Боремся с нагрузками в HPE Vertica
В HPE Vertica для планирования работы сервера под нагрузками разработан специальный механизм, под названием «ресурсные пулы». Идея его в том, что каждый пользователь сервера работает в рамках выделенного ресурсного пула, который регулирует приоритетность доступа к ресурсам кластера, ограничивает конкурентность выполнения запросов и описывает правила резервирования и работы с памятью сервера.
По умолчанию после установки сервера Vertica на созданной базе данных это выглядит примерно так:

На каждом сервере (ноде) кластера доступная для Vertica память обозначается, как ресурсный пул General. Для различных нужд сервера автоматически создаются служебные пулы, которые отрезают от General для себя кусочки памяти:
- WOS — для хранения в области памяти порционно вставляемых данных
- TM — для фонового служебного процесса Tuple Mover, выполняющего moveoute и mergeout операции
- Прочие служебные — Vertica имеет дополнительные ресурсные пулы для проведения операций восстановления нод кластера, построения проекций, выполнения служебных запросов и т.д.
По умолчанию пользователи сервера крутятся под управлением самого пула General. Можно посмотреть его текущие настройки:
dbadmin=> SELECT * FROM resource_pools WHERE name = 'general';
-[ RECORD 1 ]------------+------------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 00:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |Расшифрую некоторые параметры:
- memorysize — размер зарезервированной памяти пула, этот размер отрезается от пула General, уменьшая его размер доступной памяти, для General соответственно не указывается.
- maxmemorysize — максимально разрешенный размер использования памяти пулом. В случае использования пулом памяти, более указанной memorysize, недостающая память временно забирается из пула General, если там есть конечно что забирать.
- plannedconcurrency — делитель для установки размера памяти, выделяемой сессии при старте запроса в пуле, в данном случае для пула General maxmemorysize: 30 гб делить 10 plannedconcurrency = каждой сессии при старте выделяется 3 гб памяти пула, что мягко говоря жирновато.
- maxconcurrency — максимальное количество выполняемых на пуле конкурентных сессий.
Такие «дефолтные» настройки дают фактически 100% гарантию тормозов работы Vertica:
- 10 сессий запускает выполнение запросов
- каждой сессии выделяется по 3 гб памяти пула, даже если столько и не нужно
- Если сессии еще не успели отработать и новые сессии запустили еще запросы, то вместо памяти из 30 гб они получают работу в свапе
- Если какая-то сессия в ходе работ съела всю память пула, то другие сессии так же оказываются в свапе
Давайте поможем «горю»:
ALTER RESOURCE POOL general PLANNEDCONCURRENCY 20 MAXCONCURRENCY 10;Теперь каждой сессии при старте запроса в пуле выделяется 0.5 гб, а всего одновременно может выполнятся не более 10 сессий. При старте 10 сессий будет израсходовано 5 гб памяти пула, еще 25 гб останется как резерв для отдачи памяти тяжелым запросам и другим ресурсным пулам.
Хочу обратить внимание на параметр MAXCONCURRENCY — чем он ниже, тем быстрее будут работать ваши запросы. У каждой аппаратной части есть предел нагрузок, при превышении которого все «встает колом». Чем выше конкурентность, тем больше нагрузка на процессоры и дисковые массивы, тем ниже их скорость работы. Эффективнее выполнить 10 запросов и далее с очереди выполнить следующие 10 запросов, чем пытаться выполнить одновременно 20 запросов. Естественно, MAXCONCURRENCY будет в первую очередь зависеть от поставленных для решения задач пула и от характеристик железа кластера, Ваша задача выявить пределы и выставить его чуть ниже пределов, чтобы в случае пиковых нагрузок одновременного выполнения множества тяжелых запросов, кластер вдруг не затормозил для всех его пользователей.
Так что же с пулами? Пока мы только настроили General, однако держать в нем пользователей на самом деле дурная практика. Давайте сделаем типовые пулы по группам задач пользователей:
-- Пул для писателей
CREATE RESOURCE POOL writers
MEMORYSIZE '2G'
MAXMEMORYSIZE '10G'
PLANNEDCONCURRENCY 10
MAXCONCURRENCY 10
PRIORITY -50
RUNTIMECAP '3 MINUTE'
RUNTIMEPRIORITYTHRESHOLD 0;
-- Пул для тяжелых длинных запросов
CREATE RESOURCE POOL slowly
MEMORYSIZE '0%'
MAXMEMORYSIZE '20G'
MAXCONCURRENCY 7
RUNTIMEPRIORITY LOW
QUEUETIMEOUT '15 MINUTE'
RUNTIMEPRIORITYTHRESHOLD 0;
-- Пул для читателей
CREATE RESOURCE POOL readers
MEMORYSIZE '4G'
MAXMEMORYSIZE '10G'
PLANNEDCONCURRENCY 20
MAXCONCURRENCY 10
RUNTIMECAP '5 MINUTE'
PRIORITY 50
RUNTIMEPRIORITYTHRESHOLD 3
CASCADE TO slowly;General теперь у нас «похудел»:
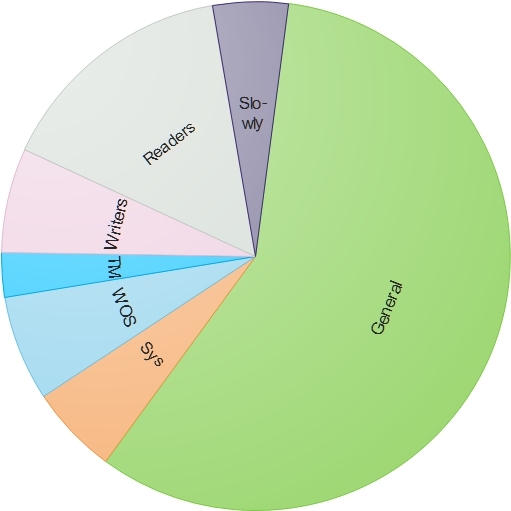
Что мы сделали:
- Раскидали по группам сессии пищушие, читающие и выполняющие длинные тяжелые запросы.
- Выделили начальную память пулам читателей и писателей, чтобы для большинства коротких запросов память бралась сразу из резервированной для пула без подкачки с General.
- Не стали выделять память пулу тяжелых запросов, все равно его сессии захотят много памяти и резервировать для них, отрезая драгоценную память из General, смысла нет, зато этому пулу разрешили забирать до 20 гб памяти от General в случае необходимости.
- Выставили для пула тяжелых запросов пониженный приоритет выполнения LOW.
- Для пула писателей и читателей выставили приоритет доступа к ресурсам так, чтобы по приоритету выполнения MEDIUM пул писателей был аутсайдером (-50 приоритет), пул General был посередине (нулевой приоритет) и пул для читателей был выше этих пулов (50 приоритет).
- Рационально выставили значения конкурентности пулам, где одновременно могут выполняться 10 запросов писателей, 10 запросов читателей и 7 тяжелых запросов.
- Для ситуаций, когда пользователь запустил тяжелый запрос в пуле читателей, который длиться более 5 минут, указали перевод каскадом таких запросов на пул тяжелых запросов. Это гарантирует, что пул читателей не просядет при выполнении на нем длинных запросов, которые забьют слоты выполнения конкурентов и замедлят конвеер выполнения из очереди быстрых запросов. Для пула писателей выставили ограничения выполнения запросов не более 3 минут, чтобы неоптимизированные запросы вставки или обновления данных сшибались.
- Для пула тяжелых запросов выставили время ожидания в очереди 15 минут. Если все конкурирующие слоты у пула заняты, то после 15 минут ожидания, стоящие в очереди запросы будут прекращены с ошибкой. Это даст понять пользователям, что сервер не висит, а просто в рамках их пула все занято.
- Для пула читателей выставили время в 3 секунды, в течении которых запрос после запуска имеет наивысший приоритет по ресурсам. Это позволит быстро выполнять короткие запросы, освобождая место в пуле для других запросов
Теперь назначаем пользователям нужные пулы и дело сделано:
ALTER USER user_writer RESOURCE POOL writers;
ALTER USER user_reader RESOURCE POOL readers;
ALTER USER user_analytical RESOURCE POOL slowly RUNTIMECAP '1 HOUR' TEMPSPACECAP '10G';Здесь мы дополнительно, помимо пула, пользователю «user_analytical» ограничили для запросов время выполнения одним часом и разрешили использовать не более 10 гб пространства в TEMP.
Хочу заметить, что все вышеописанное в статье является действием «куда копать», а не примером «что настроить». Сколько и каких будет ресурсных пулов, с какими характеристиками — это все должны решить Вы сами. Можно начать с малого — создать по примеру подобные 3 пула и дальше смотреть по нагрузкам кластера, постепенно балансируя параметры пулов и выделяя группы пользователей по разным пулам. Главное помнить, что:
- Пул General является общим кладезем памяти для всех пулов и лучше его не использовать напрямую для работы пользовательских сессий
- Чем меньше конкурентов, тем меньше скорость проседания железа в пиковых нагрузках
- Сумма максимально разрешенной памяти всех пулов не должна перекрывать память General
