Большая версия ruDALL-E, или Как отличить Кандинского от Малевича

Прошло около полугода с момента выхода базовой модели ruDALL-E XL (1.3B), мы — команды Sber AI и SberDevices — получили много лайков и, как подобается таким разработкам, дизлайков. Всё хорошее отразилось в гигантском наплыве пользователей в первые недели релиза: порядка 800 тыс. уникальных пользователей (на текущий момент уже более 2 млн), — 1.2 тыс. ⭐ в репозитории и последующем изрядном списке фантастических файнтюнов (Emojich XL, Surrealist XL, генератор кроссовок, генератор покемонов). Но если читатель обратится к прошлой статье, то обязательно вспомнит, что в ней речь шла о двух версиях модели: XL (1.3B) и XXL (12B). На тот момент похвастаться действительно впечатляющими результатами большой модели мы не могли, поэтому, сделав релиз текущего на тот момент чекпоинта XXL на SberCloud, продолжили заниматься сбором данных и дообучением модели. И вот, наконец, мы готовы вывести её в свет.
Оценить способности новой большой модели Kandinsky можно в:
Мы назвали нашу самую большую на данный момент генеративную модель в честь Василия Кандинского — и расскажем историю модели Kandinsky (уделив внимание наборам данных и метрикам качества) в нескольких разделах, вдохновлённых картинами этого русского художника, стоявшего у истоков абстракционизма. Ну и, конечно, не оставим вас без крутейших cherry-pick изображений от файнтюна модели Kandinsky. Вот тизер того, что вас ждет в конце статьи:
 Запрос: «Холст картина маслом горы радуга инопланетный пейзаж бежевый фон», ruDALL-E Kandinsky
Запрос: «Холст картина маслом горы радуга инопланетный пейзаж бежевый фон», ruDALL-E Kandinsky
Кроме того, с момента последнего релиза 2 ноября 2021 года нам удалось доучить предыдущую модель, ruDALL-E XL, еще на 119 млн уникальных парах «изображение-текст». Чекпоинт этой версии модели можно скачать тут.
Картина 1: «Пёстрая жизнь», или Что нового произошло в мире генеративного AI
 Запрос: «Пёстрая жизнь», ruDALL-E Kandinsky
Запрос: «Пёстрая жизнь», ruDALL-E Kandinsky
Буквально несколько лет назад, когда речь шла о временном промежутке около полугода, было не так просто сделать насыщенный обзор новых решений и архитектур, появившихся за столь короткий промежуток времени. Но вот в 2022 году такой проблемы просто не существует. Новые методы и модели публикуются настолько часто, что даже самый пытливый и интересующийся читатель многочисленных новостных каналов в области DL наверняка что-нибудь пропустит. Поэтому в этой части мы вовсе не претендуем на полноту обзора, а лишь хотим показать формирующиеся тренды в области генеративного AI.
Вышедшие модели можно условно разделить на две категории. Первые представляют собой мультимодальные мультизадачные архитектуры, которые призваны решать open-ended текстовые задачи (Flamingo, OFA). Данные архитектуры построены на базе сильных языковых моделей, умеют работать с разными входными модальностями (текст, изображения, видео) и решают такие задачи как Question Answering, Visual Question Answering, Visual Commonsense Reasoning и другие. По заверениям авторов, большинство монозадачных state-of-the-art моделей проигрывают им в качестве. Вторая категория моделей представляет в нашем случае куда больший интерес, потому что на выходе позволяет генерировать изображения. В этой группе наиболее значимые результаты принадлежат таким моделям как GLIDE, DALL-E 2 от OpenAI и свежайшей Imagen от Google. В основе указанных моделей лежит диффузионный процесс, который обещает стать новым трендом визуального генеративного AI: результаты генерации действительно впечатляют и порождают предсказания о трансформации профессий художника и дизайнера в ближайшем будущем.
 Запрос: «Oriental painting of tigers wearing VR headsets during the Song dynasty» («Ориентальная картина с тиграми в очках виртуальной реальности времен династии Сун»), слева Imagen, справа — DALL-E 2
Источник: https://twitter.com/hardmaru/status/1532757753797586944
Запрос: «Oriental painting of tigers wearing VR headsets during the Song dynasty» («Ориентальная картина с тиграми в очках виртуальной реальности времен династии Сун»), слева Imagen, справа — DALL-E 2
Источник: https://twitter.com/hardmaru/status/1532757753797586944
В DALL-E 2 происходит «распаковка» эмбеддингов CLIP (не зря в статье авторы называют архитектуру «unCLIP»): текстовый эмбеддинг, полученный с помощью текстового энкодера предварительно обученной модели CLIP, скармливается модели-приору (авторегрессионной или диффузионной); на выходе получаются возможные картиночные эмбеддинги CLIP, соответствующие описанию, — остаётся только прогнать их через диффузионный декодер, чтобы получить финальное изображение. Авторы же Imagen в качестве текстового энкодера берут замороженную T5-XXL — сильную языковую модель — и последовательность эмбеддингов, полученных с её помощью, пропускают через каскад диффузионных моделей: разрешение изображения, восстановленного из текстовых эмбеддингов, во время этого процесса подрастает с 64×64 до 1024×1024. Архитектура этого каскада — улучшенная версия UNet, которую авторы назвали Efficient-UNet (она проще, быстрее сходится и более эффективна с точки зрения вычислительных ресурсов).Если верить авторам, Imagen обгоняет DALL-E 2 по FID на COCO 256×256 30k: 7,27 у Imagen vs 10,39 у DALL-E 2. Что сразу становится очевидным, так это то, что модель от Google лучше справляется с генерацией текста на изображении, не путается в цветах объектов и в принципе точнее понимает запрос, чем DALL-E 2 (явно T5-XXL демонстрирует свою мудрость).
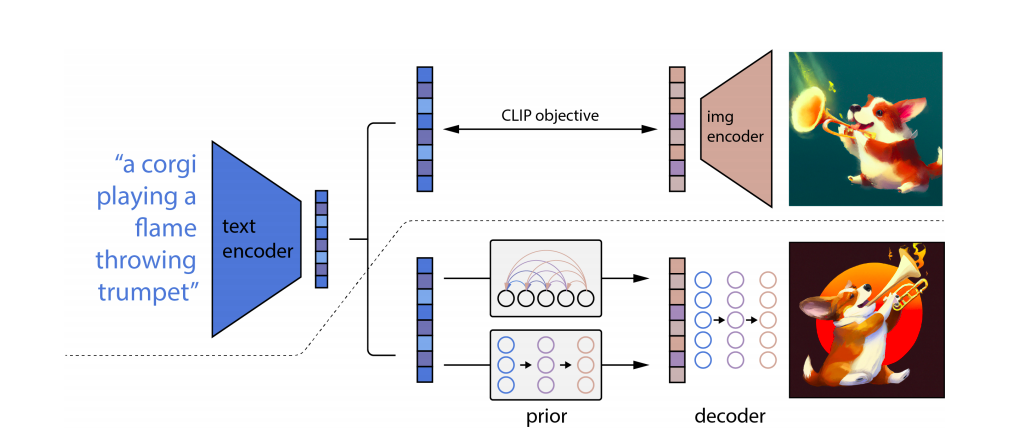 Запрос: «Корги, играющая на пламенеющем тромбоне»
Источник: https://cdn.openai.com/papers/dall-e-2.pdf
Запрос: «Корги, играющая на пламенеющем тромбоне»
Источник: https://cdn.openai.com/papers/dall-e-2.pdf
Картина 2: «Развитие», или Как появился наш самый большой нейрохудожник
 Запрос: «Развитие», ruDALL-E Kandinsky
Запрос: «Развитие», ruDALL-E Kandinsky
Архитектура
С точки зрения архитектуры и генеративного подхода модель Kandinsky практически ничем не отличается от модели ruDALL-E XL, разве что добавлено больше слоёв и увеличена размерность скрытого пространства (детали можно увидеть в таблице) — модель совместима с кодовой базой ruDALL-E XL и так же использует в качестве энкодера и декодера изображений Sber-VQ-GAN, а YTTM — в качестве токенизатора текстовых последовательностей.
Params | Layers | Hidden Size | Num Attention Heads | Optimizer | |
ruDALL-E XL | 1.3B | 24 | 2048 | 16 | AdamW |
Kandinsky | 12B | 64 | 3840 | 60 | AdamW-8bit-bnb + deepspeed zero3 |
Таким образом, модель Kandinsky всем уже хорошо знакома. В её основе лежит трансформер, который работает с последовательностью токенов, формируемой с помощью двух энкодеров: визуального и текстового. Общая идея состоит в том, чтобы вычислить эмбеддинг по входным данным с помощью энкодера, а затем с учётом известного выхода правильным образом декодировать этот эмбеддинг. Напомним кратко про использованные энкодеры:
Предварительно уменьшенные изображения с разрешением 256×256 поступают на вход автоэнкодера (SBER VQ-GAN), который учится сжимать изображение в матрицу токенов 32×32.
Токенизация текстового описания (всего у ruDALL-E 128 текстовых токенов) выполняется с помощью YTTM со словарем в 16384 токена.
Мы уже писали в прошлой статье на Хабре, что в 2021 г. столкнулись с проблемой расхождения модели Kandinsky в режиме FP16 из-за её глубины — на данный момент генерация доступна только в режиме FP32. Мы ценим вклад в развитие проекта и будем рады новым идеям в официальном репозитории.
Данные
Безусловно, нельзя обсуждать процесс обучения без описания данных, на которых он строится. Для первой и второй фаз обучения мы использовали разные наборы данных: на первом этапе использовалась та же выборка, что и для обучения модели ruDALL-E XL; основа второго этапа — русскоязычная часть датасета LAION-5B, которая включает в себя порядка 170 млн пар изображений и описаний к ним. И хотя качество исходных данных достаточно хорошее (авторы провели фильтрацию с помощью модели CLIP), мы разработали дополнительный набор фильтров, чтобы избавиться от изображений с водяными знаками, скриншотов презентаций, сайтов и прочих нежелательных данных. Фильтрацию проводили с помощью классификатора изображений с водяными знаками, который был обучен нами на открытых наборах данных, и модели ruCLIP. Также мы почистили текстовые описания изображений: убрали словосочетания, которые не несли смысловой нагрузки, но добавили бы модели трудностей в поиске закономерностей. В результате фильтрации мы получили датасет размером 119 млн. Примеры отфильтрованных изображений можно увидеть ниже.

А вот примеры фильтрации текстовых описаний, выполненной с помощью набора регулярных выражений:
Оригинальное описание | Исправленное описание |
Подвесной уличный светильник Oasis Light 88170/3 Bl чёрный | подвесной уличный светильник чёрный |
Курортный спа-отель Golden Palace — фото 4 | курортный спа-отель |
Купить Стол обеденный Coleart Tavoli 07218 | стол обеденный |
Учебный альбом из 25 листов. Арт. 5–8692–025. | учебный альбом из 25 листов |
Светодиодные настольные часы DS-3618L купить в минске | светодиодные настольные часы |
«Воздушные шары »8 марта» — фото 5» | воздушные шары 8 марта |
Старые исторические здания в Майнце, Германии стоковое изображение | старые исторические здания в майнце, германии |
динозавр стоковая фотография rf | динозавр фотография rf |
А что же за данные мы брали для файнтьюнов? Если говорить про ключевой тюн большой модели (cherry-pick генерации которого мы покажем дальше, терпение), то процесс обучения выполнялся на субъективно отобранных 400 изображениях картин — хотелось немного изменить визуальный стиль генераций, сохранив при этом знание модели о мире аналогично тому, как это описано в статье про Emojich XL.
Процесс обучения
На первом этапе модель Kandinsky обучалась командой SberDevices на протяжении двух месяцев на платформе SberCloud ML Space, и этот процесс занял 20 352 GPU-V100 дней. В рамках этой фазы обучения использовался датасет без фильтрации, состоящий из 52 млн пар изображений и текстовых описаний к ним; впоследствии он был сокращён до 28 млн пар. В состав данных вошли такие известные датасеты, как ConceptualCaptions, YFCC100m (описания были переведены на русский язык системой машинного перевода), русская Википедия и другие. Первый этап обучения продолжался в течение 250 тыс. итераций.
После этого командой Sber AI была выполнена вторая фаза обучения модели на новых отфильтрованных данных (7 680 GPU-A100 дней). В состав обучающего датасета на этот раз вошли исключительно нативные русскоязычные данные (без автоматического перевода с других языков): русская часть датасета LAION-5B, VIST, Flickr8k, Flickr30k, Wiki-ru, CelebA и др. Из датасетов были исключены изображения с водяными знаками, а также выполнен реранкинг пар с помощью модели ruCLIP. В общей сложности набор данных для второй фазы обучения составил 119 млн пар, обучение длилось 60 тыс. итераций.
В ходе обеих фаз обучения использовался динамически меняющийся learning rate (на рисунке показан график изменения LR для второй фазы).

Ниже представлены графики изменения текстовой, визуальной и общей функций потерь для первой (синий) и второй (оранжевый) фаз обучения на валидационной выборке. В качестве такой выборки мы использовали часть MS-COCO validation set, которая состояла из 422 пар. Каждая пара была проверена вручную: описание переведено на русский язык автоматическим переводчиком и скорректировано при необходимости.
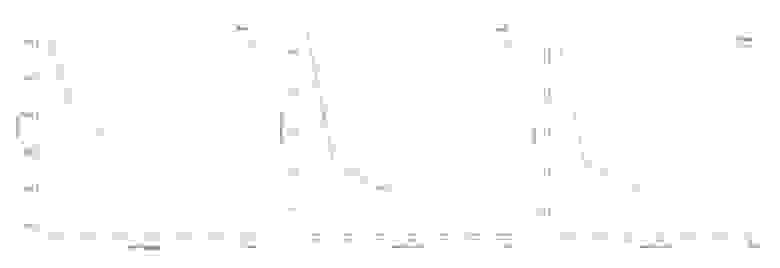
Анализируя данные горизонтальной оси, можно заметить, что первая фаза обучения включала в себя около 3,5 эпох, а вторая — 1,5 эпохи. При первом взгляде на графики возникает естественный вопрос по поводу разрыва между первой и второй фазами. На самом деле, этому есть несколько объяснений: изменение кодовой базы для тренировки модели (ушли от подхода Megatron model-parallel), изменение количества карт в обучении (что, соответственно, привело к сбросу всех состояний оптимизатора deepspeed zero3 после первой фазы), а также совершенно новые данные для обучения.
Картина 3: «Отпечатки рук художника», или Проводим эксперименты и судим о результатах
 Запрос: «Отпечатки рук художника», ruDALL-E Kandinsky
Запрос: «Отпечатки рук художника», ruDALL-E Kandinsky
Качественная оценка
Известно, что Василий Кандинский на определённом этапе творческого пути стал разделять свои произведения на три типа (и такая разметка, надо думать, очень помогла искусствоведам): «импрессии», «импровизации» и «композиции». Главным критерием такой классификации, если не вдаваться в подробности, можно назвать связь изображённого с непосредственно воспринимаемой реальностью: чем тоньше и слабее эта связь, тем больше работа отдаляется от «импрессии», приближаясь к «композиции», которая представляет собой чистую абстракцию. Мы позволили себе ещё более вольно трактовать эти типы (да простят нас искусствоведы) — и оценили, как модель справляется с генерацией реалистичных изображений («импрессий»); фантазийных образов, совмещающих в себе несколько концептов («импровизаций»); геометрических форм и пространственных структур («композиций»).
Следуя душеспасительным советам, согласно которым сравнивать себя нужно в первую очередь с «собой вчерашним», мы сравнили генерации моделей ruDALL-E XL и Surrealist XXL, полученные по текстовым описаниям из статьи про первую версию модели ruDALL-E. Что мы заметили: большая модель весьма хорошо справляется с созданием реалистичных изображений, качественно передавая различные текстуры (шерсть лисы, горная порода, гладкая поверхность металла, бархатная обивка кресла), тени (под автомобилем, под диваном) и отражения (закатное небо на озерной глади, окружающая зелень на поверхности стекла автомобиля). И хотя некоторые детали всё так же порой страдают (на морду оленя, например, лучше смотреть издалека и без очков), в большинстве случаев общая форма и отдельные элементы соответствуют желаемым объектам (те же «улиточные» олени больше не появляются, если их не звать намеренно). Что касается «импровизаций», комбинирующих в себе неожиданные образы, то здесь ситуация улучшилась, по сравнению с первой моделью: сгенерированная кошка действительно умудряется одновременно сочетать в себе признаки как кошки, так и облака («воздушная», «тающая» белая шерсть); кот оказывается если и не на Луне, то всё же на небесном теле — и может похвастаться адекватной формой; абстракция «тёмная энергия» обретает прекрасное воплощение в виде сияющей субстанции — либо в чёрной невесомости, либо в руках тёмного жреца. А Ждун сумел избавиться от созависимых отношений с авокадо.
 Озеро в горах, а рядом красивый олень пьёт воду (ruDALL-E XL vs Kandinsky)
Озеро в горах, а рядом красивый олень пьёт воду (ruDALL-E XL vs Kandinsky) Лиса в лесу (ruDALL-E XL vs Kandinsky)
Лиса в лесу (ruDALL-E XL vs Kandinsky) Орел сидит на дереве, вид сбоку (ruDALL-E XL vs Kandinsky)
Орел сидит на дереве, вид сбоку (ruDALL-E XL vs Kandinsky) Автомобиль на дороге среди красивых гор (ruDALL-E XL vs Kandinsky)
Автомобиль на дороге среди красивых гор (ruDALL-E XL vs Kandinsky) Векторная иллюстрация с розовыми цветами (ruDALL-E XL vs Kandinsky)
Векторная иллюстрация с розовыми цветами (ruDALL-E XL vs Kandinsky) Шикарная гостиная с зелеными креслами (ruDALL-E XL vs Kandinsky)
Шикарная гостиная с зелеными креслами (ruDALL-E XL vs Kandinsky) Современное кресло фиолетового цвета (ruDALL-E XL vs Kandinsky)
Современное кресло фиолетового цвета (ruDALL-E XL vs Kandinsky) Темная энергия (ruDALL-E XL vs Kandinsky)
Темная энергия (ruDALL-E XL vs Kandinsky) Кот на Луне (ruDALL-E XL vs Kandinsky)
Кот на Луне (ruDALL-E XL vs Kandinsky) Кошка, которая сделана из белого облака (ruDALL-E XL vs Kandinsky)
Кошка, которая сделана из белого облака (ruDALL-E XL vs Kandinsky) Красивое озеро на закате (ruDALL-E XL vs Kandinsky)
Красивое озеро на закате (ruDALL-E XL vs Kandinsky) Радужная сова (ruDALL-E XL vs Kandinsky)
Радужная сова (ruDALL-E XL vs Kandinsky) Ждун с авокадо (ruDALL-E XL vs Kandinsky)
Ждун с авокадо (ruDALL-E XL vs Kandinsky)
Теперь посмотрим, как модель справляется с геометрическими формами и пространственными структурами (тем, что мы договорились называть «композициями»). Начнём с простого запроса «квадратные синие часы»:

Здесь результат очень хороший, особенно если учитывать, что это случайная генерация без ранжирования по CLIP score: модель уловила форму — и практически все генерации получились соответствующими запросу (а на некоторых ещё и все цифры расставлены по порядку!). Увеличиваем количество углов — и подаём такой запрос: «Зелёные часы в виде шестиугольника».

В этом случае, конечно, меньше подходящих вариантов: считать углы непросто, иногда выходит больше, а иногда и вовсе не хочется заморачиваться — и получается привычный круг. Но верные генерации, тем не менее, в итоге успешно рождаются.
Что касается взаимного пространственного расположения объектов, то здесь у ruDALL-E те же проблемы, с которыми пока не смогли справиться ни DALL-E 2, ни Imagen: на сгенерированных изображениях объекты не всегда располагаются в соответствии с запросом — особенно, если этот порядок не соответствует привычным паттернам, как, например, в случае с фразой «A horse riding an astronaut» («Лошадь, скачущая на космонавте»). Этот запрос был даже включен в бенчмарк DrawBench — набор затравок, который создатели модели Imagen предлагают использовать для оценки text2image моделей.
 Запрос: «Лошадь, скачущая на космонавте»
Источник верхнего изображения: https://arxiv.org/pdf/2205.11487.pdf
Запрос: «Лошадь, скачущая на космонавте»
Источник верхнего изображения: https://arxiv.org/pdf/2205.11487.pdf
Мы также решили «вписать себя в историю» и дополнить кочующую из статьи в статью (от Make-A-Scene до DALL-E 2 — или, как её называют авторы в статье, unCLIP) таблицу с изображениями, сгенерированными различными моделями по избранным описаниям из MS-COCO. Результаты модели Kandinsky мы разместили рядом с её ближайшим родственником — моделью DALL-E от Open AI (модели, следующие в таблице за ней, относятся к семейству диффузионных моделей — другому типу архитектуры; разве что Make-A-Scene — всё тот же авторегрессионный трансформер, но генерирующий изображения не только на основе текста, но и сегментационной маски). Получившиеся картинки выглядят весьма достойно даже в сравнении с нынешними state-of-the-art диффузионными моделями и значительно выигрывают в качестве, реалистичности и детализированности у DALL-E.

Количественная оценка
Самое время перейти к объективным метрикам и показать какие-нибудь красивые числа. Для адекватной оценки условной генерации изображений нужно учитывать как минимум два аспекта: эстетические качества и реалистичность получившегося изображения и его соответствие исходному запросу. Базовый набор метрик в этом случае — FID и CLIP score, а каноничный датасет — MS-COCO validation set (30 тыс. изображений). Мы взяли этот датасет с описаниями, автоматически переведёнными на русский, — и получили такой результат:
FID | |
ruDALL-E XL | 18.6 |
Kandinsky | 15.4 |
