы начали создавать, начали прототипировать. В 2009 году у нас был прототип, который делал какие-то простейшие вещи.
В 2012 году мы начали переводить части нашего продакшена на ClickHouse. Появились элементы продакшена, которые начали работать поверх ClickHouse.
В 2014 году мы поняли, что ClickHouse дорос до состояния, когда можно создавать продукт нового поколения. Metrica 2.0 поверх ClickHouse, а мы начали копировать данные.
Это очень нетривиальный процесс, если кто-то пытался скопировать два петабайта с одного места в другое, это не очень просто — на флешке это нельзя сделать.
В декабре 2014 года мы запустили новую «Метрику» поверх ClickHouse — это был прям прорыв, сегментация, куча фич, и все это работало поверх этой базы.
Несколько месяцев назад, в июне, мы выложили ClickHouse в Open Source. Мы поняли, что есть ниша и на рынке всё по-прежнему. У меня был сайт про «на рынке ничего», сейчас мы всё ещё близки к этой ситуации, мало что изменилось. На рынке не так много хороших решений для этой задачи. Мы поняли, что мы вовремя — мы можем сейчас выложить в Open Source и принести много пользы людям. Многие задачи сейчас очень плохо решаются, но их очень хорошо решает ClickHouse.
Оно как-то взрывом произошло. Конечно мы ожидали какой-то большой эффект от того, что мы выложили Open Source. Но то, что произошло превзошло все наши ожидания. У нас до этого было много проектов «Яндексе», которые реализованы были в ClickHouse, но прямо сейчас, когда мы выложили, о нас начали писать везде.
Где о нас только не писали: на HackerNews, на всех профильных изданиях. Нас стали спрашивать куча крупных компаний, куча компаний помельче, про новые решения. Кто-то уже пытался делать, а прямо сейчас статус такой, что ClickHouse использует, я могу сказать — более сотни разных компаний за пределами «Яндекса». Либо на стадии уже готовых каких-то прототипов, либо уже в продакшене. Есть компании, которые используют ClickHouse прямо в продакшене и строят куски своих сервисов поверх ClickHouse.
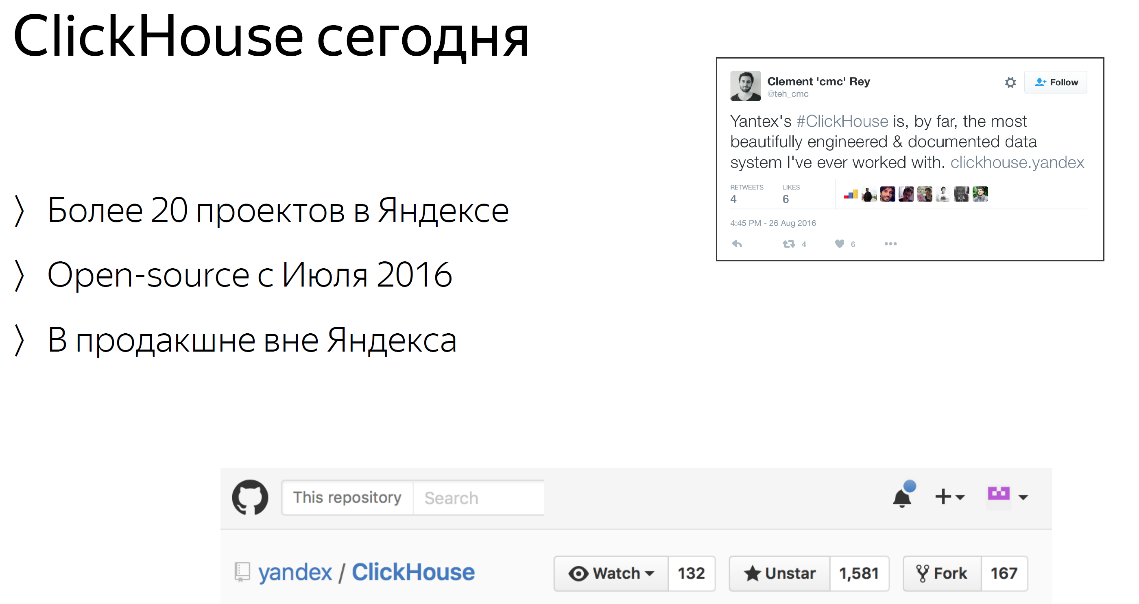
Мы получили 1500 звёздочек на GitHub —, но это устаревший слайд, сейчас их там 1800. Метрика так себе, но на всякий случай могу сказать для сравнения, что у Hadoop 2500 звёздочек. Понимаете, уровень. Мы скоро Hadoop обгоним, я думаю и тогда будет, о чем говорить.
Действительно сейчас очень много каких активностей происходит. Мы начинаем устраивать всякие митапы и будем их устраивать, так что приходите и спрашивайте.
Какие есть возможности
О чем я вообще говорю?
Линейная масштабируемость — это очень важное преимущество ClickHouse по сравнению с аналогичными решениями. Из коробки ClickHouse способен линейно масштабироваться и можно построить кластера очень большого размера и все будет хорошо работать. Например, потому что у нас оно очень хорошо работает. Петабайты данных — построить петабайтный кластер на ClickHouse не проблема. Из коробки работает cross-datacenter, для этого ничего не надо делать и он изначально задумывался как cross-datacenter решение. У нас в «Яндексе» в основном используются такие кластера.
High availability означает, что ваши данные и вообще кластер, и на чтение, и на запись всегда будет доступен. В этом смысле ClickHouse такой конструктор — можно построить кластер с любыми гарантиями, которые вам нужны. Если вы хотите выдерживать падение датацентра — вы ставите, в типичном случае, в трёх датацентрах кластер с фактором репликации х2. Если вы хотите построить решение — кластер, который выдерживает падение датацентра и одной ноды, обычно это означает, что нужно взять фактор репликации х3 и построить на базе как минимум трёх датацентров. Это достаточно гибкая система, можно любой гарантии построить, если знать как.
Сжатие данных. ClickHouse это поколоночная система, что само по себе означает, что сжатие данных работает очень хорошо. Потому что смысл поколоночного решения: данные из одной колонки хранятся, по сути, в одном файле на жестком диске и, если там примерно одинаковое написано, то сжимается это очень эффективно —, а если хранить это по строчкам, то там идёт все подряд и сжимается достаточно плохо.
В ClickHouse применено достаточно большое количество оптимизаций на эту тему, а потому сжимаются данные очень хорошо. Если сравнивать это с обычной базой данных, или с Hadoop, или еще с чем-то — разница от десятка до сотен раз, легко. Обычно у нас с этим проблема бывает: люди пробуют ClickHouse, загружают туда данные, смотрят сколько там места занимается и такие «кажется я не все загрузил», еще посмотрели — вроде все загрузилось. На самом деле очень эффективное сжатие — люди такого не ожидают.
На примере кластера «Яндекс.Метрики»: 
У нас есть несколько кластеров — это самый большой из них. У нас лежит 3 петабайта прямо сейчас, 3,4 что ли — слайд устаревший, на нем 412, а сейчас уже 420 серверов. Мы их увеличиваем потихоньку. Кластер размазан по шести датацентрам в разных странах. Несмотря на сложную конфигурацию, кластер имеет какие-то единицы часов даунтайма за все время существования. Это очень мало и невероятное количество девяток. Это все несмотря на то, что мы выкладываем каждый раз самую свежую версию ClickHouse, с самым большим количеством багов, видимо, однако это нам не помешало обеспечивать требуемые гарантии.
Это показывает, что данное решение способно работать 24/7 без всяких проблем. Да, «Метрика» работает 24/7, у нас нет никаких maintenance-периодов.
Запросы
Да, поддерживается SQL. SQL — это, по-сути, единственный способ спросить ClickHouse что-нибудь. Строго говоря, это диалект SQL, потому что есть некоторые отличия от стандарта, но в большинстве случаев, если вы делаете какой-то запрос на SQL, он скорей всего сработает нормально. Есть разнообразные дополнительные функции для приблизительных вычислений, когда можно пожертвовать точностью — зато запрос будет работать быстрее, или в память влезет. Есть множество разнообразных функций для различных типов данных, например, для URL — в «Яндекс.Метрике» очевидно много URL и там есть целый большой набор функций для работы с URL: можно вытащить домен, какие-то пути разложить, параметры. Для каждого типа данных есть большой набор функций. В «Метрике», наверное, есть самые разнообразные данные и скорее всего, примерно для всех типов данных, уже есть все возможности.
Из коробки поддерживаются массивы и кортежи. Это означает, что можно создать табличку, в которой в одной из колонок будет не колонка, а массив. Это может быть просто массив, например, много чисел, а может быть кортеж — массив со сложной структурой из нескольких полей. Поддержка массивов работает на уровне запросов — на уровне схемы базы, сверху донизу и есть много функций для работы с массивами, которые позволяют эффективно с ними работать. Можно, например, размножить остальные данные по этому массиву, а можно из массива извлечь любую информацию. Есть даже специальный лямбда-синтаксис, которым можно сделать map на массив или фильтр на массив, такие вещи.
Из коробки все запросы работают распределённо, не нужно ничего менять, нужно табличку другую указать, в которую будет распределено — будет работать на уровне всего кластера.
Так же есть такая фича, как внешние словари. Такая возможность, о которой хотелось бы немножко отдельно сказать. Когда мы её разработали, в «Метрике» это решило проблему ну, наверное, 80% join. Они просто перестали существовать. В чем смысл? Допустим, у вас есть основная табличка с данными, а в ней есть какие-то идентификаторы — предположим это идентификатор какого-то клиента. Есть отдельно справочник, который переводит этот идентификатор в имя клиента. Достаточно классическая ситуация. Как это выглядит на обычной SQL?
Вы делаете join — правильно, делаете join одного на другого и переводите ID в имя, если вы хотите в результате имя получить. В ClickHouse можно эту таблицу подключить, как внешний словарь, с помощью очень простого синтаксиса в конфиге — после этого на уровне запроса можно указать просто функцию, которая переведёт этот идентификатор в значение, ну или какие-то другие поля, которые у вас есть в этой удалённой таблице.
Что это означает? Это означает, что если вы делаете select из основной таблицы, например, множества идентификаторов, штук 5 — перевести эти идентификаторы в какую-то расшифровку вопрос одной функции. Если бы вы это делали через join, то у вас было бы 5–6 join, что выглядит ужасно. Кроме того, внешние словари можно подключить из любой базы, можно из MySQL, можно из файлика — из любой базы, которая поддерживает ODBC, например, из PostgreSQL. Это позволяет этим именам как-то обновляться, что сразу подхватится на уровне запроса. Невероятно удобная фича.
Пара примеров запросов: 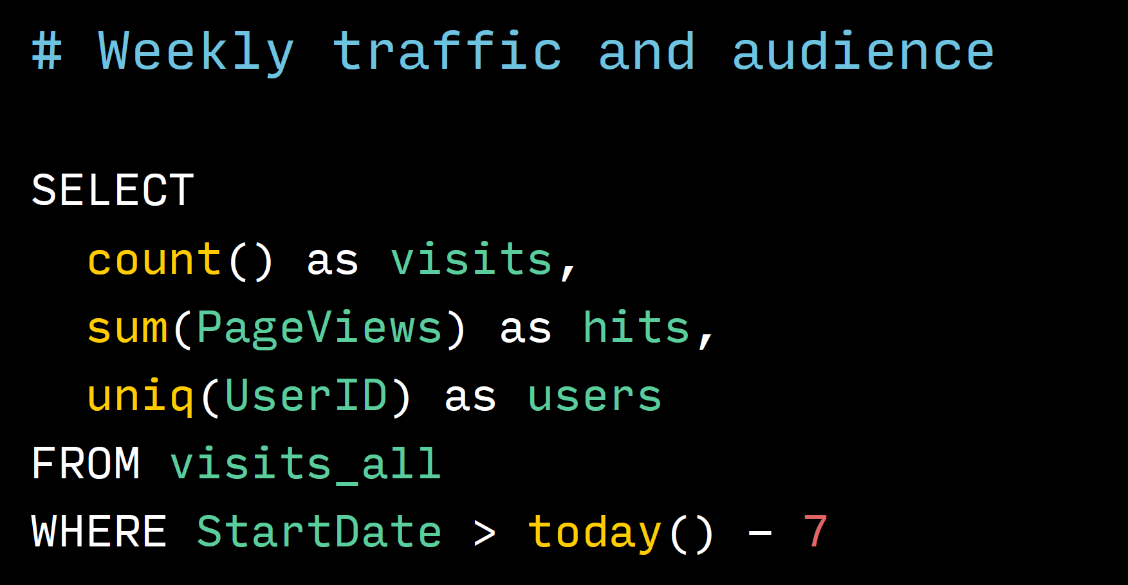
Это запрос, который забирает трафик и размер аудитории, то есть количество пользователей из кластера «Метрики» за неделю. Видно, что этот запрос достаточно простой, обычный SQL. Ничего особенного тут нет, вот только count написан без звездочки, со звездочкой если что тоже можно, но мы привыкли так писать.
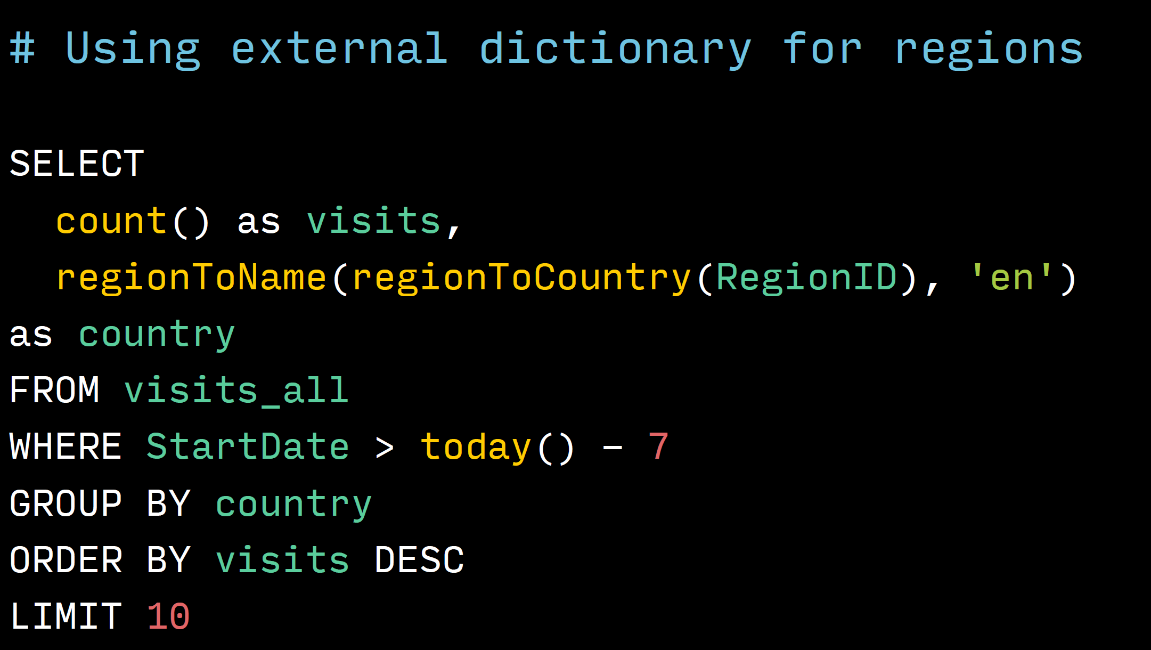
Это пример использования внешних словарей. Если посмотреть, где строчка regionToName в этой строчке — мы переводим RegionID — идентификатор региона, где был человек. Сначала в идентификатор страны, где он был. У нас есть справочник с региона на страну, и потом в название страны на английском языке. Как можно увидеть это вызов двух функций, очень понятно и очень просто выглядит. На классическом SQL это было бы два JOIN и запрос не влез бы в этот слайд, и пришлось бы его разбить слайда на три. Очень упрощает работу.
Скорость
Самая главная фича ClickHouse — это скорость. Скорость невероятная. Я думаю, что у всех есть какие-то ожидания по тому, как ClickHouse может работать. К нам приходят со своими ожиданиями — вот у вас есть какие-то ожидания. Скорее всего ClickHouse превосходит ваши ожидания — так это происходит со всеми людьми, которые к нам приходят.
Обычно типичные запросы работают быстрее, чем за секунду даже в масштабах кластера «Метрики», то есть петабайты меньше чем за секунду — несмотря на то, что данные у нас хранятся на обычных (не твердотельных) жёстких дисках.
Если сравнивать с обычными базами данных, то выигрыш в сотни тысяч раз по сравнению с Hadoop, MySQL, PostgreSQL. Оно будет давать результаты в сотни тысяч раз выше. Это реальность — у нас есть бенчмарки, я потом покажу.

Какие-то классные цифры, вплоть до 1 миллиарда строк в секунду — ClickHouse умеет обрабатывать на одной ноде, что достаточно много. В масштабах кластера «Метрики» 1 запрос может обрабатывать до 2 терабайт в секунду. Можете себе представить, что такое 2 терабайта — это такие жесткие диски, сейчас в него только 2 терабайта и влазит, бывают на 4 Тб, но пореже. И вот в секунду этот объём информации обрабатывается кластером «Метрики».
И в чем тут смысл? Почему эта скорость так важна
Она важна, примерно, вот поэтому:

Это меняет подход к работе полностью. Особенно для аналитиков и людей, которые копаются в data science. Вот это модно сейчас.
Как это обычно работает
Они делают запрос в классическую систему, в Hadoop, например, или в MapReduce какой-то. Делают запрос, нажимают ОК, берут кружку и идут на кухню. И на кухне они там с кем-то флиртуют, с кем-то общаются, возвращаются назад через полчаса, а запрос еще выполняется или уже выполнился, но только если повезло.
В случае с ClickHouse, они начинают переходить на ClickHouse и это выглядит следующим образом: печатают запрос, нажимают Enter, берут кружку, идут и замечают, что запрос уже выполнился — и они такие «ладно, погоди», ставят кружку и еще раз делают запрос другой какой-то, потому что уже увидели, что что-то там не так, и он тоже выполняется и они делают запрос ещё и ещё, входят в цикл.
Это полностью меняет подход к работе с данными, вы получаете результат мгновенно — ну, буквально за секунды. Это позволяет проверить огромное количество гипотез очень быстро и посмотреть на свои данные и так, и сяк, под одним углом, под другим углом. Проводить исследовательскую работу невероятно быстро или расследовать какие-то инциденты, которые у вас произошли, очень быстро.
У нас внутри компании даже есть проблема, связанная с этим. Аналитики, они пробуют ClickHouse, например, кластер «Метрики» или какие-то другие кластера. Потом они заражаются какой-то заразой, идут в Hadoop или какой-то MapReduce и уже не могут им пользоваться, потому что он работает слишком медленно для них. Они уже думают по-другому. Они ходят и всем говорят: «Мы хотим данные в ClickHouse. Мы всё хотим в ClickHouse».
На самом деле ClickHouse, строго говоря, не решает всех тех задач, которые решает MapReduce. MapReduce это система немножко другая, но для типичных задач ClickHouse работает намного-намного быстрее, что это реально меняет работу с данными.
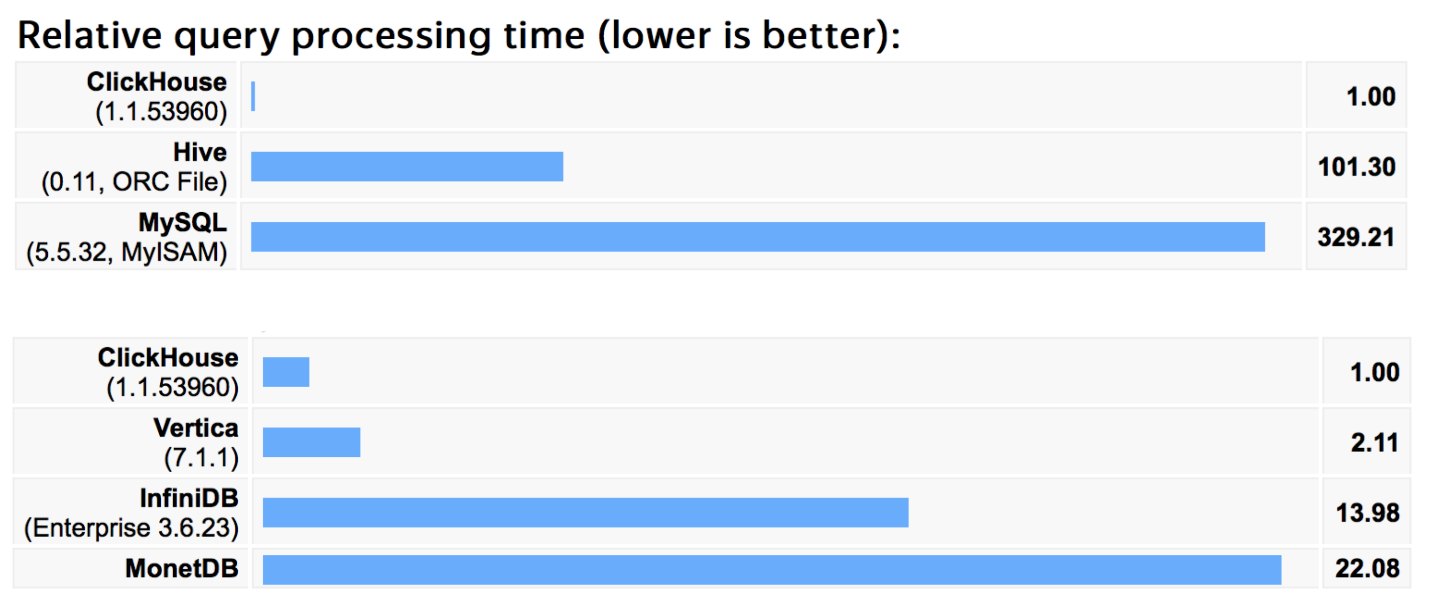
Немного бенчмарков, чтобы не быть голословным. Эти бенчмарки мы гоняли год назад на миллиарде строк, наших собственных, из «Яндекс.Метрики». Запросы, которые в этом бенчмарке были — разные. В основном это запросы, которые мы сами используем в «Метрике», нормальные аналитические запросы: select group by, достаточно сложные или достаточно простые, set из примерно сотни запросов.
На наших собственных данных результаты примерно такие, если сравнивать с Hive или MySQL — с какими-то классическими решениями, то разница в сотни раз, как я уже говорил, что не совсем честно, потому что они не поколоночные и не заточены под это.
Ниже есть более реальные конкуренты — базы, которые решают такие же задачи и видно, что сама крутая из них, которую мы пробовали, это Vertica. Vertica действительно очень хорошая база данных, хорошо спроектирована, хорошо написана и очень-очень дорогая.
ClickHouse по нашим измерениям в два раза быстрее был по этим бенчмаркам, 2 года назад. С тех пор мы очень много чего заоптимизировали.
Больше информации по ссылке: https://clickhouse.yandex/benchmark.html
Эта ссылка не ошибка — действительно ClickHouse.yandex. Дальше ничего нет — в «Яндексе» купили домен .yandex — очень круто выглядит, стоит кучу денег, но стоит видимо того. В общем, не ошибётесь.
Интерфейсы
Можно по-разному работать с ClickHouse. Есть отличный консольный клиент — очень удобный для быстрой работы и удобный для быстрой автоматизации, потому что он может работать в неинтерактивном режиме. Для скриптов это достаточно удобно. Дефолтный протокол — это HTTP, через который можно делать все: запрашивать данные, загружать данные. Всё что угодно.
Поверх HTTP у нас есть JDBC драйвер, он тоже в Open Source. Можете его использовать в Java, Scala — в каком угодно environment. Так же люди уже понаписали разных коннекторов под разные языки, можете тоже пользоваться. Если под ваш любимый язык коннектора нет, то конечно же — пишите его и люди снова порадуются.
Немного внутрь
Прежде всего хочется ответить на самый главный вопрос: «Почему ClickHouse такой быстрый? В чем магия? Почему это так?» Тут есть несколько ответов. Во-первых, с точки зрения кода, как я уже говорил — мы изначально проектировали решение чтобы оно максимально было заточено под производительность. Поэтому весь код там максимально оптимизируется.
Когда пишется какая-то фича, всегда прогоняются performance тесты и проверяется, можно ли эту фичу еще дооптимизировать. Поэтому в ClickHouse сейчас нет медленно работающих функций — все работают настолько быстро, насколько это возможно, в пределах разумного. Также используется векторная обработка данных — это означает что данные никогда не обрабатываются по строчкам, обрабатываются только колоночками. Если у вас есть колоночка чисел — вы пишете в сумму какое-то число, берётся большой массив чисел, применяется какая-нибудь классная SSE-что-нибудь-инструкция и очень быстро все это складывается. Это позволяет действительно сильно ускорить обработку.
С точки зрения данных — колоночное решение, понятно, очень эффективно работает, потому что вы запрашиваете только те данные, которые вам нужны, а не все колонки. И Merge Tree используется, кто не знаком — почитайте на Википедии, прекрасная структура для хранения данных, используется в ClickHouse. Это значит, что ваши данные будут лежать в каком-то небольшом количестве файлов, гарантировано — в ограниченном количестве файлов. Поэтому с точки зрения seek-ов на жестком диске — их количество будет минимальным. Вообще ClickHouse оптимизирован под работу на жестких дисках, потому что в «Метрике» мы используем жесткие диски, данных очень много на SSD не влезет.
Обработка данных происходит максимально близко к этим данным. Если у вас есть удаленный запрос, то ClickHouse старается максимальное количество работы сделать ближе к данным, чтобы по сети передать какие-то агрегаты и небольшое количество информации. Это, в частности одна из причин, по которой ClickHouse работает в cross-datacenter environment хорошо — потому что по сети передаётся не так много данных.
Также есть некоторые возможности, которые в ClickHouse из коробки работают для ускорения запросов, если это необходимо.
Есть семплирование.
Работает примерно так: если запрос работает недостаточно быстро, вы можете посчитать за ваш запрос не все данным, а скажем по 10% или 1%. Это нужно для исследовательской работы — если вы хотите поисследовать ваши данные, то делать это можно по 1% нормально и будет работать, примерно, в 100 раз быстрее. Очень удобно.
Есть функции с вероятностными алгоритмами — можно выбирать какой-то компромисс между скорость и точностью. Есть на уровне запроса возможность редактировать параметры, например — выбирать количество потоков, которые обработают именно этот запрос, что добавляет гибкости.
Масштабируемость и отказоустойчивость
Тут нужно сказать, что ClickHouse это такая полностью децентрализованная система и нет единой точки, которая принимает эти запросы, и единой точки, которая как-то регулирует, что происходит.
Асинхронная репликация применяется по умолчанию. Это означает, что вы данные записываете в какую-то любую реплику, а они будут гарантированно скопированы на другую реплику когда-нибудь. Ну как работает асинхронная репликация — в терминах ClickHouse это секунды, но на самом деле есть режим, который позволяет все сделать синхронно, если вам это необходимо. Обычно это не нужно.
ZooKeeper очень активно используется для синхронизации действий, для leader election и других операций. Не используется во время запросов, потому что ZooKeeper не способен выдержать RPS. Вообще он способен, но это внесёт дополнительные задержки, однако внутри он используется очень активно.
На примере кластера «Яндекс.Метрики»:
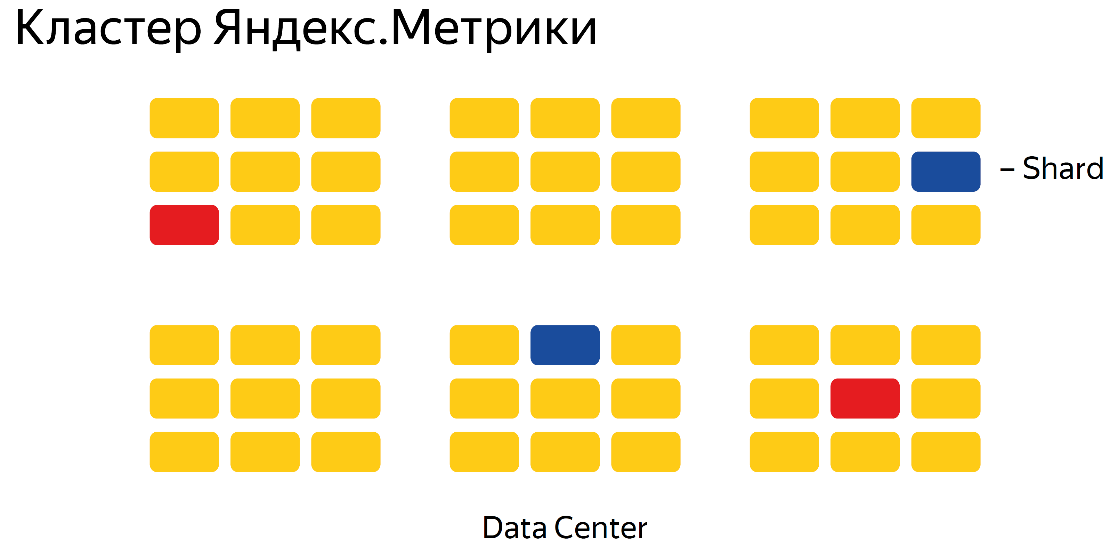
Тут изображено 6 датацентров. Синеньким изображен один шард, это две копии, х2 фактор репликации. Данные одинаково располагаются в двух датацентрах — все достаточно просто. Если фактор репликации будет х3, то синих и красных квадратиков будет 3 штуки.
Самое интересное. Как вы можете использовать ClickHouse?
Начать хотелось бы с того, как ClickHouse не нужно использовать. Не стоит микроскопом гвозди забивать. ClickHouse это не OLTP решение, что означает следующее — если вы хотите какой-то транзакционности, если вы хотите какую-то бизнес логику поверх базы делать, не используйте для этого ClickHouse. Используйте классические решения: PostgreSQL, MySQL, что вам нравится. ClickHouse это база данных для аналитики, для исследовательской работы и для каких-то real-time отчетов. ClickHouse это не key-value решение. Не надо его использовать, как storage файлов или еще что-то такое. Не складывайте туда свои любимые фильмы, сложите их куда-нибудь в другое место.
ClickHouse — не document-oriented система, это означает, что в ClickHouse жесткая схема. Её нужно задать на уровне create table и описать структуру. Чем эффективнее вы опишите эту структуру, чем правильнее вы это сделаете — тем больше профита вы получите от ClickHouse с точки зрения производительности и удобства работы.
В ClickHouse нельзя модифицировать данные. Это для многих может быть сюрпризом, но на самом деле вам не нужно модифицировать данные — это иллюзия. Ну, то есть на самом деле в ClickHouse можно модифицировать данные — есть поддержка, можно удалять целиком куски большие. Есть возможность работать с данными — такая концепция SRDT, когда вы меняете данные не меняя их, то есть вставляете новые записи. И в ClickHouse можно работать таким образом, но основная идея тут в том, что если вам нужно часто менять данные, то, скорее всего, вам не нужно использовать ClickHouse — он вряд ли подходит для ваших задач.
Когда нужно использовать ClickHouse?
Нужно использовать ClickHouse, когда у вас есть широкие таблички с большим количеством колонок. Это отлично работает в ClickHouse, в отличие от большого количества других баз, потому что это поколоночное решение. Если вы считаете аналитику — замечательное решение будет.
Если у вас паттерн такой, что запросов не очень много, но в каждом запросе используется очень много данных — то ClickHouse отлично работает в таком паттерне. «Немного» в данном случае это: единицы, десятки, сотни RPS.
Если у вас большой поток входящих данных, прям постоянно течёт в базу. В случае «Метрики» это какие-то 20 миллиардов событий день и они в реальном времени пишутся. Очень немного баз способны работать в таких условиях, когда у них постоянно всё пишет, при этом постоянно запрашивает. ClickHouse может, он под это заточен.
Если у вас в принципе есть петабайты данных и вам нужно считать аналитику по ним, то вообще говоря не так много решений способны это сделать. Прям их можно на пальцах одной руки пересчитать, ну может двух. И ClickHouse отлично с этим справляется (не пальцы считать).
У меня есть пара небольших кейсов. С чего обычно начинают — это пытаются анализировать, что у них происходит в их текущем продакшене.
Как это обычно выглядит
Люди берут св
