Большая миграция: как мы частное облако на RISC поднимали
В одном из предыдущих постов мы начали рассказ о своем частном облаке. В крупных компаниях проекты подобного масштаба — это легаси и неожиданные сюрпризы в процессе миграции. Сегодня мы хотим поделиться своим опытом миграции разных систем и показать небольшой кусочек нашей инфраструктуры, густо усеянный грифами «ДСП» и всевозможными NDA.

Чем нас x86 не устроил
В небольшой компании админ может развернуть в экзотической конфигурации сервер на Gentoo, с которым именно ему будет удобнее работать. Когда в зоне ответственности бизнес масштаба ВТБ, то каждая деталь оценивается на многочисленных совещаниях большим количеством людей. Иначе развертывание и эксплуатация новых систем может обернуться большими проблемами.
В банковской сфере широко распространены RISC-системы, и мы не стали здесь исключением. Часть наших сервисов уже работает на RISC-архитектуре или переводится на нее. При этом облачные провайдеры для проектов нашего масштаба работают преимущественно с x86. Оценив все «за» и «против», мы решили обойтись без изменения архитектуры и не переносить на x86 все сервисы, оставив на RISC то, что успешно работало на RISC до внедрения облака. Более того, часть x86-сервисов в ходе проекта, наоборот, была переведена на RISC.
Почему мы решили так сделать? Миграция сама по себе связана с рисками, которые мы не могли допустить. Ряд mission-critical систем выдерживают нужные параметры работы только на RISC — здесь стабильность этих систем оказывается выше. При соизмеримых конфигурациях RISC- и x86-машин наша АБС и базы Oracle демонстрируют большую производительность на первых. Наконец, RISC позволяет меньше тратить на обслуживание, что для банковской сферы также важно. Да и вообще доверять третьим лицам внутренние business-critical сервисы для миграции не позволит ни суровый отдел безопасности, ни законодательство.
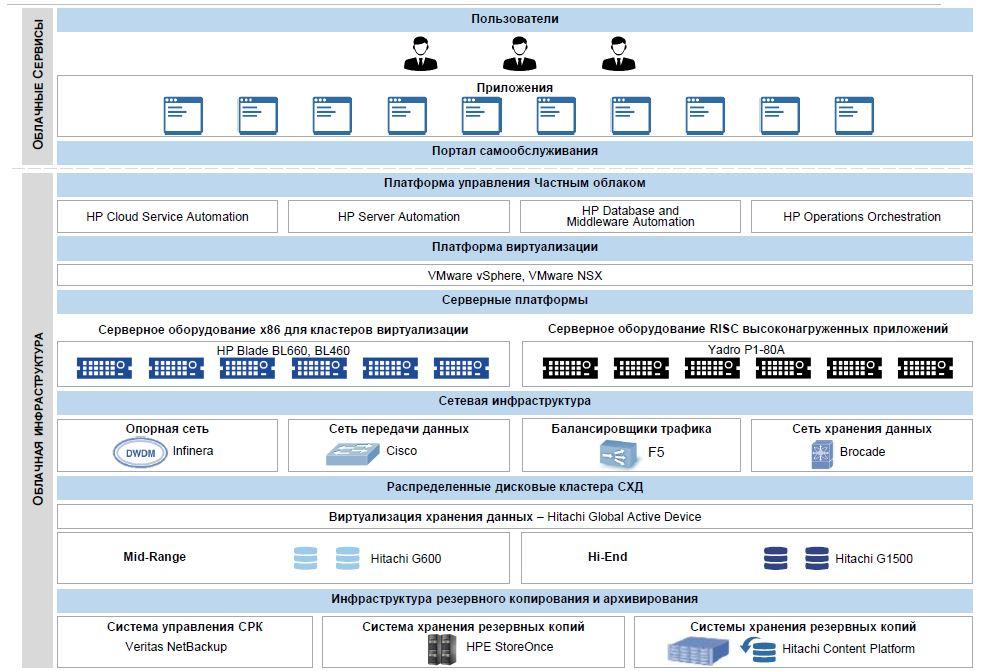
Частное облако не только способно принять на себя существующие mission-critical системы, но и обладает широкой функциональностью в работе с системами на основе RISC. Раньше процесс разворачивания тестовой или промышленной системы под описанные выше задачи занимал долгие месяцы планирования, закупки и введения оборудования в эксплуатацию. Теперь инженер в несколько кликов мыши может получить, к примеру, новый кластер Veritas Infoscale из двух пар LPAR с конфигурированием ресурсных групп под DR-сценарий. И таких гибких шаблонов и сценариев в облаке десятки, от выделения простой виртуалки или физического сервера под конкретную задачу, до разворачивания кластера на требуемой технологии.
Конечно, от x86 никто не отказывался, огромное количество задач по-прежнему решается на x86-системах. Облако имеет единый портал самообслуживания на базе технологий и продуктов HP и является единой точкой входа для управления как x86-, так и RISC-системами.
Что общего у ВТБ и IBM Watson?
Ядром облачной системы стали серверы IBM Р1–80А, сердцем которых является процессор POWER8 от IBM. Такие серверы IBM использует в своем суперкомпьютере Watson. Их ключевое преимущество — большое количество ядер и поддержка SMT8, аналога Intel Hyper-threading. Сервисы, хорошо работающие в параллельной нагрузке, отлично чувствуют себя на базе систем с этими CPU.
В каждом сервере установлено 16 процессоров POWER8 с тактовой частотой 4,02 ГГц, по 4 процессора на системную ноду. Каждый процессор имеет 12 ядер, что в сумме дает 192 ядра на сервер. С целью эффективного использования процессорных ресурсов физические сервера Р1–80А объединены в Power Enterprise Pool, а также используется схема лицензирования Mobile Capacity on Demand (CoD). В каждом сервере установлено 8 Тб оперативной памяти. Встроенная дисковая подсистема представлена носителями SSD 24×387GB SFF в полке расширения. Для запуска и функционирования приложений применяются технологии виртуальных партиций (LPAR), а для миграции виртуальных разделов между физическими серверами — технологии Live Partition Mobility.
Для нас большим преимуществом при заключении контрактов на внедрение и поддержку стало то, что поставщики оборудования — из России. Наш партнер — российская компания Yadro, которая активно внедряет решения на базе RISC-архитектуры и имеет все необходимое для работы с нашей отечественной криптографией (что критично для банков). Yadro — это первый OEM-партнером IBM в России, который имеет необходимые сертификаты по сборке вычислительных систем и СХД на базе их решений.
Миграция
Развертывать облачную систему на RISC было непростой задачей — насколько нам известно, до нас в России на таком уровне этого никто не делал. Процесс переезда начался летом 2017 года и идет сейчас полным ходом. Мы внимательно все спланировали, чтобы перенос никак не отразился на работе наших сервисов. Работа в самом разгаре: миграцией затронуто более 60 различных IT-систем.
Подходим ко всему осторожно. Активно задействуем тестовые прелайв-среды, лишний раз не экспериментируем с переходом на x86. По ходу миграции перешли на более новые поколения процессоров POWER и версии СУБД Oracle, а также в качестве внешних хранилищ данных стали использовать массивы с носителями FMD и SSD. Отказались от HP UX и SPARC. В целом, уменьшили количество вендоров и типов оборудования, ушли с end-of-life платформы.
Прогресс
По итогам апгрейда и миграции собрали статистику по ряду критичных систем. Так в централизованной автоматизированной банковской системе (ЦАБС) «Новая Афина» уменьшилось время прохождения рублевого платежного поручения. Раскладываем по этапам бизнес-процесса:
- Автоматическая обработка из ДБО — со 107 мс до 32 мс;
- Чтение — с 88 мс до 20 мс;
- Обработка картотеки — с 158 мс до 31 мс.
Кроме того, для большинства процедур расчетной системы скорость выполнения выросла в 2 раза. Среднее время обработки одного документа уменьшилось с 92 до 84 сек.
Наконец, система для обслуживания юридических и физических лиц Мбанк тоже показала заметный прогресс: время обработки одной транзакции филиала в Новосибирске снизилось с 464 до 227 с, в Екатеринбурге — со 179 до 130 с.
Отказоустойчивость и выводы
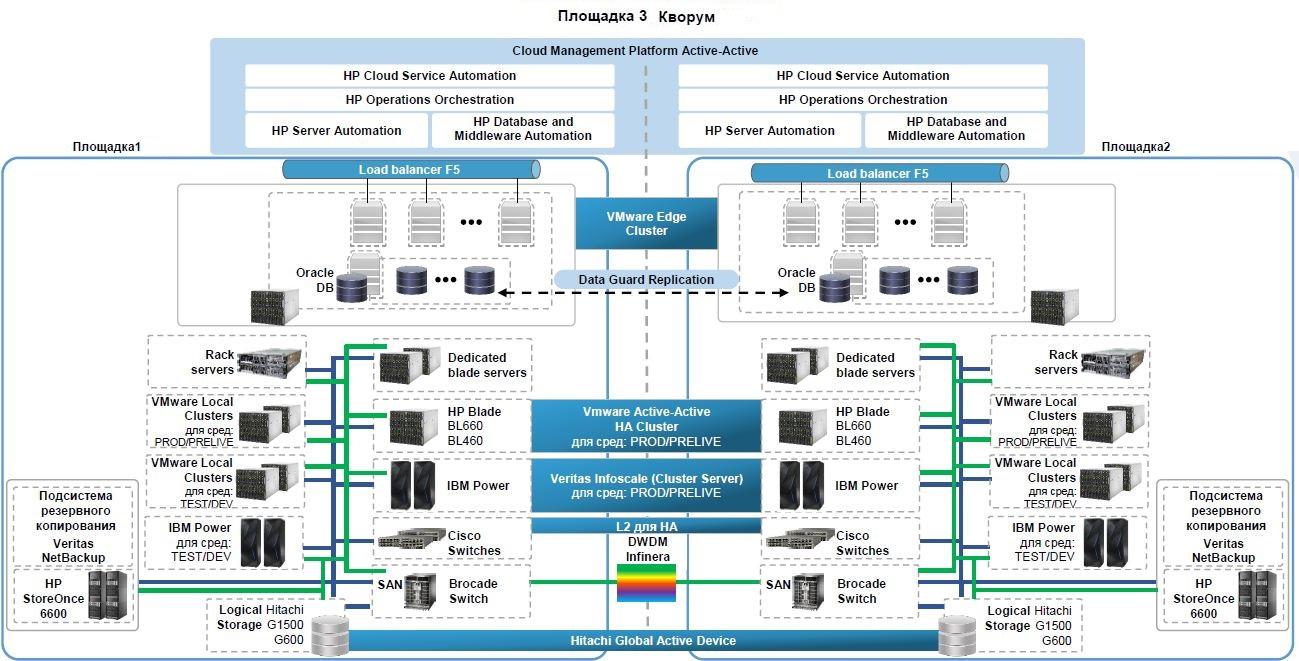
При проектировании облака были учтены требования по катастрофоустойчивости (DR), облако развернуто на двух географически разнесенных площадках. Геобалансировка фронтенд-нагрузки осуществляется с помощью платформы BigIP F5. Disaster Recovery на уровне систем хранения реализуется посредством технологии HDS Global Access Device (GAD), с арбитром кластера на третьей площадке. Каждый LUN, выдаваемый на хост, при необходимости реплицируется на оба сайта и имеет независимые пути с массивов, расположенных на разных площадках.
Сейчас внедрение облака идет полным ходом. В результате переезда мы планируем получить еще более надежную систему для обслуживания задач группы ВТБ, немного дополнительных седых волос у ответственных инженеров и весьма ощутимую экономию в финансовом плане. При этом уже сегодня облако позволяет повысить мощность вычислительных систем на базе RISC, добавляет возможности масштабирования высоконагруженных и критичных систем и облегчает миграцию существующих сервисов со standalone RISC-платформы на новую — гибкую, масштабируемую, отказоустойчивую.
