Быстрый рендеринг с DOM шаблонизаторами
Борис Каплуновский ( BSKaplou)

Я довольно долго работал над докладом и старался сделать его настолько противоречивым, насколько это возможно. И сразу начну с противоречия — я в корне не согласен с тем, что веб-компонентами можно пользоваться. Уже поднимался вопрос о 300 Кбайтах, я глубоко уверен, что 300 Кбайт для страницы Javascripta — недопустимо много.
Сегодня я расскажу о довольно глубоком путешествии во фронтенд. Началось это путешествие тогда, когда я обнаружил, что фронтенд aviasales.ru тормозит, и надо что-то делать. Это путешествие началось года полтора-два назад, и вещи, о которых я буду рассказывать, — это сжатое повествование того, что я узнал.
Самым критичным, на мой взгляд, в производительности фронтенд-приложений является рендеринг. Все мы знаем, что работа с DOM — это такая вещь, которую нужно стараться избегать. Чем больше вы делаете вызовов к DOM API, тем медленнее работает ваше приложение.
О чем конкретно мы поговорим? О правилах игры. На какие вещи в рендеренге, в работе веб-приложения нужно обращать внимание, какие параметры являются ключевыми для библиотеки шаблонизации для рендеринга, какие есть типы шаблонизаторов.
Дальше я немножко пройдусь по костям гигантов, это AngularJS и ReactJS, попытаюсь рассказать, чем они мне не нравятся, и почему они тормозят. Расскажу о том, что хорошего я нашел в других шаблонизаторах и о произведении, которое мы создали, основываясь на всех вышеизложенных знаниях.
Наверное, часть аудитории интересует, что означает дайвер в нижней части экрана? Наша команда разработки находится в Таиланде, и я лично занимаюсь дайвингом. В моей голове родилась такая аналогия: если вы находитесь под водой, то чем меньше движений вы делаете, тем больше кислорода вы экономите, тем больше сможете проплавать. С DOM мы видим примерно то же самое — чем меньше обращений к DOM вы делаете, тем больше вероятность, что пользователь не столкнется с тормозами.

Начнем о правилах игры. User experience зависит от скорости инициализации страницы. Все мы глубоко увлечены кэшированием страниц, но вынужден сразу же противоречиво заявить, что кэширование не работает. Не работает, потому что первый контакт с сайтом у человека — самый критичный. Если при первой загрузке сайт тормозит, то второй раз пользователь может к вам не вернуться. Первоначальная загрузка страницы крайне важна.
Вторая важная вещь — это скорость реакции интерфейса. Если человек нажал на кнопку или чекбокс, и при этом интерфейс не отреагировал мгновенно, пользователь может закрыть сайт и уйти на другой сайт, туда, где интерфейс отзывчив.
Следующая вещь — это потребление ресурсов. На веб-страницах важны два основных показателя: потребление процессора (если вы делаете много лишних действий, вы греете процессор, и у него не хватает времени, чтобы обсчитать анимацию на интерфейсе или что-то просто пририсовать), кроме того, если вы создаете много лишних объектов, это создает нагрузку на garbage collector. Если вы создаете нагрузку на garbage collector, то периодически он будет вызываться, и отзывчивость вашего приложения будет падать.
И последний, но от этого не менее важный пункт. Размер библиотеки. Если у вас single page application, то 200–300, иногда даже 400 Кбайт javascript вы можете себе позволить. Однако же, компонентный веб, в направлении которого мы с вами весело движемся, подразумевает, что страницы строятся из разных веб-компонент. Более того, эти веб-компоненты зачастую произведены в разных компаниях и приходят со своим пакетом.
Представим себе страницу, на которую вставлено десяток виджетов: виджет курсов валют, погоды, авиабилетов, черта в ступе чего… И каждый из этих компонент весит 300 Кбайт, и это только JS. Таким макаром, у нас запросто получится страница, которая весит 5–10 Мбайт. Все бы ничего, и Интернет становится все быстрее и быстрее, но появились мобильные устройства, появились медленные сети, и если вы пользуетесь Интернетом не в городе Москва, а где-нибудь в Екатеринбурге, то 15 Мбайтный сайт окажется для вас совершенно недопустимой роскошью. Именно поэтому размер библиотеки, на мой взгляд, критичен.
Чуть ниже я сравниваю несколько библиотек, и не сравниваю полимеры, не сравниваю по той причине, что 200 Кбайт для библиотеки веб-компонентов — это слишком много.

Итак, перейдем к теме разговора — к шаблонизаторам.
Все мы, кто занимается разработкой веб, привыкли уже к строковым шаблонизаторам. Строковые шаблонизаторы — это шаблонизаторы, которые в результате своей работы возвращают нам строку. Строку, которую позже мы вставляем посредством innerHTML в html. Это замечательный, древний, всем привычный механизм. Однако он имеет ряд недостатков. Главный недостаток — то, что каждый раз, когда вы произвели шаблонизацию и делаете вставку в innerHTML, приходится выкинуть весь DOM, который там был раньше и вставить новый DOM.
Насколько я помню, работа с DOM очень и очень медленна. Если вы выкинули 20 тегов с 30-тью атрибутами и вставили такие же, те же 20 тегов с 10-тью атрибутами, то это займет значительное время. 20 миллисекунд запросто. Кроме того, строковые шаблонизаторы не позволяют оставлять якоря для быстрых апдейтов единичных атрибутов, единичных текстовых нод и т.п.
Обнаружив эти неоптимальности, мы начали искать, как же можно избавиться от этих недостатков, что можно с этим сделать? И первое, что подсказал Goggle, это «Используйте DOM API». Это штука не очень простая. Но у нее есть плюсы.

Это скриншот с сайта jsperf. Бенчмарк, который видит производительность строковых шаблонизаторов, вставляющих куски html из innerHTML и DOM JS. Здесь мы видим в верхней части производительность на Android«е, и видим, что JSDOM API позволяет ускорить рендеринг в несколько раз. Здесь примерно в три раза. В то же время на десктопных браузерах такого адского прироста производительности нет.
Google примерно полгода назад начал обещать всем веб-разработчикам «мобилогеддон». Это значит, что все сайты, которые не адаптированы под мобильные устройства, респонсивные, адаптивные, будут пессимистироваться в поисковые выдачи. Это значит, что если вы не готовы к мобильным устройствам, просто трафик с Google на ваших сайтах значительно уменьшится.
По сути, этот слайд наглядно говорит, что используя DOM API, вы можете значительно ускорить рендеринг на мобильных устройствах. Причем это относится не только к Android«ам. Как вы знаете, все современные Android«ы и IOS-устройства используют один и тот же движок WebKit, примерно с одним набором оптимизации, а значит такой же прирост по производительности вы получите на всех IOS устройствах, если будете рендерить страницы через DOM API.

Однако, DOM API — штука довольно громоздкая. Здесь я привел пять основных вызовов, с помощью которых можно создавать участки DOM. Привел я их примерно в том виде, в котором они будут встречаться в коде вашей программы, если вы будете создавать участки DOM непосредственно через API.
Создание одного элемента, который раньше у вас укладывался в 15–17, может быть 30–50 символов, через DOM API запросто у вас выльется в 5–10 строк кода. Время работы программистов ценно, а это значит, что мы не можем заменить html на ручное программирование DOM.

Здесь-то нам и необходимы шаблонизаторы. Как вы помните, строковые шаблонизаторы медленные, и хочется иметь DOM шаблонизаторы, шаблонизаторы работающие через DOM API, но позволяющие пользоваться всеми теми плюшками, к которым мы привыкли, работая с обычными шаблонизаторами.
Итак, что же нам дают DOM шаблонизаторы, кроме возможности не использовать родной JSDOM API? Они позволяют сохранять DOM объекты в переменных для быстрого обновления позже. Используя DOM шаблонизаторы, можно использовать один и тот же участок DOM несколько раз.
Что я имею в виду? Предположим, мы посещаем страницу веб-магазина. Пользователи заходят в одну категорию товаров, и в заготовленные шаблоны подставляются данные об одном списке товаров. Когда человек переходит в другую категорию товаров, в эти же шаблоны подставляются другие данные. По сути, мы не пересоздаем DOM, мы используем одни и те же участки DOM для отображения данных. Это позволяет очень сильно сэкономить и на ресурсах процессора, и на памяти, и иногда на времени программистов.
После осознания этой мысли, что инструмент, который мне нужен, — это DOM шаблонизаторы, мы пошли смотреть, что же уже существует в индустрии, чем уже можно воспользоваться, чтобы быстро и качественно работать с DOM, и быстро его рендерить?
Дальше я расскажу, где, на мой взгляд, оступились гиганты.

Первый гигант, о котором я хочу рассказать, это AngularJS.
AngularJS, мне кажется, оступился прямо на самом старте. Если вы им пользовались, то, наверное, заметили, что все шаблоны передаются на клиент в виде либо DOM участков (что является не очень хорошим стилем), либо в виде строк. После того, как библиотека загрузилась, Angular вынужден скомпилировать ваши строки или DOM в реальные шаблоны. Это происходит на клиенте.
Представим себе интересную ситуацию. Пользователь заходит на страницу, грузит весь JS, которого для Angular приложений может быть довольно много — 100–200–300 Кбайт запросто. После этого каждый шаблон с разбором строк начинает компилиться. Приводит это всего к одной вещи — первоначальная загрузка Angular приложений может из-за этой компиляции (во время которой пользователи занимаются чем угодно кроме работы с сайтом) длиться полсекунды, секунду. Я встречал сайты, на которых процесс компиляции шаблона занимал даже две секунды. Более того, эта проблема нарастает как снежный ком: чем больше шаблонов в вашем приложении, чем сложнее ваше single page application, тем больше времени мы тратим на первоначальную компиляцию шаблонов.
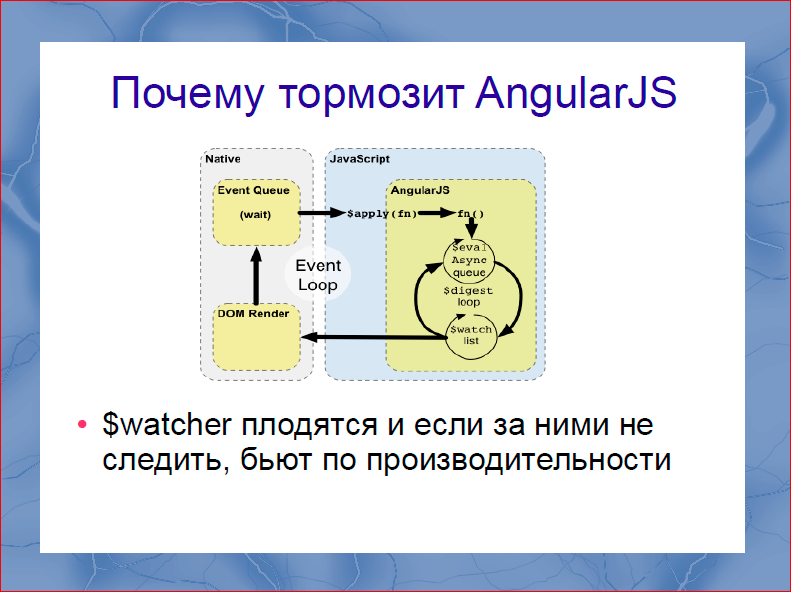
Следующая проблема в Angular. Мы все помним, что Angular продавался нам господами из Google, как первый самый крутой фреймворк с двусторонним биндингом. Причем, этот двусторонний биндинг реализуется через т.н. $watcher«ы, которые вы вешаете на структуры данных для последующего отображения их в DOM. На слайде интересная картинка, но вы на нее не смотрите. Интересным в ней является только этот замечательный цикл, в ходе которого обходятся все $watch«и, на всех данных, которые у вас существуют в системе. Причем, конечно же, в документации и во всех туториалах, вам никто не будет рассказывать, что за $watcher«ами нужно следить. Приводит это буквально к следующему. В какой-то момент ваше замечательное приложение начинает раз в 100 мс хорошо притормаживать. Начинают тормозить анимации, начинает течь память. Оказывается, что допускать много $watcher«ов просто нельзя. Как только вы допустили много $watcher«ов, ваше приложение начинает спонтанно тормозить. Тут вы начинаете хитро изощряться, идти на что угодно, сокращать количество $watcher«ов, отказываться в приложении от двустороннего биндинга, ради которого вы брали Angular, только чтобы избавиться от тормозов.

Кроме того, мне кажется, архитектурной промашкой Angular является то, что в Angular не существует единственного правильно описанного способа работать с DOM. Директивы фактически независимы, каждая из их работает с DOM так, как она считает нужным. А получается, что пройдясь по директивам Angular, мы можем пометить некоторые директивы быстрыми, некоторые как медленные, а некоторые директивы как очень медленные.
Если вы пользовались ng-repeat, то вы, наверное, видели, что если вы запихнете 100 элементов в нее, и еще там будут $watcher«ы, то рендериться все это будет очень долго. Проблема настолько широка, что работая с Angular (наша предыдущая версия выдачи была построена именно на Angular), нам пришло написать свой ng-repeat. Это сделал наш сотрудник Антон Плешивцев и рассказывал об этом на множестве конференций. Кроме этого, 50 Кбайт минимизированного размера библиотеки, на мой взгляд, все-таки многовато. Т.е. за что вы платите? Если вы смотрите код Angular, то в эти 50 Кбайт зашита собственная система классов, туда зашита очень некачественная, на мой взгляд, версия Underscore. И это все вы получаете совершенно бесплатно в рамках 50-ти Кбайт кода.

Следующее. Намного более качественный фреймворк, на мой взгляд, это ReactJS. Судя по тому, как бурлит Интернет, каждый первый программист, даже не всегда фронтендщик, пользовался Angular и в восторге от него. Я не считаю, что virtualDOM может ускорить работу с DOM.
Смотрите, что нам предлагает virtualDOM. VirtualDOM является источником, из которого ReactJS создает настоящий DOM, т.е. кроме реального DOM, от создания которого вы никуда не денетесь (virtualDOM всего лишь позволяет его создавать), ReactJS в памяти держит еще virtualDOM, это называется избыточностью.
VirtualDOM несколько меньше настоящего DOM, может быть раз в 5. Однако, на самом деле, вы вынуждены держать в памяти две копии virtualDOM.Т. е. вы держите настоящий DOM, вы держите отражение настоящего DOM в virtualDOM, кроме того, каждый раз, когда вы собираетесь делать div в virtualDOM, вы делаете еще одну копию DOM. У вас был один DOM, теперь у вас их три — молодцы! Более того, на каждое изменение данных, вы создаете еще одну копию virtualDOM, это и есть третья копия, однако, вы создаете ее с нуля.
Это создает серьезную нагрузку на garbage collector и на процессор. Кроме того, на мой взгляд, библиотека все еще жирная — 35 Кбайт. И опять же, ребята решили нарисовать свою систему классов, нарисовать свой lowdash, оригинальный почему-то не устраивал, и все это запихнули в 35 Кбайт. Кроме того, там упакован virtualDOM с мифическим алгоритмом, который якобы дает огромную производительность.
Следующая проблема virtualDOM и React в частности, это то, что ReactJS ничего не знает о семантике ваших данных. Давайте, посмотрим этот очень простой пример.

Здесь мы видим два вложенных
Кроме того, если вы программировали на React, то вы знакомы с такой штукой как pure-render-mixin. Суть его в том, чтобы избавиться от работы c virtualDom’ом. Случается очень интересная ситуация близкая к комичной. Сначала господа из Google пару лет продавали нам React как штуку, которая с помощью virtualDOM адски ускоряет работу с DOM, а потом оказывается, что чтобы быстро работать с DOM, нужно исключить virtualDOM. Молодцы, хорошо сделали.
А теперь кое-что другое. Захотелось поискать — быть может, на планете есть библиотеки, есть люди, которые сделали что-то лучше. Я не пытался найти одну библиотеку, серебряную пулю, но хотел подсмотреть в библиотеках вещи, которые можно было бы использовать либо для ускорения React, либо для создания своей библиотеки. И вот, что я нашел.

Я рассмотрю две интересные библиотеки. Первая из них — RiotJS.
На мой взгляд, RiotJS — это правильная AngularJS, просто потому что размер библиотеки 5 Кбайт. Ребята взяли абсолютно те же идеи, что были в AngularJS, но не стали переписывать lowdash, просто сказали: «Зачем? Он уже написан». Ребята не стали переписывать, изобретать свою систему классов, ничего не стали делать. Получили библиотеку в 5 Кбайт. Производительность больше, чем у AngularJS, идеи абсолютно те же. И более того, шаблоны, используемые в RiotJS, используют семантику данных, что дает неплохой прирост по производительности. Но осталась и проблема — компиляция шаблонов все еще происходит на клиенте. Это не очень быстро, но уже намного лучше.

Следующая библиотека, которая привлекла мое внимание, это PaperclipJS.
PaperclipJS использует ряд очень интересных оптимизаций. В частности, для создания шаблонов используется cloneNode, а дальше я покажу, что он дает большой прирост по производительности, но это решение позволяет PaperclipJS быть более прозрачным, более понятным для девелопера.
Но и у этой библиотеки нашлось два недостатка: она довольно большая — 40 Кбайт, это больше, чем React; и, несмотря на хорошие идеи, разработка ведется довольно вяло. Этой библиотеке уже пару лет, однако, она до сих пор не вышла из стадии beta.
Пообщавшись с этими библиотеками и другими библиотеками, начитавшись гуру html5, я смог придумать следующий список техник, которые позволяют ускорить работу с DOM.

Первая вещь — это VirtualDOM. Его плюсы я долго искал, и нашел только один — он позволяет сократить количество вызовов к DOM, тем самым подняв производительность. Однако, оверхед на создание копии DOM, на мой взгляд, все-таки значительный. Сложный алгоритм сравнения, над которым до сих пор стоит завеса тайны, который используется в React, он не такой быстрый, как нам о нем обещают. Чтобы понять, как оно работает, вы потратите дня два. И всей этой магии, о которой рассказывали в блогах, там нет, на мой взгляд. Кроме того, virtualDOM сидит на той проблеме, что алгоритм ничего не знает о структуре данных. Пока мы ничего не знаем о структуре данных, все наши врайперы, все наши элементы верстки, негативно сказываются на производительности, потому что алгоритм virtualDOM должен участвовать в их сравнении.

Техники, которые были известны очень давно — это использование cloneNode, о котором я уже говорил в рамках PaperclipJS и DocumentFragment. Эти две техники используются для повышения производительности. Ни одна, ни другая техника, насколько мне известно, не используется ни в AngularJS, ни в ReactJS. Однако скриншот бенчмарка с jsperf наглядно показывает, что это позволяет ускорить работу с DOM, как минимум в три раза. Довольно неплохая практика, очень советую пользоваться.

Следующая техника, которая лежит абсолютно на поверхности, более того, неявно встречается даже в туториале по React, — это создание DOM участков заранее. Что я имею в виду? Предположим, человек заходит на страницу интернет-магазина электронных чайников. Вводит название чайника, название фирмы чайника, который хочет приобрести. В этот момент на сервер отправляется поисковый запрос. Если ваши серверные программисты быстры и молниеносны, то вы можете получить ответ за 20 мс, эти 20 мс пользователь практически ничего не делает. И в этот момент мы можем создать структуру DOM под данные, которые вернутся с нашего сервера. Довольно простая практика. Не знаю, почему она не получила широкого применения. Я ее пользую, очень круто получается.
Итого, что получается? Мы шлем запрос на сервер, пока мы ждем ответа с сервера, мы подготавливаем структуры DOM под данные, которые должны к нам прийти с сервера. Когда к нам приходит ответ с сервера, на самом деле нам его еще нужно разобрать. Чаще всего, это не просто принять Json, но и как-то адоптировать его. Если к этому моменту DOM у нас уже готов, то те 2–3–4 мс, которые у нас есть для работы JS мы можем потратить на адаптацию и на вставку данных в DOM и добавление данных на страницу.
Очень советую использовать это, причем явным образом в фрейморках эта штука не поддерживается, но вы можете руками создать элемент при отправке запроса на сервер.
Итак, снарядившись всеми этими знаниями, и найдя немножко свободного времени по ночам и выходным, я решил написать небольшой прототип, с которым мы стали дальше работать.

Это шаблонизатор temple. Он очень простой, очень маленький, там буквально меньше 2000 строк кода.
Какими же свойствами он обладает? Шаблоны компилируются на момент сборки в JavaScript код, т.е. на клиенте никакой работы, кроме загрузки JavaScript кода не делается. Возможность создавать куски DOM заранее поддержана прямо в библиотеке. Библиотека позволяет легко и просто переиспользовать шаблоны. Размер библиотеки, на мой взгляд, более чем скромный в минимизированном и gzip«ленном виде — это всего 700 байт. Более того, вещь, которая мне в ней нравится больше всего — это максимально быстрое обновление DOM.
Дальше попытаемся по кусочкам разобрать, как же это все сделано и работает.

Структура шаблона крайне простая и примитивная. Это усы, внутри которых подставляются переменные.

Все довольно очевидно, никакой магии. Кроме этого, поддерживает две конструкции. Это forall итерация по ключу для циклов и ветвления if. Не поддерживаются выражения. Некоторое время назад, до появления React, в индустрии доминировало мнение, что нельзя ни в коем случае мешать View и модель. Я до сих пор верю, что это правильный подход, поэтому если хочется использовать сложные выражения, лучше вынести это в отдельный компонент. Если вы помните, есть такие паттерные Presenter или ViewModel, если вам нужно сложно подготавливать данные отображения в шаблоны, лучше это сделать там, и не затягивать выражения в шаблоны.
Дальше я покажу, как с этим работать. Я считаю, что не нужно на каждый чих создавать фреймворк, что будущее веба, и особенно компонентного веба, в очень маленьких и независимых библиотеках, не требующих смены религии и выпиливания всего предыдущего из программы для своей интеграции в них.
Как выглядит работа с темплом.

Мы берем именованный шаблон из темпла, апдейтим данные в нем вызовом update. И вставляем его в DOM. Фактически это очень похоже на работу с обычным DOM API. После того, как мы попользовались шаблоном, мы можем убрать его из DOM вызовом remove. Все очень просто.

Как делается заблаговременное создание DOM? Предположим, мы послали на сервер запрос и знаем, что с сервера нам должен прийти набор чайников. В этот момент мы говорим пулу шаблонов: «Создай кэш на 10 чайников». Он создается, и когда мы в следующий раз будем делать такой же вызов get, реальной работы с DOM не будет, мы получим уже подготовленный и срендеренный шаблон. Т.е. получим шаблон для вставки в DOM мгновенно.
Когда этим удобнее всего пользоваться? Смотрите, мы посылаем запрос на сервер и у нас есть 20 мс, на самом деле, конечно, не 20, скорее всего это 200–300 мс, за это время мы можем накэшировать миллионы DOM нод, т.е. времени достаточно.
Второй вариант — это кэшировать шаблоны, когда мы ожидаем DOMContentLoaded.
С DOMContentLoaded есть такая проблема, что очень много обработчиков подписываются на это событие и в итоге в момент прихода этого события просыпается чертова туча скриптов, которые все по callback«у начинают обрабатывать, и после этого события около 100 мс приложение спит. Оно глубоко считает там что-то. Чтобы сократить это ожидание, можно кэширование DOM шаблонов сделать заранее, до того, как это событие к нам придет.

Быстрое внесение изменений в DOM. Здесь я привожу простой и понятный вызов, он очень похож на то, как делается update в React. Все помнят вызов в React setState, разница только в глубине стека. Если вы видели, насколько глубоко, сколько вызовов функций делает React, перед тем как сделать целевое действие (а целевое действие у нас, скорее, такое — просто подставить в DOM это значение), то знаете, что для React это может быть глубина стека 50–60, может быть больше.
Каждый вызов, особенно в динамических языках как JavaScript, дается нам совершенно не бесплатно. Это не так медленно как DOM вызов, но все еще не бесплатно. Темпл позволяет делать эту замену с глубиной стека =2, т.е. по сути, вызывается update, из него вызывается функция, которая заменяет это значение. По сути, это функция value. И с глубиной стека =2, мы получаем целевое действие. При этом вызов update рекомендуется использовать тогда, когда мы хотим изменить сразу несколько значений. Если мы хотим изменить одно, то это можно еще быстрее — прямым вызовов property и тогда эта подстановка будет сделана с глубиной стека =1, быстрее физически невозможно.

Переиспользование шаблонов. После того, как пользователь сделал поисковый запрос на чайники, насмотрелся на чайники, и сделал новый поисковый запрос, мы можем вернуть шаблоны в пул для дальнейшего использования, чтобы потом их переиспользовать. Это тоже поддерживается фреймворком, такой функцией pool.release.

Дальше попытаюсь вам продать этот инструмент с помощью бенчмарков. Первый бенчмарк. Внизу я всегда привожу ссылку на бенчмарк, и помним, что на jsperf «больше» значит «лучше». В данном случае красное — это Темпл, и синее — это React. C React я сравниваюсь, потому что React, наверное, самое быстрое решение, он раз в 5 быстрее, чем Angular обычно. Итак, что же мы тут видим? Первоначальная инициализация в Темпле делается на процентов 30 быстрее в Chrom«е, и на процентов 10–15 в Firefox«е. За счет чего это получается? Внутри, в конечном итоге, использу.тся те же create element, create text, node appendchild. Однако в Темпле почти никогда нет глубины стека больше двух. По сути, мы экономим время исключительно на вызовах внутри библиотеки. Те 35 Кбайт JavaScript, которые вы скачиваете для использования React, отливаются вам этой разницей в производительности — длинные стеки.
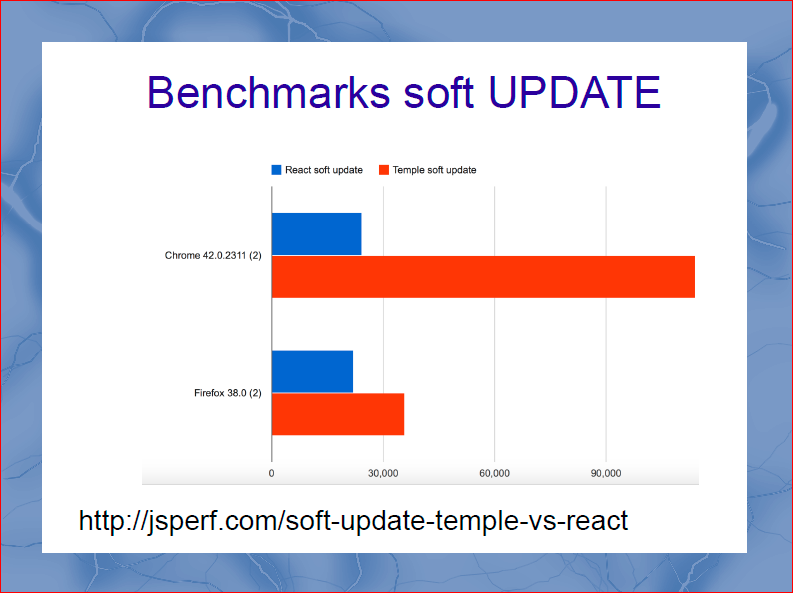
Следующий бенчмарк, который мы изобрели и прогнали — это soft Update. Soft Update — это когда мы подставляем в шаблон те же данные, которые туда уже были подставлены. Это то место, где должен проснуться virtualDOM и сказать: «Ребята, данные уже есть, ничего делать не надо». Скажу сразу, что для чистоты экспериментов на virtualDOM я не использовал pure-render-mixin. И оказалось, что оптимизации в самом браузере позволяют делать это в четыре раза быстрее. VirtualDOM вносит тормоза в четыре раза.
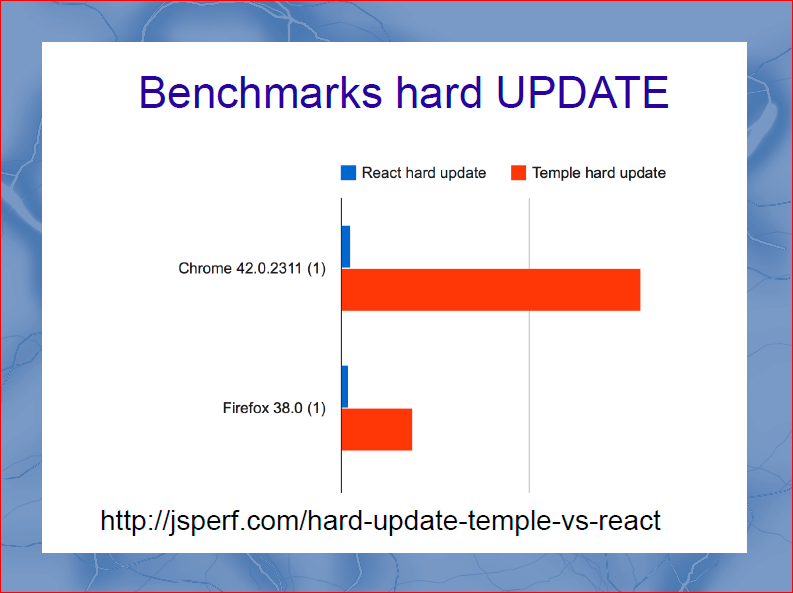
Пойдем дальше, hard update. Hard Update — это сценарий, при котором в шаблоне обновляется не один участок данных, а все данные, которые есть. Опять же не используем pure-render-mixin, но он тут бы был и бесполезен. И получаем еще более интересные данные. При hard update выигрыш Темпла в десятки раз, просто потому что там нет virtualDOM.
VirtualDOM на практике оказался очень ресурсоемкой операцией. И если вы глубоко программировали React-приложения, то довольно быстро столкнулись с тем, что работу с virtualDOM нужно сократить. Я в этой идее достиг полного перфекционизма и считаю, что virtualDOM, как идея, плох, и его нужно выкинуть. Это сделает React легче Кбайт на 20, и быстрее раз в 10.

Темпл, который мы делали, очень маленький. Aviasales — не Facebook, у нас нет миллионов инженеро-часов, у нас есть только… Как вы понимаете, разработка таких библиотек — не очень продуктовая фича, и в рабочее время заниматься этим не получается. Этим можно заниматься ночью небольшой группой энтузиастов. Поэтому библиотека очень маленькая. Темпл не предлагает работу с событиями. В React есть DOM delegate, в AngularJS есть своя работа с событиями. Но я и не считаю, что нужно работу с событиями интегрировать в шаблонизатор. Для работы с событиями можно использовать стандартные библиотеки. Мы используем domdelegate от Ftlabs. Ftlabs — это IT-подразделение «Financial Times». Ребята сделали очень хорошую, очень простую и производительную библиотеку, ее размер, если не ошибаюсь, меньше 5 Кбайт. Мы ее используем в паре с Темпл, и довольны результатами.

В пользу своих предыдущих бенчмарков и слов, хочу сказать, что на данный момент Темпл мы используем уже в двух проектах: это мобильная версия aviasales.ru и новая поисковая выдача aviasales.ru. В мобильной версии все шаблоны преобразуются в 10 Кбайт кода, речь идет о минимизированном и сжатом коде, и все приложение занимает 58 Кбайт. Мне кажется, это неплохой размер для довольно сложного single page приложения.
Следующим приложением, которое мы разрабатывали, была новая поисковая выдача, там шаблоны уже занимают 15 Кбайт, и все приложение занимает 70 Кбайт. Также было несколько интеграций с виджетами, но они менее интересны. Однако, 70 Кбайт для single page application, мне кажется это хороший показатель. Особенно если сравнивать с библиотеками, которые весят 200.

Собственно, это открыто в open source сейчас. Можете посмотреть его, поиграться с ним по url на слайде. Оно все еще довольно сыро.
Как и говорил, у нас нет огромного количества ресурсов для того, чтобы евангелизировать это наше произведение для того, чтобы делать документации. Если интересно, можете пойти, там есть документация, есть примеры, есть плагины для gulp и grunt и там вы можете увидеть хорошую производительность.
Контакты
BSKaplou
bk@aviasales.ru
Этот доклад — расшифровка одного из лучших выступлений на конференции фронтенд-разработчиков FrontendConf. Мы уже открыли подготовку к 2017 году, а подписавшись на список рассылки конференции Вы получите 8 лучших докладов прошлого года.Самая сложная секция грядущей конференции HighLoad++ это »Производительность фронтенда». Фронтенд стал большим, это уже полноценный софт со своей архитектурой, моделями и данными (а не просто интерфейс, как было раньше). Именно в этом разрезе мы и изучаем его на этой секции.
Вот некоторые из планируемых докладов:
- Промышленное ускорение сайтов / Николай Мациевский (Айри.рф);
- Your hero images need you: Save the day with HTTP2 image loading / Tobias Baldauf (Akamai Technologies);
- The Accelerated Mobile Pages (AMP) Project: What lies ahead? / Paul Bakaus (Google);
Превышаем скоростные лимиты с Angular 2 / Алексей Охрименко (IPONWEB);
Instant Loading: Building offline-first Progressive Web Apps / Alex Russell (Google);
Комментарии (2)
24 сентября 2016 в 11:20
+1↑
↓
Вместо temple берем jsx без реакта и получаем работу с евентами, легкий биндинг и такую же компиляцию в js. Биндим нужные части интерфейса к переменным стейта — получаем быстрый рендер с перерисовкой только того что изменилось, самим броузером, нативно. Почему не работают компоненты — я так и не понял.
24 сентября 2016 в 11:24
0↑
↓
А есть пример todo приложения на temple, или это для temple слишком сложно?
