[Перевод] Как работает стриминг Netflix
«Если вы можете кэшировать всё очень эффективным способом, то вы часто можете изменить правила игры»
Мы, разработчики программного обеспечения, часто сталкиваемся с проблемами, требующими распространения некоторого набора данных, который не соответствует названию «большие данные». Примерами проблем такого типа являются следующие:
- Метаданные продукта в интернет-магазине
- Метаданные документа в поисковой машине
- Метаданные фильмов и ТВ-шоу
Сталкиваясь с этим, мы обычно выбираем один из двух путей:
- Хранение этих данных в каком-то централизованном хранилище (например, реляционная СУБД, информационный склад NoSQL или кластер memcached) для удалённого доступа пользователей
- Сериализация (например, как json, XML и т.д.) и распространение среди потребителей, которые будут хранить локальную копию
Применение каждого из этих подходов имеет свои проблемы. Централизация данных может позволить вашему набору данных неограниченно расти, однако:
- Имеют место задержки и ограничения по полосе пропускания при взаимодействии с этими данными
- Удалённый информационный склад не может сравниться по надёжности с локальной копией данных
С другой стороны, сериализация и сохранение локальной копии данных полностью в ОЗУ может обеспечить на порядки меньшее время задержки и более высокую частоту доступа, однако и этот подход несёт с собой проблемы, связанные с масштабированием, которые становятся более комплексными по мере увеличения набора данных:
- Объём динамической памяти, занимаемой набором данных, растёт
- Получение набора данных требует загрузки дополнительных битов
- Обновление набора данных может потребовать значительных ресурсов ЦП или влиять на работу автоматического управления памятью
Разработчики часто выбирают гибридный подход — кешируют локально данные с частым доступом и используют удалённо — с редким. Такой подход имеет свои проблемы:
- Управление структурами данных может потребовать значительного количества динамической кэш-памяти
- Объекты часто хранятся довольно долго, чтобы их можно было распространять, и отрицательно влияют на работу автоматического управления памятью
В Netflix мы осознали, что такой гибридный подход часто создаёт лишь иллюзию выигрыша. Размер локального кэша часто является результатом тщательного поиска компромисса между задержкой при дистанционном доступе для многих записей и требованием к хранилищу (хипу) при локальном хранении большего количества данных. Но если вы можете кэшировать всё очень эффективным способом, то вы часто можете изменить игру — и держать весь набор данных в памяти, используя хип меньшего размера и меньше загружая ЦП, чем при хранении лишь части этого набора. И здесь вступает в действие Hollow — последний проект с открытым исходным кодом от Netflix.

Hollow представляет собой Java-библиотеку и всеобъемлющий набор инструментов для использования расположенных в оперативной памяти наборов данных малого и среднего размера, которые распространяются от одного производителя ко многим потребителям с доступом только для чтения.
«Hollow изменяет подход… Наборы данных, для которых ранее такую возможность никогда нельзя было даже рассматривать, теперь могут быть кандидатами для Hollow.»
Функционирование
Hollow сосредоточен исключительно на своём предписанном наборе проблем: хранение цельного набора данных «только для чтения» в оперативной памяти потребителей. Он преодолевает последствия обновления и выгрузки данных из частичного кэша.
Благодаря своим рабочим характеристикам Hollow изменяет подход с позиции размеров соответствующих наборов данных для решения при помощи оперативной памяти. Наборы данных, для которых ранее такую возможность никогда нельзя было даже рассматривать, теперь могут быть кандидатами для Hollow. Например, Hollow может быть полностью приемлемым для наборов данных, которые, если представлять их в json или XML, потребовали бы более 100 Гб.
Быстрота адаптации
Hollow не просто улучшает функционирование — этот пакет значительно усиливает быстроту адаптации команды при работе с задачами, связанными с наборами данных.
Использование Hollow является простым прямо с первого шага. Hollow автоматически создаёт пользовательский API, базирующийся на специфической модели данных, благодаря чему пользователи могут интуитивно взаимодействовать с данными, пользуясь преимуществами выполнения IDE-кода.
Но серьёзный выигрыш возникает при использовании Hollow на постоянной основе. Если ваши данные постоянно находятся в Hollow, то появляется много возможностей. Представьте, что вы можете быстро пройти весь производственный набор данных — текущий или из любой точки в недавнем прошлом, вплоть до локальной рабочей станции разработки: загрузить его, а затем точно воспроизвести определённые производственные сценарии.
Выбор Hollow даст вам преимущество на инструментарии; Hollow поставляется с множеством готовых утилит, чтобы обеспечить понимание ваших наборов данных и обращение с ними.
Устойчивость
Сколько девяток надёжности вы хотели бы иметь? Три, четыре, пять? Девять? Будучи локальным хранилищем данных в оперативной памяти, Hollow не подвержен проблемам, связанным с окружающей средой, в том числе с сетевыми сбоями, неисправностями дисков, помехам от соседей в централизованном хранилище данных и т.д. Если ваш производитель данных выходит из строя или ваш потребитель не может подключиться к хранилищу данных, то вы можете работать с устаревшими данными —, но данные будут по-прежнему присутствовать, а ваш сервис будет по-прежнему работать.
Hollow был доработан в течение более чем двух лет непрерывной жёсткой эксплуатации на Netflix. Мы используем его для предоставления важных наборов данных, необходимых для выполнения взаимодействия в Netflix, на серверах, быстро обслуживающих в реальном времени запросы клиентов при максимальной производительности или близко к ней. Несмотря на то, что Hollow затрачивает громадные усилия, чтобы выжать каждый последний бит производительности из аппаратных средств серверов, огромное внимание к деталям стало частью укрепления этой критической части нашей инфраструктуры.
Источник
Три года назад мы анонсировали Zeno — наше действующее в настоящее время решение в этой области. Hollow заменяет Zeno, но является во многом его духовным преемником.
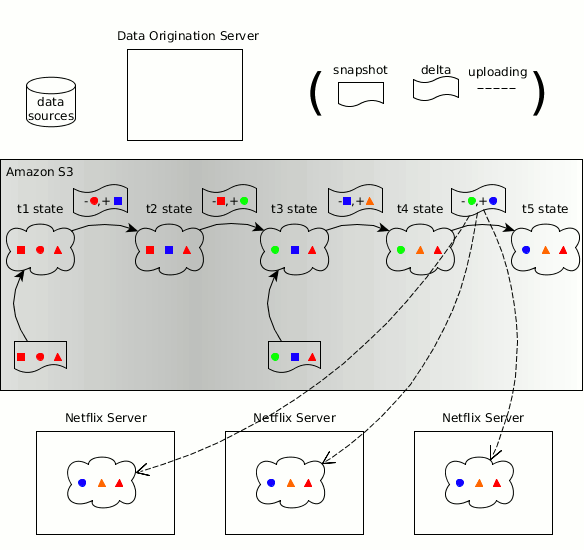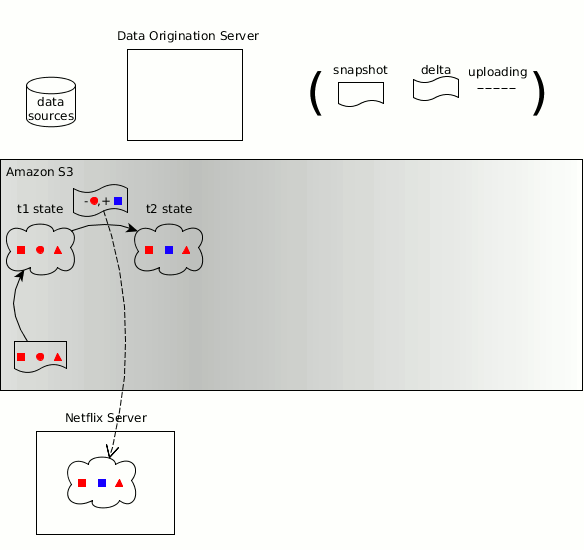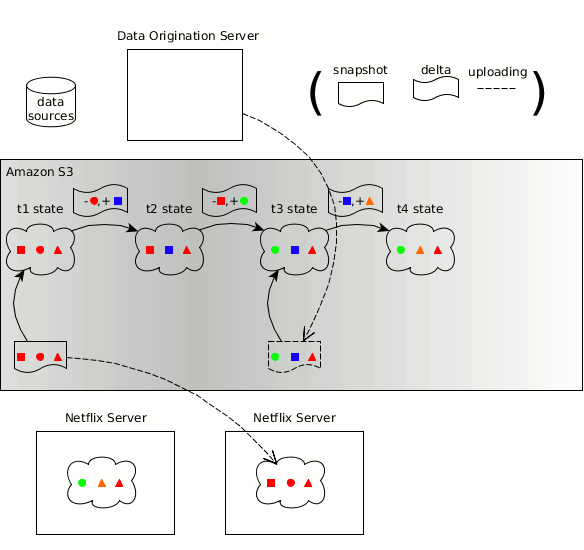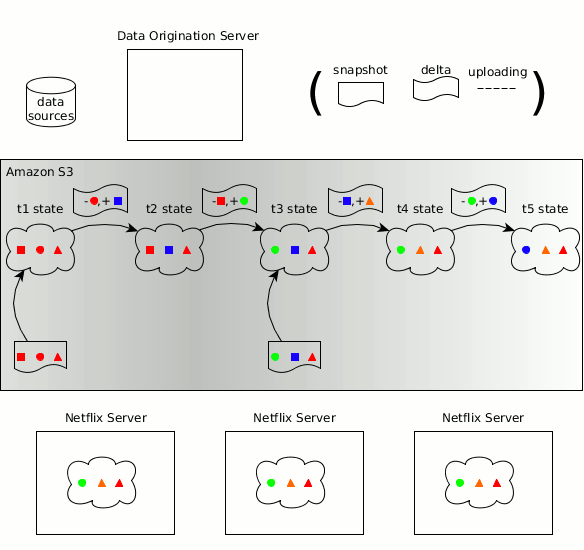
Концепции Zeno в отношении производителя, потребителей, состояния данных, копий состояния объекта и изменений состояния перешли в Hollow
Как и прежде, временная последовательность изменяющегося набора данных может быть разбита на дискретные состояния данных, каждое из которых представляет собой полную копию состояния данных на определённый момент времени. Hollow автоматически определяет изменение состояний — усилие, требуемое от пользователя на поддержание обновлённого состояния, является минимальным. Hollow автоматически дедуплицирует данные, чтобы минимизировать объём динамической памяти наших наборов данных у потребителей.
Развитие
Hollow берёт эти концепции и развивает их, улучшая почти каждый аспект решения.
Hollow избегает использовать POJOs как представление в оперативной памяти — взамен заменяет их компактным, с фиксированной длиной, сильно типизированным шифрованием данных. Такое шифрование предназначено как для минимизации объёма динамической памяти наборов данных, так и для снижения доли стоимости, связанной с ЦП, при обеспечении доступа к данным в реальном времени. Все зашифрованные записи упакованы в повторно используемые блоки памяти, которые располагаются в JVM-хипе, чтобы предотвратить воздействие на работу автоматического управления памятью на работающих серверах.

Пример расположения в памяти записей типа OBJECT
Наборы данных в Hollow являются самодостаточными — для сериализированного блоба, чтобы этот блоб мог бы быть использован фреймворком, не требуется сопровождение из кода, специфического для варианта использования. Дополнительно Hollow разработан с обратной совместимостью, благодаря чему развёртывание может происходить реже.
«Возможность построения мощных систем доступа, независимо от того, предполагались ли они изначально при разработке модели данных.»
Поскольку Hollow полностью построен на оперативной памяти, то инструментарий может быть реализован при условии, что произвольный доступ по всей ширине набора данных может быть выполнен, не выходя из Java-хипа. Множество готовых инструментов входит в состав Hollow, а создание ваших собственных инструментов благодаря базовым компоновочным блокам, предоставляемым библиотекой, является несложным делом.
Основой использования Hollow является концепция индексирования данных различными способами. Это обеспечивает O (1)-доступ к соответствующим записям в данных, что даёт возможность построения мощных систем доступа независимо от того, предполагались ли они изначально при разработке модели данных.
Преимущества
Инструментарий Hollow легко установить и он имеет интуитивно понятное управление. Вы сможете понять в ваших данных некоторые аспекты, о которых вы и не подозревали.

Инструмент отслеживания изменений позволяет проследить изменение определённых записей во времени
Hollow может усилить ваши возможности. Если что-то в какой-то записи кажется неправильным, то можно точно выяснить, что и когда случилось, используя простой запрос в инструмент отслеживания изменений. Если происходит авария и случайно происходит выпуск ненадлежащего набора данных, то ваш набор данных можно откатить назад к тому, который был перед возникновением ошибки, зафиксировав производственные проблемы на их путях. Поскольку переход между состояниями происходит быстро, то это действие может дать результат на всём парке машин уже через несколько секунд.
«Если ваши данные постоянно находятся в Hollow, то появляется много возможностей.»
Hollow проявил себя как чрезвычайно полезное средство на Netflix — мы увидели повсеместное уменьшение времени запуска серверов и снижение занимаемого объёма динамической памяти при постоянно возрастающей потребности в метаданных. Благодаря целенаправленным усилиям по моделированию данных, осуществляемым по результатам детального анализа использования динамической памяти, который стал возможным с появлением Hollow, мы сможем и дальше улучшать показатели.
В дополнение к выигрышу в качестве функционирования мы видим огромный прирост производительности, связанный с распространением наших каталожных данных. Это объясняется отчасти тем инструментарием, который имеется в Hollow, а отчасти той архитектурой, которая была бы невозможна без него.
Заключение
Везде, где мы видим проблему, мы видим, что она может быть решена при помощи Hollow. Сегодня Hollow доступен для использования всему миру.
Hollow не предназначен для работы с наборами данных любого размера. Если данных достаточно много, то сохранение всего набора данных в памяти не представляется возможным. Однако при использовании надлежащей структуры и некоторого моделирования данных этот порог может быть намного выше, чем вы думаете.
Документация имеется на http://hollow.how, а код — на GitHub. Мы рекомендуем обратиться к краткому руководству — потребуется лишь несколько минут, чтобы просмотреть деморолик и увидеть работу, а ознакомление с полностью промышленной реализацией Hollow требует примерно час. После этого можно подключить вашу модель данных и — вперёд.
Если вы начали работать, то можно получить помощь непосредственно от нас или от других пользователей через Gitter или Stack Overflow, поместив метку «hollow».
