blk-mq и планировщики ввода-вывода

В сфере устройств хранения данных за последние годы произошли серьёзные изменения: внедряются новые технологии, растут объём и скорость работы дисков. При этом складывается следующая ситуация, в которой узким местом становится не устройство, а программное обеспечение. Механизмы ядра Linux для работы с дисковой подсистемой совершенно не приспособлены к новым, быстрым блочным устройствам.
В последних версиях ядра Linux была проделана большая работа по решению этой проблемы. С выходом версии 4.12 у пользователей появилась возможность использовать несколько новых планировщиков для блочных устройств. Эти планировщики основаны на новом способе передачи запросов — multiqueue block layer (blk-mq).
В этой статье мы хотели бы подробно рассмотреть особенности работы новых планировщиков и их влияние на производительность дисковой подсистемы.
Статья будет интересна всем, кто занимается тестированием, внедрением и администрированием высоконагруженных систем. Мы поговорим о традиционных и новых планировщиках, проанализируем результаты синтетических тестов и сделаем некоторые выводы о тестировании и выборе планировщика под нагрузку. Начнем с теории.
Немного теории
Традиционно подсистема для работы с драйверами блочных устройств в Linux предоставляла два варианта передачи запроса драйверу: один с очередью, и второй — без очереди.
В первом случае используется очередь для запросов к устройству, общая для всех процессов. С одной стороны, такой подход позволяет использовать различные планировщики, которые в общей очереди могут переставлять запросы местами, замедляя одни и ускоряя другие, объединять несколько запросов к соседним блокам в единый запрос для снижения издержек. С другой стороны, при ускорении обработки запросов со стороны блочного устройства эта очередь становится узким местом: одним на всю операционную систему.
Во втором случае запрос отправляется напрямую в драйвер устройства. Конечно, это даёт возможность миновать общую очередь. Но в тоже время, возникает необходимость создавать свою очередь и планировать запросы внутри драйвера устройства. Такой вариант подходит для виртуальных устройств, которые обрабатывают запросы и перенаправляют транзитом на реальные устройства.
В последние несколько лет скорость обработки запросов блочными устройствами выросла, в связи с чем требования к операционной системе, как и к интерфейсу передачи данных, изменились.
В 2013 году был разработан третий вариант — multiqueue block layer (blk-mq).
Опишем архитектуру решения в общих чертах. Запрос сначала попадает в программную очередь. Количество этих очередей равно количеству ядер процессора. После прохождения программной очереди запрос попадает в очередь отправки. Количество очередей отправки уже зависит от драйвера устройства, который может поддерживать от 1 до 2048 очередей. Так как работа планировщика осуществляется на уровне программных очередей, то запрос из любой программной очереди может попасть в любую очередь отправки, предоставляемую драйвером.
Стандартные планировщики
В большинстве современных дистрибутивов Linux доступны три стандартных планировщика: noop, CFQ и deadline.
Название noop — это сокращение от no operation, которое наводит на мысль о том, что этот планировщик ничего не делает. На самом деле это не так: noop реализует простую FIFO-очередь и объединение запросов к соседним блокам. Он не изменяет порядка следования запросов и в этом полагается на нижележащий уровень — например, на возможности Raid-контроллера по планированию.
CFQ (Completely fair queuing) работает сложнее. Он делит пропускную способность между всеми процессами. Для синхронных запросов создается по очереди на процесс. Асинхронные же запросы объединяются в очереди по приоритетам. В дополнение к этому CFQ сортирует запросы, чтобы минимизировать поиски секторов на диске. Время на выполнение запросов между очередями распределяется согласно приоритету, который можно настроить при помощи утилиты ionice. При настройке можно изменить как класс процесса, так и приоритет внутри класса. Мы не будем подробно останавливаться на настройках, отметим только, что этот планировщик обладает большой гибкостью, а настройка приоритета по процессам — весьма полезная вещь для ограничения выполнения административных задач в угоду пользовательским.
Планировщик deadline использует другую стратегию. За основу берется время нахождения запроса в очереди. Таким образом он гарантирует, что каждый запрос будет обслужен планировщиком. Так как большинство приложений блокируются именно на чтении, то deadline по умолчанию отдает приоритет запросам на чтение.
Механизм blk-mq был разработан после появления NVMe-дисков, когда стало ясно, что стандартные средства ядра не дают необходимой производительности. Он был добавлен в ядро 3.13, однако планировщики были написаны позже. В новейших версиях ядра Linux (≥4.12) имеются следующие планировщики для blk-mq: none, bfq, mq-deadline и kyber. Рассмотрим каждый из этих планировщиков подробнее.
Планировщики blk-mq: краткий обзор
Используя blk-mq, можно действительно отключить планировщик, для этого достаточно установить его в none.
Про BFQ написано достаточно много, скажу только, что он наследует часть настроек и основной алгоритм от CFQ, привнося понятие бюджета и ещё несколько параметров для тюнинга.
Mq-deadline — это, как легко догадаться, реализация deadline с использованием blk-mq.
И последний вариант — kyber. Он был написан для работы с быстрыми устройствами. Используя две очереди — запросы на запись и на чтение, kyber отдает приоритет запросам на чтение, перед запросами на запись. Алгоритм измеряет время завершения каждого запроса и корректирует фактический размер очереди для достижения установленных в настройках задержек.
Тесты
Вводные замечания
Проверить работу планировщика не так просто. Простой однопоточный тест не покажет убедительных результатов. Есть два варианта тестирования — имитировать многопоточную нагрузку при помощи, например, fio; установить реальное приложение и проверить как оно себя покажет под нагрузкой.
Мы провели ряд синтетических тестов. Все они проводились со стандартными настройками самих планировщиков (такие настройки можно посмотреть в /sys/block/sda/queue/iosched/).
Какой кейс будем тестировать?
Мы будем создавать многопоточную нагрузку на блочное устройство. Нас будет интересовать наименьшая задержка (наименьшее значение параметра latency) при наибольшей скорости передачи данных. Будем считать, что в приоритете находятся запросы на чтение.
Тесты HDD
Начнем с тестирования планировщиков с hdd-диском.
Для тестов HDD использовался сервер:
- 2 x Intel® Xeon® CPU E5–2630 v2 @ 2.40GHz
- 128 GB RAM
- Диск 8ТБ HGST HUH721008AL
- ОС Ubuntu linux 16.04, ядро 4.13.0–17-generic из официальных репозиториев
Параметры fio
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=1
runtime=7200
random_generator=lfsr
filename=/dev/sda1
[writers]
numjobs=2
rw=randwrite
[reader_40]
rw=randrw
rwmixread=40
Из настроек видно, что, мы обходим кэширование, выставляем глубину очереди 1 для каждого процесса. Два процесса будет записывать данные в случайные блоки, один — писать и читать. Процесс, описанный в разделе reader_40 будет 40% запросов отправлять на чтение, остальные 60% — на запись (опция rwmixread).
Подробнее опции fio описаны на man-странице.
Длительность теста — два часа (7200 секунд).

Deadline:

Noop:
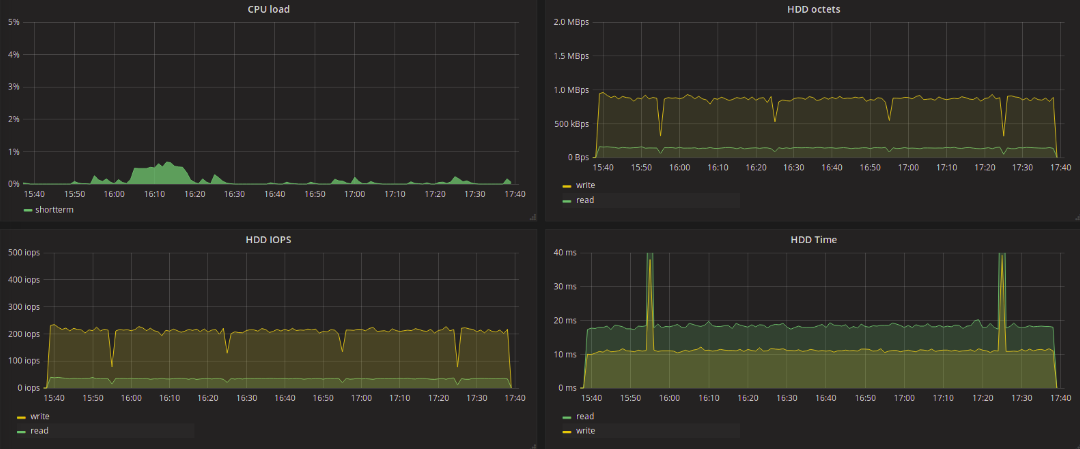
BFQ:

Mq-deadline:
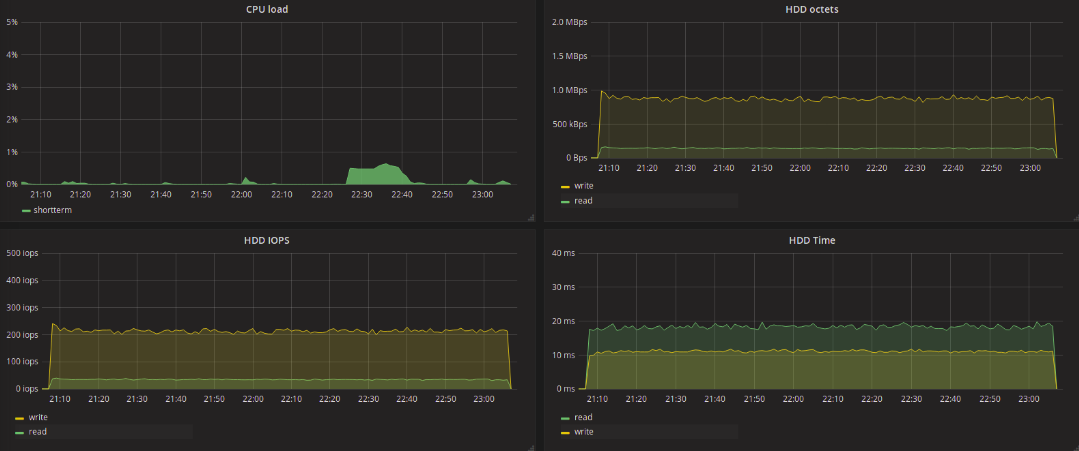
Kyber:
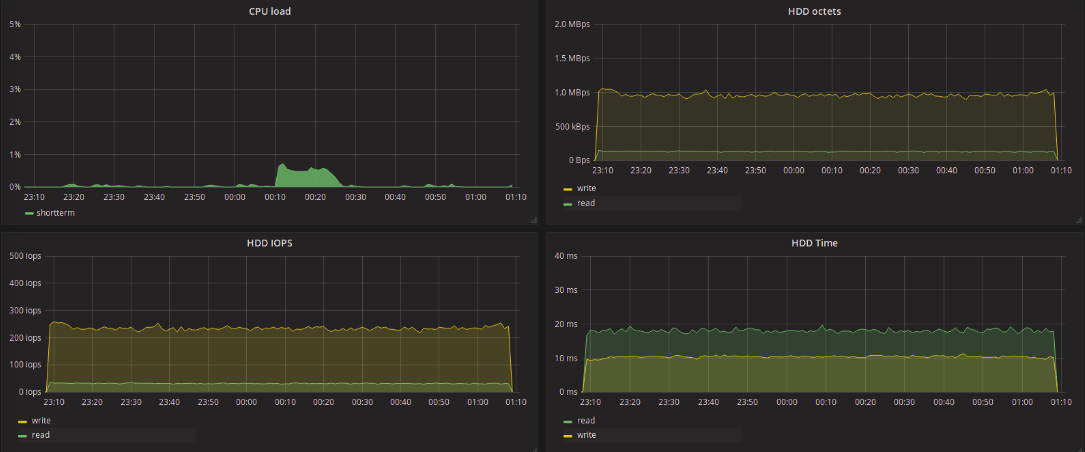
None:
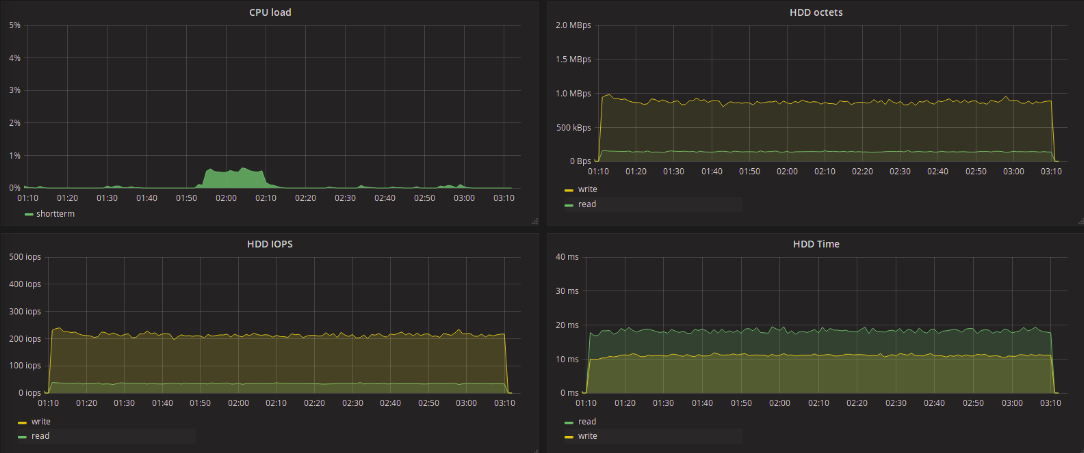
| writers randwrite | reader_40 randwrite | reader_40 read | ||
| CFQ | bw | 331 KB/s | 210 KB/s | 140 KB/s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.36 | 7.17 | 18.36 | |
| deadline | bw | 330 KB/s | 210 KB/s | 140 KB/s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.39 | 7.2 | 18.39 | |
| noop | bw | 331 KB/s | 210 KB/s | 140 KB/s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.36 | 7.16 | 18.42 | |
| BFQ | bw | 384 KB/s | 208 KB/s | 139 KB/s |
| iops | 93 | 50 | 33 | |
| avg lat | 10.65 | 6.28 | 20.03 | |
| mq-deadline | bw | 333 KB/s | 211 KB/s | 142 KB/s |
| iops | 81 | 51 | 34 | |
| avg lat | 12.29 | 7.08 | 18.32 | |
| kyber | bw | 385 KB/s | 193 KB/s | 129 KB/s |
| iops | 94 | 47 | 31 | |
| avg lat | 10.63 | 9.15 | 18.01 | |
| none | bw | 332 KB/s | 212 KB/s | 142 KB/s |
| iops | 81 | 51 | 34 | |
| avg lat | 12.3 | 7.1 | 18.3 |
*здесь и далее в столбце writers взята медиана от потоков writers, аналогично в столбцах reader_40. Значение задержки в миллисекундах.
Взглянем на результаты тестов традиционных (single-queue) планировщиков. Значения, полученные в результате тестов, практически не отличаются друг от друга. Нужно отметить, что всплески latency, которые встречаются на графиках тестов deadline и noop возникали и при тестах CFQ, хотя и реже. При тестировании blk-mq планировщиков этого не наблюдалось, максимальная величина задержки достигала целых 11 секунд, вне зависимости от типа запросов — запись или чтение.
Всё гораздо интереснее при использовании blk-mq-планировщиков. Нас в первую очередь интересует задержка обработки запросов на чтение данных. В контексте такой задачи в худшую сторону отличается BFQ. Максимальное значение задержки для этого планировщика доходило до 6 секунд на запись и до 2.5 секунд на чтение. Наименьшее максимальное значение задержки показал kyber — 129 мс на запись и 136 на чтение. На 20 мс больше максимальная задержка при none для всех потоков. Для mq-deadline она составила 173 мс на запись и 289 мс на чтение.
Как показывают результаты, достичь какого-то значимого снижения задержки путем смены планировщика не удалось. Зато можно выделить планировщик BFQ, показавший хороший результат в плане количества записанных/считанных данных. С другой стороны, при взгляде на график, полученный при тестировании BFQ, кажется странным неравномерное распределение нагрузки на диск, при том, что нагрузка со стороны fio достаточно равномерная и однообразная.
Тесты SSD
Для тестов SSD использовался сервер:
- Intel® Xeon® CPU E5–1650 v3 @ 3.50GHz
- 64 GB RAM
- 1.6TB INTEL Intel SSD DC S3520 Series
- ОС Ubuntu linux 14.04, ядро 4.12.0–041200-generic (kernel.ubuntu.com)
Параметры fio
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=4
runtime=7200
random_generator=lfsr
filename=/dev/sda1
[writers]
numjobs=10
rw=randwrite
[reader_20]
numjobs=2
rw=randrw
rwmixread=20
Тест похож на предыдущий для hdd, но отличается количеством процессов, которые будут обращаться к диску — 10 на запись и два на запись и чтение и соотношением записи/чтения 80/20, а также глубиной очереди. На накопителе был создан раздел, объемом в 1598GB, два гигабайта оставлено не задействованными.
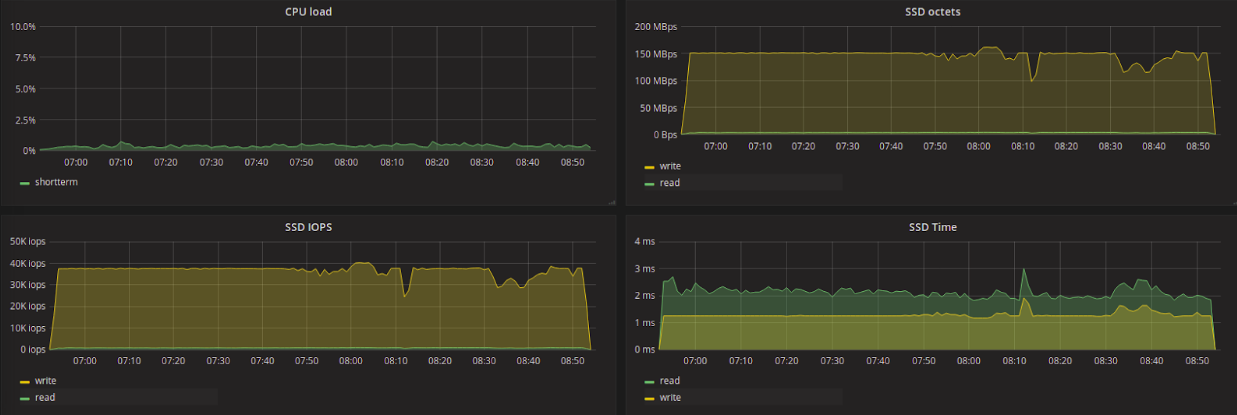
Deadline:
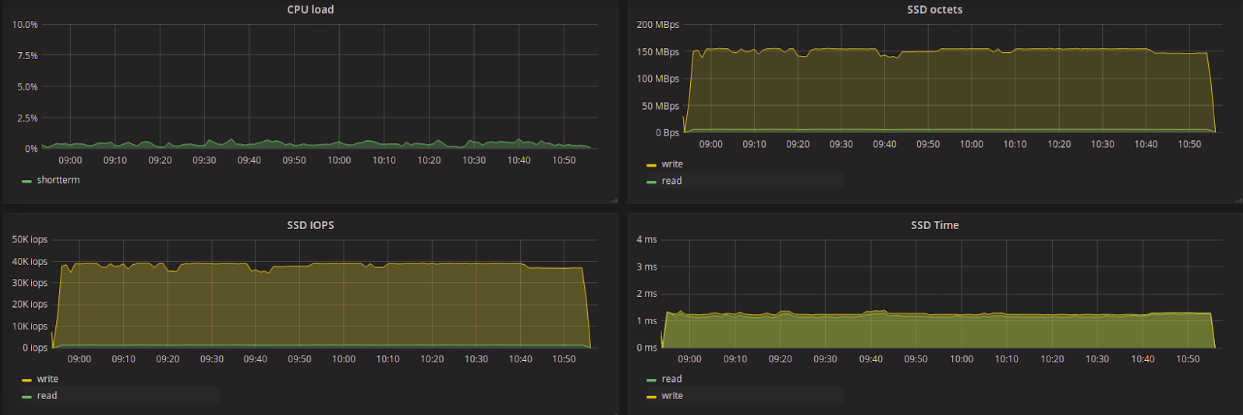
Noop:
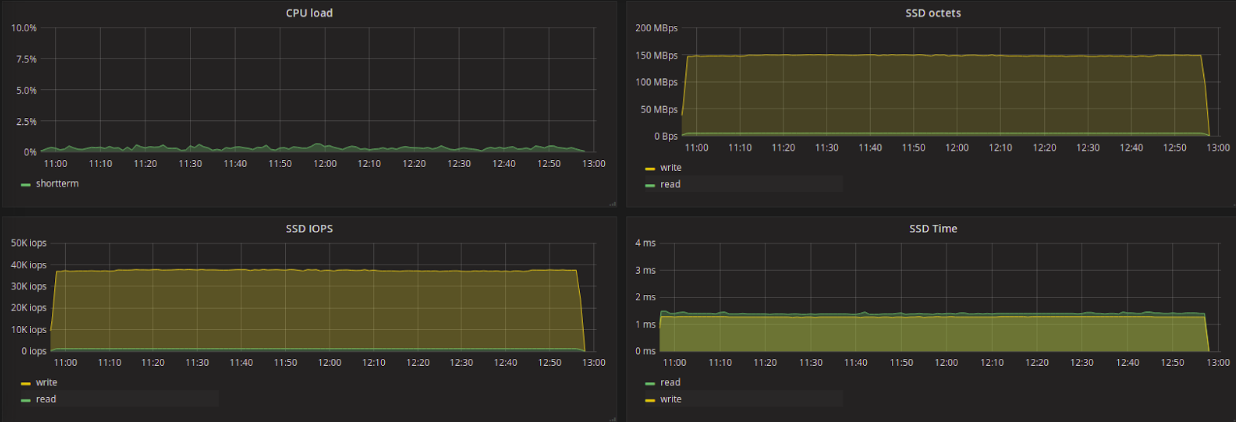
BFQ:

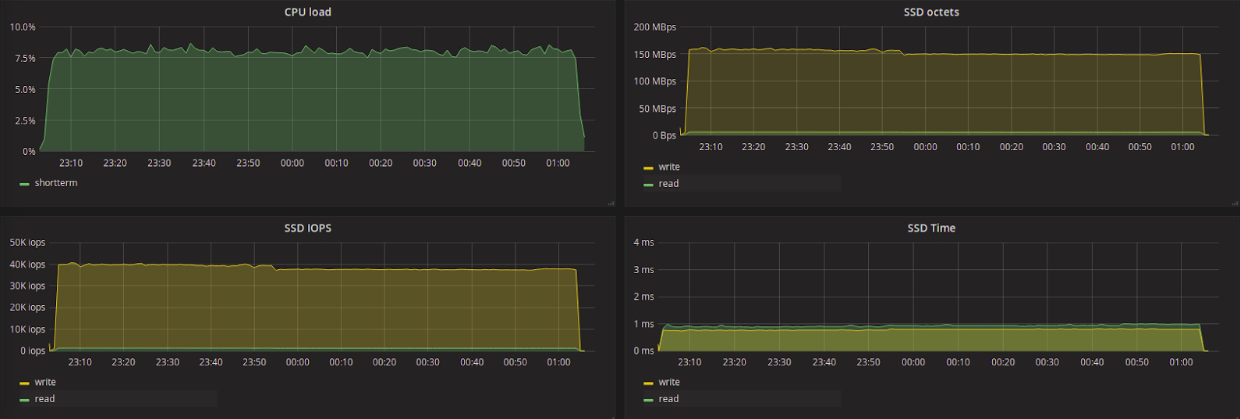
Mq-deadline:

Kyber:

None:
| writers randwrite | reader_20 randwrite | reader_20 read | ||
| CFQ | bw | 13065 KB/s | 6321 KB/s | 1578 KB/s |
| iops | 3265 | 1580 | 394 | |
| avg lat | 1.223 | 2.000 | 2.119 | |
| deadline | bw | 12690 KB/s | 10279 KB/s | 2567 KB/s |
| iops | 3172 | 2569 | 641 | |
| avg lat | 1.259 | 1.261 | 1.177 | |
| noop | bw | 12509 KB/s | 9807 KB/s | 2450 KB/s |
| iops | 3127 | 2451 | 613 | |
| avg lat | 1.278 | 1.278 | 1.405 | |
| BFQ | bw | 12803 KB/s | 10000 KB/s | 2497 KB/s |
| iops | 3201 | 2499 | 624 | |
| avg lat | 1.248 | 1.248 | 1.398 | |
| mq-deadline | bw | 12650 KB/s | 9715 KB/s | 2414 KB/s |
| iops | 3162 | 2416 | 604 | |
| avg lat | 1.264 | 1.298 | 1.423 | |
| kyber | bw | 8764 KB/s | 8572 KB/s | 2141 KB/s |
| iops | 2191 | 2143 | 535 | |
| avg lat | 1.824 | 1.823 | 0.167 | |
| none | bw | 12835 KB/s | 10174 KB/s | 2541 KB/s |
| iops | 3208 | 2543 | 635 | |
| avg lat | 1.245 | 1.227 | 1.376 |
Обратим внимание на среднюю задержку на чтение. Среди всех планировщиков здесь сильно выделяется kyber, показавший наименьшую задержку, и CFQ — наибольшую. Kyber создавался для работы с быстрыми устройствами и нацелен на снижение задержки в целом, с приоритетом для синхронных запросов. Для запросов на чтение, задержка очень низкая при этом объем прочитанных данных меньше, чем при использовании других планировщиков (за исключением CFQ).
Попробуем сравнить разницу в количестве считываемых в секунду данных между kyber и, например, deadline, а также разницу в задержке на чтение между ними. Мы видим, что kyber показал в 7 раз меньшую задержку на чтение, чем deadline, при этом уменьшение пропускной способности на чтение всего в 1.2 раза. В то же время, kyber показал результаты хуже для запросов на запись — в 1.5 увеличение задержки и уменьшение пропускной способности в 1.3 раза.
Наша исходная задача заключается в получении наименьшей задержки на чтение с наименьшим ущербом пропускной способности. По результатам тестов можно считать, что лучше других планировщиков для решения этой задачи подходит kyber.
Интересно отметить, что CFQ и BFQ показали сравнительно низкую задержку на запись, но при этом при работе CFQ наибольший приоритет получили процессы, которые выполняли только запись на диск. Какой вывод можно из этого сделать? Вероятно, BFQ более «честно» распределяет приоритет для запросов, как и заявлено разработчиками.
Максимальное значение latency было гораздо выше для *FQ планировщиков и mq-deadline — до ~3.1 секунд для CFQ и до ~2.7 секунд для BFQ и mq-deadline. Для остальных планировщиков максимальная задержка во время тестов составила 35–50 мс.
Тесты NVMe
Для тестов NVMe накопитель Micron 9100 был установлен в сервер, на котором проводились тесты SSD Разметка диска аналогична SSD — раздел под тест 1598GB и 2GB неиспользуемого пространства. Использовались такие же, как и в предыдущем тесте, настройки fio, только глубина очереди (iodepth) была увеличена до 8.
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=8
runtime=7200
random_generator=lfsr
filename=/dev/nvme0n1p1
[writers]
numjobs=10
rw=randwrite
[reader_20]
numjobs=2
rw=randrw
rwmixread=20
| writers randwrite | reader_20 write | reader_20 read | ||
| BFQ | bw | 45752 KB/s | 30541 KB/s | 7634 KB/s |
| iops | 11437 | 7635 | 1908 | |
| avg lat | 0.698 | 0.694 | 1.409 | |
| mq-deadline | bw | 46321 KB/s | 31112 KB/s | 7777 KB/s |
| iops | 11580 | 7777 | 1944 | |
| avg lat | 0.690 | 0.685 | 1.369 | |
| kyber | bw | 30460 KB/s | 27709 KB/s | 6926 KB/s |
| iops | 7615 | 6927 | 1731 | |
| avg lat | 1.049 | 1.000 | 0.612 | |
| none | bw | 45940 KB/s | 30867 KB/s | 7716 KB/s |
| iops | 11484 | 7716 | 1929 | |
| avg lat | 0.695 | 0.694 | 1.367 |
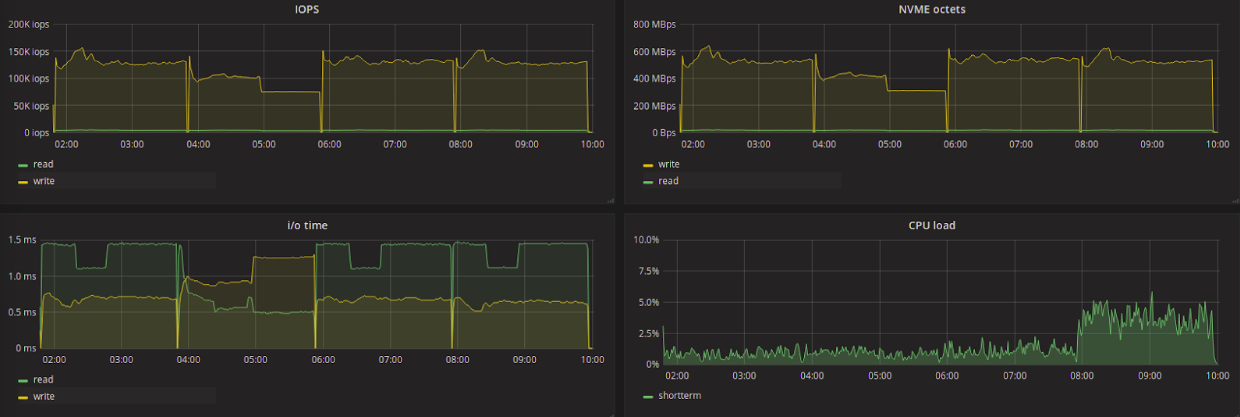
На графике показаны результаты тестирования со сменой планировщика и паузой. Порядок тестирования: none, kyber, mq-deadline, BFQ.
В таблице и на графике опять же видна активная работа алгоритма kyber по снижению задержки: 0.612 мс против 1.3–1.4 для остальных планировщиков. В основном считается, что для NVMe-дисков нет смысла использовать какой-либо планировщик, но если в приоритете стоит снижение задержки и можно пожертвовать количеством операций ввода-вывода, то имеет смысл рассмотреть kyber. Глядя на графики, можно заметить рост нагрузки на CPU при использовании BFQ (тестировался последним).
Выводы и рекомендации
Наша статья представляет собой очень общее введение в тему. Да и все данные наших тестов следует принимать с учётом того обстоятельства, что в реальной практике всё гораздо сложнее, чем в экспериментальных условиях. Всё зависит от целого ряда факторов: тип нагрузки, используемая файловая система и многое другое. Очень многое зависит и от аппаратной составляющей: модель дисков, RAID/HBA/JBOD.
Говоря в общих чертах: если приложение использует ioprio для приоритизации конкретных процессов, то выбор планировщика в сторону CFQ/BFQ будет оправдан. Но всегда стоит исходить из типа нагрузки и состава всей дисковой подсистемы. Для некоторых решений разработчики дают вполне конкретные рекомендации: например, для clickhouse рекомендуют использовать CFQ для HDD и noop для SSD дисков. Если же от дисков требуется большая пропускная способность, возможность выполнять больше операций ввода-вывода и средняя задержка не важна, тогда стоит смотреть в сторону BFQ/CFQ, а для ssd-дисков также noop и none.
Если же необходимо снижение задержки и каждая операция в отдельности, а в особенности — операция чтения, должна выполняться максимально быстро, то, помимо использования ssd, стоит использовать специально предназначенный для этого планировщик deadline, или один из новых — mq-deadline, kyber.
Наши рекомендации носят общий характер и подходят далеко не для всех случаев. При выборе планировщика, на наш взгляд, необходимо учитывать следующие моменты:
- Не последнюю роль играет аппаратная составляющая: вполне возможна ситуация, когда RAID-контроллер использует вшитые алгоритмы планирования запросов — в этом случае будет вполне оправдан выбор планировщика none или noop.
- Очень важен тип нагрузки: не в экспериментальных, а в «боевых условиях» приложение может показать другие результаты. Используемая для тестов утилита fio держит постоянную одинаковую нагрузку, но в реальной практике приложения редко обращаются к диску однообразно и постоянно. Реальная глубина очереди, средняя за минуту, может держаться в диапазоне 1–3, но в пиках подниматься до 10–13–150 запросов. Всё зависит от типа нагрузки.
- Мы тестировали только запись/чтение случайных блоков данных, а при работе планировщиков важна последовательность. При линейной нагрузке можно получить большую пропускную способность, если планировщик хорошо группирует запросы.
- У каждого планировщик есть опции, которые можно настраивать дополнительно. Все они описаны в документации к планировщикам.
Внимательный читатель наверняка заметил, что мы использовали разные ядра для тестирования планировщиков для HDD и SSD/NVMe дисков. Дело в том, что во время тестирования на ядре 4.12 с HDD работа планировщиков BFQ и mq-deadline выглядела достаточно странно — задержка то уменьшалась, то вырастала и сохраняла очень высокие значения в течение нескольких минут. Так как такое поведение выглядело не совсем адекватным и вышло ядро 4.13, мы решили провести тесты с HDD на новом ядре.
Не стоит забывать, что код планировщиков может измениться. В следующем релизе ядра окажется, что тот механизм, из-за которого на вашей нагрузке конкретный планировщик показывал деградацию производительности, уже переписан и теперь, как минимум, не снижает производительность.
Особенности работы планировщиков ввода-вывода в Linux — тема сложная, и в рамках одной публикации её вряд ли можно рассмотреть. Мы планируем вернуться к этой теме в следующих статьях. Если у вас есть опыт тестирования планировщиков в боевых условиях, мы будем рады прочитать о нем в комментариях.
