Был excel — стал ML: как мы расход ингредиентов учились прогнозировать
Прогнозирование закупок и расхода ингредиентов — часть работы управляющего любым рестораном, которая может занимать несколько часов в неделю. Мы в Dodo Engineering задумались, как можно помочь и автоматизировать рутину, при этом улучшить качество прогноза.
В статье расскажу о том, как развивался процесс прогнозирования для наших пиццерий, как строили расчёт, о недостатках и плюсах инструментов для интеллектуального прогнозирования.

В прошлом году наша сеть потеряла 1–2% выручки из-за «стопов» пиццерий, связанных с отсутствием каких-либо продуктов. Оно и неудивительно, ведь для приготовления десяти самых популярных пицц из нашего меню требуется более 30 ингредиентов! Если брать в расчёт всё меню, то количество нужных ингредиентов вырастает до нескольких сотен. Как управляющему пиццерией не сойти с ума от этого многообразия, заказать всего и в нужном количестве, при этом не сильно отвлекаясь от других дел, связанных с непосредственным управлением пиццерий? Для помощи в этой задаче мы и затеяли разработку решения, которое могло бы автоматизировать процесс прогноза будущих расходов ингредиентов.
Всё дело в деньгах
 Где деньги?
Где деньги?
Для бизнесов, которые что-то производят и продают, можно выделить два подтипа в ошибках прогнозирования запасов: перепрогноз и недопрогноз. К чему приводят такие ошибки?
Потеря лояльности клиентов. Например, клиент хочет заказать себе пиццу, чтобы съесть её с друзьями под игры в настолки, а мы не можем приготовить, потому что у нас закончился один из ингредиентов, необходимый для приготовления.
Финансовые потери от недопрогноза — следствие предыдущего пункта, так как из-за отсутствия ингредиента мы не смогли получить выручку.
Потери на списаниях. Это уже следствие перепрогноза, когда мы создаём слишком большие остатки на складе. С одной стороны, мы теряем на скоропортящейся продукции, с другой — замораживаем активы в больших запасах продуктах, которые хранятся долго.
Окунёмся в историю: много ручной работы
Процесс закупок ингредиентов долгое время был головной болью многих управляющих пиццериями. В целом нельзя сказать, что у всех был какой-то единый флоу заказа: в каждой пиццерии к этому процессу подходить могли по-разному, но что точно было общего — это огромные excel-таблички, на заполнение которых уходила уйма времени. Исторически процесс заказа ингредиентов тоже развивался и можно выделить несколько стадий этого развития:
Ручные локальные выгрузки управляющих. Сколько пиццерий, столько и вариантов прогноза. Использовались всевозможные доступные данные по предыдущим продажам, ревизиям, управляющие ориентировались на собственный опыт. Трудозатраты на один такой заказ достигали нескольких часов, а учитывая частую периодичность заказа ингредиентов (раз в две недели или чаще), это превращалось в настоящий ад для тех, кто этим занимался.
 За что…
За что…
Унификация заказа и калькулятор на таблицах. Это наша попытка помочь франчайзи с заказом, унифицировать процесс и дать всем один инструмент для заказа ингредиентов. Примерная схема, которую должны были проделать в пиццерии для заполнения калькулятора:
провести инвентаризацию и выгрузить остатки,
сделать ревизию и выгрузить количество упаковок для последующего пересчёта в тару поставщика,
вручную заполнить необходимые остатки по каждому ингредиенту и вручную выбрать горизонт прогнозирования.
После выполнения всех этих действий получалась таблица с рекомендованными параметрами для заказа из среднего расчёта на день, которые управляющие могли вручную корректировать.
 Инструмент в excel для заказа ингредиентов
Инструмент в excel для заказа ингредиентов
Предрасчитанный прогноз, основанный на медианном значении расхода с возможностью ручного выбора параметров:
исторического периода, на котором рассчитывается медиана,
коэффициента роста пиццерии,
коэффициента роста на определенные дни.
Причём медиана считается отдельно на будние и выходные дни, чтобы лучше учитывать недельную сезонность. Можно сказать, что это вершина эволюции не ML-прогноза. Управляющим не надо самим учитывать расходы, списания, потери и всё остальное — достаточно зайти в настройки пиццерии, выбрать горизонт и прогноз, основанный на медианном расходе ингредиентов будет готов. Остаётся только выгрузить и отправить. Весь процесс занимает не больше 5 минут.
 Инструмент DodoIS для заказа ингредиентов
Инструмент DodoIS для заказа ингредиентов
Казалось бы, прогноз медианой уже закрывает все базовые проблемы. Но он не учитывает дополнительные факторы: долгосрочную историю продаж, праздники, маркетинговые кампании, новинки в меню и т.д. А эти штуки могут очень сильно влиять на спрос в пиццериях. Для того чтобы улучшить качество прогнозов, добавить учёт дополнительных факторов и максимально использовать все наши исторические данные мы и вписались в прогнозирование с помощью ML.
Техническое отступление
В первую очередь надо было определиться с техническими требованиями, как мы сможем определить успешность наших прогнозов. Сформулировали 2 технических ограничения: время прогнозирования и метрики качества прогноза.
Время прогнозирования
Чтобы не усложнять процесс, мы не рассматривали вариант делать прогнозы непосредственно в момент, когда управляющий их хочет получить. Для начала решили, что какой-то процесс будет запускаться по ночам раз в N дней, обсчитывать прогнозы по ингредиентам и складывать их в нужную БД, откуда DodoIS сможет их забрать.
 Схема будущего прогноза
Схема будущего прогноза
Важно, чтобы прогноз успевал считаться к началу смены в пиццериях — при наших масштабах в 600+ пиццерий в РФ это требование накладывает серьёзные ограничения.
Метрики качества прогноза
Мы хотели, чтобы ML-прогноз был лучше, чем наивный, полученный при помощи статистик.
Когда выбирали ML-метрики качества прогнозов, поняли, что какой-то одной идеальной метрики не существует. Поэтому для замера качества решили использовать:

где f — предсказание модели на ингредиент-пиццерия-период,
a — факт расхода ингредиент-пиццерия-период.
WAPE позволяет оценить как качество прогнозов отдельных ингредиентов, так и качество прогноза всех ингредиентов внутри пиццерии.

Bias используется, как компас в прогнозе, помогая понять, в какую сторону мы ошибаемся: недопрогнозируем или, наоборот, перепрогнозируем.
Бизнес-метрики: как прогноз влияет на прибыль
Помимо ML-метрик, решили начать считать бизнес-метрику, связанную с плохим прогнозом для закупок.
Оказалось, что это намного сложнее, чем мы думали. Пришлось декомпозировать задачу и выделить главные части, суммируя которые можно получить само значение метрики в деньгах.
Недополученная выручка. Здесь вариантов расчёта очень много — зависит от конкретных случаев.
Можно смотреть количество положенных пицц в корзину, которые были в стопе из-за отсутствия ингредиентов;
Можно считать среднюю выручку за какой-то последний период по продуктам, которые попали в стоп из-за их отсутствия;
Можно отдельно прогнозировать ML-моделью спрос на продукты в дни, когда по ним был стоп, и считать недополученную выручку как разность между фактическими продажами и прогнозными.
Мы выбрали второй вариант и считаем средние продажи за последние 4 недели по продуктам, в которых есть ингредиенты из стопа.
Потери от списаний. Тут всё немного проще: смотрим, какой процент закупленной партии был списан.
Сумма двух этих пунктов даёт оценку потерь от плохих прогнозов ингредиентов. Да, она не самая точная, но для первой итерации решения полностью нас устраивает. Здесь важно отметить, что процесс создания идеальной бизнес-метрики для задачи прогнозирования — бесконечный. Главное, не останавливаться в его развитии.
После сбора требований и метрик приступили к реализации.
Первая итерация как первый блин — комом
Когда мы собрали все требования и определились, что в качестве базового решения будем использовать медианный прогноз за последние 3 недели, приступили к реализации первой итерации ML-решения.
Первое, что пришло в голову — воспользоваться авторегрессионными алгоритмами для наших прогнозов: ARIMA и SARIMA, но довольно быстро стало понятно, что они очень медленно работают на Python и качество прогнозов хуже, чем наивный прогноз медианой. Отказались.
Ещё немного погуглили и решили попробовать для прогнозирования фреймворк Prophet. Плюсами такого выбора были:
работает быстрее, чем ARIMA/SARIMA (8 минут на 150 ингредиентов в пиццерии у Prophet vs 20 минут на 150 рядов у SARIMA);
можно добавлять дополнительные факторы в прогноз;
больше возможностей, чтобы настраивать параметры модели;
красивые графики, кросс-валидация и встроенные метрики;
работает с сезонностью «из коробки» (а наши данные имеют сильную недельную сезонность);
не нужно заполнять пропуски в данных.
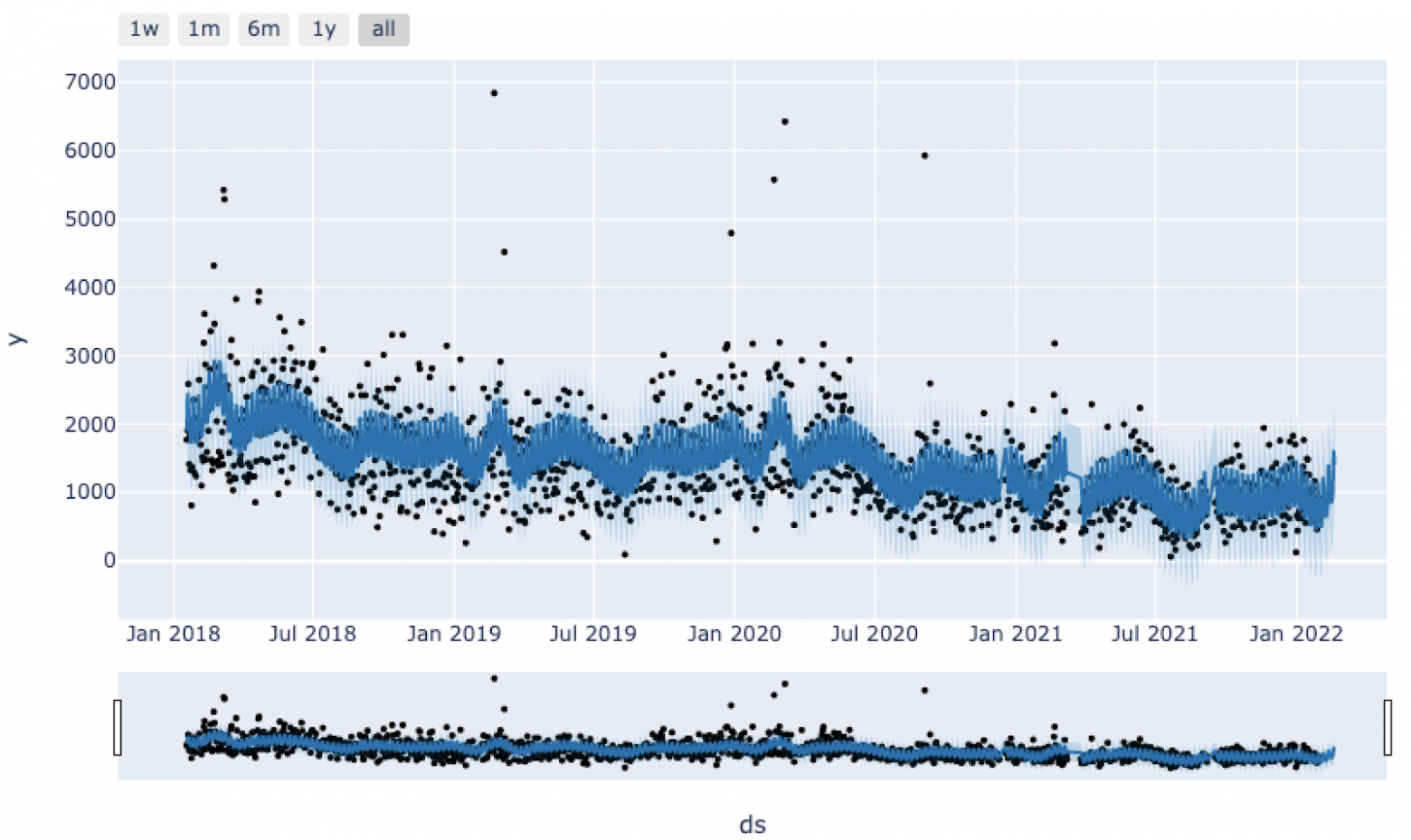 График предсказаний Prophet
График предсказаний Prophet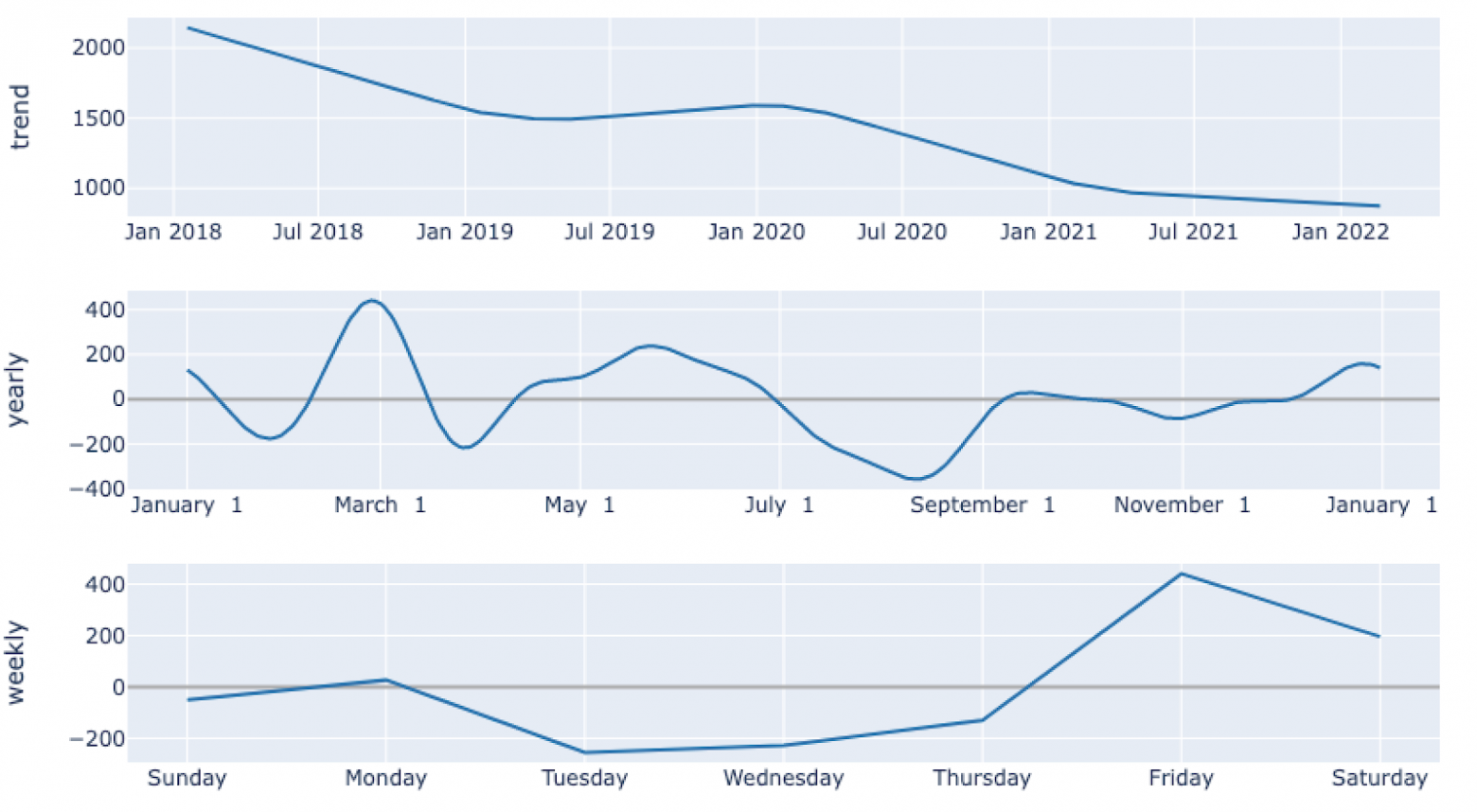 Компоненты прогноза Prophet
Компоненты прогноза Prophet
Выбрали фреймворк и сразу начали эксперименты на своей стороне, чтобы сравнить результаты двух подходов для прогноза.
Для этого зафиксировали список пиццерий, на которые собирались делать помимо базового прогноза ещё и ML-прогноз. В калькуляторе для управляющих можно выбрать горизонт — в ML-прогнозе решили не отказываться от этого и делать предсказания моделями на 21 день вперёд (это максимальный период из исторических данных по тестовым пиццериям). Для каждого ингредиента в каждой пиццерии строили свою модель.
Эксперименты постепенно усложняли:
дефолтная модель Prophet;
дефолтная модель + учёт кастомного календаря праздников;
модель с подобранными параметрами;
модель с подобранными параметрами + праздники.
Качество моделей проверяли на отложенной выборке и на кросс-валидации. В итоге оказалось, что даже стандартная модель Prophet прогнозирует примерно 30% ингредиентов не хуже, чем наивный прогноз медианой. После подбора параметров и учёта кастомного календаря праздников ML-модели оказываются лучше уже почти в половине случаев, причём на ингредиентах, где ML-решение лучше базового, прирост в качестве может достигать 5–7%.
 Сравнение прогноза ананасов медианой и Prophet
Сравнение прогноза ананасов медианой и Prophet
Но у нашего нового решения были и минусы:
Плохое качество прогнозов на коротких временных рядах (меньше 6 месяцев, эта проблема решается просто накоплением бОльшей истории наблюдений);
Невозможность работы с большим количеством рядов внутри одной модели, один ряд = одна модель;
Следствием второго пункта является долгая работа на наших объёмах данных (обучение моделей, прогноз для 50 пиццерий и примерно 150 ингредиентов в них занимали примерно 7–8 часов);
Ухудшение качества прогнозов на второй половине прогнозируемого горизонта (значит, что первые 8–10 дней прогнозируются с устраивающим нас качеством, но после 10 дня качество снижается, следовательно, при закупках на горизонт более 10 дней можно попасть на долгий стоп из-за отсутствия каких-то ингредиентов).
Несмотря на эти проблемы, первое решение на Prophet нас устроило и мы затащили его в прод, но без прогнозирования коротких временных рядов. Для 56 прогрессивных пиццерий мы добавили фича-тогл, чтобы управляющие сами могли выбирать, каким прогнозом пользоваться.
 Схема прогноза с Prophet
Схема прогноза с Prophet
Мы запустили первую итерацию прогноза на основе ML-моделей и она помогла закрыть проблемы с прогнозированием, но при попытке масштабирования на дополнительные пиццерии мы поняли, что процесс будет долгим и сложным.
Эволюция: градиентный бустинг
Нужно было придумывать какое-то другое решение. Я нашёл пару докладов (раз, два), в которых рассказывали про прогнозирование с использованием алгоритма градиентного бустинга. Он строит предсказание в виде ансамбля слабых предсказывающих моделей, которыми в основном являются деревья решений. Каждое следующее дерево старается уменьшить ошибку предыдущих. Да, кажется, что это сложнее, чем гонять Prophet, ведь нужно будет самим работать с фичами, заполнениями пропусков, аномалями в рядах. Но зато эта работа позволит по-разному группировать временные ряды, использовать одну модель на несколько пиццерий/ингредиентов и это решение уже можно будет масштабировать на большее количество пиццерий.
Сказано — сделано! Так мы и начали разрабатывать свой пайплайн прогнозирования с градиентным бустингом в качестве ML-модели.
Первым этапом решили реализовать все вспомогательные процессы: заполнение пропусков в таргете, работу с аномалиями, пайплайн расчёта фичей, ну и правильную валидацию моделей, чтобы не выкатить что-то неудачное.
Бустинг — это регрессионная модель, поэтому признаки для последующих предсказаний надо генерировать самим. Для начала решили реализовать расчёт всех стандартных фичей: лаги, скользящие статистики, временные фичи и тд. Во время реализации совершенно случайно наткнулись на фреймворк ребят из Тинькофф ETNA и поняли, что изобретать свой велосипед не стоит, лучше воспользоваться готовым решением.
Когда головная боль фича-инжиниринга, валидации, работы с пропусками и аномалиями была снята с помощью ETNA, у нас освободилось много времени на эксперименты с применением разных схем прогнозов.
Начали с простого: реализовали на ETNA пайплайн, как у Prophet, но только с бустингами. Один ингредиент в одной пиццерии — одна модель. На валидации этот подход уже начал обходить наш прогноз на Prophet. Дальше наступило время проверки следующих гипотез: одна модель — одна пиццерия, одна модель — один ингредиент. В этом сравнении уже победила одна модель на пиццерию.
Тут надо отметить, что использование бустингов с фичами позволило улучшить качество прогнозирования временных рядов длиной от 2 до 6 месяцев, но с совсем новыми рядами всё равно остались проблемы. Было очевидно, что закрыть весь прогноз каким-то одним алгоритмом не получится, поэтому мы стали двигать наши эксперименты в другую плоскость: разделять ряды по длине и схожести и прогнозировать их разными моделями.
Так как лучше всего себя показал подход с прогнозированием всех ингредиентов внутри одной пиццерии одной моделью, решили попробовать внутри одной пиццерии оставлять не все ингредиенты, а только самые похожие. Так в нашем проекте появилась кластеризация ингредиентов.
Подход простой: находим похожие кластеры временных рядов внутри одной пиццерии и предсказываем их расходы одной моделью. Оказалось, что это отлично работает и улучшает WAPE по сравнению с моделью Prophet на 5–7%. А по времени такое решение, основанное на бустинге, работает в несколько раз быстрее, так как количество моделей снижается.
 Сравнение прогноза ананасов медианой, Prophet и ETNA
Сравнение прогноза ананасов медианой, Prophet и ETNA
В конечном итоге мы остановились на таком пайплайне: для коротких рядов (короче двух месяцев) мы отдаём наивный прогноз медианой, для остальных рядов для каждой пиццерии проводим кластеризацию и обучаем свою модель для каждого кластера. Тесты показали, что при таком раскладе обсчет 600 пиццерий занимает 6.5 часов, что нас очень даже устраивает.
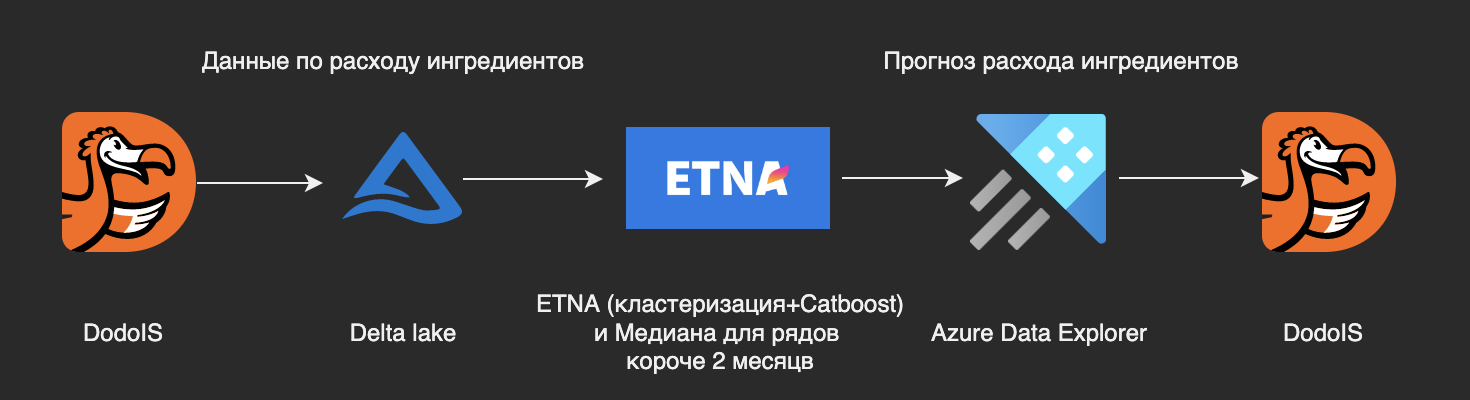 Схема прогноза с ETNA
Схема прогноза с ETNA
Немножко про факапы — как без них
Во время запуска решения на ETNA совершенно случайно обнаружили интересный кейс, который мог стоить нам много тысяч рублей: из-за наших косяков в предварительной фильтрации данных короткие временные ряды тоже прогнозировались бустингом, хотя должны были прогнозироваться медианой.
Из-за проблем бустингов с экстраполяцией в пайплайне прогноза мы сначала убираем тренд из данных, бустингом предсказываем ряд без тренда и потом отдельно прогнозируем тренд линейной моделью. Так вот, для временного ряда чиабатты мы предсказали такой восходящий тренд, что начиная с 10 дня прогноза у нас получался расход чиабатты в 100К штук. Такое же обнаружили и по некоторым другим рядам. Но вовремя успели пофиксить и ошибка не сказалась на работе и закупке пиццерий.
Итоги и выводы
В конце хотелось бы подвести небольшой итог по всему, что было сделано и дать несколько рекомендаций тем, кто с нуля залетает в какое-то прогнозирование в 2022 году.
Про ARIMA/SARIMA нам сказать особо нечего, но если они заходят у вас в задачах, то напишите в комментариях, может, мы тоже вернёмся к экспериментам с этими алгоритмами.
Prophet хорош, если у вас не очень много рядов, но в них присутствует большая историчность, а также есть сильный заметный тренд и сезонность.
Ещё одним достоинством Prophet является возможность простой работы «из коробки». Это значит, что проводить эксперименты можно быстро и просто;
Лично у нас Prophet оказался слаб на коротких рядах, но, возможно, в вашем случае стоит попробовать.
Если рядов очень много, историчность у них разная, хочется уметь по-разному группировать ряды, то вам, конечно, в ETNA. За счёт большого количества разных обёрток над другими моделями этот вариант устроит, наверное, почти всех.
Что касается нас, в данный момент прогноз внедрили, но пока его использование добровольное. Добровольцев у нас уже почти 200 пиццерий, хотя считаем прогноз на всю сеть, следим за качеством и готовимся активнее продвигать наше решение. Впереди ещё много работы: масштабирование прогноза на другие страны и другие бизнесы, добавление дополнительных факторов в прогноз от самих управляющих и т.д. Но кажется, что для начала получилось совсем неплохо.
